一种三目后视镜和三目视觉安全驾驶方法和系统与流程
本发明涉及计算机视觉技术领域,更具体的说是涉及一种三目后视镜和三目视觉安全驾驶方法和系统。
背景技术:
汽车无疑是一件伟大的发明,它为人们的生活带来了便捷。随着国家经济的不断发展和人民生活水平的不断提高,汽车保有量呈现迅猛增速。一些司机朋友驾驶习惯不好,容易为自己和他人带来安全隐患。
目前,大多数司机都会在汽车上安装行车记录仪,但是行车记录仪只能提供基本的影像信息,大部分司机在开车时,不会过多的关注到行车记录仪上的影像,无法规避风险。
因此,如何提供一种能够规避风险的安全驾驶方法是本领域技术人员亟需解决的问题。
技术实现要素:
有鉴于此,本发明提供了一种三目后视镜和三目视觉安全驾驶方法和系统,能够有效规避风险,实现安全驾驶。
为了实现上述目的,本发明采用如下技术方案:
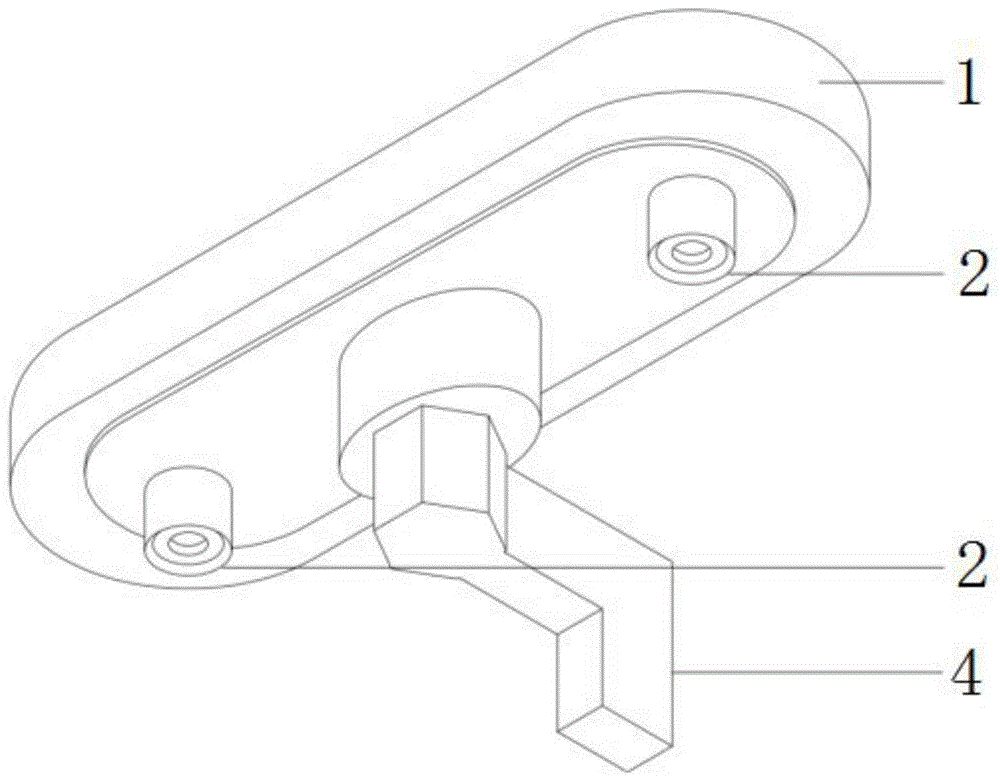
一种三目后视镜,包括:后视镜主体和控制器;所述后视镜主体的一侧连接有支架;所述支架两侧且位于所述后视镜主体上各安装有一个摄像头,组成双目摄像头;所述后视镜主体的另一侧安装有一个摄像头,且三个摄像头均与所述控制器电连接。
优选的,还包括:语音播报模块,所述语音播报模块与所述控制器电连接。
一种三目视觉安全驾驶方法,包括:单目检测部分和双目检测部分;其中双目检测部分基于所述支架两侧且位于所述后视镜主体上安装的摄像头采集的双目图像信息进行的;单目检测部分基于后视镜主体另一侧安装的摄像头采集的单目图像信息进行的;
s1:单目检测部分:
s11:基于卷积神经网络对单目图像信息中的眼睛状态信息进行二分类操作,并判断是否为疲劳驾驶;
s12:基于卷积神经网络对单目图像信息进行特征提取,得到人体骨骼节点在图像中的位置,通过节点相对位置的不同判定司机的行为动作是否影响安全驾驶;
s2:双目检测部分:
s21:对双目图像信息进行双目标定和畸变校正,得到左右畸变校正图像;
s22:将左右畸变校正图像输入到三维重建模型中进行三维重建,得到三维重建结果;
s23:将所述左右畸变校正图像输入到语义分割模型中,得到分割图像和分割识别信息;
s24:将所述左右畸变校正图像输入到车道线分割模型中,得到车道线坐标。
优选的,步骤s21中畸变校正的具体步骤包括:
对预处理后的图像信息进行双目标定,得到畸变参数和内外参数矩阵;
基于畸变参数和内外参数矩阵对双目标定后的图像进行畸变校正,得到左右畸变校正图像;
相应的,步骤s22具体包括:
基于bm方法对左右畸变校正图像进行立体匹配,得到视差图和三维坐标;
基于视差图和三维坐标进行三维投影,得到三维重建结果。
优选的,步骤s23具体包括:
对左右畸变校正图像进行三通道直方图均衡化和去噪处理;
将处理后的图像输入到预先训练好的神经网络中,并基于上色规则得到分割图像和分割识别信息。
优选的,预先训练好的神经网络采用enet网络结构,其中,enet网络的bottleneck层中激活函数采用leakyrelu结构,去掉了所有1×1大小的卷积,残差结构中所有卷积计算全部采用分解卷积核。
优选的,步骤s24具体包括:
将所述左右畸变校正图像进行滤波去噪处理,得到去噪畸变校正图像;
对去噪畸变校正图像进行边缘检测,得到边缘检测结果;
对边缘检测结果进行范围框定和霍夫变换,得到车道线坐标。
优选的,还包括:步骤s13:对影响安全驾驶的行为动作进行语音提醒。
