摘要生成方法、装置、电子设备及计算机可读存储介质与流程
本公开的实施例涉及互联网技术领域,尤其涉及一种摘要生成方法、摘要生成装置、电子设备及计算机可读存储介质。
背景技术:
随着科技水平的不断提升,人们通常会通过互联网搜索热点新闻事件,以关注最新动态。
而在日常的搜索场景中,经常可见的是:大数据热门榜单或实时搜索热点排名模块等,为用户展示了距离当前一段时间内的热门事件或话题,然而仅展示搜索词的方式,导致展示的信息量比较匮乏,用户无法得知热搜词背后的具体信息。而通过人工从互联网中提取相关信息的方式,会耗费大量的人力资源,增加了人力运营成本。
技术实现要素:
本公开实施例提供了一种摘要生成方法、装置、电子设备及计算机可读存储介质,用以挖掘出热搜词的摘要信息,可以使用户得知热搜词背后的具体信息,无需人工参与,节省了人力资源,进而减少了人力运营成本。
根据本公开实施例的第一方面,提供了一种摘要生成方法,包括:
从数据源中筛选出具有热点属性的热搜词;
从所述数据源获取与所述热搜词关联的内容文本;以及
基于所述内容文本,生成与所述热搜词对应的摘要文本。
可选地,所述从数据源中筛选出具有热点属性的热搜词,包括:
从数据源的热搜榜单中提取信息文本;以及
从所述信息文本中,筛选出具有热点属性的热搜词。
可选地,所述从数据源的热搜榜单中提取信息文本,包括:
选定具有热搜榜单的数据源;
解析所述数据源的网页元素配置,生成文本提取模板;以及
在达到设定时间时,根据所述文本提取模板从所述数据源提取信息文本。
可选地,所述从所述信息文本中,筛选出具有热点属性的热搜词,包括:
对所述信息文本进行分词处理,得到多个分词文本;
对多个所述分词文本进行通用词过滤处理,得到过滤信息文本;以及
依据所述过滤信息文本,筛选出具有热点属性的热搜词。
可选地,所述依据所述过滤信息文本,筛选出具有热点属性的热搜词,包括:
从所述过滤信息文本中,获取距离当前时间的预设时间段内出现频度大于频度阈值的至少一个目标信息文本;以及
获取所述至少一个目标信息文本对应的热度值,并将热度值为最大的目标信息文本作为热搜词。
可选地,所述从数据源中筛选出具有热点属性的热搜词,包括:
监听数据源中的热搜榜单;以及
从所述数据源的热搜榜单中筛选出具有热点属性的热搜词。
可选地,所述基于所述内容文本,生成与所述热搜词对应的摘要文本,包括:
按照句格式对所述内容文本进行拆分,得到与所述内容文本对应的多个句子文本;其中,所述句格式是指按照特殊标点符号拆分文本的格式;
将所述内容文本输入主题训练模型,获取与所述内容文本对应的主题词;以及
基于与所述内容文本对应的主题词和多个句子文本,生成所述热搜词对应的摘要文本。
可选地,在所述基于所述内容文本,生成与所述热搜词对应的摘要文本之后,还包括:
将所述热搜词和所述摘要文本进行关联及展示。
根据本公开实施例的第二方面,提供了一种摘要生成装置,包括:
热搜词获取模块,用于从数据源中筛选出具有热点属性的热搜词;
内容文本获取模块,用于从所述数据源获取与所述热搜词关联的内容文本;以及
摘要文本生成模块,用于基于所述内容文本,生成与所述热搜词对应的摘要文本。
可选地,所述热搜词获取模块包括:
信息文本提取子模块,用于从数据源的热搜榜单中提取信息文本;以及
热搜词获取子模块,用于从所述信息文本中,筛选出具有热点属性的热搜词。
可选地,所述信息文本提取子模块包括:
数据源选定子模块,用于选定具有热搜榜单的数据源;
提取模板生成子模块,用于解析所述数据源的网页元素配置,生成文本提取模板;以及
信息文本获取子模块,用于在达到设定时间时,根据所述文本提取模板从所述数据源提取信息文本。
可选地,所述热搜词获取子模块包括:
分词文本获取子模块,用于对所述信息文本进行分词处理,得到多个分词文本;
过滤文本获取子模块,用于对多个所述分词文本进行通用词过滤处理,得到过滤信息文本;以及
热搜词筛选子模块,用于依据所述过滤信息文本,筛选出具有热点属性的热搜词。
可选地,所述热搜词筛选子模块包括:
目标信息文本获取子模块,用于从所述过滤信息文本中,获取距离当前时间的预设时间段内出现频度大于频度阈值的至少一个目标信息文本;以及
热搜词确定子模块,用于获取所述至少一个目标信息文本对应的热度值,并将热度值为最大的目标信息文本作为热搜词。
可选地,所述热搜词获取模块包括:
热搜榜单监听子模块,用于监听数据源中的热搜榜单;以及
热搜词监听子模块,用于从所述数据源的热搜榜单中筛选出具有热点属性的热搜词。
