一种基于K-均值聚类算法的初始聚类中心确定方法及装置与流程
本发明涉及机器学习领域,特别是指一种基于k-均值聚类算法的初始聚类中心确定方法及装置。
背景技术:
随着媒体技术的不断进步和信息传播渠道的日趋多元化,当今社会进入了“人人都是新闻传播者”的自媒体时代。广大网民参与言论的热情高涨,特别是微博的兴起,网民可以通过电脑、手机随时随地发表言论。自新浪微博—twitter类的新兴网络应用推出以来,注册用户、月活跃用户及每日用户发博量增长极快,微博上的舆论已成为网络舆情中极具影响力的一种。如何从海量数据中快速有效地发现网民关注的热门话题,从而引导政府相关部门及时捕捉微博中敏感的舆论信息,合理地控制负面舆论的扩散。目前,很多政府机关采用全人工或是半自动的监测统计方法,效率低,准确度也低。因此,迫切需要一种更为有效的微博热点话题发现方法。
k均值(k-means)聚类算法是一种最为经典、使用最为广泛的划分聚类算法,经常被用于网络舆情的聚类中。但是,其使用有一定的局限性,例如,初始聚类中心的选择方法不一,若选取到孤立点,往往导致最终聚类结果陷入局部最优。
技术实现要素:
本发明要解决的技术问题是提供一种基于k-均值聚类算法的初始聚类中心确定方法及装置,以解决现有的k-均值聚类算法的初始聚类中心选取到孤立点,易导致聚类结果陷入局部最优的问题。
为解决上述技术问题,本发明实施例提供一种基于k-均值聚类算法的初始聚类中心确定方法,包括:
获取数据对象集合,其中,所述数据对象集合包括:微博文档集合;
确定数据对象集合中每个数据对象与其它数据对象间的平均相似度,获取平均相似度大于等于预先设定的密度阈值的数据对象作为核心对象;
从核心对象中选取彼此间最不相似的多个核心对象作为k-均值聚类算法的初始聚类中心,以便k-均值聚类算法根据得到的初始聚类中心进行聚类。
进一步地,所述确定数据对象集合中每个数据对象与其它数据对象间的平均相似度,获取平均相似度大于等于预先设定的密度阈值的数据对象作为核心对象包括:
确定微博文档集合中任意两个文档间的相似度,将相似度保存至相似度矩阵中;
根据相似度矩阵,计算每一个文档与其他文档两两之间的平均相似度,获取平均相似度大于等于预先设定的密度阈值的文档,形成核心文档集合。
进一步地,两个文档bi和bj之间的相似度similarity(bi,bj)表示为:
其中,bik、bjk分别表示文档bi和bj第k个特征项的权值,n是bi中特征项的总数目,tfk(bi)是指第k个特征项在bi中出现的次数,nbl是微博文档集合中文档的数目,nk表示包含第j个特征项的微博文档的个数。
进一步地,文档b与其他文档两两之间的平均相似度density(b)表示为:
density(b)=∑x∈blsimilarity(x,b)/nbl
其中,bl表示微博文档集合,nbl表示微博文档集合中文档的数目。
进一步地,所述从核心对象中选取彼此间最不相似的多个核心对象作为k-均值聚类算法的初始聚类中心包括:
s31,将核心文档集合中的第一个核心文档作为第一个初始聚类中心点centers[1],并从核心文档集合中删除该核心文档,令计数参数k=1,同时,将centers[1]置为当前聚类中心点;
s32,遍历核心文档集合中剩余的核心文档,选择与当前聚类中心点最不相似的核心文档作为下一个初始聚类中心,添加到初始聚类中心点centers中,并从核心文档集合中删除该核心文档;
s33,更新当前聚类中心点,并使k=k+1,转s32;
s34,重复执行s32和s33,直至k与预设的聚类簇数k值相等为止,输出初始聚类中心点centers。
本发明说实施例还提供一种基于k-均值聚类算法的初始聚类中心确定方法,包括:
获取模块,用于获取数据对象集合,其中,所述数据对象集合包括:微博文档集合;
确定模块,用于确定数据对象集合中每个数据对象与其它数据对象间的平均相似度,获取平均相似度大于等于预先设定的密度阈值的数据对象作为核心对象;
选取模块,用于从核心对象中选取彼此间最不相似的多个核心对象作为k-均值聚类算法的初始聚类中心,以便k-均值聚类算法根据得到的初始聚类中心进行聚类。
进一步地,所述确定模块包括:
确定单元,用于确定微博文档集合中任意两个文档间的相似度,将相似度保存至相似度矩阵中;
形成单元,用于根据相似度矩阵,计算每一个文档与其他文档两两之间的平均相似度,获取平均相似度大于等于预先设定的密度阈值的文档,形成核心文档集合。
进一步地,两个文档bi和bj之间的相似度similarity(bi,bj)表示为:
其中,bik、bjk分别表示文档bi和bj第k个特征项的权值,n是bi中特征项的总数目,tfk(bi)是指第k个特征项在bi中出现的次数,nbl是微博文档集合中文档的数目,nk表示包含第j个特征项的微博文档的个数。
进一步地,文档b与其他文档两两之间的平均相似度density(b)表示为:
density(b)=∑x∈blsimilarity(x,b)/nbl
其中,bl表示微博文档集合,nbl表示微博文档集合中文档的数目。
进一步地,所述选取模块包括:
删除单元,用于将核心文档集合中的第一个核心文档作为第一个初始聚类中心点centers[1],并从核心文档集合中删除该核心文档,令计数参数k=1,同时,将centers[1]置为当前聚类中心点;
遍历单元,用于遍历核心文档集合中剩余的核心文档,选择与当前聚类中心点最不相似的核心文档作为下一个初始聚类中心,添加到初始聚类中心点centers中,并从核心文档集合中删除该核心文档;
更新单元,用于更新当前聚类中心点,并使k=k+1,转遍历单元;
输出单元,用于重复执行遍历单元和更新单元,直至k与预设的聚类簇数k值相等为止,输出初始聚类中心点centers。
本发明的上述技术方案的有益效果如下:
上述方案中,通过确定数据对象集合中每个数据对象与其它数据对象间的平均相似度,获取平均相似度大于等于预先设定的密度阈值的数据对象作为核心对象,其中,所述数据对象集合包括:微博文档集合;从核心对象中选取彼此间最不相似的多个核心对象作为k-均值聚类算法的初始聚类中心,以便k-均值聚类算法根据得到的初始聚类中心对微博文档集合进行聚类。这样,不仅可以消除初始聚类中心选取到孤立点可能导致聚类结果陷入局部最优的不良影响,还提高了微博聚类的准确性、稳定性,并能够快速、准确地从大量的微博数据中发现舆情热点话题。
附图说明
图1为本发明实施例提供的基于k-均值聚类算法的初始聚类中心确定方法的流程示意图;
图2为本发明实施例提供的微博文档预处理流程示意图;
图3为本发明实施例提供的基于k-均值聚类算法的初始聚类中心确定方法的详细流程示意图;
图4为本发明实施例提供的基于k-均值聚类算法的初始聚类中心确定装置的结构示意图。
具体实施方式
为使本发明要解决的技术问题、技术方案和优点更加清楚,下面将结合附图及具体实施例进行详细描述。
本发明针对现有的k-均值聚类算法的初始聚类中心选取到孤立点,易导致聚类结果陷入局部最优的问题,提供一种基于k-均值聚类算法的初始聚类中心确定方法及装置。
实施例一
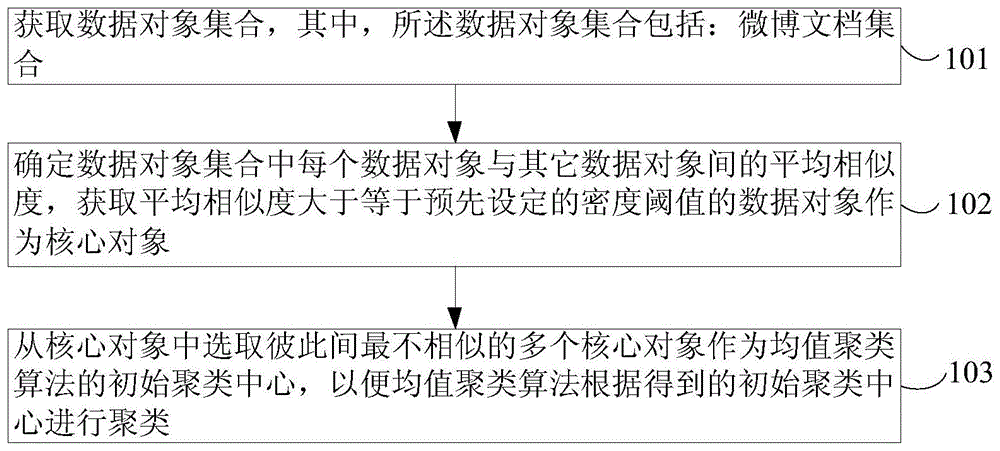
如图1所示,本发明实施例提供的基于k-均值聚类算法的初始聚类中心确定方法,包括:
s101,获取数据对象集合,其中,所述数据对象集合包括:微博文档集合;
s102,确定数据对象集合中每个数据对象与其它数据对象间的平均相似度,获取平均相似度大于等于预先设定的密度阈值的数据对象作为核心对象;
s103,从核心对象中选取彼此间最不相似的多个核心对象作为k-均值聚类算法的初始聚类中心,以便k-均值聚类算法根据得到的初始聚类中心进行聚类。
本发明实施例所述的基于k-均值聚类算法的初始聚类中心确定方法,通过确定数据对象集合中每个数据对象与其它数据对象间的平均相似度,获取平均相似度大于等于预先设定的密度阈值的数据对象作为核心对象,其中,所述数据对象集合包括:微博文档集合;从核心对象中选取彼此间最不相似的多个核心对象作为k-means聚类算法的初始聚类中心,以便k-means聚类算法根据得到的初始聚类中心对微博文档集合进行聚类。这样,不仅可以消除初始聚类中心选取到孤立点可能导致聚类结果陷入局部最优的不良影响,还提高了微博聚类的准确性、稳定性,并能够快速、准确地从大量的微博数据中发现舆情热点话题。
