基于五笔码的字符级文本分类方法与流程
本发明属于文本处理技术领域,具体涉及一种基于五笔码的字符级文本分类方法。
背景技术:
文本分类是自然语言处理中最普遍的一种应用,是对文本数据信息进行筛选、整理和组织的关键技术,得到了研究者的广泛关注。过去一段时间里,自然语言处理中文本分类领域的主流研究方向是以词为基本单位的,中文文本的预处理一般以分词为主。因此,在中文自然语言处理领域,分词成为了一个基础性的研究。然而,不同的分词算法在歧义识别、分词准确性、算法复杂度、实施难度等不同方面有一定的局限性。随着近年来深度学习在各个领域广泛应用,越来越多的研究者开始研究以字符为单位的模型。使用字符级模型可以替代传统的中文分词方法,无需分词的字符级模型解决了分词算法中效率不高和通用性不强的问题。同样,字符级模型在处理中文时也有其自身的问题,中文字符总量远大于英文字符总量,在使用同样的字符级模型时,直接输入中文字符进行分类的效果甚至不如传统模型。
不同于英文文本有天然的空格将单词分开,中文文本没有词的界限。因此,在中文文本分类中,首先要对文本数据进行分词。目前用于分词的算法主要分为以下几类:词典分词算法、理解分词算法、统计分词算法、组合分词算法。其中,词典分词算法在歧义识别和新词发现方面表现较差,准确率也一般;理解分词算法则需要构建规则库,算法较为复杂,技术不成熟,因此实施困难而且分词速度慢;而统计分词算法也有算法复杂度较高且分词速度一般的缺点。鉴于单独的分词算法有各自的缺点,研究者们采用了组合方法。
然而,分词阶段造成的误差会在之后的语义理解过程中被放大并最终影响分类结果,所以目前的分词方法在面对大规模语料时表现并不理想。另外,分词算法的通用性也是一个亟待解决的问题。
技术实现要素:
针对上述现有技术中存在的问题,本发明的目的在于提供一种可避免出现上述技术缺陷的基于五笔码的字符级文本分类方法。
为了实现上述发明目的,本发明提供的技术方案如下:
一种基于五笔码的字符级文本分类方法,采用五笔字型码对中文进行转换的字符级表示模型。
进一步地,所述字符级表示模型包括:
假设有一个离散的输入函数g(x)∈[1,l]→r和一个离散的核函数f(x)∈[1,k]→r;在f(x)和g(x)之间的卷积
其中,c=k-d+1是一个偏移常数;该模型的参数化是通过一组被称为权重的内核函数fij(x)(i=1,2,...,m;j=1,2,...,n),还有一组输入gi(x)和输出hj(y);把每个gi或hj称作输入或输出特征,m或n称为输入或输出的特征大小;
给定一个离散的输入函数g(x)∈[1,l]→r,g(x)的最大池化函数
其中,c=k-d+1是一个偏移常数。
进一步地,该模型中使用的非线性函数为阈值函数h(x)=max{0,x},该模型采用随机梯度下降算法,使用的动量大小为0.9和初始步长大小为0.01,每一层都有一个固定数量的随机抽样样本。
进一步地,所述字符级表示模型使用一系列编码字符作为输入。
进一步地,所述方法包括:构建字符表,使用one-hot编码,将字符序列转换为一组固定长度为l0,大小为m的向量;忽略所有长度超过l0的字符,任何不在表中的字符都量化为零向量,对字符编码进行反向处理。
进一步地,所述方法包括:采用五笔码将中文字符转化成唯一的英文字符串,再将英文字符串输入字符级模型中进行分类。
本发明提供的基于五笔码的字符级文本分类方法,采用字符级表示模型,无需分词且能进行很好的字符转化,在中文文本分类中有着特殊的优势,分类效果明显优于传统模型和其他深度学习模型,可以有效地应用于中文文本分类,可以很好地满足实际应用的需要。
附图说明
图1为cbow模型图;
图2为skip_gram模型图;
图3为字符级模型架构图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,下面结合附图和具体实施例对本发明做进一步说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
一种基于五笔码的字符级文本分类方法,使用五笔码的字符级表示模型应用于中文文本分类任务。基于公开的新闻语料库,构建了大规模数据集,比较使用五笔码作为输入的字符级模型与传统模型和其他深度学习模型的分类结果。实验结果表明,本发明提出的使用五笔码作为输入的字符级模型相比于传统模型和其他深度学习模型有更好表现,是一种有效的中文文本分类方法。
分词表示模型:
字符级模型具有无需分词和通用性较强的特性,这些特性使得字符级表示模型在自然语言处理中相比于分词有更优的效果。
