一种天文学数据筛选与下载的爬虫软件的制作方法
本发明涉及天文学数据筛选与下载的爬虫软件,属于计算机数据采集技术领域。
背景技术:
宇宙学在近期从一个几个人一个组就能独立做的领域,变成一个大数据、大组织的领域。大部分的宇宙学项目,比如:针对宇宙微波背景的planck、十年内要启动的欧洲eso的euclid、美国nasa的wfirst、美国nsf的lsst,大都是千人级的大组织。未来的数据量也将变得非常庞大,比如lsst每晚的观测数据量是15tb。目前天文学界尚无法处理这大数据,所以天文学越来越多需要计算机领域帮助。就现有技术而言,jsoc网站上的数据采集工作需要人力去查找、比对、下载,耗时耗力。为此,需要研发一款新的适应的软件来解决。
技术实现要素:
本发明是针对现有技术存在的不足,提供一种天文学数据筛选与下载的爬虫软件,可以解决现有技术中存在的效率低下问题,同时提供一种天文学数据自动化下载的可用流程,满足实际使用要求。
为解决上述问题,本发明所采取的技术方案如下:
一种天文学数据筛选与下载的爬虫软件,所述软件包括:noaa网站的模拟http请求与解析模块、solarmonitor网站的模拟http请求与解析模块、noaa网站与solarmonitor网站数据匹配模块及jsoc网站下载链接获取模块,上述各模块是通过python的一个库requests构建,其中,requests是使用apache2licensed许可证的http库,用python编写且支持http连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动响应内容的编码,支持国际化的url和post数据自动编码,还在python内置模块的基础上进行了高度的封装,使得python进行网络请求时,实现requests完成浏览器可有的任何操作。
作为上述技术方案的改进,所述的noaa网站的模拟http请求与解析模块为:可以对noaa网站发送http请求并得到noaa网站1975年1月1日至2017年12月31日间的每天太阳活动的时间、等级数据,可将noaa网站指定网页筛选后的特定数据项保存到磁盘。
作为上述技术方案的改进,所述solarmonitor网站的模拟http请求与解析模块为:可以循环遍历2010年1月1日至2018年10月1日间的solarmonitor网站记录的每天的太阳活动记录的时间信息、经纬度信息以及等级信息,可以将筛选后的solarmonitor网站的指定信息保存到磁盘。
作为上述技术方案的改进,所述noaa网站与solarmonitor网站数据匹配模块为:能够根据前面两个模块得到的磁盘文件进行匹配,匹配规则为若两个文件中的记录行中的太阳活动的起始时间与等级相等那么就完成匹配,否则不完成,将完成匹配的一条记录写入磁盘指定位置,从而将上述两个模块生成的数据文件合并成一个包含太阳活动的起始时间、结束时间、经度、纬度、等级信息的数据文件。
作为上述技术方案的改进,所述jsoc网站下载链接获取模块为:能够根据文本文件中的数据填写待下载书的各项参数并发送http请求,之后解析jsoc网站返回的参数获得数据的下载链接。
作为上述技术方案的改进,所述的天文学数据筛选与下载的爬虫软件还包括天文学数据自动化下载方法,方法如下:
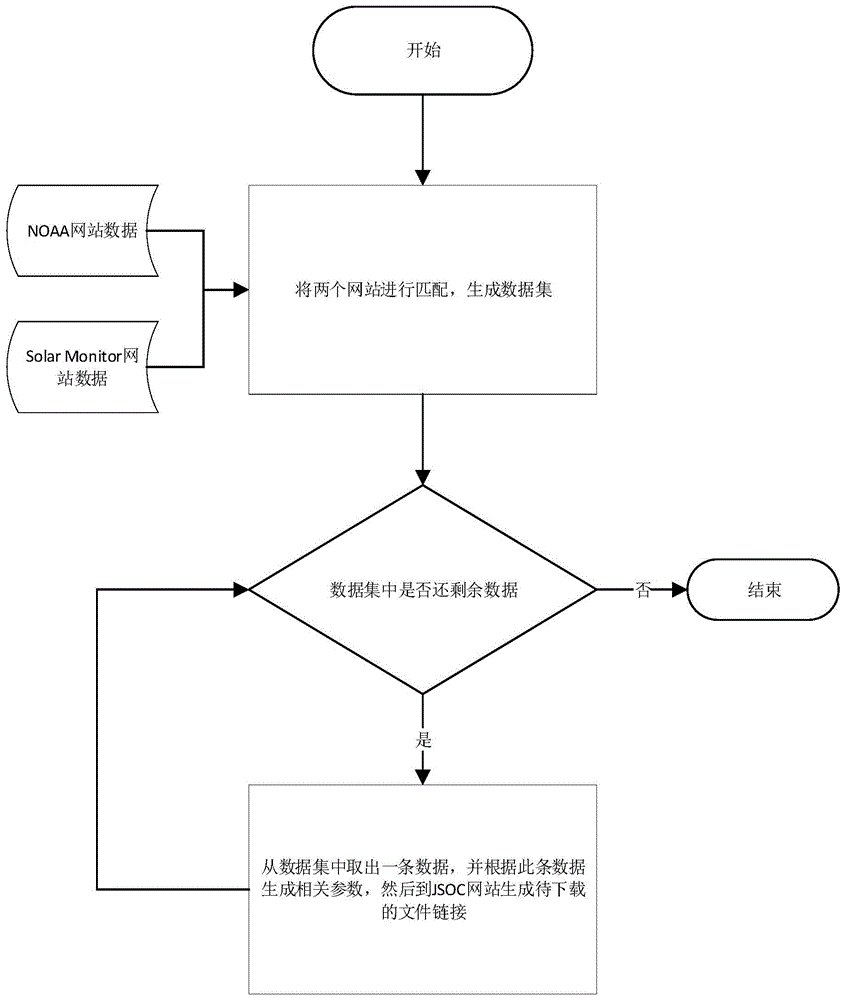
步骤1:使用网络爬虫采集noaa网站的太阳活动发生区域的起始时间、结束时间、活动等级数据;
步骤2:使用网络爬虫采集solarmonitor网站的太阳活动发生区域的起始时间、区域编号、活动等级、以及对应区域的经纬度信息;
步骤3:根据太阳活动爆发区域的起始时间与等级关系匹配步骤1和步骤2得到的数据集,得到每个太阳活动发生区域的区域编号、发生时间、结束时间、活动等级;
步骤4:利用步骤3得到的数据,去jsoc网站利用网络爬虫发送请求,并得到请求数据的下载链接;
步骤5:得到下载链接之后就可以利用任意下载工具进行下载。
本发明与现有技术相比较,本发明的实施效果如下:
使jsoc网站数据采集周期大大算短,使网站中现有的所有数据都能够被采集、使用,使利用此网站的科研工作者能更快的获得期望的数据集。
附图说明
图1为本所述软件整体流程图;
图2为本发明实施例演示示意图;
图3为本发明实施例演示获得网页代码示意图;
图4为本发明实施例从网页代码获取参数示意图;