可选地,所述摘要文本生成模块包括:
句子文本获取子模块,用于按照句格式对所述内容文本进行拆分,得到与所述内容文本对应的多个句子文本;其中,所述句格式是指按照特殊标点符号拆分文本的格式;
主题词获取子模块,用于将所述内容文本输入主题训练模型,获取与所述内容文本对应的主题词;以及
摘要文本生成子模块,用于基于与所述内容文本对应的主题词和多个句子文本,生成所述热搜词对应的摘要文本。
可选地,还包括:
摘要文本关联展示模块,用于将所述热搜词和所述摘要文本进行关联及展示。
根据本公开实施例的第三方面,提供了一种电子设备,包括:处理器、存储器以及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序时实现上述任一项所述的摘要生成方法。
根据本公开实施例的第四方面,提供了一种计算机可读存储介质,存储有计算机指令,当所述计算机指令由电子设备的处理器执行时,使得电子设备能够执行上述任一项所述的摘要生成方法。
本公开实施例提供了一种摘要生成方法、装置、电子设备及计算机可读存储介质,通过从数据源中筛选出具有热点属性的热搜词,从数据源获取与热搜词关联的内容文本,并基于内容文本生成与热搜词对应的摘要文本。本公开实施例可以通过挖掘的热搜词自动提取出爆点信息,无需人工参与,节省了人力资源;并且,通过将挖掘的热搜词的爆点信息以摘要形势展现,可以使用户能够快速得知热搜词背后的具体信息,通过上述实现方式,能够解决仅展示搜索词的方式所导致展示的信息量比较匮乏的问题,且无需人工提取热搜词的相关信息,减少了人力运营成本。
附图说明
为了更清楚地说明本公开的实施例的技术方案,下面将对本公开的实施例的描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本公开的实施例的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1是本公开实施例一提供的一种摘要生成方法的步骤流程图;
图2是本公开实施例二提供的一种摘要生成方法的步骤流程图;
图3是本公开实施例三提供的一种摘要生成装置的结构示意图;
图4是本公开实施例四提供的一种摘要生成装置的结构示意图;
图5是本公开实施例提供的一种示例中的热搜词获取模块的结构示意图;
图6是本公开实施例提供的另一种示例中的热搜词获取模块的结构示意图;
图7是本公开实施例提供的一种信息文本提取子模块的结构示意图;
图8是本公开实施例提供的一种热搜词获取子模块的结构示意图;
图9是本公开实施例提供的一种热搜词筛选子模块的结构示意图;
图10是本公开实施例提供的一种摘要文本生成模块的结构示意图。
具体实施方式
下面将结合本公开的实施例中的附图,对本公开的实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本公开的实施例一部分实施例,而不是全部的实施例。基于本公开的实施例中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本公开的实施例保护的范围。
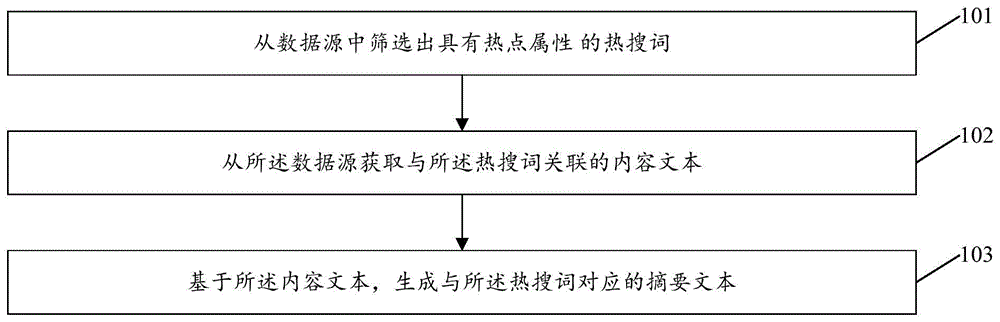
参照图1,示出了本公开实施例一提供的一种摘要生成方法的步骤流程图,该摘要生成方法具体可以包括如下步骤:
步骤101:从数据源中筛选出具有热点属性的热搜词。
本公开实施例可以应用于生成与热搜词对应的摘要信息的场景中。
数据源是指可以自主产生文本内容,且具有热搜榜单的网站或app(application,应用程序),而且,数据源中的信息更新频率可以保证能够追逐的上热点新闻,信息内容可以是来自用户或网站内部人员上传的,例如:微信公众号、新浪微博、百度新闻、搜狗新闻等主流媒体网站,在这些网站上提供有供用户查看热点信息的热门榜单、实时搜索热点等热点版块,在热点版块内可以由网站内部人员或其他用户实时上传最热门的信息内容。
可以理解地,上述示例仅是为了更好地理解本公开实施例的技术方案而列举的示例,不作为对本公开实施例的唯一限制。
热点属性是指热搜词在当前一段时间内的搜索热度和搜索量等较高,且具有提取摘要意义的属性。
在某些示例中,热点属性可以反映出从未上过热搜榜单的搜索词,在一个固定周期(如一周或一个月等)内,搜索量突然增加(如在一周内的搜索量超过800次或1000次等),并且进入了热搜榜单,可以将该搜索词在固定周期内的搜索量作为热点属性,则将该搜索词作为热搜词。
