一种基于粗化与局部重叠模块度的邮件挖掘方法与流程
本发明涉及大规模邮件网络上的重叠群组发现技术领域,特别是一种基于粗化与局部重叠模块度的邮件挖掘方法。
背景技术:
随着技术的飞速发展,电子邮件成为了生活及工作中必不可少的工具。作为社交网络的重要通讯手段之一,其往来记录中隐含着错综复杂的社交关系。对邮件往来网络中的群组结构进行分析,能够更好地帮助研究人员挖掘邮件收发人之间的共同兴趣、职业等等,从而可以进行圈子推荐、好友推荐、精准广告投放以及定位可疑人群等。目前邮件挖掘相关研究及技术仍不太成熟,人们根据邮件中的不同数据进行不同的研究,如使用时间、邮件源地址等对系统做宏观统计,使用邮件正文对邮件进行分类,使用邮件收发关系的结构发现邮件群组和重要人物等。其中,关于利用邮件收发关系的结构发现邮件群组和重要人物的已有研究存在效率不高的问题,很难满足海量邮件信息处理的要求,并且大多数邮件挖掘系统需要结合多方面的数据,但由于邮件涉及个人隐私问题,收集的邮件语料库规模有限,所以对真实大规模邮件网络的挖掘还比较少,很难保证邮件群组识别的准确性。
技术实现要素:
有鉴于此,本发明的目的是提出一种基于粗化与局部重叠模块度的邮件挖掘方法,可以高效、准确地对复杂网络的重叠结构进行划分。
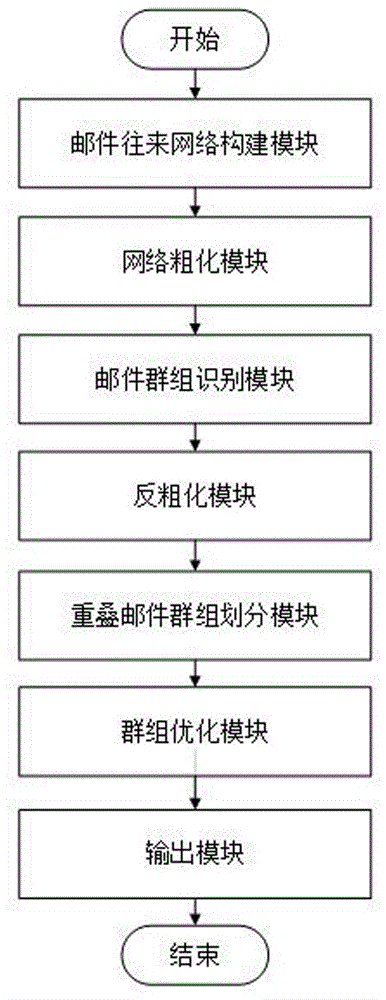
本发明采用以下方案实现:一种基于粗化与局部重叠模块度的邮件挖掘方法,提供一种系统,该系统包括邮件往来网络构建模块、网络粗化模块、邮件群组识别模块、反粗化模块、重叠邮件群组划分模块、群组优化模块和输出模块;该系统按如下步骤进行邮件挖掘:
步骤s1:所述邮件往来网络构建模块获取系统中的邮件头日志信息构建邮件往来网络g:令邮件的发件人和收件人为节点,收发邮件的关系为边,邮件收发人之间的邮件往来频率为权重,构建用于划分群组结构的邮件往来网络g=(v,e,w),其中v表示节点集,e表示边集,w表示边的权重集;
步骤s2:所述网络粗化模块读取邮件往来网络g,按照节点的度从小到大的顺序遍历g中的三角形,将构成三角形的三个节点融合为一个复合节点,多次迭代遍历直至粗化率达到设定阈值,结束粗化过程,得到粗化后的图gcn=(v',e');
步骤s3:所述邮件群组识别模块遍历所述粗化后的图gcn中的所有边,根据jaccard距离公式初始化所有边对应节点的距离;一条边存在三种不同类型的邻居,分别为直连邻居、共有邻居、专有邻居;根据这三种邻居对节点间距离的影响力,对所有边对应节点的距离进行多次迭代更新,得到节点间的距离趋于0或1;将距离为1的边切断,经过断边处理后,图结构中构成连通分支的节点属于同一群组,得到粗化图的群组划分ccn;
步骤s4:所述反粗化模块根据节点映射关系,将原始邮件往来网络g中的被复合节点加入到复合节点所属的群组中,得到所述邮件往来网络g上的初始群组划分c;
步骤s5:所述重叠邮件群组划分模块,利用邮件往来网络上的初始群组划分c进行重叠邮件群组发现;根据节点标签变化所引起的局部重叠模块度增量大小,对距离为1的边所对应的节点进行群组归属判断,得到重叠群组集合cover;
步骤s6:所述群组优化模块根据群组与群组间的紧密度,将所述重叠群组集合cover中群组节点数少于设定阈值的群组合并到与其紧密度最大的群组中,得到最终的重叠群组集合c';
步骤s7:所述输出模块输出最终邮件往来网络的群组划分结果c'。
进一步地,所述步骤s2具体包括以下步骤:
步骤s21:读取邮件往来网络g=(v,e,w);
步骤s22:将所述邮件往来网络中的节点按度大小升序排序,将序列记为lst;
步骤s23:针对每个节点v,初始化其标志位v.f=-1;