图5为本发明所述步骤1采集完成的部分数据示意图;
图6为本发明所述步骤2对应的部分数据示意图;
图7为本发明所述步骤2对应模块运行的部分截图;
图8为本发明所述步骤3对应的部分数据示意图;
图9为本发明所述步骤4对应的部分数据示意图;
图10为本发明所述步骤4对应程序运行的截图。
具体实施方式
下面将结合具体的实施例来说明本发明的内容。
实施例:天文学数据筛选与下载的爬虫软件,软件包括:noaa网站的模拟http请求与解析模块、solarmonitor网站的模拟http请求与解析模块、noaa网站与solarmonitor网站数据匹配模块及jsoc网站下载链接获取模块,上述各模块是通过python的一个库requests构建,其中,requests是使用apache2licensed许可证的http库,用python编写且支持http连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动响应内容的编码,支持国际化的url和post数据自动编码,还在python内置模块的基础上进行了高度的封装,使得python进行网络请求时,实现requests完成浏览器可有的任何操作。
其中,noaa网站的模拟http请求与解析模块为:可以对noaa网站发送http请求并得到noaa网站1975年1月1日至2017年12月31日间的每天太阳活动的时间、等级数据,可将noaa网站指定网页筛选后的特定数据项保存到磁盘。
solarmonitor网站的模拟http请求与解析模块为:可以循环遍历2010年1月1日至2018年10月1日间的solarmonitor网站记录的每天的太阳活动记录的时间信息、经纬度信息以及等级信息,可以将筛选后的solarmonitor网站的指定信息保存到磁盘。
noaa网站与solarmonitor网站数据匹配模块为:能够根据前面两个模块得到的磁盘文件进行匹配,匹配规则为若两个文件中的记录行中的太阳活动的起始时间与等级相等那么就完成匹配,否则不完成,将完成匹配的一条记录写入磁盘指定位置,从而将上述两个模块生成的数据文件合并成一个包含太阳活动的起始时间、结束时间、经度、纬度、等级信息的数据文件。
jsoc网站下载链接获取模块为:能够根据文本文件中的数据填写待下载书的各项参数并发送http请求,之后解析jsoc网站返回的参数获得数据的下载链接。
本发明的各个模块的实现思路相同,主要思想是利用python的requests库模拟发送http请求,从而得到指定网页的html代码,然后从html中提取出对我们有用的数据,下面以获取solarmonitor网站的箭头所指向的noaanumber为例进行演示,如图1所示。
首先加载相关库函数,请求https://www.solarmonitor.org网站进行测试(测试是否可以得到该网页的html代码):如图2所示。
然后,我们请求带有指定日期参数的solarmonitor网页,利用解析html的方法我们可以从该网站的html中提取出我们想要的参数:12492;如图3所示。
这样就得到了我们想要的数据,其他网站或者其他数据项的采集原理同上。
具体地,所述天文学数据筛选与下载的爬虫软件还包括天文学数据自动化下载方法,方法如下:
步骤1:使用网络爬虫采集noaa网站的太阳活动发生区域的起始时间、结束时间、活动等级数据,如图5所示;
步骤2:使用网络爬虫采集solarmonitor网站的太阳活动发生区域的起始时间、区域编号、活动等级、以及对应区域的经纬度信息,如图6和图7所示;
步骤3:根据太阳活动爆发区域的起始时间与等级关系匹配步骤1和步骤2得到的数据集,得到每个太阳活动发生区域的区域编号、发生时间、结束时间、活动等级,如图8所示;
步骤4:利用步骤3得到的数据,去jsoc网站利用网络爬虫发送请求,并得到请求数据的下载链接,如图9和图10所示;
步骤5:得到下载链接之后就可以利用任意下载工具进行下载。
进一步地,一般来说,人工采集一条数据的周期大概是3~5分钟左右,但使用我们这款软件采集一条数据的周期大概是2~3秒,大大节约了采集时间,避免了人工采集过程中可能出现的差错。
以上内容是结合具体的实施例对本发明所作的详细说明,不能认定本发明具体实施仅限于这些说明。对于本发明所属技术领域的技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!