一种关联实体的情感信息表示方法与流程
本发明属于情感信息表示技术领域,特别涉及一种关联实体的情感信息表示方法。
背景技术:
文本情感分析是通过对文本进行分析、归纳、处理等完成对文本情感极性的判别。在文本情感分析任务中,文本的词语信息,尤其是带有情感色彩的词语能直接影响文本的情感极性。在带实体的文本情感分析任务中,需要针对文本中不同的实体进行情感极性判断,这不仅要考虑文本本身,同时也要考虑文本中不同的实体信息。在现实的文本数据中,同一文本往往会存在多个实体,而不同实体会有不同的情感表达。另一方面,针对不同的实体,就算使用同一个修饰词,可能会出现完全相反的情感极性。例如“汽车的噪音很大”、“汽车的空间很大”,同样是形容实体“汽车”属性的词语“大”在形容“汽车噪音”时是消极情感,而在形容“汽车空间”时是积极情感。
传统的词语信息表示方法很多,例如:one-hot表示方法和将词语表示成连续值向量的词向量表示方法(连续词袋模型,continuesbagofwords和跳跃多元文法,skipn-gram)等。这类方法通过将词语表示成一个多维的向量来供模型学习和调整,能学习到词语在文本中的特征信息。但是,上述方法通常只考虑词语本身,以及词语和文本中其他词语的依赖关系。所以针对不同场景、不同实体、以及不同实体的属性,词语都只有相同的向量表示。针对带实体的情感分析任务,目前常用的方法是将特定实体的表示和不同词语拼接,构造新的词语表示,或者加入外部的知识库或者依存句法分析等来获取不同词语和实体之间的联系。这些方法虽然能在一定程度上解决多实体文本情感分析任务中的词语信息表示问题,但是仍存在一些缺点:
1.结合实体向量表示的方法会给不同词语加入相同的向量信息,不能有效区分不同词语对实体或实体属性的贡献程度;
2.结合外部知识的方法需要高度依赖外部知识的质量,当引入的信息不恰当时,反而会给模型的学习带来挑战;
3.这类方法都没有针对特定实体、实体属性来对不同词语构造向量表示,使词语在修饰不同实体时有不同的表示,并且对词语的重要程度进行区分。
技术实现要素:
为克服已有技术的不足之处,本发明提出一种关联实体的情感信息表示的方法,可以在不使用外部知识的情况下对词语进行针对性的向量微调,使词语在关联不同实体时有不同的向量表示,有效判别不同实体或实体属性的情感极性。
为了实现上述目的,本发明采用的技术方案为:
一种关联实体的情感信息表示方法,其特征在于,该方法包括下列步骤:
步骤一),利用维基百科语料训练大规模的词向量作为文本中词语的通用词向量表示;
步骤二),结合强化学习q学习方法针对文本中不同的实体和实体属性对词语的词向量进行微调,使词语在修饰不同实体或实体属性时有不同的向量表示;
步骤三),将学习获得的词语情感信息向量表示应用到特定的文本情感分析任务中。
用ε-greedy来选取下一个词语,并对不同实体赋予不同的奖赏值。
相比于现有的技术,本发明的优点有:
1、本发明所提出的结合强化学习中q学习来对词向量进行微调的方法,能在不使用外部知识的情况下对词语进行针对性的向量微调,使词语在关联不同实体时有不同的向量表示
2、使用ε-greedy方法能获取文本中距离实体或实体属性较远的词语对实体或实体属性的情感联系。
3、使用本发明提出的微调后的词向量来表示输入文本,能在不使用注意力机制的情况下,有效判别不同实体或实体属性的情感极性。
附图说明
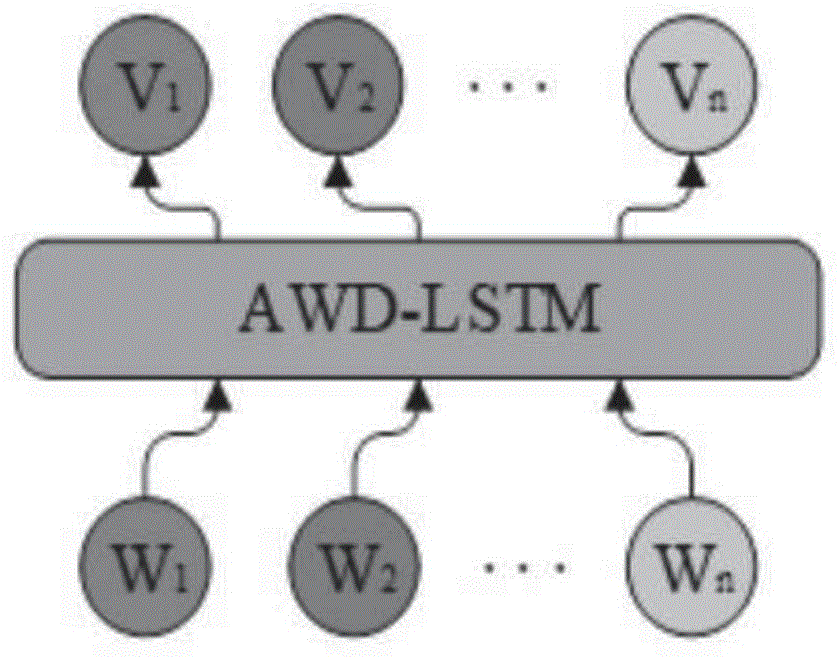
