一种自动给代码打数据结构标签的方法与流程
本发明属于人工智能下自然语言处理领域,具体是一种自动给代码打数据结构标签的方法。
背景技术:
随着互联网的普及,互联网上出现了大量高质量的代码,但是很多代码没有数据结构的标签,不方便用户查询和学习,人工给海量代码打数据结构标签是不现实的,所以本发明提出自动给代码打数据结构标签的方法,解决了如何给代码自动打数据结构标签的问题,减轻了人工标注代码的工作量。
技术实现要素:
本发明提出一种自动给代码打数据结构标签的方法。使用词法分析器和语法分析器把代码转为抽象语法树,之后对每个词进行词嵌入,在树上使用残差块和注意力机制等方法从下到上对每个结点依次编码,最终得到根结点的编码,该编码既包括所有子结点的语法和语义表达,也包括自身结点的语义表达,最后使用根结点的表达进行分类,因为一段代码有可能包含多种数据结构,所以使用多个sigmoid分类器来得到多个数据结构标签。
本发明是一种自动给代码打数据结构标签的方法,包括以下步骤:
步骤1:使用爬虫技术从网页上收集大量标注数据结构的代码。
步骤2:由于不同的代码语法不一样,需要针对不同语言使用不同的词法分析器,使用词法分析器把代码中不同类型的变量替换为对应的词,词法分析器把1、1.1等数字替换为num;词法分析器把所有变量名替换为name;词法分析器所有字符串替换为str,其中词法分析器不会把语言对应的关键字替换。
步骤3:针对不同的语言使用对应的语法分析器,使用语法分析器把词法分析后的代码转为抽象语法树。
步骤4:对词法分析和语法分析后产生的词进行词嵌入,把num、name、根结点module和赋值运算assign等词进行词嵌入。
步骤5:使用同一个残差块reb对每个结点的嵌入编码进行非线性变换得到新的语义编码。
e′=rebq(e)=ln(w2·relu(w1·e)+e)
其中e为当前结点对应的嵌入编码,e∈rembedding_size,embeddingsize为每个结点嵌入的维度,w1∈rd_i×embedding_size,w2∈rembedding_size×d_i,d_i为超参数,relu是relu激活函数,ln是层次归一化,reb为残差块。
步骤6:在树上从下到上对非叶子结点进行编码,使用注意力机制计算当前结点下所有子结点与当前结点最相关的语义表达。
vc=a·ht
a=softmax(score(q,h))
其中q为n个相同当前结点通过残差块变换后的向量叠加后的矩阵,h为当前结点下n个子结点通过残差块变换后的向量叠加后的矩阵,score函数是计算当前结点表达与每个子结点表达的相似度,相似度越高,softmax后概率越大,score函数可以通过三种方式来计算当前结点与子结点的相似度,vc为注意力表达。
再把注意力向量与当前结点向量融合形成新的当前结点的向量表达,现在当前结点的向量表达既包括自己本身的语义表达,也包括所有子结点的语义表达。如下面的公式:
e″=relu(rebq(e′)+rebc(vc)+b)
其中e’为当前结点的向量编码,vc为注意力向量,reb为残差块,b为偏值,relu为relu激活函数,e”为e’当前结点向量编码使用残差块编码与vc注意力向量编码使用残差块编码融合后的向量编码。
步骤7:按照上面的公式,在树上从下到上计算每个结点的表达,最后使用根结点的表达进行分类,因为代码有可能属于多个类别,所以使用多个sigmoid分类器来得到多个数据结构的标签。
yi=sigmoid(w2·relu(w1·e′r)+b)
其中e’r为根结点的语义表达,w1和w2为参数,b为偏值,relu为relu激活函数,sigmoid为sigmoid函数。
