一种基于抗噪移动时间势能聚类的文本分类方法与流程
本发明属于聚类分析和文本分类技术领域,涉及噪声环境下对复杂文本数据的文本分类方法;具体地说是一种基于抗噪移动时间势能聚类的文本分类方法,可用于信息检索、文本挖掘等系统中的文本分类。
背景技术:
随着大数据技术的蓬勃发展,海量的文本数据也在与日俱增,对这些文本数据进行分类和总结具有重大的应用价值。目前,文本分类已成为文本挖掘中研究的一个热点问题,已经受到国内外学者的广泛关注。从文本分类中获得的重要信息对于文本挖掘是非常重要的,可以从这些信息中挖掘出很多有用的信息。针对文本分类问题,目前的文本数据中存在大量的噪声数据,对文本分类技术提出了更高的要求,尤其是在噪声环境下对文本数据进行分类,已成为文本分类领域中具有挑战性的科学问题。
识别文本数据里的噪声数据是文本分类中需要解决的关键问题之一,传统的分类方法往往不具备识别数据集里的噪声数据的性能。噪声数据会影响文本的语义,因此在分类方法中具有识别噪声数据的能力是非常必要的,如果不对噪声数据进行处理,会造成后续的分类模型的复杂度过高。消除这些噪声数据可以大大减小文本特征空间的大小,有助于加快计算速度,提高文本分类的准确性。Joachims T提出采用SVM(支持向量机)方法对文本进行分类,Xiang Z等人提出采用卷积神经网络方法实现文本分类,Lu等人提出采用移动时间层次聚类方法(TTHC)对文本数据进行分类,这些方法对于文本数据中的噪声数据不能进行识别并去除,会把噪声数据和非噪声数据混在一起,很难正确的对文本数据分类;此外,由于这些方法对复杂数据的聚类效果一般,会影响文本分类的准确性。
技术实现要素:
针对上述问题,本发明提出一种基于抗噪移动时间势能聚类的文本分类方法,以解决文本数据量庞杂的情况下,噪声数据较多的文本分类问题,能够准确识别并去除文本数据中的噪声数据,以提高文本分类的精度,满足实际工程系统的设计需求。
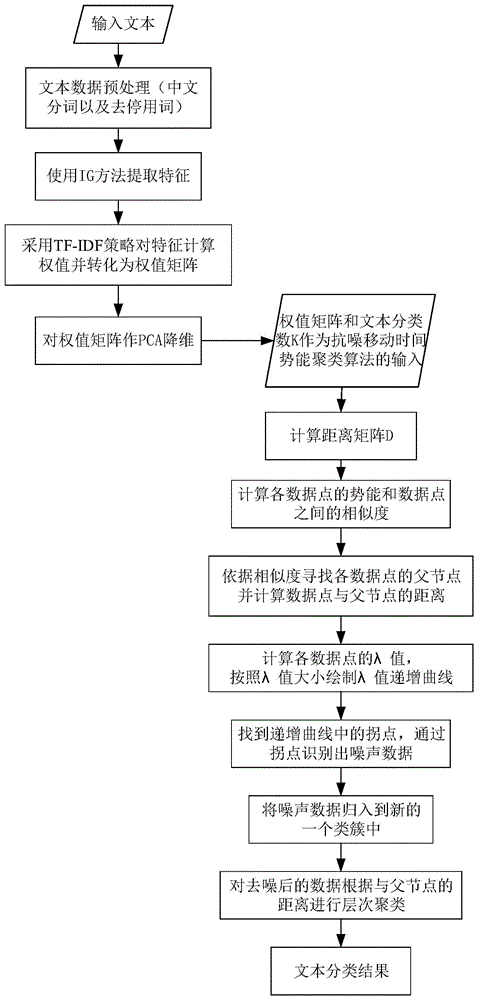
实现本发明的关键技术是:采用结巴分词和去停用词的方法对文本数据预处理,然后基于信息增益IG(Information Gain)方法对预处理后的文本数据提取特征,并使用TF-IDF(Term Frequency–Inverse Document Frequency)策略计算各个特征的权值,最后对经过主成分分析PCA降维后的权值矩阵采用抗噪移动时间势能聚类算法对其进行分类。
本发明的技术方案:
一种基于抗噪移动时间势能聚类的文本分类方法,步骤如下:
(1)对待分类文本数据进行预处理,包括中文分词以及去停用词:
(1a)采用结巴分词对文本数据进行中文分词;
(1b)使用停用词表对分词后的文本数据去除停用词;
(2)提取预处理后文本数据中的文本特征,并对文本特征进行权值计算:
(2a)使用信息增益IG方法对预处理后的文本进行特征提取;
(2b)针对提取后的特征,采用TF-IDF策略对特征进行权值计算并转化为权值矩阵;
(3)对权值矩阵作主成分分析PCA降维;
(4)将上述经过PCA降维之后的权值矩阵作为抗噪移动时间势能聚类算法的输入矩阵S,输入分类数K,实现文本数据的自动分类:
(4a)计算S代表的数据集的距离矩阵D:
其中rij是数据点之间的距离,i=1…n,j=1…n,n是文本数;
(4b)计算各数据点的势能Φi和数据点之间的相似度。数据点的势能Φi为:
其中Φij(rij)的计算方式为:
其中rij为点i到点j的欧氏距离,δ是用来防止rij为零,其计算方式为:
δ=mean(MinDi)i=1,2,…,n
其中MinDi是点i到其他各点的最小距离;mean是求平均值的函数。数据点之间的相似度为:
(4c)依据相似度寻找各数据点的父节点,其中父节点的定义为:
也就是势能值小于点i并且和点i相似度最大的数据点是点i的父节点,然后计算数据点与父节点的距离ρi:
ρi=ri,parent[i]
其中parent[i]是数据点i的父节点;
(4d)将数据点与父节点的距离和数据点的势能的绝对值的比定义为λ值,计算各数据点的λ值,λ值的计算公式为:
λi=ρi÷|Φi|=ρi÷(-Φi)i=1,2,…,n
按照λ值大小绘制λ值递增曲线,找到递增曲线中的拐点,通过拐点识别出噪声数据;
(4e)把识别出的噪声数据聚到新的一个类簇中;
(4f)对分离出噪声数据后的数据集,根据数据点与父节点的距离进行层次聚类,获得文本的分类结果。
步骤(4f)的具体过程如下:
(A)以各数据点与父节点的距离作为边缘加权树的权值,构建边缘加权树;按照势能值对各数据点升序排序,将势能最小的数据点作为边缘加权树的根节点,其余数据点寻找自身父节点;
(B)根据边缘加权树进行层次聚类获得分类结果。
本发明的有益效果:
(1)本发明方法对文本数据进行预处理,包含分词以及去除停用词,排除了一些无用词、表情符号等的影响,保证分类的准确性不受其影响;
(2)针对文本的主要特征,本发明方法选取了IG特征提取方法和TF-IDF策略来计算特征的权值,保证分类结果比较理想;
(3)本发明方法的抗噪移动时间势能聚类算法的抗噪性能使得分类的准确性更高,实现较为精准的文本数据分类。
附图说明
图1是本发明方法的整体流程图。
具体实施方式
一、基础理论介绍
1.文本分类
文本分类是最重要的文本挖掘方法之一,是用来帮助用户有效地归纳总结和组织文本文档。通过将大量文档组织成多个有意义的集群,文本分类可用于浏览一组文档或组织搜索引擎返回的结果,以响应用户的查询。它可以显著提高信息检索系统的查准率和召回率,是一种有效的查找和给定文档最相似文档的方法。文本分类问题一般定义如下:给定一组文档,目的是将它们划分为预先确定的或自动导出的集群数,这样分配给每个集群的文档之间尽可能的相似,分配给不同的集群的文档尽可能的相异。换句话说,一个集群中的文档共享同一个主题,而不同集群中的文档代表不同的主题。
在现有的文本分类算法中,文本是用向量空间模型来表示的,该模型是将文档看作一个词袋。这种表示方法的一个主要特点是特征空间的高维度,这对分类算法的性能提出了很大的挑战。由于数据的内在一致性,分类算法往往很难在高维特征空间中有效地工作。另一个问题是,并不是所有的特征对于文本分类都很重要。其中一些特征可能是多余的或是不相关的。有些特征甚至可以对分类结果产生错误干扰,特别是当有比相关特征更多的无关特征时。在这种情况下,选择初始特征的子集通常会有更好的分类效果。特征选择不仅降低了特征空间的维度,而且提供了更好的数据理解,提升了分类效果。所选的特征集应该包含关于原始数据集的足够或者可靠的信息。文本分类是关于识别一组文档中最具信息的词来进行分类的问题。
结巴分词(Jieba)是Python里一种中文分词工具,其基本实现原理有三点:基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG);采用动态规划查找最大概率路径,找出基于词频的最大切分组合;对于未登录词,采用基于汉字成词能力的HMM模型,使用了Viterbi算法。
2.信息增益(IG)特征提取方法和计算权值的TF-IDF策略以及PCA降维方法
信息增益(IG)是通过了解文档中存在或不存在某个词来衡量为类别预测而获得的信息量。对训练集中每个特征的IG数进行排序,以选择需要的一些重要特征词。信息增益(IG)度量一个特征为自动文本分类系统带来的信息量。某个特征的信息量越大,那么该特征就越重要。IG的计算公式为:
