一种基于tagSQL的数据处理方法、系统及装置与流程
本发明涉及大数据技术领域,尤其是一种基于tagsql的数据处理方法、系统及装置。
背景技术:
apachespark(基于内存计算的开源的集群计算系统)是专为大规模数据处理而设计的快速通用的计算引擎,具有hadoopmapreduce所具有的优点,但是不同于mapreduce(编程模型)的是:运行中间输出结果可以保存在内存中,从而不再需要读写hdfs(hadoopdistributedfilesystem,hadoop项目的核心子项目),所以spark(开源集群计算环境)能更好地适用于数据挖掘与机器学习等需要迭代的mapreduce的算法。sparksql是spark处理数据的一个模块,跟基本的sparkrdd(弹性分布式数据集)的api(应用程序编程接口)不同,sparksql中提供的接口将会提供给spark更多关于结构化数据和计算的信息。sparksql的一个作用是执行sql查询语句,也可以从hive(基于hadoop的数据仓库工具)中读取数据,当使用其它编程语言来运行一个sql语句时,结果会返回一个dataset(独立数据集合)或者dataframe(二位数据结构),具体可以使用命令行、jdbc(javadtatabaseconnectivity,java数据库连接)或者odbc(opendatabaseconnectivity,开放数据库连接)的方式与sql交互。
sparksql提供了几种调用方式:命令行、javaapi、pythonapi、scalaapi,这几种调用方式适用于不同的使用人员,但是,由于现有技术的sql编程的命令行只能满足单行语句调用,而sql的大部分编程人员又没有掌握另外三种接口语言,所以程序员无法快速开展大数据开发工作。
技术实现要素:
为解决上述技术问题,本发明的目的在于:提供一种能兼容多种接口语言的基于tagsql的数据处理方法、系统及装置。
本发明采用的第一种技术方案是:
一种基于tagsql的数据处理方法,包括以下步骤:
接收tagsqlxml文件和过程请求;
根据过程请求获取tagsql应用进程;
tagsql应用进程对tagsqlxml文件进行解析得到第一过程;
将过程请求转发到tagsql应用进程,使tagsql应用进程从第一过程中获取第二过程,并执行第二过程;
其中,所述tagsqlxml文件包含客户端按照tagsqlxml标签要求进行业务逻辑处理的信息。
进一步地,在接收过程请求时,还包括以下步骤:
发送spark应用进程到spark模块,并接收spark模块返回的sparksession对象;
其中,spark模块的资源管理器采用的是yarn。
进一步地,所述对tagsqlxml文件进行解析,其具体为:
从tagsqlxml文件的根目录开始解析所有的tagsqlxml文件,将tagsqlxml文件中的tagsqlxml标签转换为树结构中对应的树节点对象;
其中,树节点对象包含有sql类型对象、imp类型对象和exp类型对象。
进一步地,所述在对tagsqlxml文件进行解析时,还包括以下步骤:
对每一个可执行过程对象设置一个全局标识。
进一步地,所述从第一过程中获取第二过程,其具体为:
通过kettle从第一过程中获取第二过程。
进一步地,所述执行第二过程,其具体为:
基于hadoop集群执行第二过程;
其中,hadoop集群包含hdfs、yarn、hbase、hive、spark、oracle和mysql。
进一步地,所述基于hadoop集群执行第二过程,其具体为:
基于hadoop集群解释并运行树结构的树节点对象。
进一步地,所述解释树结构的树节点对象,其具体为:
通过调用树节点对象的解释器模式解释树节点对象。
本发明采用的第二种技术方案是:
一种基于tagsql的数据处理系统,包括:
接收模块,用于接收tagsqlxml文件和过程请求;
获取模块,用于根据过程请求获取tagsql应用进程;
解析模块,用于tagsql应用进程对tagsqlxml文件进行解析得到第一过程;
