一种基于知识图谱的暗网话题发现方法和系统与流程
本发明涉及大数据挖掘技术领域,尤其涉及一种基于知识图谱的暗网话题发现方法和系统。
背景技术:
如今,全球已有超过一半人口在使用互联网,但是用户通常所使用的facebook、twitter、youtube、微博等“明网”只是整个互联网的表层部分,而全球互联网绝大部分实际上都是不能被用户通过搜索引擎检索到的,这一部分被称之为“深网”,而“暗网”又是“深网”中可以提供匿名服务与匿名访问的更深层次的互联网络,需要特定的技术手段才可访问暗网。目前正在受到各国政府、企业、公安部门越来越多关注的利用互联网海量异构数据进行话题发现与舆情分析的系统也主要是集中在明网层面,对暗网上的数据进行话题发现与舆情分析往往能产生更具有价值的信息,其发现和分析结果能够对社会安全稳定和经济健康发展产生巨大的情报价值。
现有进行互联网话题发现的技术主要是对可被搜索引擎检索到的web页面进行爬取,然后对网页内容进行相似度计算和聚类分析,或者对web文本内容进行词的共现分析和LDA主题模型算法。相似度计算主要有基于距离的相似度计算、余弦相似度计算、编辑距离相似度计算和Jaccard相似性计算等,聚类主要有K均值聚类、层次聚类、基于密度的聚类等,而共现词分析主要就是关键词词频和共词分析,构建关键词共现网络来发现核心热点词以及话题,LDA主题模型算法根据文档中的各个单词,推测其主题的概率分布,从而确定文档的主题,利用各个文档的主题分布进行话题发现。
但是由于暗网空间中存在大量的黑话导致暗网的话题更加隐秘,上述技术没有充分考虑暗网黑话特定的语义信息,不能实现对拥有众多黑话的暗网空间内容信息的充分提取,另外暗网空间的数据更加稀疏、碎片化,并且由于暗网黑话的大量存在导致数据也呈现出弱信号特点,上述技术对于非常稀疏和弱信号的数据不能直接进行有效处理,也不能对这些数据进行弱关联分析,同时现有的技术只能针对已有的话题进行分析发现,不能进行话题的推理从而预测新兴话题。
技术实现要素:
本发明提供了一种基于知识图谱的暗网话题发现方法和系统,以解决现有技术不能实现对拥有众多黑话的暗网空间内容信息的充分提取,以及无法对非常稀疏和弱信号的数据直接进行有效处理的技术问题,从而通过构建知识图谱对黑话表示的弱信号数据进行关联关系分析,实现暗网话题的发现、推理及预测,为暗网舆情处理和情报分析提供有价值的信息。
为了解决上述技术问题,本发明实施例提供了一种基于知识图谱的暗网话题发现方法,包括:
对获取的暗网数据进行web页面去重,通过算法对存在同一个页面采集了多次的数据进行去重处理;
将去重处理后的所述暗网数据进行降维处理;
通过黑话词典和文档/段落/句子的向量表示配合词向量表示,对降维后的所述暗网数据进行黑话检测识别;
对检测到黑话后的数据进行自然语言处理,提取出弱信号数据的实体、属性、关系和事件;
根据自然语言处理提取的弱信号数据构造事实三元组,构建事件知识图谱;
在所述事件知识图谱中通过图匹配和遍历实现弱信号数据间的关联发现,并通过所述事件知识图谱中的弱信号关联和节点中心性计算实现核心话题的发现。
作为优选方案,在所述对获取的暗网数据进行web页面去重,通过算法对存在同一个页面采集了多次的数据进行去重处理之后,还包括:通过字符串匹配与字典法对与暗网黑话检测无关的停用词进行消除。
作为优选方案,所述通过黑话词典和文档/段落/句子的向量表示配合词向量表示,对降维后的所述暗网数据进行黑话检测识别,包括:
将采集的所述暗网数据作为黑话语料集和正常使用语料集作为训练样本进行黑话和正常使用情况下词语的词向量表示的联合训练;
