一种基于权重归一化的深度神经网络压缩方法与流程
本发明提供一种基于权重归一化的深度神经网络压缩方法,涉及压缩(量化)神经网络的参数,可以将模型的权重量化至极低的比特数目(2比特、3比特)适用于压缩各种主流的神经网络的参数,如resnet,mobilenet等,从而使得模型可以部署到移动端设备。
背景技术:
随着深度学习的发展,深度神经网络逐渐成为机器学习的主流模型。但是,深度学习模型有大量的参数同时需要极大的计算开销,不利于模型向移动设备和嵌入式设备部署。根据已有研究,深度神经网络中存在大量冗余,因此可以对模型的参数进行极大的压缩,同时保证模型的性能没有显著的下降。
模型权重量化是模型压缩的一个主要方法,尽管现有的方法可以把模型的参数量化至8比特几乎没有性能损失,但是当权重量化至极低的比特数目时,往往会带来较大的性能损失。
一种主流的权重量化方法是基于最小量化误差量化权重,但是这种方法受到权重的长尾分布的影响,导致较大的相对量化误差,进而造成量化模型性能的损失。
技术实现要素:
发明目的:目前的基于最小量化误差的权重量化方法受到权重的长尾分布的影响,会带来较大的相对量化误差。针对上述问题,本发明提供了一种基于权重归一化的深度神经网络压缩方法。先对权重归一化,再基于最小量化误差对权重量化,最后对权重反归一化得到量化的权重。同时对阶跃形式的量化函数的导数进行近似,使得神经网络的反向传播可以正常进行。本发明通过使用最大绝对值元素进行权重归一化,从而得到最大绝对值元素的梯度形式不同于其他元素的梯度,使得最大绝对值元素在每次迭代都快速向0值靠近,从而在多次迭代之后可以削弱权重的长尾分布,得到较小的相对量化误差,进而使得量化模型的性能损失减小。
技术方案:一种基于权重归一化的深度神经网络压缩方法,在神经网络正向传播过程中,首先对权重归一化,然后基于最小量化误差量化权重,再进行反归一化得到量化的权重,使用量化的权重进行神经网络的正向传播;在反向传播过程中,对阶跃形式的量化函数的导数进行近似,使得神经网络可以反向传播,从而进行端到端的训练,梯度累加在浮点权重上。
所述的正向传播过程,首先对权重归一化,然后基于最小量化误差量化权重,再进行反归一化得到量化的权重,具体步骤为:
步骤100,获取预训练的全精度模型的参数,对所有卷积层和全连接层的每个滤波器的参数向量化,得到w∈rm。
步骤101,对参数w进行归一化,使用w的最大绝对值的元素把w中的每个元素归一化到[-1,1],即
步骤102,基于对
步骤103,对归一化之后的权重
步骤104,对量化的归一化权重
步骤105,由得到的量化权重wq和神经网络这一层的输入x进行卷积操作(全连接操作)得到神经网络这一层的输出y。
所述的反向传播过程,对阶跃形式的量化函数的导数进行近似,使得神经网络可以反向传播,具体步骤为:
步骤200,由梯度的反向传播,得到神经网络损失函数l对量化权重wq的梯度
步骤201,根据梯度的反向传播,得到对量化的归一化权重
步骤202,对阶跃式函数π(·)的梯度进行近似,即
步骤203,根据梯度的反向传播,得到对原始浮点参数w的梯度,梯度的形式为:
其中wi是w的第i个元素。
步骤204,使用梯度
所述的基于对
其中,m为权重向量的维度,k为量化的比特数目,b是
所述模型训练的整体流程为:对神经网络卷积层和全连接层中的每个滤波器参数w量化得到量化的参数wq,使用wq进行神经网络正向传播;由正向传播计算得到损失函数l,然后进行梯度的反向传播,其中对阶跃式函数π(·)的导数进行近似,最终得到对浮点参数w的梯度,更新浮点参数w,训练需要迭代多次直至收敛。最终的模型只需保存量化的归一化权重
