自动化的配电变压器重过载流水线数据处理及预测方法与流程
本发明涉及一种自动化的配电变压器重过载流水线数据处理及预测方法,是一种对配电变压器的重过载情况进行自动化预测的方法。
背景技术:
配电变压器是电能分配的关键设备,承载着电网末端的供电能力,它的负载状态的轻重决定了用户所使用的电能的质量的好坏。如果配电变压器发生故障,可导致其所供台区发生停电,由此影响供电可靠性和用户满意度,进而损害供电企业的社会形象。
对于配电变压器负载状态的评估和预判,一直以来都缺乏有效的在线监测方式和技术手段来支撑,主要依靠人工经验,这种传统的评估方式存在无法覆盖所有配电变压器和评估结果不准等问题。随着电网用户对供电质量和可靠性的要求越来越高,对于配变重过载预测的需求也日趋突出,迫切需要一种能够减少人工投入,同时能提高配变重过载状态预测效率和精度的技术方法。
技术实现要素:
本发明的提出正是为了解决人工分析和预测配变重过载所存在问题,通过一个配变重过载数据处理流水线框架实现数据处理的自动化、流水线作业,无需人工干预。通过大数据处理技术,解决海量数据的运算问题,通过为每个变压器构建独立的多层神经网络模型解决预测不准确的问题。
为了实现上述目的,本发明提供如下技术方案:
1)配变重过载数据处理流水线框架
该框架实现了流水线处理中所需的任务及作业抽象,作业包含多个任务,任务对象支持众多的运行参数的自定义,包括:
·可定义任务的执行参数
·可定义任务的输入、输出、执行过程
·可定义任务的分片策略和并发数量
·可定义任务的依赖任务,通过依赖关系构建流水线
·可定义任务能使用的资源,如cpu、内存
2)基于mapreduce的数据预处理任务流水线
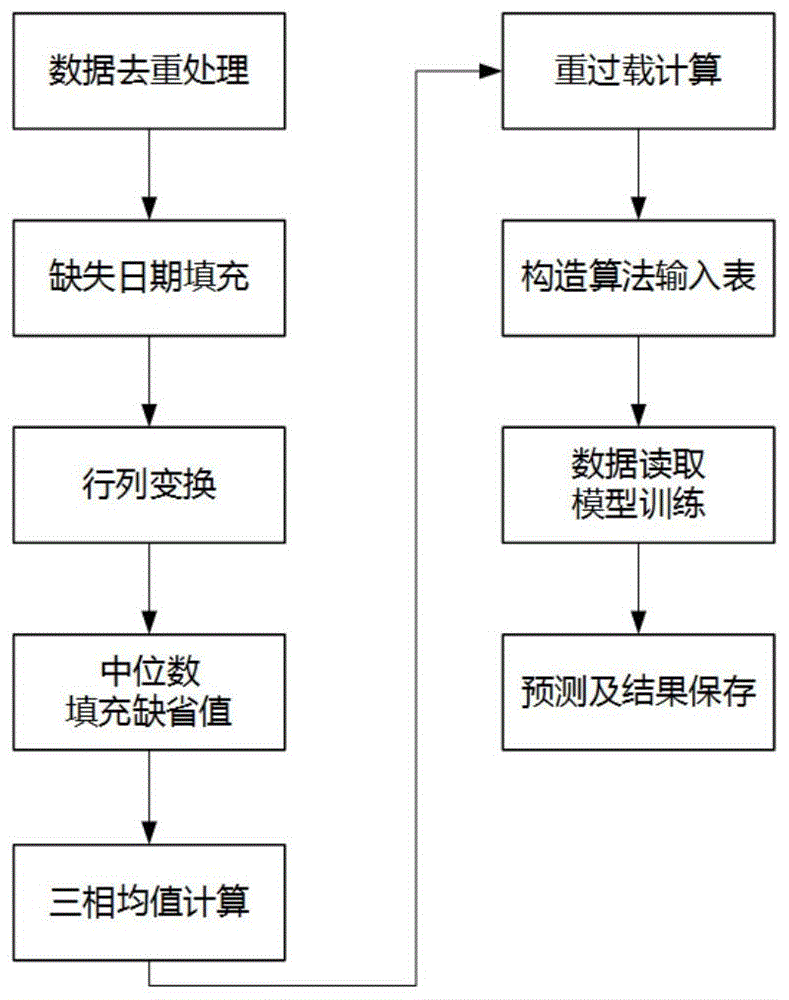
为解决处理100g+原始数据的性能问题,采用mapreduce来提升预处理任务的吞吐能力和性能;数据预处理任务包括:数据去重、处理缺失值、行列变换、三相均值计算、重过载的计算、构造算法特征;同时,采用上述流水线框架,实现各个任务间的前后依赖与自动执行;
数据处理的对象是变压器的15分钟电流数据,包括a/b/c三相电流数据,数据处理的流程如下:
a.根据变压器id、数据采集时间、相别这三个字段对数据去重
读取变压器的电流数据表,包括:变压器id、数据采集时间、相别、采集值等字段,分别记为:tid,dt,phase,value。根据tid,dt,phase这三列进行去重操作,得到唯一的去重后数据,结果表的格式:tid,dt,phase,value;
b.根据变压器id、数据采集日期、相别进行分组,补上缺失日期的数据
根据dt得到对应的日期值(y/m/d),记为date,对tid,date,phase进行分组统计,从而得到其缺失数据的日期,对每个tid,phase所缺失的日期,补上该日期的00:00:00的数据即可,通过后续的行列变换,即可生成出其他95个时间点的列,结果表的格式:tid,dt,date,phase,value;
c.根据变压器id、数据采集日期、相别做行列转换
将原来每天96个时间点的值按照15分钟数据的顺序转换到同一行数据上,将96行数据变为96个列。即对tid,dt,date,phase,value应用行转列变换,将原来每天的96条数据转换到同一行上,变换后的格式为:tid,date,phase,v1,v2,v3,…,v96;
d.根据变压器id、相别分组并计算中位数,用中位数填充缺失值
用变压器id、相别分组后计算96列的中位数,用计算得到的中位数填充缺失值,即计算每个tid、phase组合的96列(v1,v2,v3,…,v96)的中位数,用计算得到的中位数填充该tid、phase组合的96列的缺失值,结果表的格式:tid,date,phase,v1,v2,v3,…,v96;
e.根据变压器id、数据采集日期,计算96列的负载率
根据tid,date进行分组,计算以上96列(v1,v2,v3,…,v96)的a/b/c三相的电流均值:cai,得到中间表:tid,date,ca1,ca2,ca3,…,ca96;
根据变压器额定容量换算得到额定电流cr,计算以上每个日期的96列的负载率:
得到负载率表:tid,date,r1,r2,r3,…,r96。
f.按天计算配变的重过载状态