将所述黑话语料集和所述正常使用语料集中的同一个词根据各自的数据集,在权重方面,从训练过程中的输入到隐藏层,建立各自的关系,同时确保两个语料集中的词的上下文相结合,并通过隐藏层共同贡献神经网络的输出。
作为优选方案,所述训练样本还包括正常使用情况下的语料集和词语原意语料集。
作为优选方案,所述自然语言处理包括分词、命名实体识别、实体及属性对齐与消歧、事件抽取和关系抽取。
作为优选方案,所述分词用于对包含黑话的文本内容按词义进行切分,以使每一个词都有其独立的语义;
所述命名实体识别用于通过算法确定文本内容的各个实体,包括人名、地点、时间日期、机构和产品;
所述实体对齐用于通过属性相似性计算得分根据其属性信息将不同来源的实体映射到统一的实体对象上;
所述实体消歧用于对具有一词多义的实体确定其在当前上下文环境下的真正含义,实现构建知识图谱时不会发生歧义;
所述事件抽取用于将人工标注数据自动生成大规模标注数据并进行事件抽取;
所述事件关系抽取用于计算事件指称的文本语义相似度和事件类型与事件元素之间的相似度。
作为优选方案,所述节点的中心性包括度数中心度、中间中心度、接近中心度和特征值中心度。
作为优选方案,所述通过所述事件知识图谱中的弱信号关联和节点中心性计算实现核心话题的发现,包括:
计算所述事件知识图谱的中心性,得到第一话题发现结果;
根据iMLDA算法对网页内容进行计算,得到第二话题发现结果;
判断所述第一话题发现结果和所述第二话题发现结果中的相同数量是否超过预设的阈值,若是,则根据所述第一话题发现结果和所述第二话题发现结果中相同数量的发现结果直接确定为暗网话题;
若否,则通过所述第一话题发现结果和所述第二话题发现结果及其相关的三元组构造话题知识图谱,重复计算所述话题知识图谱的中心性得到最终的暗网话题。
作为优选方案,在得到最终的暗网话题之后,还包括:在所述事件知识图谱或通过得到的所述话题知识图谱上,进行关联规则挖掘总结出逻辑规则,应用得到的所述逻辑规则进行自动推理实现对暗网话题的推理预测。
本发明实施例还提供了一种基于知识图谱的暗网话题发现系统,包括:
数据预处理与降维模块,包括预处理子模块和降维子模块;所述预处理子模块用于对获取的暗网数据进行web页面去重,通过算法对存在同一个页面采集了多次的数据进行去重处理;所述降维子模块用于将去重处理后的所述暗网数据进行降维处理;
检测识别模块,用于通过黑话词典和文档/段落/句子的向量表示配合词向量表示,对降维后的所述暗网数据进行黑话检测识别;
知识图谱构建与话题发现模块,包括自然语言处理子模块、构建图谱子模块和话题发现子模块;所述自然语言处理子模块用于对检测到黑话后的数据进行自然语言处理,提取出弱信号数据的实体、属性、关系和事件;所述构建图谱子模块用于根据自然语言处理提取的弱信号数据构造事实三元组,构建事件知识图谱;所述话题发现子模块用于在所述事件知识图谱中通过图匹配和遍历实现弱信号数据间的关联发现,并通过所述事件知识图谱中的弱信号关联和节点中心性计算实现核心话题的发现。
相比于现有技术,本发明实施例具有如下有益效果:
本发明的目的是针对暗网空间数据更加稀疏和碎片化,且存在大量黑话的情况,对高度稀疏和碎片化的数据采用降维处理,利用暗网黑话语料集构建黑话字典,并使用分布式词表示技术实现对暗网黑话、行话的特征检测和识别,利用检测出的暗网黑话以及对应抽取的实体、事件和关系构建知识图谱,实现对黑话表示的弱信号数据进行关联关系分析,进一步实现暗网话题的发现、推理及预测,为暗网舆情处理和情报分析提供有价值的信息。
附图说明
图1:为本发明实施例的基于知识图谱的暗网话题发现方法流程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
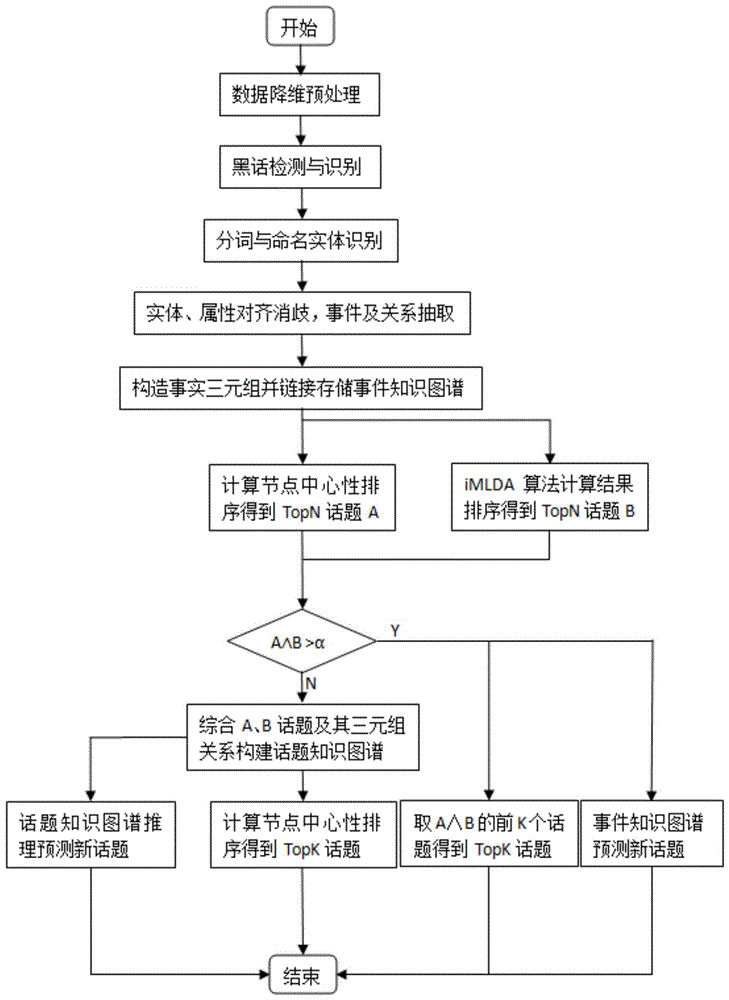
