基于随机森林模型的用户认证口令安全评估方法及装置与流程
本发明属于信息安全技术领域,涉及用户口令安全认证技术,尤其涉及一种不使用用户个人信息的基于随机森林模型的用户认证口令的安全评估方法及装置,通过获取用户认证口令评估用户身份的安全性。
背景技术:
口令在过去几十年里一直是最主要的身份认证方式之一,由于其具有成本低廉、简单易用等特点,在可预见的未来仍将是不可替代的身份认证方式。用户在设置口令时往往为了方便记忆而忽视了口令的安全性,因此为了防止用户设置容易被攻击者攻击的口令,大多数网站会使用口令强度评价器评估用户口令强度。目前使用效果较好的是基于口令猜测算法的强度评价,这种方法能够模拟现实中攻击者进行攻击的场景,能够真实反映出口令对于攻击者的口令强度。
随着技术的发展,攻击者采用不断改进的口令猜测算法以获取用户口令。但是,现有的口令猜测算法或口令评估方法存在一些问题,无法准确评估口令的安全性,容易对用户设置口令造成误导,使得用户设置口令很容易被攻击者猜测得到,这可能引发一系列信息安全问题。
在2005年,narayanan和shmatikov基于自然语言处理的方法,提出了一个基于markov模型的口令猜测算法(arvindnarayananandvitalyshmatikov.“fastdictionaryattacksonpasswordsusingtime-spacetradeoff”.in:proc.ccs,2005:364–372.):假设口令中每个字符只与前面n个字符相关,而与其它字符无关;通过统计字符串的频次,使用贝叶斯公式计算每个前缀后面的字符概率。由于该算法基于统计频次拟合模型,导致算法在阶数n过大时容易过拟合,并且算法效果依赖于训练集大小以及口令多样性,由于概率计算需要使用训练集中字符串的频次,因此,利用该算法无法准确评估用户口令的强度。
在2009年,weir等提出了另一种基于概率模型的口令猜测算法:概率上下文无关文法(pcfg)(mattweir,sudhiraggarwal,brenodemedeirosetal.“passwordcrackingusingprobabilisticcontext-freegrammars”.in:proc.s&p,2009:391–405.)。该算法的核心思想是把字符串分为三类:dls字段,即d(数字)、l(大小写字母)和s(特殊字符),然后根据这三类字符分割口令,使用训练得到的上下文无关文法计算每个口令的概率。由于该算法的模型拟合采用的是对自定义的dls字段进行分割,从而导致利用该算法无法准确估计一些长结构的口令强度,此种口令的强度大多会被错误地高估。
在2016年,melicher等提出了一个基于深度学习的口令猜测算法(williammelicher,blaseur,seanmsegretietal.“fast,lean,andaccurate:modelingpasswordguessabilityusingneuralnetworks”.in:25th{usenix}securitysymposium({usenix}security16),2016:175–191.)。该算法首次应用神经网络,基于markov模型的思想,采用lstm(longshort-termmemory,长短期记忆网络)构建神经网络。但是,该算法的效果依赖于超参数的设置,评估口令强度的稳定性低。
技术实现要素:
为了克服上述现有技术的不足,本发明提供一种基于随机森林模型的用户认证口令的安全评估方法,无需用户个人信息即可完成对用户认证口令的安全性评估,通过使用随机森林模型拟合口令猜测模型获取用户认证口令,克服已有的原始markov模型由于模型拟合原理导致的容易过拟合的问题。与基于深度学习的口令猜测算法相比,本发明方法可以更准确、更稳定地评估用户口令的安全性。
本发明的原理是:现有方法通过口令猜测模型获得用户认证口令。本发明使用随机森林拟合口令猜测模型,通过把口令猜测生成的问题看作是多分类问题,把口令中每个字符看作是类别,字符前若干长度的前缀特征作为特征向量,通过随机森林拟合这个多分类问题。随机森林拟合的样本是前缀特征和相应字符类别,每次划分时考虑前缀特征中使分裂后基尼不纯度最小的特征作为划分规则,满足相同规则的样本划分到同一个子节点中。最后满足同一组划分规则的样本落到同一个叶子节点中,叶子节点中的样本由于满足同一组划分规则因此可以认为是相似的样本,字符类别的分布也可以认为是相似的。训练后,随机森林拟合出多棵决策树,每棵决策树由多组划分规则和包含相似样本的叶子节点构成。本发明方法改进了原始markov模型通过统计频次拟合模型的原理,充分利用每个字符前的前缀特征,解决了原始markov模型容易过拟合的问题以及口令强度评估不准确的问题。