本实施例中,在s101中,可以通过微博抓取工具,抓取不同类别的数千个微博文档,经文本去噪、中文分词、删除停用词等预处理操作后,用本发明实施例提供的基于k-均值聚类算法的初始聚类中心确定方法对数千个微博文档进行聚类分析。
如图2所示,可以对微博文档进行如下预处理操作:
a1,文本去噪
文本去噪是去除微博文档中存在的那些毫无意义的文字或者符号和那些没有实际意义的字数过少的信息。
a2,中文分词
中文分词是指将一个汉字序列分成一个个单独的词,使用现有的分词软件在去噪的中文文本中词与词之间自动加上空格。
a3,删除停用词
停用词指的是那些出现频率很高但是对文本分类、聚类却没有太大作用的单词,比如中文中的“别”,“将”。通过设置好的停用词表来进行停用词的删除。
经过步骤a1、a2、a3之后,可以得到预处理后的微博文档。
本实施例中,为了更好地理解本发明实施例提供的基于k-均值聚类算法的初始聚类中心确定方法,定义如下信息:
定义1,微博文档中特征项的权值
为了降低高频特征项对其它中低频特征项的抑制作用,需要对特征向量进行归一化处理,因此,微博文档中特征项的权值可以表示为:
其中,bik表示微博文档bi中第k个特征项的权值,tfk(bi)是指第k个特征项在bi中出现的次数,nbl是微博文档集合中文档的数目,nk表示包含第j个特征项的微博文档的个数,n是bi中特征项的总数目。
定义2,两个微博文档之间的相似度
两个微博文档bi和bj之间的相似度similarity(bi,bj)定义为两个微博文档向量在状态空间方向上正交的可能性,用这两个向量的夹角余弦cosθij表示,若完全正交,表示两文档毫无相似性,点积为0。夹角余弦cosθij采用如下的计算公式:
similarity(bi,bj)=cosθij
其中,bik,bjk分别表示文档bi和bj第k个特征项的权值,bl表示微博文档集合,nbl表示微博文档集合中文档的数目。
定义3,k-means准则函数
k-means准则函数表示为
其中,k代表簇的个数,ci代表第i个簇,ci代表簇ci的中心点,x代表数据对象,e代表函数的结果。k-means聚类过程中,e的值是变化的,当e趋向一个极小的固定数值时,意味着聚类结果趋于稳定,聚类结束。
定义4,密度density
给定微博文档集合bl,b∈bl,文档b的密度定义为该文档与其他文档相似度的平均,采用如下计算公式:
density(b)=∑x∈blsimilarity(x,b)/nbl
定义5,核心文档
若文档b的密度大于或等于预先设定的密度阈值refsimilarity(大于0),则该文档是核心文档。
本实施例中,所述基于k-均值聚类算法的初始聚类中心确定方法的输入:微博文档集合bl={b1,b2,···,bn},聚类簇数k,密度阈值refsimilarity;输出:初始聚类簇中心centers={c1,c2,···,ck};如图3所示,具体可以包括以下步骤:
step1:对于给定的微博文档集合bl,求出任意两个文档间的相似度,保存至相似度矩阵docsimilarity中;
step2:根据相似度矩阵docsimilarity,计算每一个文档与其他文档两两之间的平均相似度,找出平均相似度大于等于密度阈值的文档,形成核心文档集合coredocs;
step3:将coredocs中的第一个核心文档作为第一个初始聚类中心点centers[1],并从核心文档集合coredocs删除该文档,令计数变量k=1,同时,将centers[1]置为当前聚类中心点;
step4:遍历coredocs中剩余的核心文档,选择与当前聚类中心点最不相似(相似度最小)的文档作为下一个初始聚类中心,添加到centers中,并从coredocs删除该文档;
step5:更新当前聚类中心点,并使k=k+1,转step4;
step6:重复step4和step5,直至k与聚类簇数k值相等为止,输出centers,即centers={c1,c2,···,ck};
step7:计算每个微博文档bi与每个初始聚类簇中心点的相似度,并将bi归入到与其最相似的簇clusters中;