其中P(Cj)代表一个文档是类别Cj的概率,P(fi)代表文档中出现词fi的概率,而P(Cj|fi)代表包含词fi的文档是类别Cj的概率。
TF-IDF是一种数值统计方法,它允许确定每个文档中每个词的权重。TF-IDF方法常用于自然语言处理或信息检索和文本挖掘。TF-IDF方法确定权重,用于评估文档集合中词的重要性。计算TF与IDF的公式为:
∑knk,j表示文档中的总词数,ni,j表示词在一个文档中出现的次数,N为文档个数。而TF-IDF为tfi,j和idfi的乘积,由于文档长短不固定,在运用TF-IDF策略时,某个不重要的词可能会在一个长文档里出现多次,因此需要作归一化的处理,归一化之后如下:
ni,j表示含有特征项ti,j的文档个数,N是文档的总个数,M是文档di的特征项总数。特征向量里的各数值表示对应特征词在该文本向量中的权重,权重越大就表明该特征词在对应文本下的重要程度就越大。
主成分分析(PCA)是一种统计技术,PCA将高维数据分解为一个低维子空间成分和一个噪声分量,这种分解对于数据压缩是有用的。PCA的计算方式为:给定m个样本和n个标记或变量,m个样本可以表示为大小为m×n的矩阵X。进一步假设每个标记的样本均值为0,即利用n个向量或坐标轴的另一组基,表示为P的列向量,可以将样本投影到新的坐标轴上,得到另一个大小为m×n的矩阵Y=XP。PCA可以得到一个向量P,使得n个新变量的样本协方差矩阵是一个对角矩阵。
其中D是一个对角矩阵,∑Y和∑x分别是原始的样本协方差矩阵和新的n个变量。向量P可以通过对∑x的特征分解来获得。
二、本发明基于抗噪移动时间势能聚类的文本分类方法
参照图1,本发明的具体实施过程包括以下步骤:
步骤1.对待分类文本数据进行预处理,包括中文分词以及去停用词:
(1.1)采用结巴分词对文本数据进行中文分词;
(1.2)使用停用词表对分词后的文本数据去除停用词。停用词表选用的是哈工大停用词表(参见:官琴,邓三鸿,王昊.《中文文本聚类常用停用词表对比研究》.数据分析与知识发现,2017,1(03):76-84);
步骤2.提取预处理后的文本数据中的文本特征并对文本特征进行权值计算:
(2.1)使用IG方法对预处理后的文本进行特征提取;
(2.2)针对提取后的特征,采用TF-IDF策略对特征进行权值计算并转化为权值矩阵;
步骤3.对权值矩阵作PCA降维;
步骤4.将上述经过PCA降维之后的权值矩阵作为抗噪移动时间势能聚类算法的输入矩阵S,输入分类数K,实现文本数据的自动分类:
(4.1)计算矩阵S代表的数据集的距离矩阵D:
其中rij是数据点之间的欧式距离,i=1…n,j=1…n,n是文本数;
(4.2)计算各数据点的势能Φi和数据点之间的相似度;
(a)按照势能的物理意义,先计算各数据点的势能值。数据点之间的势能Φij定义为:
其中rij为点i到点j的欧氏距离,δ是用来防止rij为零,其计算方式为:
δ=mean(MinDi)i=1,2,…,n
其中MinDi是点i到其他各点的最小距离;mean是求平均值的函数。在得到每两个点之间的势能Φij后,那么数据点的势能Φi定义为:
(b)遵照牛顿运动定律,两个质点间引力大小为:
Fij=|Φi-Φj|÷rij
从而质点的加速度为:
其中m是质点的质量。因此在数据点i与数据点j之间质点移动所需的时间为:
基于计算得到的移动时间,那么数据点i和数据点j的相似度的定义为:
(4.3)依据相似度寻找各数据点的父节点,并计算数据点与父节点的距离ρi。各数据点的父节点的定义为:
换句话说数据点i的父节点就是势能值比数据点i小的数据点中和数据点i相似度最大的点。数据点与父节点的距离ρi为:
ρi=ri,parent[i]