执行模块,用于将过程请求转发到tagsql应用进程,使tagsql应用进程从第一过程中获取第二过程,并执行第二过程;
其中,所述tagsqlxml文件包含客户端按照tagsqlxml标签要求进行业务逻辑处理的信息。
本发明采用的第三种技术方案是:
一种基于tagsql的数据处理装置,包括:
至少一个存储器,用于存储程序;
至少一个处理器,用于加载所述程序以实现所述的一种基于tagsql的数据处理方法。
本发明的有益效果是:通过根据过程请求提取的tagsql应用进程,并将tagsqlxml文件解析转换为第一过程,再根据过程请求从第一过程中提取需要执行的第二过程,tagsql应用进程执行第二过程,使得sparksql变成类sql存储过程的编程语言,从而能够兼容多种接口语言,使程序员从传统的数据处理技术切换到大数据处理技术时,无需掌握api、java、python和scala等接口语言,就能快速开展大数据的开发工作。
附图说明
图1为本发明具体实施例的一种基于tagsql的数据处理方法的流程图;
图2为本发明具体实施例的一种基于tagsql的数据处理系统的模块框图;
图3为本发明具体实施例的基于tagsql的数据处理的流程图。
具体实施方式
下面结合附图和具体实施例对本发明做进一步的详细说明。对于以下实施例中的步骤编号,其仅为了便于阐述说明而设置,对步骤之间的顺序不做任何限定,实施例中的各步骤的执行顺序均可根据本领域技术人员的理解来进行适应性调整。
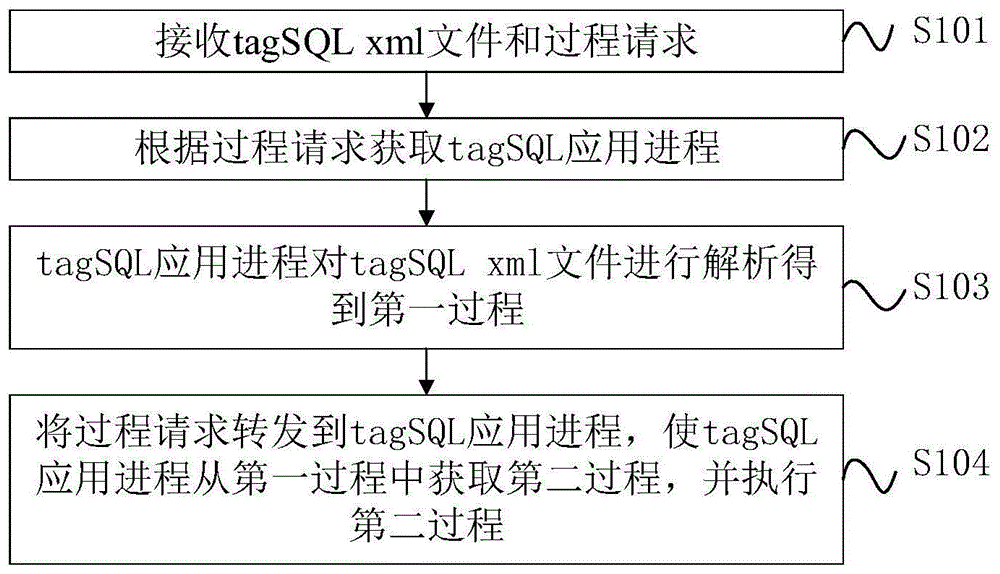
参照图1,一种基于tagsql的数据处理方法,包括以下步骤:
s101、接收tagsqlxml文件和过程请求;
具体地,所述tagsql是一种标签sql语言。所述tagsqlxml是标签sql语言形成的文件。通过kettle(开源的etl调度工具)或者tagsqldevtool(调试工具)发送tagsqlxml文件和过程请求。mainserver(服务器)接收kettle或者tagsqldevtool发送的tagsqlxml文件和过程请求。其中,kettle是调度工具,tagsqldevtool是用来开发和调试tagsqlxml文件的工具。
s102、根据过程请求获取tagsql应用进程;
具体地,所述tagsql应用进程是从进程池中提取的。进程池是用于存放tagsql应用进程,其位于mainserver中。所述tagsql应用进程是运行在spark上面的一个应用。mainserver接收到过程请求后,从进程池中提取可用的tagsql应用进程进行具体的业务处理。
s103、tagsql应用进程对tagsqlxml文件进行解析得到第一过程;
具体地,所述第一过程为tagsql应用进程对tagsqlxml文件进行解析得到可执行过程对象。所述可执行过程对象存放在tagsql应用进程内的过程池中。所述可执行过程对象的内部结构是一个树结构。
s104、将过程请求转发到tagsql应用进程,使tagsql应用进程从第一过程中获取第二过程,并执行第二过程;
具体地,所述第二过程是第一过程(也称为可执行过程对象)中需要执行的过程对象。tagsql应用进程接收到mainserver转发过来的过程请求时,从过程池中提取需要执行的过程对象执行处理。过程对象的执行过程就是xml业务描述的具体实现,过程对象的执行是基于分布式框架执行的。
其中,所述tagsqlxml文件包含客户端按照tagsqlxml标签要求进行业务逻辑处理的信息。
具体地,所述tagsqlxml标签包含以下标签:
service标签:服务标签;
procedure标签:过程标签,声明一个过程;
var标签:变量标签,变量的声明和赋值;
sql标签:执行sql标签,可以是变量赋值、创建表、删除表、清空表和插入数据等其中一个或多个操作;
print标签:打印标签;
imp标签:从oracle等外部数据库导入数据到hive中;
