一种基于知识表示的生物医学实体链接方法与流程
本发明属于自然语言处理领域,涉及到一种对生物医学文本进行实体链接的方法,特别涉及到基于知识表示和深度神经网络融合的生物医学实体链接。
背景技术:
随着计算机技术和生物技术的高速发展,生物医学领域的文献正在以指数方式增长。面对快速增长的海量数据,研究人员迫切希望揭示蕴含于海量的生物医学文献中的生物医学知识,推动生物医学的发展。这一需求推动了生物医学文本挖掘技术的产生与发展。生物医学命名实体链接(biomedicalnamedentitylinking,bionel)作为其中的一项重要研究,目的是促进数据的集成(dataintegration)和重用(re-use)。bionel是指将文本中的生物医学实体(如蛋白质、基因、疾病和药物等)通过知识库映射为唯一标识符(id),方便于将文本中的非结构化信息转换为结构化数据。它的本质其实是建立文本中实体提及与知识库中实体之间的映射关系,通过建立文本与知识之间的联系,来帮助生物医学知识库自动填充和实体关系抽取等技术的研究。
生物医学命名实体具有如下特点:1)一词多义(多义词),即相同的词或短语可以表示不同的生物命名实体或概念,如:作为生物实体的cap就有多种意义如胱氨酸氨基肽酶(cystineaminopeptidase)、衣壳蛋白(capsid)、环化酶相关蛋白(cyclase-associatedprotein)和钙激活蛋白(calciumactivatedprotease-q9uqc9)等;2)多词一义(同义词),即同一生物医学实体具有多种变体。如:ptgs2,cyclooxygenase-2,prostaglandin-endoperoxidesynthase2,cox2均表示前列腺素过氧化物合成酶。除此之外,生物医学命名实体的缩写被大量使用且不规范,命名方式复杂多样没有统一标准,这都使得生物医学命名实体链接变得困难。
目前,解决bionel的方法主要有基于词典的方法,基于向量的方法,基于传统机器学习的方法,以及基于深度学习的方法。
基于词典的方法是通过字符匹配和一些启发式规则从文本中识别词典中的生物医学实体id。简单的字符匹配方法可以获得较高的精确率,但是召回率极低。这种情况大多跟上述生物医学命名实体的特点有关。同时,此方法严重依赖词典的完整性和规则的设计,难以被应用于新的领域。
基于向量的方法是将实体提及(entitymention)和所有候选实体映射到公共向量空间,然后对每个候选实体定义一个评分度量进行排序(如余弦相似度、欧氏距离、编辑距离、主题相似度、实体流行度等),选取排序第一的候选作为实体提及的链接结果。leaman等人(dnorm:diseasenamenormalizationwithpairwiselearningtorank,2013,bioinformatics,29(22):2909-2917)提出dnorm系统,采用向量空间模型来表示医学实体,并使用相似性矩阵来衡量实体提及和候选实体的相似程度。他们在ncbi疾病数据集上取得了0.782的f值,高于基于词典的方法。
基于传统机器学习的方法根据上下文语境对候选实体id进行分类,其目的是对数据的分布进行统计,拟合出数据趋势走向。常用的机器学习模型包括:条件随机域模型(crf)、支持向量机模型(svm)、隐马尔可夫模型(hmm)、最大熵模型(me)等。但是,基于传统机器学习的方法依赖于复杂的特征工程,需要对数据进行深度探索性分析,根据丰富的领域知识和长期经验来设计和确定模型的最优特征集合,人工成本昂贵且耗时。同时,抽取的特征表示均采用独热(one-hot)的高维稀疏表示方法,难以捕捉文本蕴含的深层语义信息。
