一种时间序列数据的最长公共子串提取方法与流程
本发明涉及最长公共子串提取,尤其是一种时间序列数据的最长公共子串提取方法。
背景技术:
利用数据挖掘技术从时间序列数据中提取最长公共子串对于衡量不同时间序列数据间的相似度来说具有重要意义。现有的最长公共子串(longestcommonsubstring)求取方法广泛应用于文本相似度比较、图形相似处理、程序代码相似比较、媒体流相似比较、基因序列比对、轨迹分类等应用领域。
目前,研究者们针对不同的应用领域,对lcs问题已经做了大量工作:
中国航天科技集团公司第710研究所张毅超等人于2007年12月在《计算机仿真》的《求最长公共子串问题的算法分析》一文中提出一种新算法,该算法利用两个字符串广义后缀数组,在保持和广义后缀树复杂度相等的基础上,能简单实现并具有较小的空间占用度。
中国工程物理研究院计算机应用研究所及电子工程研究所王开云等人在2013年《计算机研究与发展》的《两种基于双向比较的最长公共子串算法》一文中提出两种基于双向比较的最长公共子串算法lcsstrsel和lcsstrscel,通过增加字符跨越等机制,提高了平均计算效率。
以上方法均从求解lcs的角度出发,在一定程度上提升了算法性能,但对于时间序列尤其是时间序列数据的最长公共子串而言,要兼顾到对数据丢失情况的适应性,则并没有完全适合的研究论著,以上方法可以做一些借鉴,但要达到理想效果,还需要有针对性的研究适合于时间序列数据的最长公共子串提取方法。
技术实现要素:
本发明所要解决的技术问题是:针对上述存在的问题,提供一种时间序列数据的最长公共子串提取方法。
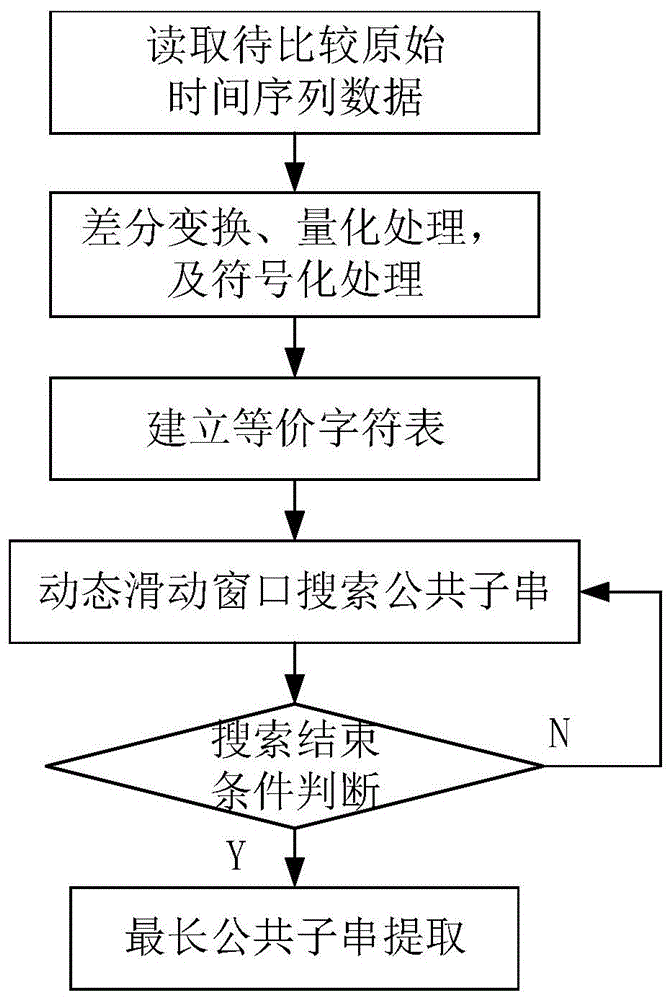
本发明提供的一种时间序列数据的最长公共子串提取方法,包括如下步骤:
步骤1,读取待比较的时间序列数据;
步骤2,选取时间序列数据的时间特征参数作为计算参数,对时间序列数据进行差分变换、量化处理,以及符号化处理后,得到符号化序列;
步骤3,根据所述符号化序列建立时间序列数据的等价字符表;
步骤4,根据所述等价字符表,采用动态滑动窗口的方式,搜索并存储时间序列数据的公共子串;
步骤5,通过判断所述公共子串的长度提取最长公共子串。
进一步地,所述步骤2中选取时间序列数据的时间特征参数作为计算参数,对时间序列数据进行差分变换、量化处理,以及符号化处理后,得到符号化序列的方法,包括:
步骤2.1,要将时间序列数据的时间特征参数进行差分变换后作为一维输入参数;
步骤2.2,所述一维输入参数作为主要因素决定了空间上的一点,将这个空间按照可提前设定的动态阈值进行自适应性的区域划分,划分的每个区域对应着一个量化值,对所有量化值依次打上符号标签,得到符号化序列。
进一步地,选取时间特征参数作为计算参数,则时间序列数据表示为
其中,xj代表序列号为j的时间序列数据,i代表时间序列数据中的时间序号,
进一步地,所述符号化序列表示为:
其中,lx1和lx2分别为待比较的两组时间序列数据x1和x2差分变换、量化处理以及符号化处理后得到的符号化序列,
进一步地,所述步骤3中根据所述符号化序列建立时间序列数据的等价字符表的方法,包括:
在符号化序列的时间特征参数满足如下条件时建立等价字符表:
其中,s为设定的差值级数;k为时间序列数据连续丢失数据的实际个数;km为最大连续丢失数据的个数。
进一步地,步骤4中所述根据所述等价字符表,采用动态滑动窗口的方式,搜索并存储时间序列数据的公共子串的过程,包括:
步骤4.1,选择一个时间序列数据为基准,对另一个时间序列数据进行动态滑动窗口搜索;
步骤4.2,在步骤4.1搜索完成后,交换两序列后进行动态滑动窗口搜索。