优选的,步骤s1中还包括:基于单目图像信息判断驾驶员是否为车主或允许的人员。
一种三目视觉安全驾驶系统,包括:
单目检测模块,用于基于卷积神经网络对单目图像信息中的眼睛状态信息进行二分类操作,并判断是否为疲劳驾驶;
行为判断模块,用于基于卷积神经网络对单目图像信息进行特征提取,得到人体骨骼节点在图像中的位置,通过节点相对位置的不同判定司机的行为动作是否影响安全驾驶;
畸变校正模块,用于对双目图像信息进行双目标定和畸变校正,得到左右畸变校正图像;
三维重建模块,用于将左右畸变校正图像输入到三维重建模型中进行三维重建,得到三维重建结果;
语义分割模块,用于将所述左右畸变校正图像输入到语义分割模型中,得到分割图像和分割识别信息;
车道线检测模块,用于将所述左右畸变校正图像输入到车道线分割模型中,得到车道线坐标。
经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种三目后视镜和三目视觉安全驾驶方法和系统,通过摄像头采集单目图像和双目图像,基于单目摄像头采集的图像检测驾驶员疲劳状态,结合驾驶员行为分析,检测驾驶员是否专心驾驶,规避驾驶员不好的习惯带来的风险。基于双目摄像头采集的图像信息来检测与前方车辆的安全距离、其他车辆的行驶方向、车速以及行人、前车测距、交通标志、红绿灯、十字路口等道路环境的分析处理,以便在危险情况时提醒驾驶员,规避行车风险。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
图1为本发明提供的三目后视镜结构示意图一;
图2为本发明提供的三目后视镜结构示意图二;
图3为本发明提供的三目后视镜结构示意图三;
图4为本发明提供的三目视觉安全驾驶方法的流程图;
图5为本发明提供的畸变校正和三维重建的方法流程图;
图6为本发明提供的标定的具体方法流程图;
图7为本发明提供的车道检测线检测方法流程图;
图8为本发明提供的坐标系转换方法示意图;
图9为本发明提供的语义分割方法的流程图;
图10为本发明提供的残差结构图的示意图;
图11为本发明提供的现有的神经网络bottleneck层的结构和处理流程;
图12为本发明改进的神经网络bottleneck层的结构和处理流程。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
参见附图1和2,本发明实施例公开了一种三目后视镜,包括:后视镜主体1和控制器3;所述后视镜主体1的一侧连接有支架4;所述支架4两侧且位于所述后视镜主体1上各安装有一个摄像头2,组成双目摄像头;所述后视镜主体1的另一侧安装有一个摄像头2,且三个摄像头2均与所述控制器3电连接。各个摄像头2均通过数据线7与控制器3电连接。其中,还需要说明的是。设置有镜面6的一侧设置1个摄像头,靠近挡风玻璃的一侧设置2个摄像头。
参见附图3,还包括:语音播报模块5,所述语音播报模块5与所述控制器3电连接。三个摄像头分别通过数据线与控制器,如:嵌入式开发平台相连,通过分析采集到图像来驱动语音播报模块来警告司机安全驾驶。如下述的可以通过三个摄像头采集的图像进行三维重建,之后进行语义分割和测距等计算,从而判断司机是否安全驾驶。
此外,本发明实施例还公开了一种三目视觉安全驾驶方法,具体请参见附图4,包括:单目检测部分和双目检测部分;其中双目检测部分基于所述支架两侧且位于所述后视镜主体上安装的摄像头采集的双目图像信息进行的;单目检测部分基于后视镜主体另一侧安装的摄像头采集的单目图像信息进行的;