步骤8:训练模型,使用大量标数据结构代码来训练整体模型,首先使用词法分析器对这段代码进行词法分析,把1、1.1等数字替换为num,把所有变量名替换为name,把所有字符串替换为str,使用语法分析器把词法分析后的代码转为抽象语法树,把抽象语法树中每个结点进行嵌入,也就是把结点找到对应的实维向量,使用残差块对每个结点的嵌入编码进行非线性变换得到新的语义编码。如下面公式:
e′=rebq(e)=ln(w2·relu(w1·e)+e)
其中e为当前结点对应的嵌入编码,e∈rembedding_size,embeddingsize为每个结点嵌入的维度,w1∈rd_i×embedding_size,w2∈rembedding_size×d_i,d_i为超参数,relu是relu激活函数,ln是层次归一化,reb为残差块。
在树上从下到上对非叶子结点进行编码,使用注意力机制计算当前结点下所有子结点与当前结点最相关的语义表达。
vc=a·ht
a=softmax(score(q,h))
q为n个相同当前结点通过残差块变换后的向量叠加后的矩阵,h为当前结点下n个子结点通过残差块变换后的向量叠加后的矩阵,score函数是计算当前结点表达与每个子结点表达的相似度,相似度越高,softmax后概率越大,score函数可以通过三种方式来计算当前结点与子结点的相似度,vc为注意力表达。
再把注意力向量与当前结点向量融合形成新的当前结点的向量表达,现在当前结点的向量表达既包括自己本身的语义表达,也包括所有子结点的语义表达。如下面的公式:
e′=relu(rebq(e′)+rebc(vc)+b)
e’为当前结点的向量与注意力向量vc融合后的表达。
最后使用根结点的编码进行分类,因为代码有可能属于多个类别,所以使用多个sigmoid分类器来得到多个数据结构的标签。
yi=sigmoid(w2·relu(w1·e′r)+b)
e’r为根结点的语义表达,relu为relu激活函数,sigmoid为sigmoid函数。
根结点的编码通过sigmoid函数有预测概率与真实概率差会产生损失值。再通过反向梯度传播来更新每个参数,进而达到训练的作用。
步骤9:使用训练好的模型对新的代码进行预测,来了一段新代码,使用词法分析器对这段新代码进行词法分析,把1、1.1等数字替换为num,把所有变量名替换为name,把所有字符串替换为str,使用语法分析器把词法分析后的代码转为抽象语法树,把抽象语法树中每个结点进行嵌入,如num、name等结点进行嵌入,也就是把结点找到对应的实维向量,使用残差块对每个结点的向量进行编码,得到新的编码,再使用注意力机制从下到上依次对每个结点进行编码,最后使用根结点的编码来分类,由于使用多个sigmoid分类器,会判断为多个数据结构,如果其中一个分类器预测某个标签概率大于50%,那么这段代码属于这个类别,也可以设置一个阈值,如预测概率高于70%,才认为这段代码属于这个类别。
附图说明
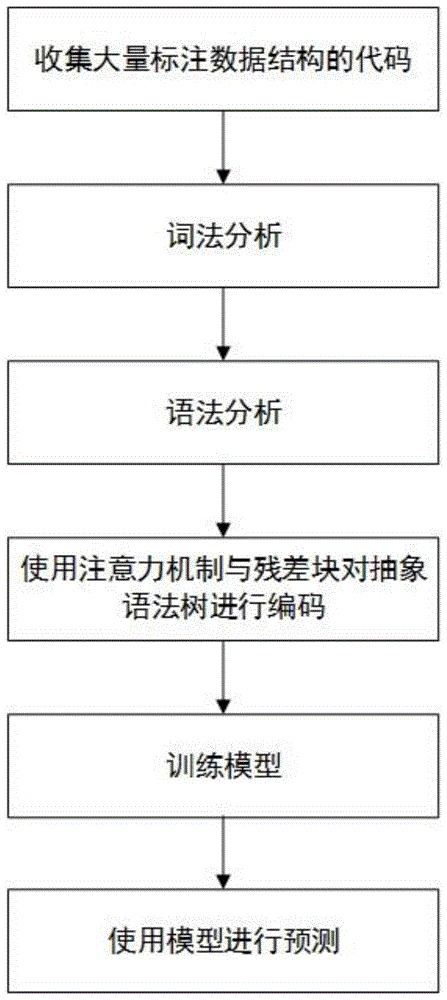
图1为本发明的流程示意图。
图2为a=b+c代码的抽象语法树示意图。
图3为抽象语法树编码的示意图。
具体实施方式
现在结合附图对本发明作进一步详细的说明。这些附图均为简化的示意图,仅以示意方式说明本发明的基本结构,因此其仅显示与本发明有关的构成。
图1示出了一种自动给代码打数据结构标签的方法的流程图,包括:
第一步使用爬虫技术从各种博客、论坛等网上收集大量有数据结构的代码;
第二步使用词法分析器对代码进行词法分析,把1、1.1等数字替换为num,把所有变量名替换为name,把所有字符串替换为str,其中词法分析器不把语言对应的关键字替换;
第三步使用语法分析器对代码进行语法分析,把代码转为抽象语法树;