本发明提供的技术方案如下:
一种基于随机森林模型的用户认证口令的安全评估方法,对现有markov模型进行改进,将口令训练集口令中的每个字符作为一个类别,提取出字符的前缀特征作为特征向量,使用随机森林模型进行训练,得到一个多分类问题的概率模型;对于任意字符串,通过该概率模型得到前缀的后缀字符(即前缀后面的一个字符)的概率分布,生成候选口令,实现对用户认证口令的安全性(强度)进行评估;包括如下步骤:
a.提取口令字符串(口令训练集中的口令)的前缀特征;前缀特征包括字符特征和长度特征;在提取字符串的前缀特征时,包括提取字符特征和长度特征;具体执行如下操作:
a1.字符特征用四个维度的特征表示前缀中的每个字符;四个维度的特征包括:字符类型、字符所在类型序号、字符键盘所在行号、字符键盘所在列号,称为字符特征;
遍历前缀中的每个字符,对于每个字符用四个维度的特征表示:字符类型、字符所在类型序号、字符键盘所在行号、字符键盘所在列号。其中,字符类型用0、1、2、3分别表示特殊字符、数字、大写字母和小写字母;所在类型序号即字符的序号,用0~26表示a~z和a~z,用10、1~9表示0~9,用0~32表示各个特殊字符的序号;字符键盘所在行号和列号即字符在键盘上所在的位置,键盘第一行从1开始计数,如1表示为(1,1),q表示为(2,1)等。同时考虑shift键对键盘进行切换,表示方法与无shift键时相同。
a2.获取前缀的长度特征;
考虑前缀的长度特征,包括两个特征:第一个是前缀所在口令已经遍历的字符的长度;第二个是在前缀所在口令中,前缀后一个字符所在的相同字符类型的段已经遍历的长度。
如对于口令“789abc1234”,正在提取特征的前缀为“abc123”,则当前口令已经遍历的长度为前面的“789”加上“abc123”的长度,即为9;当前字符为4,4所在的段为“1234”,在“1234”中已经遍历的长度即为“123”的长度3,所以该前缀的长度特征为(9,3);
a3.通过步骤a1和a2提取得到前缀的特征,对于字符串长度为n的前缀,每个字符的字符特征用4个维度表示,长度特征用2个维度表示,前缀特征的表示一共使用4*n+2个维度。
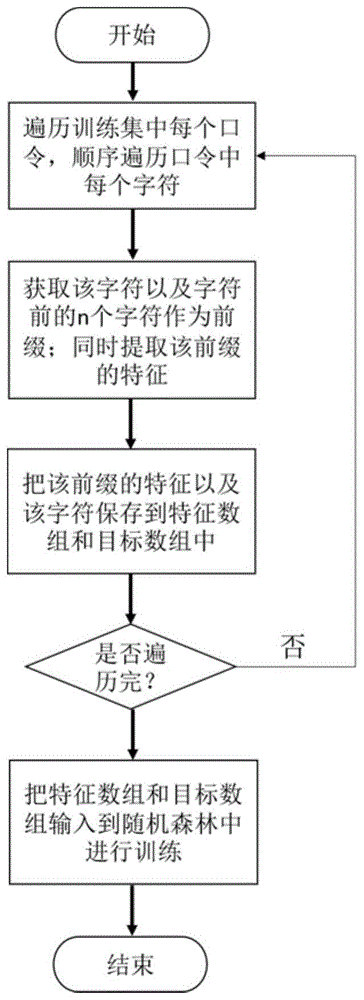
b.用口令训练集训练随机森林模型,在随机森林模型训练阶段,执行如下操作:
b1.对每个口令进行补齐,原始口令前添加多个字符,即起始符(前缀字符串的长度等于阶数n,即添加起始符的个数等于模型的阶数n),原始口令后增加1个字符即结束符,形成新的口令字符串;从原始口令的第一个字符开始,遍历每个字符及其对应的前缀,其中前缀长度优选为大于等于6;把当前字符作为目标类别,对当前字符对应的前缀使用步骤a的方法提取前缀特征,包括字符特征和长度特征;
b2.把步骤b1得到的前缀特征向量和目标类别分别保存到特征向量数组和相应的目标类别数组中。
b3.遍历训练集中所有口令,对每个口令执行步骤b1和b2。把得到的特征向量数组和目标类别数组输入到随机森林中进行训练,得到训练好的随机森林模型。具体实施时,随机森林决策树棵数设置为30,叶子节点最少样本数设置为10。
c.在生成口令阶段,执行如下操作:
c1.从空串开始生成口令,空串的概率赋为1,首先对空串补齐起始符,方便后续提取,把空串和相应概率二元组(表示为(“stststststst”,1),其中st为起始符)压入到候选口令队列中。该二元组的第一列表示候选口令的字符串,第二列表示该生成的候选口令的概率。
c2.弹出候选口令队列的队首,对于候选口令队首的字符串(记为s),使用步骤a的方法提取s最后长度为n的字符串(前缀)特征,把提取出的特征输入到步骤b训练好的随机森林模型中,得到s的后一个字符的概率分布,使用laplace平滑方法对概率为0的字符概率进行平滑,平滑参数为0.001,即对每个字符的概率均加上0.001,然后再做一次正规化操作。若终结符的字符概率pend乘以候选口令的概率ps大于设置阈值,则把(s,pend*ps)这个二元组输出到候选口令数组中;若该字符串s后接其他各个字符c的字符概率pc乘以候选口令的字符串s的概率ps大于阈值,则把(s|c,pc*ps)的结果输出到候选口令队列中,其中,s|c表示s后面接字符c。