s1:单目检测部分:
s11:基于卷积神经网络对单目图像信息中的眼睛状态信息进行二分类操作,并判断是否为疲劳驾驶;具体的,可以根据perclos指标来判断是否为疲劳驾驶;
s12:基于卷积神经网络对单目图像信息进行特征提取,得到人体骨骼节点在图像中的位置,通过节点相对位置的不同判定司机的行为动作是否影响安全驾驶;
步骤s11和步骤s12不限定执行的先后顺序。
s2:双目检测部分:
s21:对双目图像信息进行双目标定和畸变校正,得到左右畸变校正图像;
s22:将左右畸变校正图像输入到三维重建模型中进行三维重建,得到三维重建结果;通过三维重建能够得到车距信息,车距信息是车辆避障和行驶所必须的条件;
s23:将所述左右畸变校正图像输入到语义分割模型中,得到分割图像和分割识别信息;将前方的所有物体分割出,就能够给自动驾驶或者驾驶员对不同物体应用不同方式避障的可能;
s24:将所述左右畸变校正图像输入到车道线分割模型中,得到车道线坐标。车辆在行驶时,必须依靠一定的规则进行行驶,车道线则是其规则,车辆必须按照车辆险规则进行行驶。
这里需要说明的是,步骤s22~步骤s24的处理顺序并没有限定。
基于单目摄像头采集的图像检测驾驶员疲劳状态,结合驾驶员行为分析,检测驾驶员是否专心驾驶,规避驾驶员不好的习惯带来的风险。基于双目摄像头采集的图像信息来检测与前方车辆的安全距离、其他车辆的行驶方向、车速以及行人、前车测距、交通标志、红绿灯、十字路口等道路环境的分析处理,以便在危险情况时提醒驾驶员,规避行车风险。
为了避免碰撞,需要感知到前方所有物体的距离。激光雷达可以精准的感知周围距离但造价十分昂贵,无法普及。摄像头可以已低廉的成本进行三维重建从而感知距离信息。摄像头本身是二维信息,如何将二维信息转化成三维信息是算法的要点和目标。利用摄像头三维重建的方法有很多种,基本分为两大类:单目和多目。通常感知距离需要两张不同角度的照片,单目摄像头可以利用不同焦距拍摄图片来感知也可以通过移动摄像头方位和角度拍摄来感知。相比单目摄像头,双目摄像头进行三维重建的有点是可以做到在同一时刻进行重建,而不像单目必须通过移动和变焦取得两张不同时刻的照片。高速行驶的智能汽车上,以前物体都是相对运动的的,不同时刻会导致信息发生较大的变化,故选择双目模组实现重建。
具体的,请参见附图5,为了进一步优化上述技术方案,步骤s21中畸变校正的具体步骤包括:
对预处理后的图像信息进行双目标定,得到畸变参数和内外参数矩阵;
基于畸变参数和内外参数矩阵对双目标定后的图像进行畸变校正,得到左右畸变校正图像;
相应的,步骤s22具体包括:
基于bm方法对左右畸变校正图像进行立体匹配,得到视差图和三维坐标;
基于视差图和三维坐标进行三维投影,得到三维重建结果。
其中,标定的目的是为了获取后续步骤所需要的参数,使得整个双目模组满足:1.严格平行。2.针孔模型(无畸变模型)。首先,为了使获取的图像无畸变,必须进行畸变校正,畸变校正分为径向畸变和切向畸变。标定的效果决定了后续所有步骤的好与坏,且不同的摄像头也需要不同的标定模型。标定算法流程图如图6所示。整个标定算法分为两个步骤:初次标定和再次标定。