exp标签:导出标签,把hive中的数据导出到oracle等外部数据库;
if标签:条件判断标签;
loop标签:根据循环条件,循环执行内部嵌套的标签;
exception标签:异常标签,通过逻辑判断,当业务数据出现异常时,通过此标签抛出异常,停止运行;
call标签:嵌套调用标签。
通过根据过程请求提取的tagsql应用进程,并将tagsqlxml文件解析转换为第一过程,再根据过程请求从第一过程中提取需要执行的第二过程,tagsql应用进程执行第二过程,使得sparksql变成类sql存储过程的编程语言,从而能够兼容多种接口语言,使程序员从传统的数据处理技术切换到大数据处理技术时,无需掌握api(应用程序接口)、java、python和scala等接口语言,就能快速开展大数据的开发工作。
进一步作为优选的实施方式,在接收过程请求时,还包括以下步骤:
发送spark应用进程到spark模块,并接收spark模块返回的sparksession对象;
其中,spark模块的资源管理器采用的是yarn。
具体地,所述session对象存储特定用户会话所需的属性及配置信息。通过sparksession对象,使tagsql应用进程和spark模块建立连接,从而可以直接运行sparksql和spark的算子,其中,spark的算子是运行在slave(分布式节点)上。所述spark模块的资源管理器采用的是yarn,即sparkonyarn,通过sparkonyarn的资源管理模式,使得分析编程人员无需关注后台内存、cpu和磁盘等资源的分配情况。
进一步作为优选的实施方式,所述对tagsqlxml文件进行解析,其具体为:
从tagsqlxml文件的根目录开始解析所有的tagsqlxml文件,将tagsqlxml文件中的tagsqlxml标签转换为树结构中对应的树节点对象;
其中,树节点对象包含有sql类型对象、imp类型对象和exp类型对象。
具体地,在tagsql应用进程启动时,就会从tagsqlxml文件的根目录开始解析所有的tagsqlxml文件,将tagsqlxml文件中的tagsqlxml标签转换为树结构中对应的树节点对象(基本属性被赋值),树节点对象之间的上下级关系和tagsqlxml文件描述的一致。若接收到装在单个tagsqlxml文件请求时,就解析指定的tagsqlxml文件,将tagsqlxml标签转换为对应的树节点对象。
进一步作为优选的实施方式,所述在对tagsqlxml文件进行解析时,还包括以下步骤:
对每一个可执行过程对象设置一个全局标识。
具体地,每一个可执行过程对象都有一个唯一的全局标识。所述全局标识的生成规则为预先设定好的。通过全局标识,可快速查找可执行过程对象。
进一步作为优选的实施方式,所述从第一过程中获取第二过程,其具体为:
通过kettle从第一过程中获取第二过程。
具体地,所述kettle是一款开源的etl工具,本发明是在kettle的基础上进行二次开发的,支持同周期数据依赖检测(包含跨流程的数据相互依赖的检测),同时具备了web管理端和丰富了相关的日志。通过kettle提供简单易用的可视化调度模式,用户只需通过托、拉、拽和画流程图的方式就能实现作业调度。
进一步作为优选的实施方式,所述执行第二过程,其具体为:
基于hadoop集群执行第二过程;
其中,hadoop集群包含hdfs、yarn、hbase、hive、spark、oracle和mysql。
具体地,所述hadoop集群包含hdfs(hadoop分布式文件系统)、yarn(资源协调器)、hbase(分布式、面向列的开源数据库)、hive(数据仓库工具)、spark、oracle(关系数据库管理系统)和mysql(关系数据库管理系统)等数据库。所述hadoop集群的资源管理采用的是yarn,即sparkonyarn。通过hadoop集群提供的关系型和非关系型数据库,使得执行第二过程时,可以操作多种数据库。
进一步作为优选的实施方式,所述基于hadoop集群执行第二过程,其具体为:
基于hadoop集群解释并运行树结构的树节点对象。
具体地,所述树节点对象包含变量类型对象、sql类型对象、print类型对象、imp类型对象、exp类型对象、if类型对象、loop类型对象、exception类型对象等其中的一个或多个。解释运行的顺序是同一级别从左到右,父子节点是先子后父。每个树节点对象都可拥有自己的变量,父节点变量的作用范围包含自己、自己的子节点和自己的子子节点。
进一步作为优选的实施方式,所述解释树结构的树节点对象,其具体为:
通过调用树节点对象的解释器模式解释树节点对象。
具体地,通过调用解释器模式的方法,实现节点的解释功能。例如,当节点为imp类型的对象时,那它要实现的功能是:解析自定义的sql实现多分布式(多个计算节点)计算从oracle导数据到hive;解析自定义的sql实现分布式(多个计算节点)计算从mysql到数据到hive;解析自定义的sql实现从ftp服务器(filetransferprotocolserver,在互联上提供文件存储和访问服务的计算机)导数据到hive。
参照图2,本发明实施例还提供了一种与图1的方法相对应的基于tagsql的数据处理系统,包括:
接收模块,用于接收tagsqlxml文件和过程请求;
获取模块,用于根据过程请求获取tagsql应用进程;
解析模块,用于tagsql应用进程对tagsqlxml文件进行解析得到第一过程;
执行模块,用于将过程请求转发到tagsql应用进程,使tagsql应用进程从第一过程中获取第二过程,并执行第二过程;
其中,所述tagsqlxml文件包含客户端按照tagsqlxml标签要求进行业务逻辑处理的信息。
上述方法实施例中的内容均适用于本系统实施例中,本系统实施例所具体实现的功能与上述方法实施例相同,并且达到的有益效果与上述方法所达到的有益效果也相同。
本发明实施例还提供了一种与图1的方法相对应的基于tagsql的数据处理装置,包括:
至少一个存储器,用于存储程序;
至少一个处理器,用于加载所述程序以实现所述的一种基于tagsql的数据处理方法。
上述方法实施例中的内容均适用于本装置实施例中,本装置实施例所具体实现的功能与上述方法实施例相同,并且达到的有益效果与上述方法所达到的有益效果也相同。
参照图3,本发明具体实施例的基于tagsql的数据处理的执行过程:其中,
可执行过程对象:
a)、可执行过程对象的内部结构是一个树结构,树节点有变量类型对象、sql类型对象、print类型对象、imp类型对象、exp类型对象、if类型对象、loop类型对象、exception类型对象等等,类似语法树。
b)、设计模式采用解释器模式,树节点的对象都实现同一个解释器模式接口,由于是一颗多叉树,同一级树节点解释运行的顺序是从左到右,父子树节点的解释运行的顺序先子后父;每个节点对象都可拥有自己的变量,父节点变量的作用范围包含自己,自己子节点及自己的子子节点。
c)、每个树节点对象都实现了解释方法,该方法去实现节点的解释功能;例如:节点为imp类型的对象时,那它要实现的功能:解析自定义的sql实现多分布式(多个计算节点)计算从oracle导数据到hive;解析自定义的sql实现分布式(多个计算节点)计算从mysql到数据到hive;解析自定义的sql实现从ftp服务器上的ftp文件内导数据到hive等其中的一个或多个功能。
d)、tagsql应用进程运行后,它并没有马上和spark模块建立连接,直到提交(启动)spark应用进程到spark模块,spark模块返回sparksession对象。
e)、在接收到sparksession对象后,就可以直接运行sparksql和spark的算子,其中,spark的算子是运行在slave(分布式节点)上的。
f)、当接收tagsql过程请求时,就按树结构遍历解释运行(同一级树节点对象解释运行的顺序是从左到右,父子树节点对象的解释运行的顺序先子后父),解释运行的结果就是tagsqlxml表达的结果,结果返回给rpc服务模块。节点对象解释过程中可以获sparksession对象,也可以从连接管理器获取外部数据源的连接等资源。