c3.重复执行步骤c2,直到候选口令队列为空。对候选口令数组(二维数字,第一维表示生成的口令,第二维表示相应概率值)根据相应概率从大到小进行排序,最后把生成口令及相应概率输出到文件中。相应概率值越大,则生成的口令匹配用户认证口令的可能性越大。
具体实施时,利用上述基于随机森林的用户口令生成和评估方法实现的系统生成用户口令并进行口令强度评估,包括如下模块:前缀特征提取模块、训练集读入和处理模块、模型训练模块、口令猜测生成模块;
前缀特征提取模块用于提取字符串的前缀特征,包括字符特征和长度特征;对于字符串长度为n的前缀,前缀特征使用4*n+2个维度表示;
训练集读入和处理模块用于读入口令训练集并进行包括补齐与提取前缀特征的处理;
模型训练模块用于训练随机森林模型,当前字符作为目标类别,将前缀特征和目标类别分别保存到特征向量数组和相应的目标类别数组中,将特征向量数组和目标类别数组输入到随机森林中进行训练,得到训练好的随机森林模型;
口令猜测生成模块用于将前缀特征输入到训练好的随机森林模型中,得到前缀字符串的后缀字符的概率分布,进一步进行口令猜测生成口令。
为实现上述基于随机森林的用户口令生成和评估方法,本发明还提供一种基于随机森林的用户口令生成装置,包括存储器和处理器;所述存储器,用于存储计算机程序;所述处理器,用于当执行所述计算机程序时。存储器可采用128gb内存和512gb固态硬盘;处理器可采用intelcorei3/5/7第2代以上处理器;操作系统可采用linux和windows7/10;该装置能够提高对用户口令的安全性评估的稳定性和准确性。
本发明的有益效果是:
利用本发明所提供的基于随机森林模型的用户认证口令的安全评估方法及装置,提高了采用现有传统口令猜测算法评估口令强度方法的拟合能力和泛化能力,提升了口令获取的准确率,同时本发明方法降低了对口令训练集大小的依赖,提高了方法的鲁棒性,能够提高对用户口令的安全性评估的稳定性和准确性。
附图说明
图1是本发明提供方法的模型训练的流程框图。
图2是采用本发明提供方法生成用户口令的流程框图。
具体实施方式
下面通过实例对本发明做进一步的说明。
假设采用模型为6阶markov模型,即假设口令中每个字符只与前面6个字符相关,与其他字符无关。
首先以若干个实例说明特征提取的过程。对于任一口令,首先对口令进行补齐,在口令前补6个起始符,口令后补一个结束符。以口令“123456”为例,补齐后为:
“stststststst123456ed”,共13个字符。其中st为起始符,ed为结束符。补齐后,遍历口令中原始口令的每个字符以及结束符,即从字符1开始遍历到字符ed,每个字符前长度为6的字符串为该字符的前缀。然后提取每个字符前长度为6的字符串的前缀特征。即对字符“1”,提取字符串“stststststst”的特征,作为字符1的前缀特征;对字符“2”,提取字符串“ststststst1”的特征;…对字符ed提取字符串“123456”的前缀特征。
下面说明前缀特征提取的方法。前缀特征分为2类,一是字符特征,二是长度特征。首先提取字符特征,对前缀中的每个字符,用四个维度的特征表示:字符类型、所在类型的序号、字符键盘所在行号、字符键盘所在列号。其中,字符类型用0、1、2、3分别表示特殊字符、数字、大写字母和小写字母;所在类型序号即字符的序号,用0~26表示a~z和a~z,用10、1~9表示0~9,用0~32表示各个特殊字符的序号;字符键盘所在行号和列号即字符在键盘上所在的位置,键盘第一行从1开始计数,如1表示为(1,1),q表示为(2,1)等。同时考虑shift键对键盘进行切换,表示方法与无shift键时相同。比如,起始符st表示为(0,0,0,0)、字符a表示为(3,1,3,1),字符b表示为(3,2,4,5)…字符0表示为(1,10,1,10),字符1表示为(1,1,1,1)…字符#表示为(1,4,1,3)…。其中特殊字符的序号按照ascii码的顺序进行排序,另外,结束符ed不可能出现在前缀中,因此不需要提取特征。
然后提取长度特征。对于前缀的长度特征(包括两个长度值),第一个是前缀所在口令已经遍历的字符的长度;第二个是在前缀所在口令中,前缀后一个字符所在的相同字符类型的段已经遍历的长度(均不包括起始符)。如对于口令“789abc1234”,正在遍历字符4,提取特征的前缀为“abc123”,则当前口令已经处理的长度为前面的“789”加上“abc123”的长度,即为9,当前字段已经处理的长度即为“123”的长度即为3,所以该前缀的长度特征为(9,3)