初次标定:在双目摄像头下从不同的角度,不同的位置(中心、四角、四边)分别进行棋盘图采样,例如:共得到双目各47张,共94张图像。利用matlab工具箱,数据集为采集的47组图像,可以方便的计算出相机的内参及畸变系数等,其结果误差一般比较大,无法直接使用。
再次标定:衡量标定结果的好坏的指标是再次标定的条件,本发明采用平均像素反投影误差作为衡量标定的标准。相机的标定一般无法一次达到最佳效果,因此需要再次标定,这一过程是对初次标定的结果进行优化,即将反投影误差中最大的10%的图片删除后再次标定,循环反复,直到最大反投影误差小于0.15时,可以算作成功标定。
畸变校正是为立体匹配乃至整个环境感知算法提供数据保障,好的畸变校正能使算法获取真实世界的景物,从而获得更高的鲁棒性。利用标定后的参数进行图像校正。对棋盘图校正最可以看出校正算数据的可行性,若棋盘格保证直线则会有较好的校正效果。
立体匹配算法原理是:完成畸变校正后的双目摄像头呈现完全平行的状态,这时世界中的物理点再左右两幅图像中的纵坐标完全一致,故匹配点的搜索从二维直接转换为一维搜索,以达到实时的目的。
考虑到自动驾驶的特殊性,虽然sgbm拥有较好的边缘细节但视差不平滑和噪声可能导致误判,bm对边缘处理不够好而由于算法有语义分割部分,很好了弥补了边缘问题,且bm算法效率足够高,故选用bm算法做立体匹配。
前面所有的校正工作已经使相机成像符合针孔相机模型,但仍然是处于相机坐标系中,而实际场景中物体的三维坐标需要通过双目立体视觉技术来确定,故此时需要利用相似三角形模型将相机坐标系转化为世界坐标系,即三维估计,请参见附图8。
o表示两个双目相机,当然通过校正已经完全平行,基线b表示双目相机主光轴之间的距离,直线o-c代表两相机的主光轴,距离oc为相机的焦距,p为世界坐标系上的物理点,成像图上的p代表物理点p在左右相机成像的像素点,x代表其横坐标值,y代表其纵坐标值,d代表视差,(i,j,k)代表物理点的三维坐标。首先阐述焦距和视差的概念。
焦距:
fleft=|oleft-cleft|
fright=|oright-cright|
视差:
d=xleft-xright
再可从上图得出三角关系:
联立上述方程即可求得i,j,k三值:
k即为最后所求得的距离,也可通过三维点云直接绘制三维图像,为自动驾驶提供条件。
为了进一步优化上述技术方案,步骤s23具体包括:
对左右畸变校正图像进行三通道直方图均衡化和去噪处理;
将处理后的图像输入到预先训练好的神经网络中,并基于上色规则得到分割图像和分割识别信息。
道路场景的语义分割算法难点在于必须兼顾效率,故需要在结构上相比传统卷积网络做出改进。训练集图像与摄像头采集的图像的色彩范围并不一致,故预处理首先需要在rgb通道上分别进行直方图均衡化。由于效率限制计算能力,必须将更多的计算能力放在特征提取阶段,以达到最好的编码效果。在分割的同时也获取了物体属性信息,即物体的名称,所以网络本身也是一个分类网络。为了可视化整个结果,还需要利用色彩标签对图像进行上色,具体流程请参见附图9。
为了进一步优化上述技术方案,预先训练好的神经网络采用enet网络结构,其中,enet网络的bottleneck层中激活函数采用leakyrelu结构,去掉了所有1×1大小的卷积,残差结构中所有卷积计算全部采用分解卷积核。
本发明采用的神经网络在现有神经网络的基础上进行了以上几点改进,具体请参见附图11和附图12的对比,附图11为现有的神经网络bottleneck层的结构和处理流程,图12为本发明改进的神经网络bottleneck层的结构和处理流程。