基于深度学习的方法克服了对特征工程的依赖,利用多层神经网络构建数据的深层次抽象特征表示。深度学习的代表性模型主要有自动编码机、rnn、lstm、cnn等。li等(cnn-basedrankingforbiomedicalentitynormalization,2017,bmcbioinformatics,18(11):385)将生物医学实体链接任务视为一个排序问题,利用卷积神经网络对候选的语义信息及其形态信息进行建模,然后计算所有<实体,候选>对的相似度得分并排序,得分最高的候选即作为链接结果。他们的模型在share/clef和ncbi数据集上取得了较好的性能。
实体所在的上下文是消歧的关键,正如分布式假说的想法“词的语义由其上下文决定”。上述方法大都着眼于文本数据,通过自动或半自动的方式挖掘有效特征来提高生物医学实体链接的性能。但相比于其它领域,生物医学实体链接需要有力的知识资源支撑,而大量的隐含知识难以在样本数据中进行体现。这些特征数据背后的关联逻辑隐藏在丰富的生物医学词典、知识库(knowledgebase,kb)等语义网络中,比如蛋白质知识库uniprot,基因知识库ncbigene等。他们包含丰富的实体及其结构信息,能够为实体链接任务提供知识支持。然而这些知识在生物医学实体链接系统中尚未得到充分应用。融合实体结构信息和实体语义信息,开展面向大规模生物医学知识库的知识表示学习研究,对于生物医学实体链接具有重要的理论意义和实际应用价值。
技术实现要素:
为利用知识库丰富的实体结构信息帮助克服生物医学实体一词多义和多词一义的难题,本发明提供了一种面向实体结构信息的表示学习方法和一种基于知识表示的生物医学实体链接方法,融合了知识表示与文本语义表示,提高现有生物医学实体链接的性能。
本发明的技术方案:
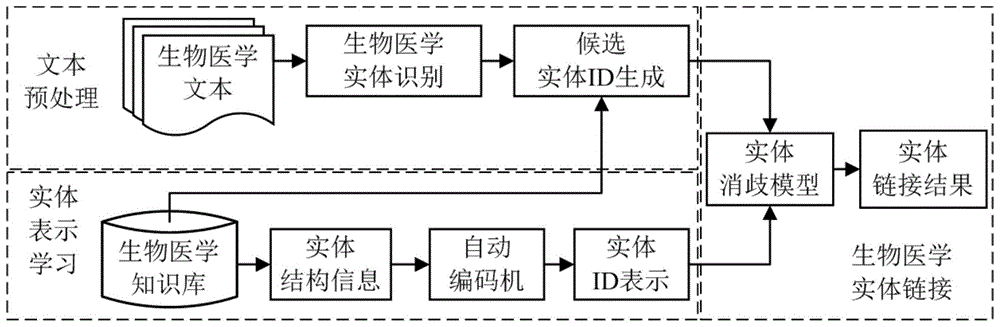
一种基于知识表示的生物医学实体链接方法,该方法包括三部分:文本预处理、基于知识库的实体表示学习、基于知识表示的生物医学实体链接。具体步骤如下:
步骤一、文本预处理
对于生物医学文本,首先提取出文本中所有待链接的生物医学实体提及,然后通过知识库查找实体提及对应的所有候选实体标识符(id)。为了优化内存和运行时间,仅保留排序前五的查找结果作为实体提及的候选id集合。
步骤二、基于生物医学知识库的实体表示学习
知识库中包含了丰富的实体及其结构信息,如同一实体多种变体和不同实体同名。本发明将这些实体结构信息作为向量空间上的约束,采用自动编码机对实体提及表示和变体表示进行重构,从而学习实体id表示。自动编码机是基于如下两个约束:(i)实体id表示是其各个变体表示的和;(ii)实体提及表示是其同名变体表示的和。定义实体提及表示为
s(j)=∑iv(i,j)
m(i)=∑jv(i,j)
该自动编码机由两部分组成,即编码器和解码器。编码时,编码器按照实体提及→变体→实体id的顺序进行。其中,实体提及表示m(i)初始化为其组成单词的预训练词表示的平均值,变体表示v(i,j)通过引入一个对角矩阵
s(j)=∑iv(i,j)=∑ie(i,j)m(i)
e(i,j)是一个对角矩阵,满足条件∑je(i,j)=in,其中in是一个单位矩阵。
解码时,解码器按照实体id→变体→实体提及的顺序进行。通过引入另一个对角矩阵
对角矩阵
定义一个重构误差函数来训练自动编码机的参数,其公式为:
该重构误差函数由两部分组成,一个是要求解码出的实体提及表示
综上,生物医学知识库中包含实体间同一实体多种变体和不同实体同名的结构信息,而基于知识库的实体表示学习旨在将这些实体结构信息作为向量空间的约束,通过自动编码机表示为稠密低维实值向量,最终获得实体id表示。
步骤三、基于知识表示的生物医学实体链接
利用步骤二学习获得的实体id表示,对步骤一抽取出的生物医学实体提及进行消歧,获得在特定上下文中实体提及对应的唯一id。本发明提供了一种基于知识表示的实体消歧模型,该模型通过注意力机制(attention)和门机制(gating)融合文本语义表示和实体id表示,从而预测实体提及被链接到当前候选实体id的概率。具体来说,首先,通过嵌入层,将待链接实体提及的候选实体id,和它的左侧上下文、右侧上下文分别映射到向量空间,获得候选id表示s和左、右侧上下文词向量序列
对于一段词序列的语义信息,其中每个词相对于候选id的重要性应该是不同的。为此,我们提出基于知识表示的注意力(attention)机制,利用候选id表示计算每个时间步隐层表示的归一化权重αt。以左上下文表示为例,其计算公式如下:
其中,ht是
接下来,对gru隐层表示的整个序列作加权求和操作,使结构信息编码的候选id表示与上下文语义表示融合,公式如下:
o=∑tαtht
其中,o表示左上下文表示ol或右上下文表示or;
注意力机制分别应用于左、右侧隐层表示从而获得的左、右上下文表示ol和or,并通过一个门机制来进行动态控制,让实体提及的最终上下文表示z获得充分的学习,计算公式如下:
z=g⊙ol+(1-g)⊙or
g=σ(wg·ol+vg·or+bg)
其中,wg,vg,bg是待训练的参数;⊙表示逐元素相乘;g是权重,通过将左右上下文ol和or输入一层全连接层并通过sigmoid激活函数σ获得的。
最后,我们将实体提及的上下文表示z和候选id表示s拼接输入给分类器。分类器由具有relu激活的两层全连接神经网络(fc)和一个包含两个分类单元(分别为被连接和不被链接的概率)的sigmoid输出层组成,公式如下:
pr1=relu(w1·[z;s]+b1)
pr2=relu(w2·pr1+b2)
p=sigmoid(w3·pr2+b3)
其中,w1,b1,w2,b2,w3,b3是待训练的参数,[;]表示拼接操作。
基于知识表示的实体消歧模型通过一个二元交叉熵损失函数进行训练,公式如下:
其中,n是训练样例个数,yi是第i个样例的正确标签,λ||w||为训练参数的正则项,pi是第i个样例的预测概率,。
生物医学实体消歧模型为每个实体提及与其候选id进行打分并排序,选择得分最高的候选id作为最终的链接结果。
本发明的有益效果:
1、本发明利用知识库辅助生物医学实体链接,将知识库中实体间的结构信息(不同实体同名和同一实体多种变体)作为自动编码机的约束,学习实体id表示。该实体id表示嵌入了知识库的实体结构信息,有效解决了实体id表示质量无法保证的问题,并能同时学习获得多种变体表示和同名实体提及表示。
2、本发明将实体id表示用于生物医学实体链接,构建了一个基于知识表示和深度神经网络结合的生物医学实体链接模型。基于实体id表示,采用注意力机制gru网络,计算待链接实体提及的上下文加权平均表示,深度融合文本语义表示和知识表示两方面的信息,进行实体消歧,有效提高生物医学实体链接的准确性和可靠性。
附图说明
附图1是技术流程图。
附图2是同一实体多种变体和不同实体同名的语义关系示例图。
附图3是自动编码机的结构图。