步骤s24:从lst中依次取出每个节点v;寻找由节点v构成的三角形;当构成三角形的三个顶点的标志位均小于2且其余两个节点的度小于v的度时,将三个节点粗化成一个复合节点vcm,即用一个复合节点vcm代替三角形的三个顶点;原先与三个顶点相连的边改为与vcm相连,并合并两点间的重复边及边权;
步骤s25:当遍历完lst中的所有节点后,即完成一层粗化,利用式(1)求出该层粗化的粗化率;
ratecoar=(|gm|-|gm-1|)/|g|(1)
其中,gm-1存储该层粗化前的图结构信息;gm中存储粗化后
的图结构信息;
步骤s26:若ratecoar大于给定阈值,所述阈值范围为[0,1],则重复步骤s21至s25;否则将gm-1中的图结构信息存储至粗化后的图
gcn=(v',e')中。
进一步地,所述步骤s3具体包括以下步骤:
步骤s31:遍历粗化后的图gcn的边集e',基于jaccard距离公式初始化所有边对应节点的距离的d(u,v);jaccard距离公式如下:
其中,γ(·)表示包含节点自身的邻居集;
步骤s32:遍历粗化后的图gcn的边集e',将边记为e=(u,v),当0<d(u,v)<1时,依次求出该边的直连邻居、共有邻居、专有邻居的影响力di、ci、ei;di、ci、ei定义如下:
其中,f(·)为耦合函数,采用sin(·)函数;cn(u,v)为节点u,v的共同邻居集;en(·)表示节点的专有邻居集,其定义如下:
en(u)=nb(u)-cn(u,v)(6)
步骤s33:令dist=d(u,v)+di+ci+ei;若dist≤0,则d(u,v)=0;若0<dist<1,则d(u,v)=dist;若dist≥1,则d(u,v)=1;将距离更新至粗化后的图gcn中;
步骤s34:当所有边对应节点的距离均为0或1,终止迭代过程;反之,重复步骤s32至步骤s34。
步骤s35:将粗化后的图gcn中距离为1的边切断,经过断边处理后,粗化后的图gcn中构成连通分支的节点属于同一群组,得到粗化图的群组划分gcn。
进一步地,所述步骤s4具体包括以下步骤:
步骤s41:遍历粗化后的图gcn的节点集v',将节点记为v,将v覆盖的原始节点加入到v所属的群组中,更新群组划分gcn;
步骤s42:遍历完成后,将群组划分gcn中的群组信息存储至初始群组划分c。
进一步地,所述步骤s5具体包括以下步骤:
步骤s51:将所述邮件往来网络g中距离为1的边所对应的节点存入集合s中;
步骤s52:遍历s中的节点,即为i,求出节点i加入某一群组集,用以使局部重叠模块度增量δeq达到最大;节点i加入某一群组集局部重叠模块度增量的定义如下:
其中,m表示邮件往来网络g中的边数;tr表示节点u加入的某个群组,oe表示节点e所属的群组个数;ke表示节点e的度;aei用于表示节点e和节点i的连接情况;若两节点存在边,则aei取值为1,反之为0;
步骤s53:更新群组信息,得到重叠群组集合cover。
进一步地,所述步骤s6具体包括以下步骤:
步骤s61:遍历所述重叠群组集合cover中的节点数少于设定阈值的群组,记为c1,计算该群组与其他群组的紧密度intimacy(c1,ck);其中群组与群组的紧密度intimacy(c1,ck)的定义如下:
步骤s62:将c1加入到紧密度最大的群组ci中;
步骤s63:遍历完后,如果还存在节点数少于设定阈值的群组,则重复步骤s61至s63;反之,将最新的群组结构更新到重叠群组集合cover中;
步骤s64:遍历完成后,将cover中的群组信息存储至c'。
进一步地,所述步骤s7具体包括以下步骤:
步骤s71:将重叠群组集合c'中每个群组ci'中的节点vi,j写成行向量形式ri=(vi,j);