下面对神经网络具体结构做具体论述:
已经过畸变校正后的图像由于尺寸过大,首先进行两次降维操作,而后利用5个残差块对特征充分学习,将得到的特征再次降维,此时图像尺寸非常小,但对于3x3的卷积来说,感受野实在太小,故需要再降维,但再次降维带来的弊端时图像细节丢失过多导致无法学习到有效特征,这时使用空洞卷积残差块来增大感受野进行学习,共两组残差,每组4个残差块,其空洞步长分别为2,4,6,8,越到后面感受野越大。然后通过两次升采样块,每个升采样后面更两个残差块细化重构的特征,最后再跟上一个升采样块得到pixel-wise的分类信息,通过softmax多项式分布拟合整个数据。整个网络分为两大模块:编码模块和解码模块。编码模块对整幅图像的特征进行提取,而解码模块对特征进行重组以达到分割效果。从结构图中可以看出,整个网络用残差结构贯穿。图像尺寸大时快速的进行降维,但直接降维会导致图像的细节丢失,故利用下采样块双通道降维方式。这种方式的优点是:1.有参数的卷积以保证细节部分。2.maxpooling相当于无参数降维,可以保证整个网络不会梯度弥散,效果类似于残差结构。3.增加了降维操作的鲁棒性。升采样块并未使用反卷积,反卷积会导致出现棋盘效应而采用最近邻上采用加上卷积的组合可以消除期盼效应并且有着同样的效果。在残差块中,网络采用空洞卷积,空洞卷积可以增大卷积核的感受野从而使特征提取更加精准,还加随机失活层,防止网络过拟合。
过多的降维操作会导致图像信息丢失,而不降维则感受野太小无法获取大范围的信息,在图像尺寸大时用降维操作来提升感受野,图像尺寸小时无法降维,就用空洞卷积进行特征学习。空洞卷积即带孔卷积(dilatedconvolution),将卷积核隔点填充0即可完成操作。当卷积核为3x3,带孔1个时,实际感受野大小相当于一次降采样后的卷积,即实际卷积核大小为5x5。整个带孔卷积操作相当于做了一次pooling却没有特征丢失。
反卷积使用在步长设置方面有着严格的要求,如果冲突叠加就会产生棋盘格纹理。有三种解决方案:1.设置不会产生叠加冲突的反卷积步长,但由于层数过多通常设置起来非常困难。2.在反卷操作后再添加1x1的反卷积结构能改善这一现象,但实际消耗的计算能力会增长。3.利用最近邻上采样和一层卷积结构代替反卷积结构,即解决了棋盘效应,又不额外消耗计算能力,本文算法即采用这种方案。
残差结构会面临一个问题,那就是梯度弥散,网络越深,梯度大小会以数量级的减小甚至消失,使得网络无法继续训练。残差模式可以让网络非常的深,因为其在训练时将前层不经过卷积的数据直接叠加到后层数据中,使得梯度可以贯穿整个网络。残差结构图如图10所示。
来自上一层网络的计算结果有两个输出,一是流向下一次隐藏层进行特征的提取,二是与隐藏层的输出结果一起作为两者共有的下一层网络的输入,这一连接方式叫做shortcut连接,解决了网络深度增加带来的致梯度弥散或梯度爆炸,这一结构使得网络能够变得很深,性能得到显著提升。
残差结构的公式:
res(n+1)=f2[res(n)+f1[res(n)]]
梯度反向传播时,残差块前一层直接可以获得残差块后一层的梯度进行更新,故梯度数量级不会衰减。