在某些示例中,热点属性可以反映出一个曾经出现在热搜榜单上的热搜词的搜索量,例如,曾经出现在热搜榜单中的一个热搜词,在当前一段时间内的搜索量突然增加,并再次进入了热搜榜单,可以将该热搜词在当前一段时间段内的搜索量作为该热搜词的热点属性,并将该热搜词重新作为具有热点属性的热搜词。
当然,不仅限于此,在具体实现中,还可以筛选出其它形式的具有热点属性的热搜词,具体地,可以根据实际情况而定,本公开实施例对此不加以限制。
本公开实施例通过获取热搜词的摘要信息,可以更好地为用户展示热搜词的摘要信息,以使用户得知热搜词背后的具体信息。
在选定数据源之后,可以从选定的数据源中提取信息文本,获取具有热点属性的热搜词。
在一种可实现的示例中,可以按照预先设置的文本提取模板从数据源中提取出信息文本,进而根据提取的信息文本筛选出具有热点属性的热搜词。
在另一种可实现的示例中,可以是对热搜榜单实时监听,从选定的数据源中筛选出具有热点属性的热搜词。
在从数据源中筛选出具有热点属性的热搜词之后,执行步骤102。
步骤102:从所述数据源获取与所述热搜词关联的内容文本。
内容文本是指与热搜词关联的热点事件的信息文本,内容文本可以是如通过热搜词在数据源中搜索到的新闻事件等热点事件,在点击热点事件对应的链接后,可以展示一个详细介绍热搜词关联事件的信息文本,这些信息文本可以作为与热搜词关联的内容文本。
在筛选出具有热点属性的热搜词之后,可以根据热搜词在数据源中进行搜索,得到与热搜词相关的内容文本。
在本公开中,可以采用网络爬虫的方式爬取数据源中与热搜词关联的内容文本,或者,也可以实时监听数据源中与热搜词关联的ugc(usergeneratedcontent,用户生成内容),即实时监听用户原创的与热搜词关联的内容文本。
网络爬虫又被成为网络机器人,是一种按照一定的规则,自动抓取万维网信息的程序或脚本,在本公开实施例中,可以由业务人员预先设置提取规则,如爬取热搜榜单获取与热搜词关联链接地址的内容的规则等,进而,可以采用网络爬虫从热搜词关联的页面内,读取网页的内容。
ugc也即用户原创内容,在系统中可以预先设置监听程序,通过该监听程序可以实时监听数据源的热搜榜单内出现的与热搜词关联的原创内容,在监听到与热搜词关联的用户原创内容时,可以获取用户原创内容的详细内容文本。
在具体实现中,还可以采用其它方式获取与热搜词关联的内容文本,如每隔预设时间采用热搜词在热搜榜单内执行一次搜索,以获取与热搜词关联的内容文本等方式。具体地,可以根据业务需求而定,本公开实施例对此不加以限定。
在从数据源获取与热搜词关联的内容文本之后,执行步骤103。
步骤103:基于所述内容文本,生成与所述热搜词对应的摘要文本。
摘要文本是指用于描述热搜词对应的热点事件的文本信息。
在从数据源中获取与热搜词关联的内容文本之后,可以结合内容文本生成与热搜词对应的摘要文本,具体地,可以将内容文本进行拆分,得到多个句子文本,并将内容文本输入至主题训练模型获取对应的主题词,根据多个句子文本和主题词,生成热搜词对应的摘要文本。
主题训练模型是指用于对文本进行训练得到对应的主题词的模型。
主题训练模型的训练过程可以为:
1、预先获取多个(如800个或1000个等)训练样本,每个训练样本包括内容文本和内容文本对应的初始主题词;
2、将多个训练样本依次输入初始主题训练模型(即还未进行训练的模型),由初始主题训练模型输出每个训练样本所对应的预测主题词;
3、根据初始主题词和预测主题词的相似性,计算得到损失值;
4、在损失值处于预设范围内的情况下,则将初始主题训练模型作为训练后的主题训练模型;
5、在损失值未处于预设范围内的情况下,可以根据预先获取的训练样本再次输入至初始训练模型中执行训练过程,直至损失值处于预设范围内。
当然,在执行上述训练的过程中,在每次将一个训练样本输入至初始主题训练模型之后,均执行一次损失值获取,及与预设范围的比较过程,在获取的损失值未处于预设范围内的情况下,则获取下一个训练样本进行训练,依次类推,直至获取的损失值处于预设范围内。
在训练得到主题训练模型之后,可以将得到的内容文本输入至主题训练模型,由主题训练模型输出内容文本所对应的主题词。
在本公开实施例中,主题训练模型可以为lda(latentdirichletallocation,文档主题生成模型)或者textrank等主题模型,在具体实现中,可以根据实际需要选择具体的主题训练模型,本公开实施例对此不加以限制。