请参照图1,本发明优选实施例提供了一种基于知识图谱的暗网话题发现方法,包括:
S1,对获取的暗网数据进行web页面去重,通过算法对存在同一个页面采集了多次的数据进行去重处理;
S2,将去重处理后的所述暗网数据进行降维处理;
S3,通过黑话词典和文档/段落/句子的向量表示配合词向量表示,对降维后的所述暗网数据进行黑话检测识别;
S4,对检测到黑话后的数据进行自然语言处理,提取出弱信号数据的实体、属性、关系和事件;
S5,根据自然语言处理提取的弱信号数据构造事实三元组,构建事件知识图谱;
S6,在所述事件知识图谱中通过图匹配和遍历实现弱信号数据间的关联发现,并通过所述事件知识图谱中的弱信号关联和节点中心性计算实现核心话题的发现。
在本实施例中,在所述对获取的暗网数据进行web页面去重,通过算法对存在同一个页面采集了多次的数据进行去重处理之后,还包括:通过字符串匹配与字典法对与暗网黑话检测无关的停用词进行消除。
在本实施例中,所述通过黑话词典和文档/段落/句子的向量表示配合词向量表示,对降维后的所述暗网数据进行黑话检测识别,包括:
将采集的所述暗网数据作为黑话语料集和正常使用语料集作为训练样本进行黑话和正常使用情况下词语的词向量表示的联合训练;
将所述黑话语料集和所述正常使用语料集中的同一个词根据各自的数据集,在权重方面,从训练过程中的输入到隐藏层,建立各自的关系,同时确保两个语料集中的词的上下文相结合,并通过隐藏层共同贡献神经网络的输出。
在本实施例中,所述训练样本还包括正常使用情况下的语料集和词语原意语料集。
在本实施例中,所述自然语言处理包括分词、命名实体识别、实体及属性对齐与消歧、事件抽取和关系抽取。
在本实施例中,所述分词用于对包含黑话的文本内容按词义进行切分,以使每一个词都有其独立的语义;
所述命名实体识别用于通过算法确定文本内容的各个实体,包括人名、地点、时间日期、机构和产品;
所述实体对齐用于通过属性相似性计算得分根据其属性信息将不同来源的实体映射到统一的实体对象上;
所述实体消歧用于对具有一词多义的实体确定其在当前上下文环境下的真正含义,实现构建知识图谱时不会发生歧义;
所述事件抽取用于将人工标注数据自动生成大规模标注数据并进行事件抽取;
所述事件关系抽取用于计算事件指称的文本语义相似度和事件类型与事件元素之间的相似度。
在本实施例中,所述节点的中心性包括度数中心度、中间中心度、接近中心度和特征值中心度。
在本实施例中,所述通过所述事件知识图谱中的弱信号关联和节点中心性计算实现核心话题的发现,包括:
计算所述事件知识图谱的中心性,得到第一话题发现结果;
根据iMLDA算法对网页内容进行计算,得到第二话题发现结果;
判断所述第一话题发现结果和所述第二话题发现结果中的相同数量是否超过预设的阈值,若是,则根据所述第一话题发现结果和所述第二话题发现结果中相同数量的发现结果直接确定为暗网话题;
若否,则通过所述第一话题发现结果和所述第二话题发现结果及其相关的三元组构造话题知识图谱,重复计算所述话题知识图谱的中心性得到最终的暗网话题。
在本实施例中,在得到最终的暗网话题之后,还包括:在所述事件知识图谱或通过得到的所述话题知识图谱上,进行关联规则挖掘总结出逻辑规则,应用得到的所述逻辑规则进行自动推理实现对暗网话题的推理预测。
本发明实施例还提供了一种基于知识图谱的暗网话题发现系统,包括:
数据预处理与降维模块,包括预处理子模块和降维子模块;所述预处理子模块用于对获取的暗网数据进行web页面去重,通过算法对存在同一个页面采集了多次的数据进行去重处理;所述降维子模块用于将去重处理后的所述暗网数据进行降维处理;
检测识别模块,用于通过黑话词典和文档/段落/句子的向量表示配合词向量表示,对降维后的所述暗网数据进行黑话检测识别;
