一种基于卷积自编码模型的唇部特征提取方法与流程
本发明涉及一种基于卷积自编码模型的唇部特征提取方法,属于计算机视觉、图像处理、人机交互等交叉技术领域。随着人工智能的发展,人机交互技术越来越多,唇语识别将机器视觉和自然语言处理结合起来,不需要听声音,仅仅依靠识别说话者的唇语动作便可解读说话者的内容。唇语识别在智慧城市、人机交互、辅助语音识别及生命健康等诸多领域都具有广泛的应用,对于噪声环境或听力障碍者更加具有重要意义。
背景技术:
计算机唇读识别是一种通过分析说话者的唇部视觉信息,包括对嘴唇、面部和舌头的运动解释来理解语言的技术,在嘈杂环境中,只利用语音识别是很复杂的,通过视觉信息来辅助语音识别提供了一种高效的理解语言的方式。由于每个人不同的口音、说话速度、面部特征以及肤色等原因,唇读变成是一个具有挑战性的问题。近些年来,唇读已经被运用到了许多应用中,唇读的应用不仅是对听障人士非常有帮助,也有助于在嘈杂环境中理解口语等,这些原因使得研究唇读这一问题具有重要的现实意义。
目前,唇读的任务主要包括两个处理块,第一个块负责从输入视频帧中提取相关特征,而另一个块负责模拟这些视频帧的特征之间的关系。前者能够从输入的视频中缩小至唇部区域并提取唇部特征,后者则是对提取的唇部区域特征进行数据分析识别,从而能够识别出说话者的内容。除此之外还包括对图像的处理等。
技术实现要素:
技术问题:发明所要解决的技术问题是视频中对唇部区域的压缩与重构,有助于帮助我们从唇部图像中提取视觉特征,从而得到更准确的潜在表示空间,能够有效提升唇读的准确性与可靠性。
技术方案:为了实现上述目的,本发明采用以下技术方案:
一种基于卷积自编码模型的唇部特征提取方法,包括以下步骤:
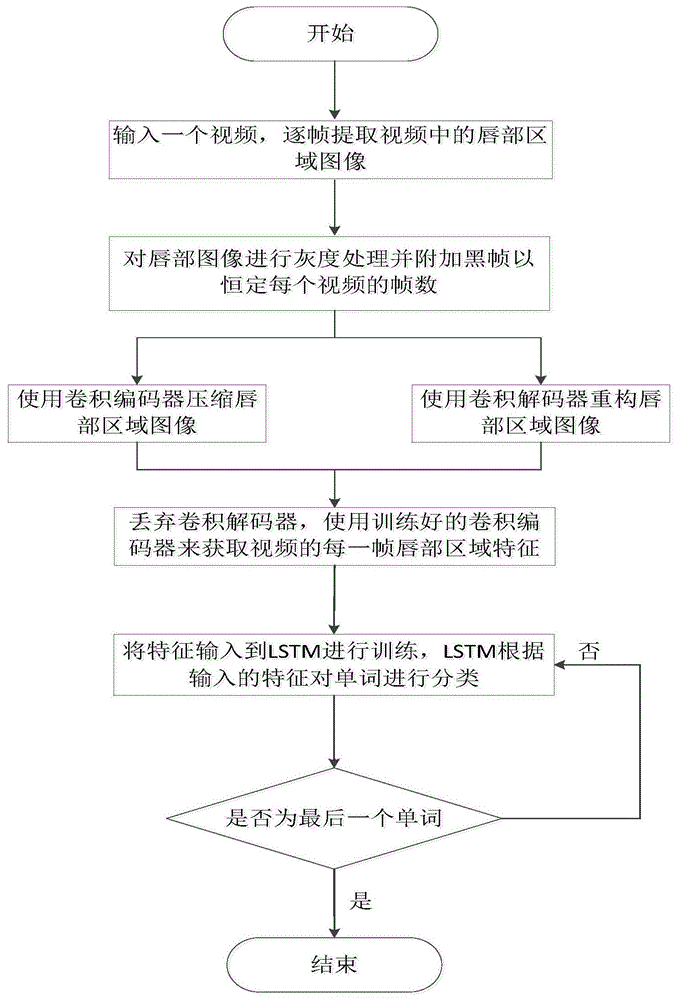
步骤1)输入一个视频,所述视频为带有唇部区域的单人说话视频,逐帧提取视频中的唇部区域图像;
步骤2)当每帧唇部区域图像被提取出来后,对每帧图像进行灰度化处理,给每个视频附加黑帧,使得视频中的帧数恒定;
步骤3)通过使用卷积自编码模型来对步骤2)中处理过后的唇部区域图像进行特征提取,所述卷积自编码模型包括通过利用输入层与输出层之间的映射关系实现样本重构,其中输入层和输出层具有相同规模;
步骤31)令输入层x={x1,x2,...,xm},输出层
步骤32)初始化h个卷积核,每个卷积核搭配一个偏置b,与输入数据x进行卷积后生成k个特征图h,公式如下:hk=f(x*wk+bk),其中:*表示二维卷积运算,w表示连接权重,f(.)表示激活函数;
步骤33)对特征图h进行池化操作,保留池化时的位置关系的矩阵,方便之后反池化的操作;
步骤34)对特征图h进行反池化操作,用到保留池化时的位置关系的矩阵,将数据还原到原始大小的矩阵的相应位置;
步骤35)每张特征图h与其对应的权矩阵的转置进行卷积操作并将结果求和,然后加上偏置c,输出数据为:
步骤36)确定损失函数来更新权值,此处采用最小均方差函数,公式如下:
步骤37)当确定损失函数后,对w和b求导,通过梯度下降法调整权重参数最小化重构误差,目标函数梯度值公式如下:
步骤4)当训练好卷积自编码模型后,丢弃卷积解码器,使用卷积编码器获取视频的每一帧特征;
步骤5)当获取到每个帧的特征时,对lstm进行训练,所述lstm为长短期记忆网络,包括输入门、遗忘门和输出门;
步骤51)将特征输入到lstm进行训练,lstm根据输入的特征输出概率以对单词进行分类;
步骤52)经过步骤4)提取唇部图像的每一帧特征
步骤53)使用lstm完成一个输入序列到输出类别的映射:
步骤54)输入特征经过第1层lstm层,输出为h1∈rn'×t,所述n'为隐藏层的节点个数;
步骤55)经过第2层lstm层,输出为h2∈rn'×t;
步骤56)在lstm最后一层,最后一层设为第l层,最后一个时间点输出为
步骤57)使用softmax将
进一步地,所述步骤1中,通过使用opencv中的haar-cascade逐帧提取视频中的唇部区域图像,利用基于adaboost级联的haar分类器来筛选有效地矩形特征,进而分类识别唇部区域图像,采用opencv中已经训练好的haarcascade_smile.xml来检测唇部区域图像。