图1是通用词向量训练;
图2是使用微调词向量的分类模型。
具体实施方式
下面结合附图说明及具体实施方式对本发明进一步说明。
本发明为一种关联实体的情感信息表示方法。
本方法的主要步骤有:
步骤1:利用维基百科语料训练大规模的词向量作为文本中词语的通用词向量表示;
步骤2:结合强化学习q学习方法针对文本中不同的实体和实体属性对词语的词向量进行微调,使词语在修饰不同实体或实体属性时有不同的向量表示;
步骤3:将学习获得的词语情感信息向量表示应用到特定的文本情感分析任务中。
本方法示意图见附图1、2。
在上述方法步骤一中,使用大规模的维基百科语料训练通用词向量,具体如下(附图1所示):
1.从维基百科中爬取足量的语料,并对语料进行预处理,过滤掉对任务没有作用的文本;
2.使用深度语言模型网络(asgdweight-droppedlong-shorttermmemory,awd-lstm)在维基百科语料上进行词向量训练,获取词条的词向量集合。
在上述方法步骤二中,利用强化学习中的q学习和awd-lstm网络在特定任务语料中对词向量进行微调整:
vs,w=vs,w+α(ri+γmaxw′vs′,w′-vs,w)
其中,vs,w为当前词语的向量表示,vs′,w′为从当前词语到达下一个词语的向量表示,ri为针对实体或实体属性i给出的本次词语移动的奖赏值,α为学习率,γ为奖赏衰变系数。在本发明中,以某一实体或实体属性为中心,使词语沿着该实体或者实体属性移动,每移动一个词语,赋予一个奖赏0,当词语移动至实体或实体属性i时赋予一个特定的奖赏ri。通过对不同实体和实体属性设置不同奖赏的方法,能在学习过程中对不同词语进行针对性的调整。同时,通过使词语逐步移动的方法,也能区别不同词语对实体或实体属性的情感影响程度。
此外,在现实的文本中,某些对实体有高度关联的词语可能会出现在离实体较远的地方,此时使用上述的微调方法将无法很好地学习这些词语对实体或实体属性的情感联系。为了解决该问题,本发明在上述方法中使用了ε-greedy来选取下一次的词语,即以ε的概率在文本中随机选取词语。通过该方法能有效获取那些离实体较远但有着重要影响的词语对实体或实体属性的情感联系。
在微调词向量方法中,使用均方误差来定义目标函数:
l(v)=e(ri+γmaxw′vs′,w′-vs,w)2
在上述方法步骤三中,采用传统的长短期记忆网络(long-shorttermmemory,lstm)对特定语料进行带实体的文本情感分析。具体方法如下(附图2所示):
步骤31):使用微调后的词向量来表示输入文本,并将文本按时序输送到lstm网络中。
步骤32):通过lstm网络对1中的词向量矩阵进行学习和调参可以得到文本的抽象化特征表示:
h=[h1,h2,...,hn]
步骤33)将2中得到的最后一层网络的抽象化特征作为全连接层的输入,通过softmax函数可以得到关联实体的情感分析结果。
y=softmax(whn+b)。
综上,该方法能在不使用外部知识的情况下对词语进行针对性的向量微调,使词语在关联不同实体时有不同的向量表示,使用ε-greedy方法能获取文本中距离实体或实体属性较远的词语对实体或实体属性的情感联系,微调后的词向量来表示输入文本,能在不使用注意力机制的情况下,有效判别不同实体或实体属性的情感极性。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!