知识图谱构建与话题发现模块,包括自然语言处理子模块、构建图谱子模块和话题发现子模块;所述自然语言处理子模块用于对检测到黑话后的数据进行自然语言处理,提取出弱信号数据的实体、属性、关系和事件;所述构建图谱子模块用于根据自然语言处理提取的弱信号数据构造事实三元组,构建事件知识图谱;所述话题发现子模块用于在所述事件知识图谱中通过图匹配和遍历实现弱信号数据间的关联发现,并通过所述事件知识图谱中的弱信号关联和节点中心性计算实现核心话题的发现。
下面结合具体实施例,对本发明进行详细说明。
本发明涉及人工智能领域的自然语言处理和知识图谱方向,具体涉及一种面向暗网数据的话题发现、追踪及预测的方法和系统。
暗网数据预处理与降维
数据预处理:这一阶段主要是对获取的暗网数据进行web页面去重,比如可能存在同一个页面采集了多次,就需要对该页面去重处理,这里采用局部敏感哈希算法对网页进行去重。再者是对无用信息进行清除,例如将与暗网黑话检测无关的停用词消除掉,这一步采用字符串匹配与字典法实现。
简单预处理后的暗网数据相对于日常表层网络的数据还是非常稀疏和碎片化,不能直接用于黑话的检测识别,所以需要对数据进行降维处理,降维的同时也能够帮助寻找暗网弱信号数据内部的本质结构特征。本专利所采用的高维数据降维方法主要是局部线性逼近(Locally Linear Approximating,LLA)算法,其能够找到一个在平均意义上保留原数据点局部特性到低维空间的映射,实现良好的降维效果。
黑话检测与识别
数据降维之后,需要进行暗网黑话的检测与识别。暗网黑话的特点是这些词看起来都是非常正确的词,比如popcorn(爆米花)、blueberry(蓝莓)、orange(橘子)等,同时黑话在使用上与正常情况下的使用形式很相似,比如sell popcorns(卖爆米花)与正常情况下popcorn(爆米花)的上下文搭配类似,所以很难用传统方法进行识别,这也是暗网数据呈现非常弱信号化的原因之一。本专利采用黑话词典和doc2vec(文档/段落/句子的向量表示)配合word2vec(词向量表示)的方法实现黑话的检测与识别。黑话语料集、正常使用语料集作为训练样本进行黑话和正常使用情况下词语的word2vec的联合训练,为了避免正常语料下所使用的单词语义有可能已经在词典中原意的基础上进行了延伸,所以正常使用情况下的语料集和词语原意语料集也作为训练样本进行正常情况下词语和原意词语的word2vec的联合训练,具体训练过程是让两个不同语料库中的同一个词根据各自的数据集,在权重方面,从训练过程中的输入到隐藏层,建立各自的关系,同时确保两个语料库中的词的上下文相结合,并通过隐藏层共同贡献神经网络的输出。
为了进行联合训练,需要对输入形式也做一下改变。输入的one-hot形式表示为:
Vzero是全为0的V维度大小的向量,Vonehot()是w在输入语料里标准的ont-hot向量,这使得两个语料库的单词都表示为统一2V大小维度的ont-hot向量,满足联合训练维度大小的一致性,同时避免了直接将两个语料混在一起使用one-hot表示而导致语义丢失和干扰。计算训练出来黑话词向量与正常使用时的词向量相似性S1,计算正常使用的词向量与词原意的词向量的相似性S2,S1小于阈值α1,S2大于阈值α2,则检测为黑话,并根据黑话字典判定黑话的准确语义,对阈值α1与α2的确定,采用doc2vec算法计算两个语料库分别的句向量,计算包含同一个词的句向量间的相似度,根据相似度大小确定α1、α2的值。
知识图谱构建与话题发现
知识图谱构建主要分为两个步骤,首先是对检测到黑话后的数据进行自然语言处理,提取出弱信号数据的实体、属性、关系和事件,最后进行知识图谱的构建。