(4.4)将数据点与父节点的距离和数据点的势能的绝对值的比定义为λ值,计算各数据点的λ值,按照λ值大小绘制λ值递增曲线,找到递增曲线中的拐点,通过拐点识别出噪声数据。各点的λ值计算方式为:
λi=ρi÷|Φi|=ρi÷(-Φi)i=1,2,…,n
其中ρi是数据点i到其父节点的距离,Φi是数据点i的势能值;
数据点的λ值是判别数据点是否为噪声数据的考量指标。我们通过构造λ值的递增曲线来识别数据集中的噪声数据点。由于数据集中噪声数据点的数量远少于正常数据点,且其分布比较稀疏,所以它们的势能值都比较大,而势能恒为负值,因此它们的势能绝对值都比较小;此外这些噪声数据点和父节点的距离也比较大,所以噪声数据点的λ值就会很大。相反,数据集中非噪声数据点往往分布较噪声数据点会更密集,其势能比噪声数据点的势能要小的多,其势能绝对值则要大的多;和数据集中的噪声数据点相比,这些非噪声数据点和父节点的距离也较小,所以非噪声数据点的λ值就比较小。通过绘制数据点的λ值递增曲线,可以在λ值的递增曲线上发现,噪声数据点和正常数据点之间会存在一个拐点,递增曲线上位于拐点前面的数据点为正常数据点,递增曲线上位于拐点后面的数据点为噪声数据点。
(4.5)把识别出的噪声数据聚到新的一个类簇中;
(4.6)对分离出噪声数据后的数据集根据数据点与父节点的距离作层次聚类,获得文本分类的结果。在层次聚类的过程中构建边缘加权树,按照势能值对各数据点升序排序,将势能最小的数据点作为边缘加权树的根节点,其余数据点寻找自身父节点,边缘加权树中的权值为数据点与父节点的距离。
本发明的效果可通过以下实验进一步说明。
1.仿真条件及参数
为了验证本发明方法的可行性与有效性,将本发明方法与TTHC方法、PHA方法、CSPV方法以及SVM方法进行对比分析。仿真实验中采用常用的聚类结果评价指标FM指标、F1-measure指标以及ARI指标。
FM评价指标的计算公式如下:
其中FN代表在R2中为同一类而在R1中非同一类的数据点对数量;TP代表在R1、R2中都为同一类的数据点对数量;FP代表在R1中是同一类而在R2中不是同一类的样本对数量;TN是在R1、R2中都不是同一类的样本对数量。FM的取值范围为[0,1],愈大的FM值表示愈优的聚类效果。
F1-measure评价指标,其计算公式如下:
其中N是数据集中数据点总数,Di代表D中真实分类是第i类的数量,Cj是C中聚类为第j类的数量,D代表原始数据集的真实类别序列,C为聚类算法取得的聚类类别序列。
P(Di,Cj)=Nij/Ni
R(Di,Cj)=Nij/Nj
ARI评价指标的计算公式为:
其中a、b、c、d所表示的含义和FM中的TP、FP、FN、TN类似,ARI聚类评价指标的最大值是1。ARI值越大表明算法的聚类效果越好。
2.仿真内容及结果分析
仿真实验中,将本发明方法与TTHC方法、PHA方法、CSPV方法以及SVM方法作对比。对从微博官网中下载的不实微博和热门微博进行分类,不实微博总数为750个,分为三个类别,见表1;热门微博个数为1000个,分为10个类别,见表2。分类结果如表3和表4所示。
表1不实微博分类
表2热门微博分类
表3各方法对不实微博分类的结果
表4各方法对热门微博分类的结果
表1给出了不实微博的分类信息。
表2给出了热门微博的分类信息。
表3给出了采用五种方法对不实微博进行分类的结果。
表4给出了采用五种方法对热门微博进行分类的结果。
从表3和表4可以明显看出,本发明方法的分类精度是最好的,由于能够去除噪声数据,所以本发明方法的分类效果要好于其他四种方法。
从实验结果表可以明显看出,本发明方法的分类精度是最高的,要优于其他四种方法,具有较好的分类性能。
- 还没有人留言评论。精彩留言会获得点赞!