进一步地,所述动态滑动窗口的窗口长度随待比较的时间序列数据的长度变化,即每一次比较的动态滑动窗口起始位置向后移动一个序列单元,结束位置为序列末尾。
进一步地,所述动态滑动窗口搜索的结束条件包括:当搜索到两组序列中明显不相同的字符值,且也不属于等价字符时,则停止本次搜索,将后续序列直接剪去,输出公共子串。
进一步地,所述步骤5中通过判断所述公共子串的长度提取最长公共子串的方法包括:对每一次动态滑动窗口搜索输出的所述公共子串进行长度判断:
(1)当所述公共子串的长度满足最长公共子串提取条件时,查找等价字符表中的字符值及对应字符序列,并用字符序列替换字符值,从而提取最长公共子串;
(2)当所述公共子串的长度不满足最长公共子串提取条件时,则搜索完所有的公共子串后,再判断并提取最长公共子串。
进一步地,所述最长公共子串提取条件为:
lcss(x1,x2)≥min(len(x1),len(x2));其中,lcss(x1,x2)表示两序列x1和x2的公共子串长度,len(x1)和len(x2)分别为两序列x1和x2的序列长度;此时有:llcss(x1,x2)=l′css(x1,x2),l′css(x1,x2)≥lcss(x1,x2),其中,l′css(x1,x2)是lcss(x1,x2)替换后的子串长度,llcss(x1,x2)为最长公共子串长度。
综上所述,由于采用了上述技术方案,本发明的有益效果是:
本发明的时间序列数据的最长公共子串提取方法可以快速提取时间序列数据的最长公共子串,且在时间序列存在数据部分丢失的情况下同样有效。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
图1为本发明的时间序列数据的最长公共子串提取方法的流程框图。
图2为本发明的创建等价字符表的流程框图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明,即所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明提供的一种时间序列数据的最长公共子串提取方法,如图1所示,包括如下步骤:
步骤1,读取待比较的时间序列数据;本发明的时间序列数据主要为离散时间序列,如果是连续时间序列,则需要先经过采样转换成离散时间序列。设读取待比较的时间序列数据分别为:
步骤2,选取时间序列数据的时间特征参数作为计算参数,对时间序列数据进行差分变换、量化处理,以及符号化处理后,得到符号化序列;在时间序列数据的采样过程中,由于各种原因可能会有数据丢失的情况发生,因此本发明结合实际数据,还考虑到数据丢失时的容忍处理,解决在一定丢失概率下,最长公共子串提取不准确的问题。这需要在第一步序列符号化处理过程中加入等价字符表的建立。具体地,
步骤2.1,要将时间序列数据的时间特征参数进行差分变换后作为一维输入参数;选取时间特征参数作为计算参数,则时间序列数据表示为
其中,xj代表序列号为j的时间序列数据,i代表时间序列数据中的时间序号,
步骤2.2,所述一维输入参数作为主要因素决定了空间上的一点,将这个空间按照可提前设定的动态阈值进行自适应性的区域划分,划分的每个区域对应着一个量化值,对所有量化值依次打上符号标签,得到符号化序列。得到的所述符号化序列表示为:
其中,lx1和lx2分别为待比较的时间序列数据x1和x2差分变换、量化处理以及符号化处理后得到的符号化序列;
步骤3,根据所述符号化序列建立时间序列数据的等价字符表;具体地,
在符号化序列的时间特征参数满足如下条件时建立等价字符表:
其中,s为设定的差值级数;k为时间序列数据连续丢失数据的实际个数;km为最大连续丢失数据的个数。