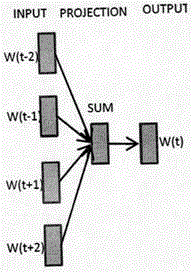
在分词后,通常要对单词进行向量化。word2vec使用向量间的距离来表示单词语义上的远近,弥补了分词在近义词表示方面的不足,因其有着提取低维特征和很好地表达词的句法和语义信息的能力而被广泛地应用于文本分类领域。word2vec是wordembedding词向量生成技术的一个表示工具,它通过将单词映射为实数值向量来表示单词。word2vec是根据上下文信息来生成词向量,而单词间的相似度由所生成的词向量的相似度表示。word2vec的训练模型分为两类,分别是cbow(continuousbag-of-wordsmodel)模型和skip_gram模型。其中,cbow模型是利用上下文去计算当前词的概率,而skip_gram模型是利用当前词去计算上下文的概率。两种模型如图1和图2所示。
cbow模型通过上下文预测当前词,其模型表达式如下:
p(wt|sum(wt-k,wt-k+1,k,wt-1+k,wt+k))(1)
其中,wt为当前词,该模型利用wt上下文窗口大小为k的词来计算wt属于词典某个词的概率。sum表示将周围相邻的2k个单词的词向量作相加运算。
而skip_gram模型则是利用当前词预测上下文,即通过当前词wt计算其周围2k个单词wt-k,wt-k+1,...,wt-1+k,wt+k属于词典某个词的概率。
p(wt-k,wt-k+1,k,wt-1+k,wt+k|wt)(2)
由于窗口尺寸的限制,cbow模型无法计算当前词与窗口外词语的关系,造成了语义信息的丢失,影响语义准确率。相比于cbow模型,skip_gram模型的语义准确率更高。skip_gram模型可以通过跳跃词汇构建词组来避免cbow模型丢失窗口外语义信息的问题,但缺点是模型的计算代价大,模型训练耗时过长,对大规模的训练语料是不切实际的。由于上述两种模型的不足,研究人员开始尝试从字符的角度对文本进行处理。
字符级表示模型:
与词语级语言模型相比,字符级语言模型保留了更多的原始信息。因此,在众多用于文本分类的神经网络模型中,字符级语言模型有着相对突出的优良效果。gb2312-80汉字集一级3755个,二级3008个,两级共6763个(不包括繁体字),涵盖99.99%的常用汉字,字符级模型需要处理两级国标汉字,并且在某些具体应用情境下还需扩展汉字集。由于汉字数量庞大,将每一个中文汉字当做一个字符直接输入字符级语言模型工作量会相当庞大,并且实验效果相对英文语料来说并不理想。
拼音表示模型:
现有技术中有采用拼音处理中文数据的方法。使用pypinyin包将中文数据转化为拼音,将每一个中文字符转化为其对应的拼音,例如,字符“北”可以转化为“bei”。这样的方法使得原本适用于英文文本的模型可以直接应用于中文数据集而无需进行更改。
五笔表示模型:
本发明采用五笔字型码对中文进行转换的字符级表示模型。拼音模型有着重码率高这个致命的缺点。与拼音模型相比,五笔字形码模型具有“字”同“码”的唯一性,例如,拼音“bei”可以表示“北”、“被”、“贝”等众多同音字符,而五笔码“ux”只能表示字符“北”。五笔字型码属于形码,它把单字拆分为字根,字根拆分为笔画,按字根编码输入汉字。五笔码编码有着严谨的方法和规则,字根组合的强相容性使重码大幅减少,能很好地处理两级国标字库的所有汉字,是一种高效率的汉字输入法。本发明就是采用五笔码将中文字符转化成唯一的英文字符串,再将英文字符串输入字符级模型中进行分类。表1展示了五笔码的处理结果。
表1五笔码处理结果实例
字符级文本分类:
本发明从字符级层面对文本进行分类,提取出高层的抽象特征。相比于那些使用单词(统计信息或者n-grams、word2vec等)、短语或句子对文本进行建模,或者对语义和语法结构进行分析的模型,字符级模型有下列优点:
1.不需要预先训练的词向量或者学习句法语义结构等信息;
2.在语言处理任务中相比于传统方法使用范围更广,容易推广到所有语言。
基于字符级模型的上述优点,本发明提出了一个使用五笔码作为输入的字符级模型应用于中文文本分类。
关键模型:
字符级模型的主要组件是时间卷积模块,只计算一维卷积。假设有一个离散的输入函数g(x)∈[1,l]→r和一个离散的核函数f(x)∈[1,k]→r。在f(x)和g(x)之间的卷积
其中,c=k-d+1是一个偏移常数。该模型的参数化是通过一组被称为权重的内核函数fij(x)(i=1,2,...,m;j=1,2,...,n),还有一组输入gi(x)和输出hj(y)。我们把每个gi(或hj)称作输入(或输出)特征,m(或n)称为输入(或输出)的特征大小。输出hj(y)是通过gi(x)和fij(x)的卷积得到。