本公开实施例通过生成与热搜词对应的摘要文本,用户可以直接通过摘要文本得知热搜词关联的具体信息,能够提高用户的感知度。
本公开实施例提供的摘要生成方法,通过从数据源中筛选出具有热点属性的热搜词,从数据源获取与热搜词关联的内容文本,并基于内容文本生成与热搜词对应的摘要文本。本公开实施例可以通过挖掘的热搜词自动提取出爆点信息,无需人工参与,节省了人力资源;并且,通过将挖掘的热搜词的爆点信息以摘要形势展现,可以使用户能够快速得知热搜词背后的具体信息,通过上述实现方式,能够解决仅展示搜索词的方式所导致展示的信息量比较匮乏的问题,且无需人工提取热搜词的相关信息,减少了人力运营成本。
参照图2,示出了本公开实施例二提供的一种摘要生成方法的步骤流程图,该摘要生成方法具体可以包括如下步骤:
步骤201:从数据源中筛选出具有热点属性的热搜词。
本公开实施例可以应用于生成与热搜词对应的摘要信息的场景中。
数据源是指可以自主产生文本内容,且具有热搜榜单的网站或应用,而且,数据源中的信息更新频率可以保证能够追逐的上热点新闻,信息内容可以是来自用户或网站内部人员上传的,例如:微信公众号、新浪微博、百度新闻、搜狗新闻等主流媒体网站,在这些网站上提供有供用户查看热点信息的热门榜单、实时搜索热点等热点版块,在热点版块内可以由网站内部人员或其他用户实时上传最热门的信息内容。
可以理解地,上述示例仅是为了更好地理解本公开实施例的技术方案而列举的示例,不作为对本公开实施例的唯一限制。
热点属性是指热搜词在当前一段时间内的搜索热度和搜索量等较高,且具有提取摘要意义的属性。
在某些示例中,热点属性可以反映出从未上过热搜榜单的搜索词,在一个固定周期(如一周或一个月等)内,搜索量突然增加(如在一周内的搜索量超过800次或1000次等),并且进入了热搜榜单,可以将该搜索词在固定周期内的搜索量作为热点属性,则将该搜索词作为热搜词。
在某些示例中,热点属性可以反映出一个曾经出现在热搜榜单上的热搜词的搜索量,例如,在当前一段时间内的曾经出现的一个热搜词的搜索量突然增加,并再次进入了热搜榜单,可以将该热搜词在当前一段时间段内的搜索量作为该热搜词的热点属性,并将该热搜词重新作为具有热点属性的热搜词。
当然,不仅限于此,在具体实现中,还可以筛选出其它形式的具有热点属性的热搜词,具体地,可以根据实际情况而定,本公开实施例对此不加以限制。
本公开实施例通过获取热搜词的摘要信息,可以更好地为用户展示热搜词的摘要信息,以使用户得知热搜词背后的具体信息。
而从数据源中获取具有热点属性的热搜词的方式可以结合下述具体实现方式进行详细描述。
在某些示例中,可以按照预先设置的文本提取模板从数据源中提取出信息文本,进而根据提取的信息文本筛选出具有热点属性的热搜词,具体地,结合下述具体实现方式进行详细描述。
在本公开的一种具体实现中,上述步骤201可以包括:
子步骤s1:从数据源的热搜榜单中提取信息文本。
信息文本是指从数据源的热搜榜单中提取的文本,可以理解地,在具有热搜榜单的数据源中,具有一个专门的版块用以提供热度较高的信息,从这个版块中可以提取出信息文本,如将这个版块内的所有信息均进行提取,以作为热搜榜单对应的信息文本。
当然,也可以预先设置一个提取模板,按照提取模板提取出相应的信息文本,具体地,可以参照下述具体实现方式的描述。
在本公开的一种具体实现中,上述子步骤s1可以包括:
子步骤a1:选定具有热搜榜单的数据源。
在本公开实施例中,可以预先从多个数据源中选取具有热搜榜单的数据源,例如,数据源包括数据源a、数据源b和数据源c,数据源a和数据源c具有热搜榜单,则可以将数据源a和数据源c作为选定的数据源。
可以理解地,上述示例仅是为了更好地理解本公开实施例的技术方案而列举的示例,不作为对本公开实施例的唯一限制。
在选定具有热搜榜单的数据源之后,执行子步骤a2。
子步骤a2:解析所述数据源的网页元素配置,生成文本提取模板。
文本提取模板是指由业务人员预先设置的,用于提取信息文本的模板。
对于不同的数据源可能具有不同的网页元素配置,也即不同的数据源对应的文本内容的格式是不相同的,可以针对不同网页元素配置的数据源配置不同的文本提取模板,例如,配置与网页元素配置为a的文本提取模板为:“content\:body\>div\>div\>div\>div\>div\.lemma-summary,title\:body\>div\>div\>a”。