进一步地,所述步骤2中,灰度化处理是指使用灰度缩放图像代替彩色图像。
有益效果:本发明采用以上技术方案与现有技术相比,具有以下技术效果:
本发明首先通过对用户输入的视频逐帧提取唇部区域;然后对每帧唇部区域图像进行处理;处理完成后利用卷积自编码器模型来提取唇部区域图像特征,最后将特征输入到lstm进行训练,lstm根据输入的特征对单词进行分类,从而完成对唇部的读取。
具体来说:
(1)本发明采用了opencv中已经训练好的haar特征分类器,直接利用haarcascade_smile.xml文件就可以方便的提取出唇部图像。
(2)本发明通过基于卷积自编码器模型的唇部特征提取方法,可以有效地帮助我们从唇部图像中提取视觉特征,以得到更准确的潜在表示空间,能够有效提升唇读的准确性和可靠性。
附图说明
图1是基于卷积自编码模型的唇部特征提取方法;
图2是卷积自编码模型。
具体实施方式
下面结合附图对本发明的技术方案做进一步的详细说明:
如图1和2所示,一种基于卷积自编码模型的唇部特征提取方法,包括以下步骤:
步骤1)首先输入一个带有唇部区域的单人说话视频,通过使用opencv中的haar-cascade逐帧提取视频中的唇部区域,所述唇部区域的提取是指利用基于adaboost级联的haar分类器来筛选有效地矩形特征来分类识别,本说明采用opencv中已经训练好的haarcascade_smile.xml来检测唇部,部分代码如下:
paths='d:/opencv/opencv/build/etc/haarcascades/haarcascade_smile.xml';
lip_cascade=cv.cascadeclassifier(paths);//加载分类器
lip=lip_cascade.detectmultiscale(face_re_g);//检测唇部
步骤2)当每帧唇部区域图像被提取出来后,对每帧唇部区域图像进行灰度化处理,所述灰度化处理是指使用灰度缩放图像代替彩色图像,其中给每个视频附加黑帧,使得视频中的帧数恒定,
步骤3)通过使用卷积自编码模型来对步骤2)中处理过后的唇部区域图像进行特征提取,所述的卷积自编码模型包括通过利用输入层与输出层之间的映射关系实现样本重构,其中输入层和输出层具有相同规模;
步骤31)令输入层x={x1,x2,...,xm},输出层
步骤32)初始化h个卷积核,每个卷积核搭配一个偏置b,与输入数据x进行卷积后生成k个特征图h,公式如下:hk=f(x*wk+bk),其中:*表示二维卷积运算,w表示连接权重,f(.)表示激活函数;
步骤33)对特征图h进行池化操作,保留池化时的位置关系的矩阵,方便之后反池化的操作;
步骤34)对特征图h进行反池化操作,用到保留池化时的位置关系的矩阵,将数据还原到原始大小的矩阵的相应位置;
步骤35)每张特征图h与其对应的权矩阵的转置进行卷积操作并将结果求和,然后加上偏置c,输出数据
步骤36)确定损失函数来更新权值,此处采用最小均方差函数,公式如下:
步骤37)当确定损失函数后,对w和b求导,通过梯度下降法调整权重参数最小化重构误差,目标函数梯度值公式如下:
步骤4)当训练好卷积自编码模型后,丢弃卷积解码器,使用卷积编码器来获取视频的每一帧特征;
步骤5)当获取到每个帧的特征时,对lstm进行训练,所述lstm为长短期记忆网络,包括输入门、遗忘门和输出门;
步骤51)将特征输入到lstm进行训练,lstm根据输入的特征输出概率以对单词进行分类;
步骤52)经过步骤4)提取唇部图像的每一帧特征
步骤53)使用lstm完成一个输入序列到输出类别的映射:
步骤54)输入特征经过第1层lstm层,输出为h1∈rn'×t,所述n'为隐藏层的节点个数;
步骤55)经过第2层lstm层,输出为h2∈rn'×t;
步骤56)在lstm最后一层(设为第l层)最后一个时间点输出为
步骤57)使用softmax将
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!