用h和o分别表示重载、过载的百分比的值,一般情况下h=100%,o=80%。根据重过载标准,油式变压器持续2小时、干式变压器持续1小时处于h和o之上则记为发生重载或过载;
此过程转换为计算逻辑为:将ri大于h和o的值记为字符1,将ri小于h和o的记为0,再96列的0、1字符进行字符串拼接,得到一个长度为96的字符串,再用正则表达式匹配字符串,即可得到其是否发生重过载;
记发生重载为1、过载为2,则可得到重过载结果表,包括列:tid,date,result;
g.构造算法输入表
连接负载率表(tid,date,r1,r2,r3,…,r96)和重过载结果表(tid,date,result),得到算法输入表(tid,date,r1,r2,r3,…,r96,result)。由于这是一个时序预测问题,数据本身具有自相关性,为此本方法采用日期平移的方法对输入表进行处理,将date加1以便得到预测日期的算法输入数据;
3)数据读取与模型训练的并行化
为减少读取100g+的输入数据所造成的i/o长时等待,解决无法将全量数据载入内存的问题,提升模型训练的整体效率,基于消费者/生产者模式实现了数据读取和模型训练的并行化;采用分批读取的方式,每读取完一批数据后立即将此批次数据投入模型训练,从而实现模型训练和数据读取的并行,由于模型训练属于cpu密集型计算,而数据读取属于io密集型,并行处理可以最大化地利用硬件资源;
4)多层神经网络模型
基于多层神经网络,为每一个变压器构建一个独立的预测模型,充分考虑不同变压器的个性化特点,用训练得到的多层神经网络实现重过载的预测;
本发明使用的神经网络模型包含1个输入层、3个隐含层、1个输出层,按照数据的分片策略将每个tid对应的数据切分为一个独立的数据集,输入多层神经网络模型。输入表的格式为:(tid,date,r1,r2,r3,…,r96,result),由于是先按照tid分组,再按照date进行排序,所以将每一组训练数据的格式简化为:(r1,r2,r3,…,r96,result),其中,r1,r2,r3,…,r96用于输入,result用于输出。
本发明的有益效果是,提出了一个配变重过载数据处理及预测的流水线作业框架,基于该框架实现数据预处理、数据加载、模型训练、预测结果存储的自动化流水线作业;其中,在数据预处理阶段,通过mapreduce大数据技术,解决了处理100g+电流数据的性能问题,使得本方法可支持数量众多的配电变压器的数据加工;另外,在模型构建阶段,基于多层神经网络为每一个变压器构建一个独立的预测模型,充分考虑不同变压器的个性化特点,从而提升预测的准确性;同时,通过任务分片和并行计算,来提高模型训练过程的运行效率。
附图说明
图1为本发明结构框图。
具体实施方式
下面根据说明书附图并结合具体实施例对本发明的技术方案进一步详细表述。请参阅图1,图1为本发明提供的一种自动化的配电变压器重过载流水线数据处理及预测方法流程图,包括如下步骤:
1)配变重过载数据处理流水线框架
该框架实现了流水线处理中所需的任务(task)、作业(job)等抽象,作业可包含多个任务;支持任务对象的自定义,包括:
·可定义任务的执行参数
·可定义任务的输入、输出、执行过程
·可定义任务的分片策略和并发数量
·可定义任务的依赖任务,通过依赖关系构建流水线
·可定义任务能使用的资源,如cpu、内存
2)基于mapreduce的数据预处理任务流水线
本方法采用mapreduce来提升预处理任务的吞吐能力和性能,数据处理的对象是电流数据,数据预处理任务包括:数据去重、处理缺失值、行列变换、三相均值计算、重过载的计算、构造算法特征。同时,采用上述流水线框架,实现各个任务间的前后依赖与自动执行。具体的任务包括:
a)数据去重
读取变压器的电流数据表,包括:变压器id、数据采集时间、相别、采集值等字段,分别记为:tid,dt,phase,value。根据tid,dt,phase这三列进行去重操作,得到唯一的tid,dt,phase,value数据,结果表的格式:tid,dt,phase,value。
b)填充缺失日期
根据dt得到其日期值(y/m/d),记为date,对tid,date,phase进行分组统计,从而得到其缺失数据的日期。对于每个tid,phase所缺失的日期,只需补上00:00:00的数据即可,通过后续的行列变换,即可生成出其他95个时间点的列,结果表的格式:tid,dt,date,phase,value。