在选定具有热搜榜单的数据源之后,可以对数据源的网页元素配置进行解析,并根据解析的数据源的网页元素配置,生成与数据源对应的文本提取模板,进而,执行子步骤a3。
子步骤a3:在达到设定时间时,根据所述文本提取模板从所述数据源提取信息文本。
设定时间是指预先设置的用于从热搜榜单提取信息文本的时间。
设定时间可以为预先设置的定时时间,如每天上午十点,或,每隔一天的上午十点等。
设定时间也可以为预先设置的等间隔时间,如每间隔两小时,或者每间隔四小时等。
设定时间还可以为根据数据源的特征,预先设置的不等间隔的时间,例如,数据源在白天的访问量比较大,数据源内的信息更新频率较高,设定时间可以设置为:从早上六点到夜间十二点的时间段内,每隔一个小时;而夜间的访问量较小,信息更新频率比较低,设定时间可以设置为:从夜间十二点至早上六点的时间段内,每隔两个小时等。
在达到设定时间时,可以采用网络爬虫按照文本提取模板从网页中提取信息文本,例如,承接上述子步骤a2中的示例,配置的模板为:“content\:body\>div\>div\>div\>div\>div\.lemma-summary,title\:body\>div\>div\>a”,可以采用爬虫服务按照这个模板解析网页上的对应html元素结构下的数据,并赋值给content和title两个变量。
可以理解地,上述示例仅是为了更好地理解本公开实施例的技术方案而列举的示例,不作为对本公开实施例的唯一限制。
当然,在具体实现中,还可以采用其它方式从数据源的热搜榜单中提取信息文本,具体地,可以根据业务需求而定,本公开实施例对此不加以限制。
在从数据源的热搜榜单中提取信息文本之后,执行子步骤s2。
子步骤s2:从所述信息文本中,筛选出具有热点属性的热搜词。
热点属性是指热搜词在当前一段时间内的搜索热度和搜索量等较高,且具有提取摘要意义的属性。
在从数据源的热搜榜单中提取出信息文本之后,可以根据提取的信息文本筛选出具有热点属性的热搜词,具体地,可以结合下述具体实现方式进行详细描述。
在本公开的一种具体实现方式中,上述子步骤s2可以包括:
子步骤b1:对所述信息文本进行分词处理,得到多个分词文本。
在本公开实施例中,分词处理的方式可以为采用预先训练好的分词处理模型,即将信息文本输入至分词处理模型,通过分词处理模型对信息文本进行分词。
分词处理模型是指对信息文本进行分词的模型,分词处理模型的训练过程可以参照步骤:
1、预先获取多个(如800个或1000个等)训练样本,每个训练样本包括信息文本和信息文本对应的初始分词文本;
2、将多个训练样本依次输入初始分词处理模型(即还未进行训练的模型),由初始分词模型输出每个训练样本对应的预测分词文本;
3、根据初始分词文本和预测分词文本,计算得到损失值;
4、在损失值处于预设范围内的情况下,则将初始分词处理模型作为训练后的分词处理模型;
5、在损失值未处于预设范围内的情况下,可以根据预先获取的训练样本再次输入至初始分词处理模型中执行训练过程,直至损失值处于预设范围内。
当然,在执行上述训练的过程中,在每次将一个训练样本输入至初始分词处理模型之后,均执行一次损失值获取,及与预设范围的比较过程,在获取的损失值未处于预设范围内的情况下,则获取下一个训练样本进行训练,依次类推,直至获取的损失值处于预设范围内。
在训练得到分词处理模型之后,可以将得到的信息文本输入至分词处理模型,由分词处理模型输出信息文本所对应的多个分词文本。
当然,分词处理的方式还可以为其它分词方式,本公开实施例对此不加以限制。
分词文本是指对信息文本进行分词处理之后,所得到的多个分词对应的文本,例如,信息文本为“米其林轮胎的质量比较好”,在对信息文本进行分词处理之后,得到的分词文本为:“米其林”、“轮胎”、“的”、“质量”、“比较”、“好”等。
可以理解地,上述示例仅是为了更好地理解本公开实施例的技术方案而列举的示例,不作为对本公开实施例的唯一限制。
在得到信息文本之后,可以对信息文本进行分词处理,从而得到多个分词文本,进而,执行子步骤b2。
子步骤b2:对多个所述分词文本进行通用词过滤处理,得到过滤信息文本。
通用词过滤是指过滤掉分词文本中的通用词,如语气词“的”、“吗”、“哦”等,也可以是其它类型的词,如感叹词等,具体地,可以根据实际情况而定。
过滤信息文本是指在将多个分词文本中的通用词过滤掉之后,剩余的分词文本即为过滤信息文本。例如,承接上述子步骤b1中的示例,对信息文本为“米其林轮胎的质量比较好”进行分词之后,得到的多个分词文本为:“米其林”、“轮胎”、“的”、“质量”、“比较”、“好”,过滤掉其中的通用词“的”、“比较”,剩余的分词文本为:“米其林”、“轮胎”、“质量”、“好”,这些剩余的分词文本即为过滤信息文本。
