一种基于统计特征的社交网络用户关系的计算方法与流程
本发明涉及网络通信技术领域,尤其涉及一种基于统计特征的社交网络用户关系的计算方法。
背景技术:
基于社交网络的用户关系的应用越来越广泛,如视频推荐网站clicker与亚马逊等基于用户关系提供社会化推荐以及各社交平台中的好友推荐等应用。其中将用户关系引入推荐系统可以增加推荐结果的信任度、解决推荐系统的冷启动问题。因此如何准确地度量用户间的关系强度就成为了一个重要问题,而基于用户互动信息的度量是一种有效的解决思路。
基于用户互动信息的关系强度度量基于如下假设:两个用户间的互动越多则认为彼此间的关系越强。在现有的方法里不考虑不同用户对关系强度的敏感度的差异,然而在实际社交网络中存在以下情形:不同用户对关系强度的敏感度是有差异的;存在一些不以社交为目的而是以宣传、提供咨询等为目的的用户,这些用户对关系强度的敏感度低于以社交为目的的用户。
因此,有必要提供更准确的用户关系计算方法,以解决现有技术所存在的准确度低的问题。
技术实现要素:
本发明的目的在于克服目前用户关系计算方法中存在的准确度低的问题,提出了一种基于统计特征的社交网络用户关系计算方法,该方法根据互动记录集合得到互动频数分布,计算用户的关系强度因子,以此调整用户之间的关系强度,从而能够准确计算出用户关系强度。
为了实现上述方法,本发明提供了一种基于统计特征的社交网络用户关系计算方法,所述方法包括:
步骤1)从业务系统中采集用户互动行为数据;
步骤2)根据用户互动行为数据生成用户互动记录集合,统计用户对集合和每个用户对的互动频数分布;由此统计每个用户的互动频数分布;
步骤3)统计每个用户的互动频数总数及互动频数分布,计算每个用户的关系强 度因子;
步骤4)计算用户对集合中每对用户的关系强度。
上述技术方案中,所述步骤2)具体包括:
步骤2-1)对用户互动行为数据中的残缺数据、错误数据以及重复数据进行清洗;
步骤2-1)对用户互动行为数据中的残缺数据、错误数据以及重复数据进行清洗;
首先将缺失用户标识符的数据删除;其次检查是否符合命名规则,如果不符合则删除,符合则保留;最后将保留的数据集执行聚合操作删除重复数据;
步骤2-2)根据清洗后的数据生成互动记录集合;
根据业务系统特性将清洗后的社交类型的用户行为数据去掉冗余信息形成用户互动记录,提取互动用户双方的标识符放入用户对集合中,然后为这个互动记录加上互动双方的标识符,最后,将所有的互动记录组合生成互动记录集合;
步骤2-3)根据互动记录集合统计用户总数u、用户对集合和每个用户对的互动频数分布。
上述技术方案中,所述步骤2-2)中的互动记录集合,其中互动是不受用户关系约束的,即互动双方为好友或陌生人。
上述技术方案中,所述步骤3)的用户的关系强度因子为用户的互动频数分布的二阶中心矩、三阶中心矩或四阶中心矩。
上述技术方案中,当用户的关系强度因子为用户的互动频数分布的二阶中心矩时,用户a的关系强度因子parameter(a)的计算过程为:
从所述互动记录集合获取源用户a的互动用户集合ua,互动用户总数为|ua|;其与用户u的互动频数为ea,u,u∈ua;则用户a的互动频数分布的期望
上述技术方案中,所述步骤4)的具体实现过程为:
对于源用户a和目的用户b组成的互动用户对(a,b),源用户a对目标用户b的关系强度ta,b为:
其中,ea,b为用户a与用户b的互动频数。
上述技术方案中,所述互动用户对的关系强度是不对称的,即ta,b≠tb,a。
上述技术方案中,在所述步骤4)后,还包括:
根据统计数据为不同的用户关系类型预设对应的关系强度区间,将步骤4)计算出的用户关系强度进行关系强度区间匹配,确定用户对所属的用户关系类型;具体过程为:
通过有监督的机器学习方法获得k个阈值0≤h1<h2<…<hk,相邻两阈值间[hi,hi+1)对应第i种用户关系类型,计算出用户对的关系强度ta,b后,匹配关系强度ta,b所在的阈值区间;如果hi≤ta,b<hi+1,则将该用户对(a,b)放入第i种用户关系集合中。
本发明的优点在于:本发明的方法利用用户互动的统计特征对用户关系进行了量化,该量化值能够准确客观地体现用户之间的关系;并由此判断出用户关系所属的类型。
附图说明
图1是本发明的基于统计特征的社交网络用户关系计算方法的流程图;
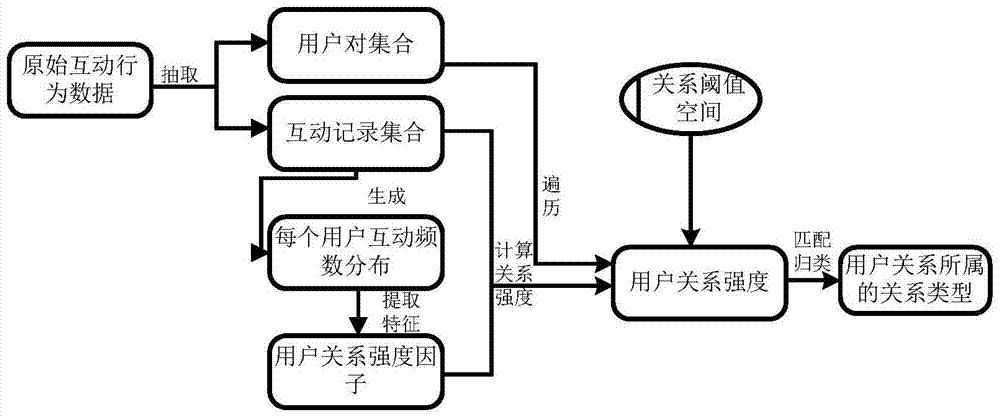
图2是本发明的方法中的用户关系类型判定的数据流程图。
具体实施方式
下面结合附图和具体实施例对本发明做进一步详细的说明。
如图1所示,一种基于统计特征的社交网络用户关系计算方法,所述方法包括:
步骤1)从业务系统中采集用户互动行为数据;