xml文件解析模块:
tagsqlxml基于存储过程的概念,定义一个统一的大数据开发界面,使大数据的开发和维护变得简单;定义了一套对应的xml标签,标签如下:tagsql应用进程启动时,xml文件解析模块就会从tagsqlxml文件的根目录开始解析所有的tagsqlxml文件,将tagsqlxml文件中的tagsqlxml标签转换为对应的树节点对象(基本属性被赋值),树节点对象之间的上下级关系和tagsqlxml文件描述的一致;接收到装载单个tagsqlxml文件请求时,就解析指定的tagsqlxml文件,将tagsqlxml标签转换为对应的树节点对象(基本属性被赋值)。
过程对象容器:
a)、解析模块解析tagsqlxml文件,生成可执行过程对象,每个可执行过程对象有一个唯一的全局标识。
b)、过程对象容器提供了存入和查找过程对象的方法,存入过程对象前一定要对过程对象内部对象按名称进行重复的检查,确保过程对象的子对象、子子对象的名称是唯一的。
连接管理器:用于保存外部数据源的连接信息,在过程对象解释运行、需要从外部数据源读写数据时,就从这查询出外部数据源的连接信息,然后进行连接。
mainserver构件:用于向tagsql应用进程的rpc服务模块转发tagsql过程请求和装载单个tagsqlxml文件的请求。
rpc服务模块:
a)、接收来自mainserver的tagsql过程请求和装载tagsqlxml文件请求。
b)、从过程对象容器里面查询出要执行的过程对象,组装好上下文和过程解释运行时所需要的参数,然后调用过程对象解释器模式的方法,过程的业务逻辑处理被启动了,rpc服务模块会遍历过程对象中的所有子对象,并进行解释运行。
c)、装载tagsqlxml文件,解析tagsqlxml文件,将tagsqlxml文件转换为过程对象,并存入过程对象容器。
sparkdriver是main类,它启动时rpc服务模块的监听开启,解析所有的tagsqlxml文件转换为过程对象,存入过程对象容器,连接容器的初始化。
spark模块是分布式并行计算框架,运行速度快,采用sparkonyarn资源管理模式运行spark的分布式计算框架;当前spark可以sparksql和算子来进行计算的。
hbase是分布式、面向列的存储系统,其读写性能非常好、多版本管理和rowkey(hbase中的行主键)的设计;基于hbase的特性,使用phoniex(构建在hbase上的一个sql层)组件来实现表索引功能,写数据入hbase支持buckload方式,写hbase索引也支持buckload方式,查询hbase通过phoniex的jdbc方式。
综上所述,本发明通过根据过程请求提取的tagsql应用进程,并将tagsqlxml文件解析转换为第一过程,再根据过程请求从第一过程中提取需要执行的第二过程,tagsql应用进程执行第二过程,使得sparksql变成类sql存储过程的编程语言,从而能够兼容多种接口语言,使程序员从传统的数据处理技术切换到大数据处理技术时,无需掌握api、java、python和scala等接口语言,就能快速开展大数据的开发工作,提高程序员在大数据处理方面的工作效率;进一步地,通过sparkonyarn资源管理模式,使得分析编程人员无需关注后台内存、cpu和磁盘等资源的分配情况;进一步地,通过kettle提供简单易用的可视化调度模式,用户只需通过托、拉、拽和画流程图的方式就能实现作业调度;通过hadoop集群提供的关系型和非关系型数据库,使得执行第二过程时,可以操作多种数据库。
以上是对本发明的较佳实施进行了具体说明,但本发明并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可做作出种种的等同变形或替换,这些等同的变形或替换均包含在本申请权利要求所限定的范围内。
- 还没有人留言评论。精彩留言会获得点赞!