自然语言处理:这一步包括分词、命名实体识别、实体及属性对齐与消歧、事件抽取和关系抽取等一系列操作。分词对包含黑话的文本内容按词义进行切分,分词后的结果是每一个词都有其独立的语义;命名实体识别用于确定文本内容的各个实体,包括人名、地点、时间日期、机构、产品等,这里实体识别采用的是双向的LSTM算法实现,实体对齐是根据其属性信息将不同来源的实体映射到统一的实体对象上,实体消歧则是对具有一词多义等情况的实体确定其在当前上下文环境下的真正含义,实现构建知识图谱时不会发生歧义,实体对齐主要通过属性相似性计算得分实现,实体消歧使用基于实体链接的实体消歧方法实现,属性的对齐是通过属性值embedding后计算相似性实现,属性消歧则通过外链验证实现;事件抽取基于Distant Supervision(远程监督)的方法实现,远程监督的方法只需要少量人工标注数据就能自动生成大规模标注数据并进行事件抽取;这里的事件关系抽取主要是指事件共指关系抽取,主要采用的方法是计算事件指称的文本语义相似度和事件类型与事件元素之间的相似度。整个自然语言处理过程采用NLTK和Stanford CoreNLP工具包实现基础操作。
话题知识图谱构建:根据自然语言处理得到的实体、事件等构造事实三元组<subject,predicate,object>,也即是RDF(Resource Description Framework),通过图数据库Neo4j存储RDF。根据得到的所有RDF通过关系链接构建出事件知识图谱,在事件知识图谱中通过图匹配和遍历可以实现弱信号数据间的关联发现,并且通过知识图谱中的弱信号关联和节点中心性计算实现核心话题的发现,节点的中心性包括度数中心度、中间中心度、接近中心度和特征值中心度,度数中心度测量的是一个点与其他点发展联系的能力,一个点控制网络中其他节点之间相互联系的能力是通过中间中心度和接近中心度来测量的。度数中心度和中间中心度越高,接近中心度越小的节点在网络中的地位越高,越可能处于网络核心,拥有的控制优势越大,是主要话题的可能性也就越大。具体的在知识图谱上的话题发现为以下步骤:
步骤1:计算知识图谱的中心性,选出发现的前TopN个话题;
步骤2:采用改进的用于社会网络话题发现的iMLDA算法实现对网页内容的话题发现,根据iMLDA算法的计算结果选出发现的前TopN个话题;
步骤3:如果步骤(1)(2)得到的话题相同数量超出了系统规定的阈值α则根据(1)(2)结果相同的前K个直接确定暗网话题TopK;
步骤4:若(1)(2)相同话题数低于阈值α,则用(1)(2)的TopN话题及其相关的三元组构造话题知识图谱,重复(1)的步骤得到最终的暗网话题TopK;
步骤5:在事件知识图谱或通过(4)得到的话题知识图谱基础上,进一步进行关联规则挖掘(具体的讲是频繁子图挖掘)总结出逻辑规则,应用得到的逻辑规则进行自动推理实现对暗网话题的推理预测。
本发明充分考虑了暗网数据更加稀疏、碎片化的特点,对高维稀疏的数据使用LLA算法实现精确降维,对于大量黑话的存在,对数据采用分布式词向量表示进行黑话检测,利用NLP技术抽取暗网事件三元组构建事件知识图谱实现弱信号数据关联,并结合iMLDA算法得到的话题,共同实现暗网话题发现,同时构建了话题知识图谱实现暗网话题的推理预测。
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步的详细说明,应当理解,以上所述仅为本发明的具体实施例而已,并不用于限定本发明的保护范围。特别指出,对于本领域技术人员来说,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!