c)行列变换
对上一步得到的tid,dt,date,phase,value应用行转列变换,将原来每天的96条数据转换到同一行上,变换后的格式为:tid,date,phase,v1,v2,v3,…,v96。
d)填充缺失值
根据tid,phase进行分组,分别计算每个tid、phase组合的96列(v1,v2,v3,…,v96)的中位数,用计算得到的中位数填充该tid、phase组合的缺失值。
e)计算三相电流均值和负载率
首先,根据tid,date进行分组,计算以上96列(v1,v2,v3,…,v96)的a/b/c三相的电流均值:cai,得到结果表:tid,date,ca1,ca2,ca3,…,ca96。
其次,根据变压器额定容量cap换算变压器的额定电流cr,计算公式为:
然后,计算以上每个日期的96列的负载率,得到负载率表:tid,date,r1,r2,r3,…,r96,计算公式如下:
f)按天计算配变的重过载状态
用h和o分别表示重载、过载的百分比的值,一般情况下h=100%,o=80%。根据重过载标准,油式变压器持续2小时、干式变压器持续1小时处于h和o之上则记为发生重载或过载。
此过程转换为计算逻辑为:将ri大于等于h和o的值记为字符1,将ri小于h和o的记为0,再将每个日期的ri进行字符串拼接,得到一个长度为96的0、1字符串,再用正则表达式匹配字符串,即可得到其是否发生重过载。
如某干式变压器一天数据超过h=100%的结果可转换为字符串:
01000000000000110111111100010…….101010101111111000001
用正则表达式匹配连续出现4个1的子字符串,即可实现重过载的判断,记重载为1,过载为2,则得到重过载结果表,包括列:tid,date,result。
g)构造算法输入表
连接负载率表(tid,date,r1,r2,r3,…,r96)和重过载结果表(tid,date,result),得到算法输入表(tid,date,r1,r2,r3,…,r96,result)。由于这是一个时序预测问题,数据本身具有自相关性,为此本方法采用日期平移的方法对输入表进行处理,将date加1以便得到预测日期的算法输入数据。
3)数据读取与模型训练的并行化
为减少读取100g+的输入数据所造成的i/o长时等待,提升模型训练的整体效率,基于消费者/生产者模式实现了数据读取和模型训练的并行化。
a)生产者-读取数据
生产者的作用是读取算法的输入表数据并放入队列,由于输入表的数据量巨大,如果采用传统的顺序读取,将耗费数小时才能完成。由于读取数据属于i/o密集型任务,为此设置此任务的分片策略为输入表的变压器id列(tid),每2000~5000个tid为一组,设置cpu的使用数量为2~3核。
b)消费者-模型训练
消费者负责从队列中获取数据集,进行模型训练和预测。由于模型训练和预测属于计算密集型任务,所以可将服务器上剩余的cpu资源全部都分配给消费者进行模型训练。为此,设置此任务的分片策略为输入表的变压器id列(tid),每个tid的所有数据为一个单独的任务处理对象,设置cpu数量为:总的cpu核心数–生产者使用核心数。
4)多层神经网络模型
本方法使用的神经网络模型包含1个输入层、3个隐含层、1个输出层。上一步骤的数据消费者获取到数据后,按照分片策略将每个tid对应的数据切分为一个独立的数据集,传入多层神经网络模型。由前面的步骤生成的算法输入表格式为:(tid,date,r1,r2,r3,…,r96,result),由于已经按照tid分组,再按照date进行了排序,所以可将输入表的格式设置简化为:(r1,r2,r3,…,r96,result)。
根据输入表的格式设置神经网络的参数,其中输入层节点数为96(r1,r2,r3,…,r96),输出层节点数是result的类别数量,即重载、过载、正常,因此设置为3。另外,根据反复多次的实验和经验,设置神经网络的batchsize为120,学习率为0.01。
5)预测及结果保存
此为流水线处理的最后一个任务,该任务直接获取上一步骤所得到的神经网络模型,并用模型对未来重过载情况进行预测,再将预测结果持久化至数据库中。
- 还没有人留言评论。精彩留言会获得点赞!