步骤s72:输出向量集{ri},0<i<p,p为群组个数,每行代表一个群组;群组重叠由行向量中包含的重复节点表示。
与现有技术相比,本发明有以下有益效果:
(1)本发明提出一种新的局部增量重叠模块度,并推导了其计算公式。新的模块度在很大程度上克服了传统模块度计算效率低的问题,并且有助于提高重叠群组发现的精度。
(2)本发明采用一种新的群组优化策略进行相似群组的合并,减少离群群组的数量,从而提高群组划分质量。因此能够有效地得到网络中重叠群组结构划分,并为网络聚类在重叠群组发现方向的发展提供有益补充。
附图说明
图1为本发明实施例的流程图。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
如图1所示,本实施例提供了一种基于粗化与局部重叠模块度的邮件挖掘方法,提供一种系统,该系统包括邮件往来网络构建模块、网络粗化模块、邮件群组识别模块、反粗化模块、重叠邮件群组划分模块、群组优化模块和输出模块;该系统按如下步骤进行邮件挖掘:
步骤s1:所述邮件往来网络构建模块获取系统中的邮件头日志信息构建邮件往来网络g:令邮件的发件人和收件人为节点,收发邮件的关系为边,邮件收发人之间的邮件往来频率为权重,构建用于划分群组结构的邮件往来网络g=(v,e,w),其中v表示节点集,e表示边集,w表示边的权重集;
步骤s2:所述网络粗化模块读取邮件往来网络g,按照节点的度从小到大的顺序遍历g中的三角形,将构成三角形的三个节点融合为一个复合节点,多次迭代遍历直至粗化率达到设定阈值,结束粗化过程,得到粗化后的图gcn=(v',e');
步骤s3:所述邮件群组识别模块遍历所述粗化后的图gcn中的所有边,根据jaccard距离公式初始化所有边对应节点的距离;一条边存在三种不同类型的邻居,分别为直连邻居、共有邻居、专有邻居;根据这三种邻居对节点间距离的影响力,对所有边对应节点的距离进行多次迭代更新,得到节点间的距离趋于0或1;将距离为1的边切断,经过断边处理后,图结构中构成连通分支的节点属于同一群组,得到粗化图的群组划分ccn;
步骤s4:所述反粗化模块根据节点映射关系,将原始邮件往来网络g中的被复合节点加入到复合节点所属的群组中,得到所述邮件往来网络g上的初始群组划分c;
步骤s5:所述重叠邮件群组划分模块,利用邮件往来网络上的初始群组划分c进行重叠邮件群组发现;根据节点标签变化所引起的局部重叠模块度增量大小,对距离为1的边所对应的节点进行群组归属判断,得到重叠群组集合cover;
步骤s6:所述群组优化模块根据群组与群组间的紧密度,将所述重叠群组集合cover中群组节点数少于设定阈值即5的群组合并到与其紧密度最大的群组中,得到最终的重叠群组集合c';
步骤s7:所述输出模块输出最终邮件往来网络的群组划分结果c'。
进一步地,所述步骤s2具体包括以下步骤:
步骤s21:读取邮件往来网络g=(v,e,w);
步骤s22:将所述邮件往来网络中的节点按度大小升序排序,将序列记为lst;
步骤s23:针对每个节点v,一般初始化其标志位v.f=-1;
步骤s24:从lst中依次取出每个节点v;寻找由节点v构成的三角形;当构成三角形的三个顶点的标志位均小于2且其余两个节点的度小于v的度时,将三个节点粗化成一个复合节点vcm,即用一个复合节点vcm代替三角形的三个顶点;原先与三个顶点相连的边改为与vcm相连,并合并两点间的重复边及边权;
步骤s25:当遍历完lst中的所有节点后,即完成一层粗化,利用式(1)求出该层粗化的粗化率;
ratecoar=(|gm|-|gm-1|)/|g|(1)