有益效果:与现有技术相比,本发明提供的基于权重归一化的神经网络权重量化方法,可以把神经网络的权重量化到极低的比特,同时保证模型的性能没有明显的损失。利用最大绝对值元素进行权重归一化,从而得到最大绝对值元素的梯度形式不同于其他元素的梯度,使得最大绝对值元素在每次迭代都快速向0值靠近,从而在多次迭代之后可以削弱权重的长尾分布,得到更小的量化误差,从而使得量化模型的性能损失减小。
附图说明
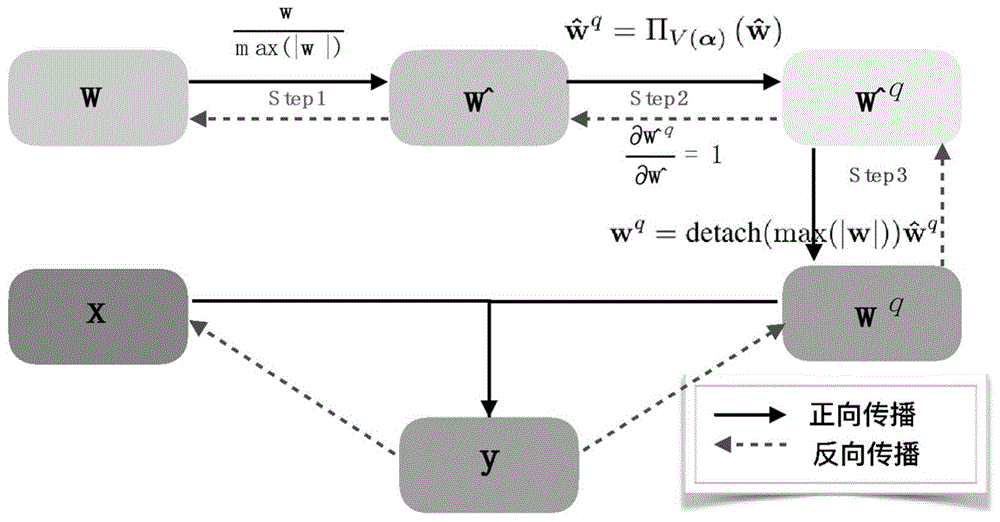
图1为本发明的量化过程的正向传播和反向传播示意图;
图2为本发明的量化权重的神经网络整体训练流程图;
图3为本发明的量化基α求解过程;
图4为使用训练好的量化模型预测的过程;
图5为本发明方法与“基于可学习的量化函数的高精度紧凑神经网络”的浮点权重分布对比图。
具体实施方式
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
基于权重归一化的深度神经网络压缩方法,量化过程的正向传播和反向传播如图1所示。量化函数正向传播过程为:先对每个滤波器权重w进行归一化得到
基于权重归一化的深度神经网络压缩方法,整体训练流程如图2所示。首先需要取得一个预训练的全精度模型,然后根据图1的量化器的正向传播过程对网络中所有卷积层和全连接的每个滤波器的浮点权重w量化,使用量化的权重wq和输入的训练数据进行网络的正向传播,计算得到网络的损失函数l。然后经过神经网络的反向传播得到对量化权重wq的梯度,根据图1的量化器的反向传播过程,得到对浮点权重w的梯度,更新浮点权重w,多次更新直到收敛。保存浮点权重w和量化基α,在模型预测之前会进一步处理成压缩(低精度)的格式。
量化基α求解过程如图3所示。采用交替优化的方式,首先初始化量化基α,计算所有量化值的集合v(α),然后把
使用训练好的量化模型预测的过程如图4所示,首先根据训练得到的浮点权重w和量化基α计算
由于bij是二值的,取值为{-1,1},所以bij·xi的计算只需根据bij的取值,对xi取正或者取负,无需乘法操作,因此可以消除内积运算中大量的乘法操作,在特定的硬件下可以加速推断过程。此外还可以结合一些现有的方法把输入x也量化为低比特的,大大提升神经网络的推断速度。
本发明在两个数据集上进行了实验,对比了本发明的方法和已有最好方法的效果,已有的最好方法是dongqingzhang在2018年欧洲计算机视觉国际会议eccv论文中提出的“基于可学习的量化函数的高精度紧凑神经网络”。
第一个数据集是cifar-100,cifar-100包括60k张32x32的rgb图片,一共100个类别,每个类别有600张图片。其中包括50k张训练图片和10k张测试图片。实验结果如表1所示,评价指标为top1分类精确度,采用的网络为resnet20。可见本发明的方法比于已有的最好方法有很大提升,并且当采用4比特量化权重,可以超过全精度模型的效果。
表1为本发明在cifar-100数据集上使用resnet20的top1分类精度(%)
表2为本发明在imagenet数据集上使用mobilenetv1的top1/top5分类
精度(%)
第二个数据集是imagenet,imagenet包括1.28m张训练图片和50k张测试图片,一共1000个类别。实验结果如表2所示,评价指标为top1和top5分类精确度,采用的网络为mobilenetv1。可见本发明的方法比于已有的最好方法有很大提升。
基于权重归一化的深度神经网络压缩方法,得到的权重分布如图5所示,使用2比特量化权重,上面四张图为本发明得到的浮点权重分布,四张图分别对应选取的四个卷积层/全连接层的浮点权重分布。下面四张图为“基于可学习的量化函数的高精度紧凑神经网络”相应层得到的浮点权重分布,x轴上的点代表这一层所有滤波器的量化值的平均。其中“mse”表示这一层每个滤波器的相对量化误差的平均,每个滤波器的相对量化误差定义为
- 还没有人留言评论。精彩留言会获得点赞!