第四步使用残差块对抽象语法树中每个结点进行编码,每个结点得到通过残差块编码后的新的编码,再使用注意力机制在树上从下到上依次对每个结点进行编码,把每个结点的所有子结点和当前结点的信息进行融合,该结点既有所有子结点的语义编码又有当前结点的语义编码,从下到上一层一层编码,直到对树上根结点进行编码后结束;
第五步训练模型,使用大量标数据结构代码来训练整体模型,首先使用词法分析器对这段代码进行词法分析,把1、1.1等数字替换为num,把所有变量名替换为name,把所有字符串替换为str,使用语法分析器把词法分析后的代码转为抽象语法树,把抽象语法树中每个结点进行嵌入,也就是把结点找到对应的实维向量,使用残差块对每个结点的嵌入编码进行非线性变换得到新的语义编码。如下面公式:
e′=rebq(e)=ln(w2·relu(w1·e)+e)
其中e为当前结点对应的嵌入编码,e∈rembedding_size,embeddingsize为每个结点嵌入的维度,w1∈rd_i×embedding_size,w2∈rembedding_size×d_i,d_i为超参数,relu是relu激活函数,ln是层次归一化,reb为残差块。
在树上从下到上对非叶子结点进行编码,使用注意力机制计算当前结点下所有子结点与当前结点最相关的语义表达。
vc=a·ht
a=softmax(score(q,h))
q为n个相同当前结点通过残差块变换后的向量叠加后的矩阵,h为当前结点下n个子结点通过残差块变换后的向量叠加后的矩阵,score函数是计算当前结点表达与每个子结点表达的相似度,相似度越高,softmax后概率越大,score函数可以通过三种方式来计算当前结点与子结点的相似度,vc为注意力表达。
再把注意力向量与当前结点向量融合形成新的当前结点的向量表达,现在当前结点的向量表达既包括自己本身的语义表达,也包括所有子结点的语义表达。如下面的公式:
e′=relu(rebq(e′)+rebc(vc)+b)
e’为当前结点的向量与注意力向量vc融合后的表达。
最后使用根结点的编码进行分类,因为代码有可能属于多个类别,所以使用多个sigmoid分类器来得到多个数据结构的标签。
yi=sigmoid(w2·relu(w1·e′r)+b)
e’r为根结点的语义表达,relu为relu激活函数,sigmoid为sigmoid函数。
根结点的编码通过sigmoid函数有预测概率与真实概率差会产生损失值。再通过反向梯度传播来更新每个参数,进而达到训练的作用。
第六步使用训练好的模型对新的代码进行预测,来了一段新代码,使用词法分析器对这段新代码进行词法分析,把1、1.1等数字替换为num,把所有变量名替换为name,把所有字符串替换为str,使用语法分析器把词法分析后的代码转为抽象语法树,把抽象语法树中每个结点进行嵌入,如num、name等结点进行嵌入,也就是把结点找到对应的实维向量,使用残差块对每个结点的向量进行编码,得到新的编码,再使用注意力机制从下到上依次对每个结点进行编码,最后使用根结点的编码来分类,由于使用多个sigmoid分类器,会判断为多个数据结构,如果其中一个分类器预测某个标签概率大于50%,那么这段代码属于这个类别,也可以设置一个阈值,如预测概率高于70%,才认为这段代码属于这个类别。
图2示出了a=b+c代码的抽象语法树示意图,其中包括module、assign、name、store、binop、load、add名称。下面依次来介绍一下,module为根结点,所有代码的开始;assign为赋值符号,具体是a=b+c代码中=;name为变量名的抽象名称,具体不清楚是哪一个变量,但是从代码中可以看出,是a、b、c变量;store为存储符号,把b+c计算后的值赋值给a,并存在内存当中;binop为二元操作,如加法、减法、乘法、除法;load为加载符号,加载某个变量的值;add为加法符号,把两个变量的值相加。