本发明提供的方法在网络中加入了leakyrelu结构。leakyrelu解决了relu函数′dyingrelu′问题,当学习率不稳定时,神经元有半数以上会′dead′,也就是权值为0。leakyrelu给了负值一个很小的权值因子,既修正了数据的分布,也保留了非激活神经元的信息:
leakyrelu(x)=max(ax,x)
为了使网络梯度更新更加稳定,收敛更加迅速,本文在残差架构中加入了batchnormalization(bn)结构。bn结构和lrn类似,首先需要将均值归0方差归1化:
为了防止降低模型的表达能力,bn结构在对均值归0方差归1化的同时,又加入了可学习的两个参数γ和β,增加了模型的容量,并利用动量衰减进行梯度更新:
损失函数
在选用损失函数前先分析整体算法优化目标。本算法目标是做分割,预测结果应当是分割图像,而由于每个分割区域会对应不同的分类即物体属性,故相当于是对每一个像素做分类,最后输出的就是每个像素分类完成的图像,是一个单通道图像,每个像素值代表着其所在分割区域的物体分类。既然是分类网络且是一个多分类网络,最好的损失函数就是多项式交叉熵损失:
为了满足广义线性回归模型,网络结尾激活函数选用softmax函数,是sigmoid的多分类版本,其在二分类时会退化成sigmoid函数:
综上所述,本发明提供的方法主要从以下几个方面对语义分割所采用的神经网络做出了改进:
1、激活函数用leakyrelu结构替代了prelu,解决了relu函数‘dyingrelu’问题,当学习率不稳定时,神经元有半数以上会‘dead’,也就是权值为0。激活函数leakyrelu既修正了数据的分布,也保留了非激活神经元的信息。2.去掉了所有的1x1大小的卷积。3.残差结构的所有卷积计算全部使用了分解卷积核。4.使用多项式交叉熵损失函数。以上对神经网络结构的改进能够得到更好的分割结果。
为了进一步优化上述技术方案,步骤s24具体包括:
将所述左右畸变校正图像进行滤波去噪处理,得到去噪畸变校正图像;
对去噪畸变校正图像进行边缘检测,得到边缘检测结果;
对边缘检测结果进行范围框定和霍夫变换,得到车道线坐标。
车道线是自动驾驶前行方向的依据,故需要准确高效的识别车道线。车道线检测算法流程图如图7所示。
为了进一步优化上述技术方案,还包括:步骤s13:对影响安全驾驶的行为动作进行语音提醒。通过对采集的图像进行处理,得到驾驶员是否疲劳驾驶和安全驾驶,若发现不安全的情况则进行语音提醒,为驾驶员的安全行驶保驾护航。
为了进一步优化上述技术方案,步骤s1中还包括:基于单目图像信息判断驾驶员是否为车主或允许的人员。
此外,本发明实施例还公开了一种三目视觉安全驾驶系统,包括:
单目检测模块,用于基于卷积神经网络对单目图像信息中的眼睛状态信息进行二分类操作,并根据perclos指标来判断是否为疲劳驾驶;
行为判断模块,用于基于卷积神经网络对单目图像信息进行特征提取,得到人体骨骼节点在图像中的位置,通过节点相对位置的不同判定司机的行为动作是否影响安全驾驶;
畸变校正模块,用于对双目图像信息进行双目标定和畸变校正,得到左右畸变校正图像;
三维重建模块,用于将左右畸变校正图像输入到三维重建模型中进行三维重建,得到三维重建结果;
语义分割模块,用于将所述左右畸变校正图像输入到语义分割模型中,得到分割图像和分割识别信息;
车道线检测模块,用于将所述左右畸变校正图像输入到车道线分割模型中,得到车道线坐标。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!