以上是特征提取的方法。下面以口令“abc456”中字符4为例,提取该字符的前缀特征。首先对口令补齐为“ststststststabc456ed”,字符4的前缀为“stststabc”,根据上述的特征提取的方法,该前缀的特征为(0,0,0,0,0,0,0,0,0,0,0,0,3,1,3,1,3,2,4,5,3,3,4,3,3,0)
下面说明本发明的训练过程。训练过程需要遍历训练集中的每个口令,对于每个口令,首先使用上述方法对口令进行补全,然后遍历原始口令中的每个字符以及结束符,使用上述方法对每个字符前长度为6的前缀提取特征,用26个维度的特征向量表示该前缀特征。假设口令长度为l,然后把提取出的l+1个特征向量以及相应的l+1个目标字符类别保存到特征向量数组和目标字符类别数组中。遍历训练集中所有口令后,把特征向量数组和目标类别数组输入到随机森林中进行训练,以python的sklearn为例,调用下列语句进行训练:
rf=randomforestclassifier(n_estimators=30,max_features=0.8,min_samples_leaf=10,random_state=10,n_jobs=4)
rf.fit(data,target)
rf.n_jobs=1
第一行代码为调用sklearn库中随机森林分类器的接口,n_estimators=30表示训练30棵决策树;max_features=0.8表示每次划分随机抽取80%的特征进行选取;min_samples_leaf=10表示叶子节点最少样本数为10;random_state=10表示随机种子,保证每次随机数选取都是相同的,训练的结果也是相同的,应用中可设置其他值;n_jobs=4表示使用4个线程同时训练模型,应用中可设置其他值。
第二行代码作用是把特征向量数组和目标类别数组输入到模型中进行模型拟合。
第三行代码作用是把线程数调整回1,生成口令时采用多线程会导致速度变慢。
下面说明本发明生成口令过程。生成口令时从空串开始生成,概率赋为1,为方便特征提取,首先用起始符补齐空串,补齐后为“stststststst”,把(“stststststst”,1)这个二元组压入候选口令队列gq中,第一列表示候选口令的字符串,第二列表示该候选口令的概率。
然后从gq中弹出队首元素(s,p),首先获取s的最后6个字符作为生成下一个字符的前缀,对这个前缀使用上述前缀特征提取的方法提取出26维的特征向量,然后把该特征向量输入到训练好的随机森林模型中,模型输出下一个字符的概率数组。遍历概率数组中的字符以及相应的概率,假设遍历到字符c,概率为pc,计算pnew=p*pc,若pnew小于阈值,则不考虑该字符;若pnew大于阈值,如果c为终结符ed,则把(s|c,pnew)这个二元组作为最终口令输出到候选口令数组g中。如果c为其他字符,则把(s|c,pnew)这个二元组压入gq中。重复以上操作直至gq为空。
最后把候选口令数组g中的二元组按照概率大小从高到低排序,生成按概率递减的口令,算法结束。
具体实施时,利用基于随机森林的用户口令生成方法实现的系统包括如下模块:前缀特征提取模块、训练集读入和处理模块、模型训练模块、口令猜测生成模块;
前缀特征提取模块用于提取字符串的前缀特征,包括字符特征和长度特征;对于字符串长度为n的前缀,前缀特征使用4*n+2个维度表示;
训练集读入和处理模块用于读入口令训练集并进行包括补齐与提取前缀特征的处理;
模型训练模块用于训练随机森林模型,当前字符作为目标类别,将前缀特征和目标类别分别保存到特征向量数组和相应的目标类别数组中,将特征向量数组和目标类别数组输入到随机森林中进行训练,得到训练好的随机森林模型;
口令猜测生成模块用于将前缀特征输入到训练好的随机森林模型中,得到前缀字符串的后缀字符的概率分布,进一步生成口令。
本发明还提供一种基于随机森林的用户口令生成装置,包括存储器和处理器;所述存储器,用于存储计算机程序;所述处理器,用于当执行所述计算机程序时,实现上述基于随机森林的用户口令生成方法。存储器可采用128gb内存和512gb固态硬盘;处理器可采用intelcorei3/5/7第2代以上处理器;操作系统可采用linux和windows7/10。
需要注意的是,公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附权利要求的精神和范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!