附图4是生物医学实体消歧模型图。
具体实施方式
给定表1的一个应用实例,包括文本1和文本2。下面结合本发明的技术方案(和附图)详细叙述本发明的具体实施方式。
表1应用实例
1、首先,从文本1和文本2中提取待链接的实体提及“vegf”。然后通过知识库查找实体提及“vegf”可能对应的所有候选实体id,包括人类属id“ncbigene:7422”和家鼠属id“ncbigene:22339”。
2、从知识库中抽取同一实体多种变体和不同实体同名等实体结构信息。以图2为例,在实线框中,变体“vegf(human)”,“mvcd1”和“vpf”均表示同一基因(血管内皮生长因子),id为“ncbigene:7422”。这就是生物医学实体的同一实体多种变体问题(同义词)。在虚线框中,变体“vegf(human)”和“vegf(mouse)”的名称相同,但是分别对应不同的人类属id“ncbigene:7422”和家鼠属id“ncbigene:22339”。这就是生物医学实体的不同实体同名问题(多义词)。
3、将这些实体结构信息作为向量空间上的约束,采用自动编码机对实体提及表示和变体表示进行重构,学习基于知识库的实体id表示。自动编码机的结构如图3所示,它基于如下两个约束:(i)实体id表示是其各个变体表示的和;(ii)实体提及表示是其同名变体表示的和。以图2为例进行说明。根据约束(i),实体id“ncbigene:7422”的表示是其各个变体“vegf(human)”,“mvcd1”和“vpf”表示的和;根据约束(ii),实体提及“vegf”的表示是其同名变体“vegf(human)”和“vegf(mouse)”表示的和。
自动编码机的学习过程如下。首先,按照实体提及→变体→实体id的顺序进行编码。其中,实体提及表示初始化为其组成单词的预训练词向量的平均值;变体表示则通过引入的对角矩阵对同名实体提及表示进行分解获得;实体id表示由其对应的各个变体表示加和获得。然后是解码,按照实体id→变体→实体提及的顺序进行。引入另一个对角矩阵,将编码获得的实体id表示分解为各个变体表示,再由同名变体表示的加和重构实体提及表示。自动编码机的目标有两个,一个是让解码部分重构的实体提及表示与输入的提及表示对齐,另一个是让解码部分重构的变体表示与编码部分的变体表示对齐,从而使得他们在向量空间上尽可能接近。最后,通过最小化重构误差函数,调整自编码机的参数,将实体结构信息嵌入到实体id表示中。
3、利用实体消歧模型,通过注意力机制(attention)和门机制(gating)融合文本语义表示和实体id表示,预测实体提及被链接到当前候选实体id的概率。消歧模型如图4所示。首先,通过嵌入层,将一个候选实体id,和它的左侧上下文、右侧上下文分别映射到向量空间,获得实体id表示和左、右侧上下文词向量序列。然后,将左、右侧上下文词向量序列分别输入给一个门递归单元神经网络(gru)获得隐层表示。接下来,利用id表示,基于注意力机制计算每个时间步隐层表示的归一化权重,作加权求和获得左、右上下文表示。最后,采用一个门机制组合左、右上下文表示,并与候选id表示拼接输入给分类器。分类器预测实体提及被链接到当前候选实体id的概率,选择概率最高的一个候选id作为最终的链接结果。
在本实例中(表1),系统识别出文本1中的实体提及“vegf”并将其链接到家鼠属的标识符“ncbigene:22339”,识别出文本2中的实体提及“vegf”并将其链接到人类属的标识符“ncbigene:7422”上。
- 还没有人留言评论。精彩留言会获得点赞!