在得到信息文本对应的多个分词文本之后,可以对多个分词文本进行通用词过滤处理,即过滤掉多个分词文本中的通用分词文本,从而得到过滤信息文本。
在对多个分词文本进行通用词过滤处理得到过滤信息文本之后,执行子步骤b3。
子步骤b3:依据所述过滤信息文本,筛选出具有热点属性的热搜词。
在得到的信息文本对应的过滤信息文本之后,可以根据过滤信息文本,筛选出具有热点属性的热搜词,例如,可以从过滤信息文本中提取当前时间出现频率比较高的一个过滤信息文本作为热搜词,具体地,可以参照下述具体实现方式的描述。
在本公开的另一种具体实现方式中,上述子步骤b3可以包括:
子步骤c1:从所述过滤信息文本中,获取距离当前时间的预设时间段内出现频度大于频度阈值的至少一个目标信息文本。
在本公开实施例中,目标信息文本是指过滤信息文本中出现频度大于频度阈值的一个或多个过滤信息文本。
当前时间可以是指终端系统当前的时间。
预设时间段是指由业务人员预先设置的与当前时间距离的时间段,预设时间段可以为1天、3天或6天等,具体地,可以根据业务需求而定,本公开实施例对此不加以限制。
频度阈值是指由业务人员预先设置文本出现频度的阈值。
在获得过滤信息文本之后,可以从过滤信息文本中,获取距离当前时间的预设时间段内出现频度大于频度阈值的至少一个目标信息文本,例如,过滤信息文本包括文本a、文本b、文本c和文本d,频度阈值为0.6,文本a在距离当前时间的预设时间段内出现的频度为0.7,文本出现的频度为0.5,文本c出现的频度为0.8,文本d出现的频度为0.3,则可以将文本a和文本c作为目标信息文本。
可以理解地,上述示例仅是为了更好地理解本公开实施例的技术方案而列举的示例,不作为对本公开实施例的唯一限制。
在得到至少一个目标信息文本之后,执行子步骤c2。
子步骤c2:获取所述至少一个目标信息文本对应的热度值,并将热度值为最大的目标信息文本作为热搜词。
热度值是指信息文本的热度分值,热度值可以是结合距离当前时间的预设时间段内信息文本的搜索量得到的,例如,在一个固定周期内如一周或一个月内从未出上过榜单的搜索词,突然搜索量增加,可以根据搜索量确定该搜索词的热度值。
在具体实现方式中,还可以采用其它方式获取信息文本的热度值,具体地,可以根据业务需求而定,本公开实施例对此不加以限制。
在获取至少一个目标信息文本对应的热度值之后,可以将热度值最大的目标信息文本作为热搜词,例如,目标信息文本包括文本1、文本2和文本3,文本1的热度值为0.8,文本2的热度值为0.6,文本3的热度值为0.5,则将文本1作为热搜词;而在文本1和文本2的热度值均为0.7,文本3的热度值为0.5时,则将文本1和文本2作为热搜词。
可以理解地,上述示例仅是为了更好地理解本公开实施例的技术方案而列举的示例,不作为对本公开实施例的唯一限制。
在某些示例中,还可以通过监听数据源中的热搜榜单的方式获取具有热点属性的热搜词,具体地,可以结合下述具体实现方式进行详细描述。
在本公开的一种具体实现中,上述步骤201可以包括:
子步骤s3:监听数据源中的热搜榜单。
在本公开实施例中,可以在系统中预先设置热搜榜单对应的监听程序,通过该监听程序可以实时对数据源中的热搜榜单进行监听。
在实际应用中,还可以采用其它监听方式,具体地,可以根据业务需求而定,本公开实施例对此不加以限制。
在本公开中,可以预先选取具有热搜榜单的数据源,并对这些数据源中的热搜榜单进行实时监听,以实时监听出现在热搜榜单中的搜索词。
子步骤s4:从所述数据源的热搜榜单中筛选出具有热点属性的热搜词。
在实时监听到数据源中的热搜榜单中出现的搜索词之后,可以采用预先设置的规则而进行判定,以筛选出具有热点属性的热搜词。
预先设置的规则可以是如搜索热度判定、词性过滤、复合词调整等,从而提取出有摘要意义的热搜词,例如,在一个固定周期内如一周或一个月内从未出上过榜单的搜索词,突然搜索量增加,则必然存在一定的热点事件,如某个poi(pointofinterest,兴趣点)被评为米其林或某地新开了某家网红poi,此时就比较需要在榜单上加上辅助的摘要信息进行用户引导。
在从数据源中筛选出具有热点属性的热搜词之后,执行步骤202。
步骤202:从所述数据源获取与所述热搜词关联的内容文本。