图2中a=b+c代码的抽象语法树流程为先给module根结点,有多少行代码那module根结点下就有多少个子结点,现在只有一行代码,这a=b+c代码主要在做赋值运算,那module根结点下有了assign赋值结点,assign赋值结点有左子树和右子树,左子树代表赋值给某一个变量,也就是a=b+c中等号左边的变量,右子树代表a=b+c中等号右边的符号,assign赋值结点左子结点为name代表赋值给name这个变量值,name下子结点为store存储结点,代表把等式右边的值赋值给左边并且存储到内存当中。
assign赋值结点右子结点有binop二元操作符号,代表下面有可能有加法、减法、乘法、除法。binop二元操作符号下有add加法符号代表该代码等号右边为加法运算,add加法符号左边name变量符号为代码a=b+c中b变量,该变量符号下面子结点为load加载符号,说明需要使用b变量中的值来进行计算。add加法符号右边name变量符号为代码a=b+c中c变量,该变量符号下面子结点为load加载符号,说明需要使用c变量中的值来进行计算。
在抽象语法树中,module为根结点,assign为赋值结点,先计算右边的binop二元操作符号,把name变量符号代表b变量,load把b变量中的值取出来,再把另一个name变量符号代表c变量,load把c变量中的值取出来,把两个变量的值进行运算,再看add加法符号把b变量中的值与c变量中的值相加,相加后通过assign赋值符号,把计算得到的值赋值给name变量符号,具体为a=b+c代码中a变量,赋值给a变量后需要把a变量的值存储下来,需要使用store存储符号,最后store存储符号把赋值给a变量的值存储到内存当中。
图3示对抽象语法树编码的示意图,从下到上叙述,最下面叶子结点为nameembedding、addembedding、nameembedding,embedding代表对这些结点进行嵌入,也就是把结点转为实值向量,再对这三个结点使用残差块对这三个结点进行更进一步编码,得到这三个结点语义编码,下一步对binop二元操作结点进行嵌入embedding,把binop二元操作结点转为对应的实值向量,再使用残差块对binop结点进行编码。如下面的公式:
e′=rebq(e)=ln(w2·relu(w1·e)+e)
其中e为当前结点对应的嵌入编码,e∈rembedding_size,embeddingsize为每个结点嵌入的维度,w1∈rd_i×embedding_size,w2∈rembedding_size×d_i,d_i为超参数,relu是relu激活函数,ln是层次归一化,reb为残差块。
编码后使用注意力机制计算当前binop结点下所有子结点与当前binop结点最相关的语义表达。如下面的公式:
vc=a·ht
a=softmax(score(q,h))
q为n个相同当前结点通过残差块变换后的向量叠加后的矩阵,h为当前结点下n个子结点通过残差块变换后的向量叠加后的矩阵,score函数是计算当前结点表达与每个子结点表达的相似度,相似度越高,softmax后概率越大,score函数可以通过三种方式来计算当前结点与子结点的相似度,vc为注意力表达。
再把注意力机制得到binop结点下所有子结点的语义编码向量与残差块对binop结点的编码向量融合形成新的当前结点的向量表达,现在当前结点的向量表达既包括自己本身的语义表达,也包括所有子结点的语义表达。如下面的公式:
e′=relu(rebq(e′)+rebc(vc)+b)
e’为当前结点的向量与注意力向量vc融合后的表达。