以qq空间业务系统为例,按照展示形式可分为日志版块、相册版块、说说版块、留言板版块等等,按照互动形式可分为评论、回复、点赞、访问、转载、分享等,爬虫程序遍历每个qq用户的空间,爬取其空间各个版块的互动信息,从这些信息中采集用户互动行为数据;
步骤2)根据用户互动行为数据生成用户互动记录集合,统计用户对集合和每个用户对的互动频数分布;由此统计每个用户的互动频数分布;具体包括:
步骤2-1)对用户互动行为数据中的残缺数据、错误数据以及重复数据进行清洗;
首先将缺失uid(用户标识符)的数据删除;其次检查是否符合命名规则,如果不符合则删除,符合则保留;最后将保留的数据集执行聚合操作删除重复数据。
步骤2-2)根据清洗后的数据生成互动记录集合;
根据业务系统特性将清洗后的社交类型的用户行为数据去掉冗余信息形成用户 互动记录,提取互动双方的标识符:(源用户uid,目标用户uid);放入用户对集合中,然后为这个互动记录加上互动双方的标识符,最后,将所有的互动记录组合生成互动记录集合。
所述互动记录集合,其中互动是不受用户关系约束的,即互动双方可以是好友、陌生人或者其它关系。
步骤2-3)统计用户总数u、用户对集合和每个用户对的互动频数分布;
步骤3)统计每个用户的互动频数总数及互动频数分布,由此计算每个用户的关系强度因子;
设源用户a的互动用户集合为ua,互动用户总数为|ua|;其与用户u的互动频数为ea,u,u∈ua;则用户a的互动频数分布的期望为:
在本实施例中,用户a的关系强度因子parameter(a)采用用户a的互动频数分布的二阶中心矩,计算公式为:
在其它实施例中,用户a的关系强度因子parameter(a)可以采用用户a的互动频数分布的三阶中心矩或四阶中心矩。
步骤4)计算用户对集合中每对用户的关系强度;
对于源用户a和目的用户b组成的互动用户对(a,b),源用户a对目标用户b的关系强度ta,b为:
其中,ea,b为用户a与用户b的互动频数;
将ta,b分别对ea,b求偏导得:
证明可得到:
将ta,b分别对parameter(a)求偏导得:
当
所述用户对的关系强度是不对称的,即ta,b≠tb,a。
如图2所示,在所述步骤4)后,还包括:
根据统计数据为不同的用户关系类型预设对应的关系强度区间,将步骤4)计算出的用户关系强度匹配的关系强度区间,确定用户对所属的用户关系类型;
通过有监督的机器学习方法设定阈值h;在计算出用户对的关系强度ta,b后,比较关系强度ta,b与阈值h;如果ta,b>h,则将该用户对(a,b)放入强关系集合中;如果ta,b≤h,则将该用户对(a,b)放入弱关系集合中;
优选地,通过有监督的机器学习方法获得k个阈值0≤h1<h2<…<hk,相邻两阈值间[hi,hi+1)对应第i种用户关系类型,如[h1,h2)区间对应于陌生关系;计算出用户对的关系强度ta,b后,匹配关系强度ta,b所在的阈值区间;如果hi≤ta,b<hi+1,则将该用户对(a,b)放入第i种用户关系集合中。
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!
- 用于生成和显示通过社交网络的用户内容的视觉流的技术的制作方法
- 媒体流的转移方法和用户设备的制作方法
- 用于向社交网络中的用户提醒好友位置变化的方法和设备的制作方法
- Network element for enabling a user of an IPTV system to obtain media stream ...的制作方法
- 用于模拟社交网络中离线用户的推荐的方法和系统的制作方法
- 一种用户设备的媒体信息获知方法和用户设备的制作方法
- 用于同步社交网络中的用户内容的方法和系统的制作方法
- 利用媒体提示来识别和关联用户设备的系统、方法和介质的制作方法
- 基于用户的媒体内容分节系统和方法
- 对公司社交网络的用户接收的消息进行分类的方法
- 基于对邻近一个或多个用户的媒体输出设备的动态发现的自组织(ad-hoc)媒体呈现的制作方法
- 使用确认指示来提高社交网络中的用户参与度的制作方法
- 用于生成和显示通过社交网络的用户内容的视觉流的技术的制作方法
- 在多个社交网络中识别同一用户的方法及装置的制造方法
- 媒体流的转移方法和用户设备的制作方法
- 用于向社交网络中的用户提醒好友位置变化的方法和设备的制作方法
- Network element for enabling a user of an IPTV system to obtain media stream ...的制作方法
- 用于模拟社交网络中离线用户的推荐的方法和系统的制作方法
- 一种用户设备的媒体信息获知方法和用户设备的制作方法
- 用于同步社交网络中的用户内容的方法和系统的制作方法