内容文本是指与热搜词关联的热点事件的信息文本,内容文本可以是如通过热搜词在数据源中搜索到的新闻事件等热点事件,在点击热点事件对应的链接后,可以展示一个详细介绍热搜词关联事件的信息文本,这些信息文本可以作为与热搜词关联的内容文本。
在筛选出具有热点属性的热搜词之后,可以根据热搜词在数据源中进行搜索,可以得到与热搜词相关的内容文本。
在本公开中,可以采用网络爬虫的方式爬取数据源中与热搜词关联的内容文本,或者,也可以实时监听数据源中与热搜词关联的ugc(usergeneratedcontent,用户生成内容),即实时监听用户原创的与热搜词关联的内容文本。
在具体实现中,还可以采用其它方式获取与热搜词关联的内容文本,具体地,可以根据业务需求而定,本公开实施例对此不加以限定。
在从数据源获取与热搜词关联的内容文本之后,执行步骤203。
步骤203:按照句格式对所述内容文本进行拆分,得到与所述内容文本对应的多个句子文本;其中,所述句格式是指按照特殊标点符号拆分文本的格式。
句格式是指按照特殊标点符号拆分文本的格式,特殊标点符号可以为“。”、“?”、“!”等,具体地,可以根据业务需求而定。
句子文本是指在将内容文本按照句格式进行拆分之后,得到的多个文本。
在从数据源中获取与热搜词关联的内容文本之后,可以按照句格式对内容文本进行拆分,从而可以得到多个句子文本,例如,内容文本为:“银鱼的可食率达100%,被誉为"鱼参"。对于银鱼的滋补作用,在我国古代医典中多有记载。如《日用本草》载:味甘,平,无毒。宽中健胃。《医林纂要》云:补肺清金,滋阴,补虚劳。《随息居饮食谱》记载:养胃阴,和经脉。”,在内容按照句格式进行拆分之后,得到的句子文本分别为:1、“银鱼的可食率达100%,被誉为"鱼参"”;2、“对于银鱼的滋补作用,在我国古代医典中多有记载”;3、“如《日用本草》载:味甘,平,无毒”;4、“宽中健胃”;5、“《医林纂要》云:补肺清金,滋阴,补虚劳”;6、“《随息居饮食谱》记载:养胃阴,和经脉”。
可以理解地,上述示例仅是为了更好地理解本公开实施例的技术方案而列举的示例,不作为对本公开实施例的唯一限制。
在按照句格式对所述内容文本进行拆分,得到与内容文本对应的多个句子文本之后,执行步骤204。
步骤204:将所述内容文本输入主题训练模型,获取与所述内容文本对应的主题词。
主题训练模型是指用于对文本进行训练得到对应的主题词的模型,主题训练模型可以为lda(latentdirichletallocation,文档主题生成模型)或者textrank等主题模型。
对于主题训练模型的训练及应用过程可以参照上述方法实施例步骤103的描述,本公开实施例在此不再加以赘述。
在得到内容文本之后,可以将内容文本输入主题训练模型,从而可以获取与内容文本对应的主题词,以lda为例:可以将内容文本的主题以概率分布的形式给出,从而通过分析一些文档抽取出它们的主题分布后,便可以根据主题分布进行主题聚类或文本分类;例如,当以搜索词“鹅夫人”去进行网页爬取,再通过lda模型可分析出“米其林”、“粤菜”、“古法熏鹅肝”等主题词。
在获取与内容文本对应的主题词之后,执行步骤205。
步骤205:基于与所述内容文本对应的主题词和多个句子文本,生成所述热搜词对应的摘要文本。
在得到内容文本对应的主题词和多个句子文本之后,可以对句子文本中语句较长的句子执行分隔、相似语句去重、多次主题提取等步骤,最终得到热搜词对应的摘要文本。
摘要文本可以作为热搜词登上热搜榜单的理由,以为用户提供指引。
步骤206:将所述热搜词和所述摘要文本进行关联及展示。
在得到热搜词对应的摘要文本之后,可以将热搜词与摘要文本关联存储于缓存中,app端可以实时读取缓存中的摘要文本,也可以实时展示于客户端,例如,在用户移动鼠标光标至该热搜词至上时,可以弹出一个透明窗口,在透明窗口中可以展示热搜词关联的摘要文本;或者是,在热搜榜单所处的版块,可以在热搜词的附近位置处,展示与热搜词关联的摘要文本。
在具体实现中,还可以采用其它热搜词和摘要文本的关联展示方式,本公开实施例对此不加以限制。
本公开实施例通过将热搜词和摘要文本关联展示,可以使用户及时得知热搜词背后的具体信息,提高了用户的感知度。
本公开实施例提供的摘要生成方法,除了具备上述实施例一提供的摘要生成方法所具备的有益效果外,还可以实时监听热搜词,及时将挖掘出的摘要信息推送至客户端榜单页面,可以使用户及时了解热搜词关联的具体信息,提高了用户的感知度。