其中,gm-1存储该层粗化前的图结构信息;gm中存储粗化后的图结构信息;
步骤s26:若ratecoar大于给定阈值所述阈值范围为[0,1],则重复步骤s21至s25;否则将gm-1中的图结构信息存储至粗化后的图
gcn=(v',e')中。
进一步地,所述步骤s3具体包括以下步骤:
步骤s31:遍历粗化后的图gcn的边集e',基于jaccard距离公式初始化所有边对应节点的距离的d(u,v);jaccard距离公式如下:
其中,γ(·)表示包含节点自身的邻居集;
步骤s32:遍历粗化后的图gcn的边集e',将边记为e=(u,v),当0<d(u,v)<1时,依次求出该边的直连邻居、共有邻居、专有邻居的影响力di、ci、ei;di、ci、ei定义如下:
其中,f(·)为耦合函数,一般采用sin(·)函数;cn(u,v)为节点u,v的共同邻居集;en(·)表示节点的专有邻居集,其定义如下:
en(u)=nb(u)-cn(u,v)(6)
步骤s33:令dist=d(u,v)+di+ci+ei;若dist≤0,则d(u,v)=0;若0<dist<1,则d(u,v)=dist;若dist≥1,则d(u,v)=1;将距离更新至粗化后的图gcn中;
步骤s34:当所有边对应节点的距离均为0或1,终止迭代过程;反之,重复步骤s32至步骤s34。
步骤s35:将粗化后的图gcn中距离为1的边切断,经过断边处理后,粗化后的图gcn中构成连通分支的节点属于同一群组,得到粗化图的群组划分gcn。
在本实施例中,所述步骤s4具体包括以下步骤:
步骤s41:遍历粗化后的图gcn的节点集v',将节点记为v,将v覆盖的原始节点加入到v所属的群组中,更新群组划分gcn;
步骤s42:遍历完成后,将群组划分gcn中的群组信息存储至初始群组划分c。
在本实施例中,所述步骤s5具体包括以下步骤:
步骤s51:将所述邮件往来网络g中距离为1的边所对应的节点存入集合s中;
步骤s52:遍历s中的节点,即为i,求出节点i加入某一群组集,用以使局部重叠模块度增量δeq达到最大;节点i加入某一群组集局部重叠模块度增量的定义如下:
其中,m表示邮件往来网络g中的边数;tr表示节点u加入的某个群组,oe表示节点e所属的群组个数;ke表示节点e的度;aei用于表示节点e和节点i的连接情况;若两节点存在边,则aei取值为1,反之为0;
步骤s53:更新群组信息,得到重叠群组集合cover。
在本实施例中,所述步骤s6具体包括以下步骤:
步骤s61:遍历所述重叠群组集合cover中的节点数少于设定阈值的群组,记为c1,计算该群组与其他群组的紧密度intimacy(c1,ck);其中群组与群组的紧密度intimacy(c1,ck)的定义如下:
步骤s62:将c1加入到紧密度最大的群组ci中;
步骤s63:遍历完后,如果还存在节点数少于设定阈值的群组,则重复步骤s61至s63;反之,将最新的群组结构更新到重叠群组集合cover中;
步骤s64:遍历完成后,将cover中的群组信息存储至c'。
在本实施例中,所述步骤s7具体包括以下步骤:
步骤s71:将重叠群组集合c'中每个群组ci'中的节点vi,j写成行向量形式ri=(vi,j);
步骤s72:输出向量集{ri},0<i<p,p为群组个数,每行代表一个群组;群组重叠由行向量中包含的重复节点表示。
较佳的,本发明提出一种基于粗化与局部重叠模块度的邮件挖掘方法与系统,该系统挖掘邮件群组的时间复杂度近似线性,适用海量邮件信息的处理,并且能利用邮件往来网络的拓扑结构准确的识别网络中的群组。
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!