一种基于社交媒体内容和结构的用户实时观点检测方法与流程
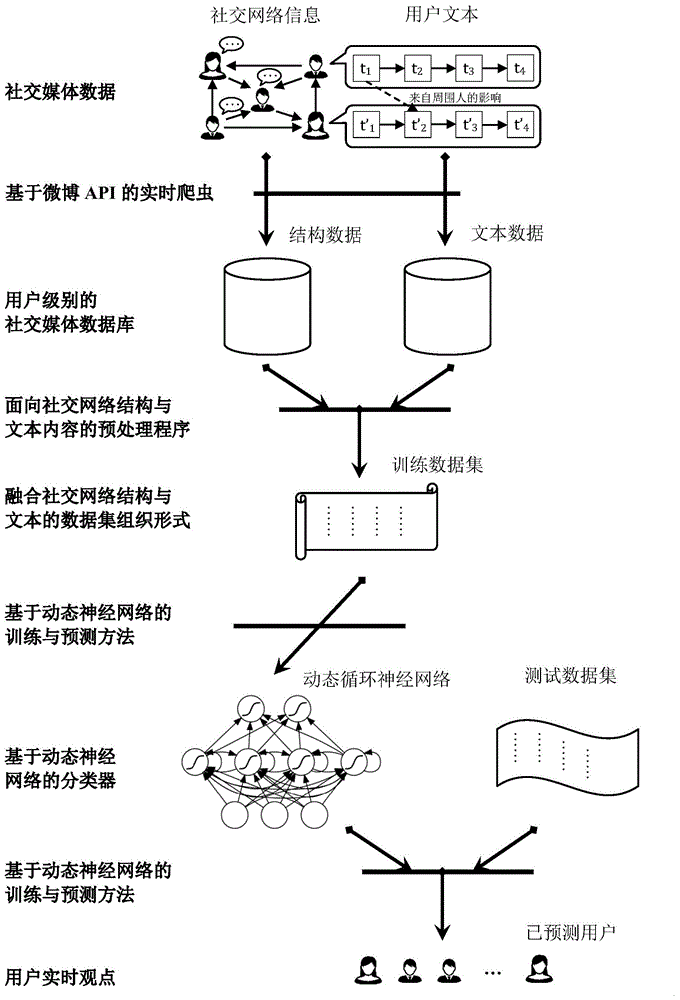
本发明涉及一种基于社交媒体内容和结构的用户实时观点检测方法,属于信息处理技术领域。
背景技术:
社交媒体实时观点预测(dynamicopinionprediction),又称用户级别的动态立场预测,是指为微博中的每一个用户标注一个正确的观点,用户的观点由两部分组成,第一部分是用户讨论或关心的主题,第二部分是用户的立场。正确、及时和高效地预测用户观点,不仅有助于掌握社会舆情和政府决策,具有深远的社会价值,而且有利于企业制定合适的市场策略,具有重要的市场研究价值。目前,社交媒体为社会公众提供了前所未有的舆论表达新手段和自由的公共事务讨论新空间,已成为现今社会内容文本和网络数据的重要载体,反映了社会的舆论趋势、汇集了民意。特别是近几年,随着以推特,脸书,新浪微博和微信等社交平台的迅猛发展,用户的社会关系和用户发表的文本信息量急剧增长,如何利用这些结构数据和内容数据进行正确而高效的观点预测,是目前面临的一大挑战。
当前的用户级别的观点预测方法按照特征提取方法可以分为基于纯文本的观点预测方法、基于社交网络结构的观点预测方法以及基于文本上下文注意力机制的观点预测方法,按照分类器类型可以分为静态观点预测方法和动态观点预测方法。现有的比较成熟的方法大多面向纯文本,把观点预测看作一个文本分类的问题,使用长短时记忆神经网络(lstm)和条件随机场(crf)对社交网络用户进行立场分类。少数工作只考虑用户关系信息,把用户观点看作一个影响力在加权网络上传播的过程。也有一些工作考虑了文本之间的主题相关性,引入了上下文注意力(attention)的概念,认为主题相近的微博文本用户的关注度较高,从而提高了文本分类的准确率和召回率。关于分类器类型的选择,就目前已有的研究方法而言,基于动态分类器的用户观点检测很少,有且仅限于概率图模型,而且面向文本级别进行分类。
技术实现要素:
发明目的:为了填补融合社交网络结构和内容进行用户观点预测研究的不足,本发明提供一种基于社交媒体内容和结构的用户实时观点检测方法,能够解决社交网络特有的用户观点预测实时性的问题;能够整合用户关系和用户微博文本这两种模态的信息,旨在提升用户观点检测的准确率。
技术方案:为实现上述目的,本发明采用了实时抓取社交媒体数据、预处理整合网络结构和文本内容、动态训练神经网络和预测用户观点的技术方案,所述的基于社交媒体内容和结构的用户实时观点检测方法,包括以下步骤:
(1)抓取微博文本并分析得到微博作者,抓取作者的社交网络信息;
(2)构建用户级别的社交媒体数据库,包括社交网络结构数据库和社交网络文本数据库,分别存储社交网络结构数据和文本数据;
(3)进行面向社交网络结构与文本内容的预处理,包括:首先对社交网络文本数据库中的微博按照发布时间排序,然后以设定时间为单位进行分割,得到以时间为区分的文本数据块;接着对社交网络结构数据库中的用户用哈希表进行存储;最后对每个以时间为单位的文本数据块,遍历每条微博,得到活跃过的用户id集合以及用户最近发的设定条数的微博,然后遍历每条微博并输出,每次输出用户最近发的1条微博时,伴随着同时输出他的邻居们最近发的设定条数的微博;
(4)将步骤(3)处理得到的数据进行存储,得到融合社交网络结构与文本的数据结构,作为神经网络的训练数据集和测试数据集;该数据结构中包括若干数据块,每个数据块中包括若干用户发表的微博串,每条微博由用户自身微博博文和它的语境构成,每条微博博文有对应的主题;训练数据集中每条微博标记了用户的真实立场;
(5)利用训练数据集训练动态神经网络;其中训练数据集以步骤(3)中设定的分割时间为单位,采用增量训练的过程,每次训练完一个数据块后,将循环神经网络神经元的参数值进行保存,下次进行训练时,先载入原先的循环神经网络的参数值,然后使用最新的训练数据执行梯度下降算法,在原先已训练好的循环神经元的参数值的基础上进行更新;
(6)在使用完训练数据集中的数据块后,得到一个训练好的基于动态神经网络的用户观点分类器;
(7)利用训练好的用户观点分类器和预测数据块预测此数据块中每个的实时用户观点。