最大时间池化层是训练更深入的模型的一个关键模块,是计算机视觉中一维的最大池化层。给定一个离散的输入函数g(x)∈[1,l]→r,g(x)的最大池化函数
其中,c=k-d+1是一个偏移常数。该池化模块使cnn的训练深度超过6层,这是很难达到的一个深度。
该模型中使用的非线性函数为阈值函数h(x)=max{0,x},使得卷积层类似激活函数relus。该模型采用随机梯度下降算法(sgd),使用的动量大小为0.9和初始步长大小为0.01,每一层都有一个固定数量的随机抽样样本。
特征量化:
字符级模型使用一系列编码字符作为输入。首先,要构建字符表,使用one-hot编码,将字符序列转换为一组固定长度为l0,大小为m的向量。忽略所有长度超过l0的字符,任何不在表中的字符(包括空格字符)都量化为零向量。为了使最新读入的字符处于输出开始的地方,对字符编码进行反向处理。
本发明的字符级模型中使用的字符表如表2所示,共有70个字符,包含26个英文字母、10个数字、33个其他字符和1个全零向量。
表2字符级模型中使用的字符表
模型架构:本发明设计了large和small两种规模的神经网络。两种神经网络都是9层模型,由6个卷积层和3个全连接层组成,如图3所示。
实验设置和结果分析
实验数据集:
以往的研究表明,神经网络模型通常在大数据集的情况下表现出良好的效果,对于字符级模型来说更是如此。因此,本发明采用搜狗新闻语料库和中科院自动化所中文新闻语料库这两个相对较大的数据库进行实验。
1.搜狗新闻语料库。搜狗新闻语料库来自搜狗实验室发布的新闻数据,包含全网新闻数据(sogouca)和搜狐新闻数据(sogoucs)两个数据集共计2909551篇新闻报道。本发明选取其中体育、金融、汽车、娱乐、社会这5个类别的540000篇作为实验数据,同时将其分为大、小两个子数据集,大数据集包含510000篇语料,其中408000篇作为训练样本,102000篇作为测试样本;小数据集包含30000篇语料,其中24000篇作为训练样本,6000篇作为测试样本。
2.中科院自动化所中文新闻语料库。中科院自动化所中文新闻语料库来源于凤凰、新浪、网易、腾讯等新闻网站,包含了2009年12月-2010年3月期间共计39247篇新闻报道的标题和内容。由于该语料数量较少且每篇的篇幅较长,本发明按照平均每篇有十个段落的原则将每一篇语料按段落拆分为十份,从而得到392470篇新闻语料。同样将这些语料分为大、小两个子数据集,大数据集包含370000篇语料,其中296000篇作为训练样本,74000篇作为测试样本;小数据集包含22470篇语料,其中17976篇作为训练样本,4494篇作为测试样本。表3列出了实验数据集的相关数据。
表3实验数据集
模型对比:
为了验证本发明方法的效果,采用一系列传统模型和深度学习模型作为对比。
1.词袋模型(bag-of-words)。本发明通过从每个数据集的训练子集中选出50000个频繁词汇来构造词袋模型。对于一般的词袋模型,使用词频作为特征。对于结合了tf-idf的词袋模型,使用tf-idf值作为特征。
2.n-grams模型。本发明通过从每个数据集的训练子集中选择最频繁的500000个n个词来构造n-grams模型。特征值的计算方法与词袋模型相同。
3.bag-of-means模型。bag-of-means模型采用基于word2vec[12]的k-means算法从每个数据集的训练集中学习,然后使用这些学习后的聚类中心作为聚类词的代表。本发明考虑了训练子集中出现超过5次的所有单词。bag-of-means的特征计算方法与词袋模型的方法相同,embedding的维数为300,聚类中心的数量是5000个。
4.lstm(longshort-termmemory)。lstm即长短期记忆模型。本发明采用基于词的lstm模型,同前面模型一样使用大小为300维的word2vecembedding。该模型以所有lstm细胞输出均值作为特征向量,采用多类别逻辑回归处理特征向量,输出维度为512。
5.基于word2vec的cnn模型。基于word2vec的cnn模型的embedding的大小为300维,与bag-of-means模型相同。为确保对比实验的公平性,基于word2vec的cnn模型与本发明的字符级cnn模型采用相同的层数,各层输出大小也相同。