这样,第一个序列x1中的符号化处理后的字符值
步骤4,根据所述等价字符表,采用动态滑动窗口的方式,搜索并存储时间序列数据的公共子串;具体地,
步骤4.1,选择一个时间序列数据为基准,对另一个时间序列数据进行动态滑动窗口搜索;
步骤4.2,在步骤4.1搜索完成后,交换两序列后进行动态滑动窗口搜索。
滑动窗口是根据指定的长度来框住时间序列,从而统计框内数据。而本发明的所述动态滑动窗口的窗口长度随待比较的时间序列数据的长度变化,即每一次比较的动态滑动窗口起始位置向后移动一个序列单元,结束位置为序列末尾。
进一步地,所述动态滑动窗口搜索的的结束条件包括:当搜索到两组序列中明显不相同的字符值,且也不属于等价字符时,则停止本次搜索,将后续序列直接剪去,输出公共子串。
步骤5,通过判断所述公共子串的长度提取最长公共子串。具体地,
对每一次动态滑动窗口搜索输出的所述公共子串进行长度判断:
(1)当所述公共子串的长度满足最长公共子串提取条件时,查找等价字符表中的字符值及对应字符序列,并用字符序列替换字符值,从而提取最长公共子串;所述最长公共子串提取条件为:lcss(x1,x2)≥min(len(x1),len(x2));其中,lcss(x1,x2)表示两序列x1和x2的公共子串长度,len(x1)和len(x2)分别为两序列x1和x2的序列长度;此时有:llcss(x1,x2)=l′css(x1,x2),l′css(x1,x2)≥lcss(x1,x2),其中,l′css(x1,x2)是lcss(x1,x2)替换后的子串长度,llcss(x1,x2)为最长公共子串长度;
(2)当所述公共子串的长度不满足最长公共子串提取条件时,则搜索完所有的公共子串后,再判断并提取最长公共子串。
实施例1:
本实施例以脉冲时间序列为例。
步骤1,读取待比较的脉冲时间序列;待比较的脉冲时间序列采用两类数据,如表1所示。
表1:
根据表1,本实施例中采用的两类脉冲时间序列中,一类是无丢失情况的两组待比较的脉冲时间序列;另一类是存在部分丢失情况的两组待比较的脉冲时间序列。
步骤2,选取脉冲时间序列的时间特征参数作为计算参数,对脉冲时间序列进行差分变换、量化处理,以及符号化处理后,得到符号化序列;通过一级差分、量化和符号化处理后得到的符号化序列如表2所示。
表2:
步骤3,根据所述符号化序列建立脉冲时间序列的等价字符表;
考虑到两组序列数据最大长度均为8,因此设置两类脉冲时间序列的最大连续丢失数km均为6(也可根据需求和先验信息选择1≤km≤6的任一值),利用图2所示流程创建不同层级等价字符表,第一组数据由于无数据丢失,因此无需创建等价字符表,而第二组数据存在丢失一个数据的情况,对其创建2级等价字符表,如表3所示。
表3:
步骤4,根据所述等价字符表,采用动态滑动窗口的方式,搜索并存储脉冲时间序列的公共子串;
对两类脉冲时间序列搜索后提取的公共子串为:(0,1,1)和(0,3,5,4,3,3,3):
步骤5,通过判断所述公共子串的长度提取最长公共子串。
对(0,1,1)和(0,3,5,4,3,3,3)进行长度判断:
第二对脉冲时间序列的公共子串的长度满足最长公共子串长度条件,结束对第二对序列的搜索,查找等价字符表中的字符值及对应字符序列,并用字符序列替换字符值,从而提取最长公共子串为(0,3,3,3,4,3,3,3);
第一对脉冲时间序列继续搜索,得到的最长公共子串为(0,1,1,2,1,1,1)。
综上所述,本发明的时间序列数据的最长公共子串提取方法可以快速提取时间序列数据的最长公共子串,且在时间序列存在数据部分丢失的情况下同样有效。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!