在优选的实施方案中,步骤(1)中调用微博流式api来实时地监听用户可见的微博窗口,允许输入一组哈希标签来过滤抓取到的微博;在监听到最新的微博后,分析微博json数据,得到微博作者的用户id,然后调用微博查询式api问询用户id,获得用户的社交网络信息。
在优选的实施方案中,社交网络结构数据库中的社交网络数据表以用户id为主键,每一行第一列为用户id,其他列为关注该用户的用户id;社交网络文本数据库中的文本数据表以微博id为主键,其中每一行第一列为微博的作者的用户id,第二列为微博的文本,第三列为是否转发标识,第四列为微博的发布时间,最后一列为这条微博的id。
在优选的实施方案中,面向社交网络结构与文本内容的预处理具体包括:
(3.1)将社交网络数据表读入并存储为一张以用户id为键的哈希表,每个键映射到的值是用户关注对象的id集合;
(3.2)将文本数据表按照发布时间升序排序,然后以“天”为时间单位进行分割,得到若干文本数据子表;
(3.3)对每个文本数据子表执行了下述操作:
i)遍历得到一个哈希表,键是用户id,键集合是这一天活跃过的用户id集合,每个键映射到的值是一张数据表,该数据表以微博id为主键,键集合是用户这一天最近发的3条微博,主键映射到的非主属性是离该微博的时间戳最近的5条邻居微博;
ii)遍历i)中哈希表中的每个用户,输出该用户的时间线和时间线上每条微博所处的邻居微博的情况。
在优选的实施方案中,融合社交网络结构与文本的数据集组织形式如下表所示:
表中,每十八行表示一个用户,用户每天被设定为发了三条微博,每条微博占六行,第一行是用户本人的微博,第二至六行是用户发这条微博时周围人发的微博。
在优选的实施方案中,基于动态神经网络的训练与预测方式是:把开始到当前时间为止的所有时序数据块作为训练数据,预测数据为当前时间往下一个时间点的时序数据块;训练时,并不从头开始训练,设当前数据块为e,载入已训练好的e-1数据块对应的模型参数,使用数据块e更新模型的参数,而不是初始化模型后用数据块1至e的数据训练;预测数据块e+1时,载入已训练好的e数据块对应模型的参数,预测数据块e+1的用户观点。
在优选的实施方案中,基于动态神经网络的用户观点分类器是一个神经网络分类器,基于反向传播梯度下降算法优化模型参数;分类器由6个模块构成,自底向上分别为长短时记忆神经网络(lstm)层,平均pooling层,语境注意力(attention)层,门循环神经网络(gru)层,平均pooling层和softmax层;lstm层和平均pooling层输入用户微博文本的词向量串表示,输出微博文本的向量表示;语境attention层输入用户微博的语境,输出融合了社交网络信息的用户微博的向量表示;gru层,平均pooling层和softmax层输入用户微博数据单元串的向量表示串,输出用户的主题相关立场归一化分布,即观点分布。
有益效果:本发明方法基于动态神经网络模型,同时利用用户社交网络结构信息和文本信息,动态追踪用户的实时观点,与现有的观点预测方法,本发明观点预测的准确率更高;并且本发明可以动态地更新模型,训练时间更短,在有了新的训练数据后不需从头开始训练模型。
附图说明
图1是本发明实施例的方法流程图。
图2是本发明实施例中融合社交网络结构与文本的数据集组织形式所描述的数据结构示意图。
图3是本发明实施例中动态神经网络分类器结构示意图。
具体实施方式
下面结合附图和具体实施例,进一步阐明本发明,应理解这些实例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
本发明实施例公开的一种基于社交媒体内容和结构的用户实时观点检测方法,如图1所示,该方法解决的问题为:用
一、获取微博语料
步骤1,设定好哈希标签后,将基于微博流式api的微博爬虫上线,监听整个时间线,将微博文本逐条的进行基于哈希标签的过滤抓取,每抓取到一条微博,分析微博的json格式的数据,得到微博作者的用户id,然后立刻调用微博查询式api问询用户id,抓取微博作者所关注的用户名集合。