现在得到binop二元操作结点的编码向量,然后对assginembedding结点的左子树编码,左子树只有nameembedding结点,就对name变量结点进行嵌入embedding,得到该结点的编码向量,与上面一样,使用残差块对nameembedding进行编码得到新的语义表达,assignembedding所有子结点都有编码向量了,现在对assign结点进行嵌入embedding,把assign结点转为实值向量,使用残差块对assignembedding结点向量进行重新编码得到新的语义表达。再使用注意力机制计算当前assignembedding结点下所有子结点与当前assignembedding结点最相关的语义表达。随后把注意力机制得到assignembedding结点下所有子结点的语义编码向量与残差块对assignembedding结点的编码向量融合形成新的当前结点的向量表达,现在当前结点的向量表达既包括自己本身的语义表达,也包括所有子结点的语义表达。
编码最后阶段,把module根结点进行嵌入embedding转为对应的实值向量,使用残差块对moduleembedding进行重新编码得到新的语义编码。再使用注意力机制计算当前moduleembedding结点下所有子结点与当前moduleembedding结点最相关的语义表达。随后把注意力机制得到moduleembedding结点下所有子结点的语义编码向量与残差块对moduleembedding结点的编码向量融合形成新的当前结点的向量表达。现在得到module结点的语义编码向量,它也代表整个代码的语义编码,下面把module结点的语义编码向量输入到多个sigmoid函数里面,每个sigmoid函数判断是否是某个数据结构。
下面结合附图,详细描述本发明的技术方案:
如图1所示,本发明的主要流程为:
步骤1:使用爬虫技术从网页上收集大量标注数据结构的代码。
步骤2:由于不同的代码语法不一样,需要针对不同语言使用不同的词法分析器,使用词法分析器把代码中不同类型的变量替换为对应的词,词法分析器把1、1.1等数字替换为num,词法分析器把所有变量名替换为name,词法分析器把所有字符串替换为str,其中词法分析器不会把语言对应的关键字替换。
步骤3:针对不同的语言使用对应的语法分析器,使用语法分析器把词法分析后的代码转为抽象语法树。如图2所示,使用pythonast工具器对a=b+c代码转为抽象语法树。
步骤4:对词法分析和语法分析后产生的词进行词嵌入,如num、name、根结点module、赋值运算assign等词进行词嵌入。
步骤5:使用同一个残差块reb对每个结点的嵌入编码进行非线性变换得到新的语义编码。
e′=rebq(e)=ln(w2·relu(w1·e)+e)
其中e为当前结点对应的嵌入编码,e∈rembedding_size,embeddingsize为每个结点嵌入的维度,w1∈rd_i×embedding_size,w2∈rembedding_size×d_i,d_i为超参数,relu是relu激活函数,ln是层次归一化,reb为残差块。
步骤6:在树上从下到上对非叶子结点进行编码,使用注意力机制计算当前结点下所有子结点与当前结点最相关的语义表达。
vc=a·ht
a=softmax(score(q,h))
q为n个相同当前结点通过残差块变换后的向量叠加后的矩阵,h为当前结点下n个子结点通过残差块变换后的向量叠加后的矩阵,score函数是计算当前结点表达与每个子结点表达的相似度,相似度越高,softmax后概率越大,score函数可以通过三种方式来计算当前结点与子结点的相似度,vc为注意力表达。