6.pinyinchar-cnn。本发明采用基于拼音的字符级cnn模型,该模型的embedding大小、层数、各层输出大小均与基于word2vec的cnn模型相同。
实验结果分析:
本发明提出的一种采用五笔字型码对中文进行转换的字符级表示模型,在实验中选择了5种传统模型和3种深度学习模型作为对比验证本发明方法的效果。实验结果如表4(表中数据为错误率,以百分比表示,“large”表示相对应的大数据集,“small”表示小数据集)所示。
表4不同数据集下各种模型的分类错误率
实验使用了两个新闻数据集,分别是搜狗新闻语料库和中科院自动化所中文新闻语料库。将两个数据集各自分为大、小两个子数据集,分别用“large”、“small”表示。表4的实验结果表明,在小数据集的情况下,传统分类方法的表现优于深度学习模型。在sogou新闻库中,传统方法在小数据集中的优势非常明显:n-grams模型的错误率只有2.94%,结合tf-idf的n-grams模型的错误率更是低至2.83%。而深度学习模型则普遍表现不佳,字符级模型(char-cnn)的错误率更是高达8%以上,其中拼音字符级模型(pinyinchar-cnn)的错误率高达8.75%,五笔码字符级模型(wubichar-cnn)的错误率稍低,但也有8.23%。在中科院自动化所的语料库中情况是相似的,n-grams模型的错误率只有2.75%,而深度学习模型的错误率均在6%以上,字符级模型的错误率更是高达8%以上。出现这种情况的原因在于lstm、cnn这类深度学习模型需要训练的参数非常多,在小数据集上学习这些数量庞大的参数是不现实的,容易出现过拟合,从而导致分类效果不佳。而实验中的几类传统模型则原理简单,泛化能力强,因此在小样本数据集中有着良好的表现。
然而,在大数据集的情况下,实验结果恰巧相反。在sogou新闻库中,传统模型的错误率依然维持在2.8%左右,而深度学习模型的错误率已降至4%以下。字符级模型更是表现突出,其中的pinyinchar-cnn的错误率已经低至2.78%,使用了五笔码的wubichar-cnn更是只有2.56%。在中科院自动化所的语料库中情况也是相似的,pinyinchar-cnn的错误率低至2.71%,wubichar-cnn的效果有进一步提升,错误率为2.53%。这样的实验结果表明,使用五笔码作为输入的字符级模型(wubichar-cnn)在大数据集上取得了很好的分类效果。
传统方法的错误率并没有降低多少,而神经网络方法的分类效果则有大幅度提升,而且使用pinyin或wubi作为输入的情况下,效果有进一步的提升。这样的结果是由于传统模型的分词误差会在之后的语义理解过程中被放大,而且提取的语义信息也不充分,在面对大规模语料时分类效果基本没有提升。而深度学习模型(尤其是字符级模型)保留了更多的深层语义信息,当数据量达到一定程度时,其优势就显现了出来。本发明的wubichar-cnn使用五笔码作为字符级模型的输入,相较于拼音模型pinyinchar-cnn大幅降低了重码率,例如拼音“bei”可以表示“北”、“被”、“贝”等众多同音字符,而五笔码“ux”只能表示字符“北”,这样“字”同“码”的唯一性优化了字符级模型的输入,使其在中文文本分类任务中表现得更为理想。
另外,由表3中的实验数据可知,bag-of-means模型在每一种情况下均表现较差,错误率在10%左右。这样的结果表明,简单地使用词向量不会给中文文本的分类效果带来优势,word2vec用于中文文本分类的输入有一定的局限性。
传统模型在小数据集中的优势明显,而在几十万样本的大数据量情况下几乎没有提升。而深度学习模型虽然在小数据集中表现不理想,但在使用了大数据集后分类效果大幅提升,并且在使用字符级模型的情况下效果有进一步的提升。大数据集下的字符级模型的分类效果超过了传统模型,其中的wubichar-cnn模型效果最优。综上所述,本发明提出的使用五笔码作为输入的字符级模型在大数据集下的分类效果明显优于传统模型和其他深度学习模型,可以有效地应用于中文文本分类。
本发明提出了一种采用五笔字型码对中文进行转换的字符级表示模型用于中文文本分类研究,采用了5种传统模型和3种深度学习模型进行对比试验。由于无需分词且能进行很好的字符转化,本发明的字符级表示模型在中文文本分类中有着特殊的优势。实验结果表明,本发明提出的使用五笔码作为输入的字符级模型的分类效果优于其他模型,是一种有效的分类方法。
以上所述实施例仅表达了本发明的实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!