步骤2,将抓取到的微博数据用两张表存储,分别为社交网络结构数据和社交网络内容数据,社交网络数据表以用户id为主键,每一行第一列为用户id,其他列为关注该用户的用户id;其中文本数据表以微博id为主键,每一行第一列为微博的作者的用户id,第二列为微博的文本,第三列为是否转发标识,第四列为微博的发布时间,最后一列为这条微博的id。
二、构建融合结构和内容的训练和预测数据集
步骤3,预处理融合社交网络结构数据与文本内容数据,生成符合分类器设定的训练数据和预测数据的数据结构。如图2所示,该数据结构描述如下,设
步骤4,存储融合结构和内容的数据集。将步骤3所得的数据结构,即每条用户3条微博按照时间排序,每条微博由6行表示,其中第一行为用户本人所发的微博,第2到6行为用户当时所处的语境,即邻居所发的最近的5条微博,每个用户占18行。具体组织形式如表1所示。
表1融合社交网络结构与文本的数据集数据结构
三、基于动态神经网络模型训练和预测用户的观点
步骤5,训练基于注意力机制和长短时记忆神经网络的动态观点检测模型(dynamicopiniondetectionmodel,dodm),以下简称训练dodm。
dodm的输入为步骤3所述的数据结构,即每个用户实例
dodm的结构如图3所示,它由6个模块构成,自底向上分别为长短时记忆神经网络(lstm)层,平均pooling层,语境注意力(attention)层,门循环神经网络(gru)层,平均pooling层和softmax层;其中,lstm层和平均pooling层输入用户微博文本的词向量串表示,输出微博文本的向量表示
其中,α1、α2、w、b、v、βn均为注意力机制中的参数,在本步骤中将会被训练。
门循环神经网络gru层,平均pooling层和softmax层输入的是用户微博串的向量表示
oe,u=wout·he,u(9)
其中,式(5)~式(8)为门循环神经网络(gru)的状态转移函数,he,u是
第二种直接是立场分布形式,所有主题按照立场累加起来,然后再进行归一化,类别数为s,此时运用交叉熵来计算误差损失函数:
步骤6,用训练数据集训练dodm,用预测数据集和训练好的dodm预测用户最新的观点。训练数据集以天为单位,采用增量训练的过程,每次训练完一个数据集后,将循环神经网络神经元的参数值进行保存,下次进行训练时,先载入原先的循环神经网络的参数值,然后使用最新的训练数据执行梯度下降算法,在原先已训练好的循环神经元的参数值的基础上进行更新。当有新的未标记数据,即预测数据集时,用最近训练的dodm预测用户在训练数据集上的观点。
基于动态神经网络模型的社交媒体用户实时观点检测算法流程如下:
上述算法描述的是训练的过程,关于预测的过程,可以设待预测的数据块为e+1,在实际应用场景中,对应用户最近一段时间发的尚未标注过的微博,数据的组织形式即数据结构与训练数据集的数据块一样,但没有真实标记。预测时,只需生成预测标记即可,为
本发明在实验过程中所使用的动态神经网络分类器,系本发明权益的一部分,参数设置默认学习率η为0.0005,学习率衰减系数为0.9,在英文数据集brexit和uselection上,准确率达到67.86%,性能均优于其他现有的用户观点预测方法,如csim(chenc,wangz,liw.trackingdynamicsofopinionbehaviorswithacontent-basedsequentialopinioninfluencemodel[j].ieeetransactionsonaffectivecomputing,2018.)。
本发明提出的基于社交媒体内容和结构的用户实时观点检测方法,可以解决微博社交网络多模态信息的获取和融合的问题,有利于及时追踪用户观点,促进一系列基于用户观点检测的下游应用的展开。可以解决现有的模型存在的训练时间过长,实时性差,需要耗费大量资源从头开始训练的问题,与已有的用户观点检测方法相比,本发明提出的方法基于在线爬虫和动态神经网络,在有新的标注数据时避免了从头开始训练,也就避免了批处理训练模式中存在的训练速度慢的问题。此外,本发明提出的方法采用了注意力机制,融合了社交媒体中存在的用户关系网络数据和用户微博文本数据,显著地提升了模型预测的准确性。
- 还没有人留言评论。精彩留言会获得点赞!