再把注意力向量与当前结点向量融合形成新的当前结点的向量表达,现在当前结点的向量表达既包括自己本身的语义表达,也包括所有子结点的语义表达。如下面的公式:
e′=relu(rebq(e′)+rebc(vc)+b)
e’为当前结点的向量与注意力向量vc融合后的表达。
步骤7:按照上面的公式,在树上从下到上计算每个结点的表达,最后使用根结点的表达进行分类,因为代码有可能属于多个类别,所以使用多个sigmoid分类器来得到多个数据结构的标签。
yi=sigmoid(w2·relu(w1·e′r)+b)
e’r为根结点的语义表达,relu为relu激活函数,sigmoid为sigmoid函数。
步骤8:训练模型,使用大量标数据结构代码来训练整体模型,使得模型对任何代码判断,准确率达到50%以上,所有带数据结构的代码训练模型一次为一个epoch,其中一段代码训练一次模型的流程为提供一段代码,使用词法分析器对这段代码进行词法分析,把1、1.1等数字替换为num,把所有变量名替换为name,把所有字符串替换为str,使用语法分析器把词法分析后的代码转为抽象语法树,把抽象语法树中每个结点进行嵌入,也就是把结点找到对应的实维向量,使用残差块对每个结点的嵌入编码进行非线性变换得到新的语义编码。如下面公式:
e′=rebq(e)=ln(w2·relu(w1·e)+e)
其中e为当前结点对应的嵌入编码,e∈rembedding_size,embeddingsize为每个结点嵌入的维度,w1∈rd_i×embedding_size,w2∈rembedding_size×d_i,d_i为超参数,relu是relu激活函数,ln是层次归一化,reb为残差块。
在树上从下到上对非叶子结点进行编码,使用注意力机制计算当前结点下所有子结点与当前结点最相关的语义表达。
vc=a·ht
a=softmax(score(q,h))
q为n个相同当前结点通过残差块变换后的向量叠加后的矩阵,h为当前结点下n个子结点通过残差块变换后的向量叠加后的矩阵,score函数是计算当前结点表达与每个子结点表达的相似度,相似度越高,softmax后概率越大,score函数可以通过三种方式来计算当前结点与子结点的相似度,vc为注意力表达。
再把注意力向量与当前结点向量融合形成新的当前结点的向量表达,现在当前结点的向量表达既包括自己本身的语义表达,也包括所有子结点的语义表达。如下面的公式:
e′=relu(rebq(e′)+rebc(vc)+b)
e’为当前结点的向量与注意力向量vc融合后的表达。
最后使用根结点的编码来分类,根结点的编码通过sigmoid函数有预测概率与真实概率差会产生损失值,再通过反向梯度传播来更新每个参数,进而达到训练的作用。
步骤9:使用训练好的模型对新的代码进行预测,来了一段新代码,使用词法分析器对这段新代码进行词法分析,把1、1.1等数字替换为num,把所有变量名替换为name,把所有字符串替换为str,使用语法分析器把词法分析后的代码转为抽象语法树,把抽象语法树中每个结点进行嵌入,如num、name等结点进行嵌入,也就是把结点找到对应的实维向量,使用残差块对每个结点的向量进行编码,得到新的编码,再使用注意力机制从下到上依次对每个结点进行编码,最后使用根结点的编码来分类,由于使用多个sigmoid分类器,会判断为多个数据结构,如果其中一个分类器预测某个标签概率大于50%,那么这段代码属于这个类别,也可以设置一个阈值,如预测概率高于70%,才认为这段代码属于这个类别。
上对本发明实施所提供的一种自动给代码打数据结构标签的方法进行了详细地介绍,本文对本发明的原理和实施方式进行了阐述,以上实施的说明只是用于辅助理解本发明的方法及其核心思想。
- 还没有人留言评论。精彩留言会获得点赞!