step8:重新计算簇中心,若簇中心发生变化,更新聚类中心点为centers'={c1',c'2,···,c'k},同时清空clusters,开始下一轮聚类;
step9:重复迭代step7和step8,直到准则函数e收敛;
step10:输出最终聚类结果。
实施例二
本发明还提供一种基于k-均值聚类算法的初始聚类中心确定装置的具体实施方式,由于本发明提供的基于k-均值聚类算法的初始聚类中心确定装置与前述基于k-均值聚类算法的初始聚类中心确定方法的具体实施方式相对应,该基于k-均值聚类算法的初始聚类中心确定装置可以通过执行上述方法具体实施方式中的流程步骤来实现本发明的目的,因此上述基于k-均值聚类算法的初始聚类中心确定方法具体实施方式中的解释说明,也适用于本发明提供的基于k-均值聚类算法的初始聚类中心确定装置的具体实施方式,在本发明以下的具体实施方式中将不再赘述。
如图4所示,本发明实施例还提供一种基于k-均值聚类算法的初始聚类中心确定装置,包括:
获取模块11,用于获取数据对象集合,其中,所述数据对象集合包括:微博文档集合;
确定模块12,用于确定数据对象集合中每个数据对象与其它数据对象间的平均相似度,获取平均相似度大于等于预先设定的密度阈值的数据对象作为核心对象;
选取模块13,用于从核心对象中选取彼此间最不相似的多个核心对象作为k-均值聚类算法的初始聚类中心,以便k-均值聚类算法根据得到的初始聚类中心进行聚类。
本发明实施例所述的基于k-均值聚类算法的初始聚类中心确定装置,通过确定数据对象集合中每个数据对象与其它数据对象间的平均相似度,获取平均相似度大于等于预先设定的密度阈值的数据对象作为核心对象,其中,所述数据对象集合包括:微博文档集合;从核心对象中选取彼此间最不相似的多个核心对象作为k-means聚类算法的初始聚类中心,以便k-means聚类算法根据得到的初始聚类中心对微博文档集合进行聚类。这样,不仅可以消除初始聚类中心选取到孤立点可能导致聚类结果陷入局部最优的不良影响,还提高了微博聚类的准确性、稳定性,并能够快速、准确地从大量的微博数据中发现舆情热点话题。
在前述基于k-均值聚类算法的初始聚类中心确定装置的具体实施方式中,所述确定模块包括:
确定单元,用于确定微博文档集合中任意两个文档间的相似度,将相似度保存至相似度矩阵中;
形成单元,用于根据相似度矩阵,计算每一个文档与其他文档两两之间的平均相似度,获取平均相似度大于等于预先设定的密度阈值的文档,形成核心文档集合。
在前述基于k-均值聚类算法的初始聚类中心确定装置的具体实施方式中,两个文档bi和bj之间的相似度similarity(bi,bj)表示为:
其中,bik、bjk分别表示文档bi和bj第k个特征项的权值,n是bi中特征项的总数目,tfk(bi)是指第k个特征项在bi中出现的次数,nbl是微博文档集合中文档的数目,nk表示包含第j个特征项的微博文档的个数。
在前述基于k-均值聚类算法的初始聚类中心确定装置的具体实施方式中,文档b与其他文档两两之间的平均相似度density(b)表示为:
density(b)=∑x∈blsimilarity(x,b)/nbl
其中,bl表示微博文档集合,nbl表示微博文档集合中文档的数目。
在前述基于k-均值聚类算法的初始聚类中心确定装置的具体实施方式中,所述选取模块包括:
删除单元,用于将核心文档集合中的第一个核心文档作为第一个初始聚类中心点centers[1],并从核心文档集合中删除该核心文档,令计数参数k=1,同时,将centers[1]置为当前聚类中心点;
遍历单元,用于遍历核心文档集合中剩余的核心文档,选择与当前聚类中心点最不相似的核心文档作为下一个初始聚类中心,添加到初始聚类中心点centers中,并从核心文档集合中删除该核心文档;
更新单元,用于更新当前聚类中心点,并使k=k+1,转遍历单元;
输出单元,用于重复执行遍历单元和更新单元,直至k与预设的聚类簇数k值相等为止,输出初始聚类中心点centers。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明所述原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!