参照图3,示出了本发明实施例三提供的一种摘要生成装置的结构示意图,该摘要生成装置300可以包括如下模块:
热搜词获取模块310,用于从数据源中筛选出具有热点属性的热搜词。
本公开实施例可以应用于生成与热搜词对应的摘要信息的场景中。
数据源是指可以自主产生文本内容,且具有热搜榜单的网站或应用,而且,数据源中的网页信息更新频率可以保证能够追逐的上热点新闻,信息内容可以是来自用户或网站内部人员上传的,例如:微信公众号、新浪微博、百度新闻、搜狗新闻等主流媒体网站,在这些网站上提供有供用户查看热点信息的热门榜单、实时搜索热点等热点版块,在热点版块内可以由网站内部人员或其他用户实时上传最热门的信息内容。
可以理解地,上述示例仅是为了更好地理解本公开实施例的技术方案而列举的示例,不作为对本公开实施例的唯一限制。
热点属性是指热搜词在当前一段时间内的搜索热度和搜索量等较高,且具有提取摘要意义的属性。
在某些示例中,热点属性可以反映出从未上过热搜榜单的搜索词,在一个固定周期(如一周或一个月等)内,搜索量突然增加(如在一周内的搜索量超过800次或1000次等),并且进入了热搜榜单,可以将该搜索词在固定周期内的搜索量作为热点属性,则将该搜索词作为热搜词。
在某些示例中,热点属性也可以反映出一个曾经出现在热搜榜单上的热搜词的搜索量,例如,曾经出现在热搜榜单中的一个热搜词,在当前一段时间内的搜索量突然增加,并再次进入了热搜榜单,可以将该热搜词在当前一段时间段内的搜索量作为该热搜词的热点属性,并将该热搜词重新作为具有热点属性的热搜词。
当然,不仅限于此,在具体实现中,还可以筛选出其它形式的具有热点属性的热搜词,具体地,可以根据实际情况而定,本公开实施例对此不加以限制。
本公开实施例通过获取热搜词的摘要信息,可以更好地为用户展示热搜词的摘要信息,以使用户得知热搜词背后的具体信息。
在选定数据源之后,热搜词获取模块310可以从选定的数据源中提取信息文本,获取具有热点属性的热搜词。
在一种可实现的示例中,热搜词获取模块310可以按照预先设置的文本提取模板从数据源中提取出信息文本,进而根据提取的信息文本筛选出具有热点属性的热搜词。
在另一种可实现的示例中,热搜词获取模块310可以是对热搜榜单实时监听,从选定的数据源中筛选出具有热点属性的热搜词。
在热搜词获取模块310从数据源中筛选出具有热点属性的热搜词之后,执行内容文本获取模块320。
内容文本获取模块320,用于从所述数据源获取与所述热搜词关联的内容文本。
内容文本是指与热搜词关联的热点事件的信息文本,内容文本可以是如通过热搜词在数据源中搜索到的新闻事件等热点事件,在点击热点事件对应的链接后,可以展示一个详细介绍热搜词关联事件的信息文本,这些信息文本可以作为与热搜词关联的内容文本。
在热搜词获取模块310筛选出具有热点属性的热搜词之后,可以由内容文本获取模块320根据热搜词在数据源中进行搜索,得到与热搜词相关的内容文本。
在本公开中,可以由内容文本获取模块320采用网络爬虫的方式爬取数据源中与热搜词关联的内容文本,或者,实时监听数据源中与热搜词关联的ugc(usergeneratedcontent,用户生成内容),即实时监听用户原创的与热搜词关联的内容文本。
网络爬虫又被成为网络机器人,是一种按照一定的规则,自动抓取万维网信息的程序或脚本,在本公开实施例中,可以由业务人员预先设置提取规则,如爬取热搜榜单获取与热搜词关联链接地址的内容的规则等,进而,可以采用网络爬虫从热搜词关联的页面内,读取网页的内容。
ugc也即用户原创内容,在系统中可以预先设置监听程序,通过该监听程序可以实时监听数据源的热搜榜单内出现的与热搜词关联的原创内容,在监听到与热搜词关联的用户原创内容时,可以获取用户原创内容的详细内容文本。
在具体实现中,还可以内容文本获取模块320采用其它方式获取与热搜词关联的内容文本,如每隔预设时间采用热搜词在热搜榜单内执行一次搜索,以获取与热搜词关联的内容文本等方式。具体地,可以根据业务需求而定,本公开实施例对此不加以限定。
在内容文本获取模块320从数据源获取与热搜词关联的内容文本之后,执行摘要文本生成模块330。
摘要文本生成模块330,用于基于所述内容文本,生成与所述热搜词对应的摘要文本。
摘要文本是指用于描述热搜词对应的热点事件的文本信息。
在内容文本获取模块320从数据源获取与热搜词关联的内容文本之后,可以由摘要文本生成模块330结合内容文本生成与热搜词对应的摘要文本,具体地,可以将内容文本进行拆分,得到多个句子文本,并将内容文本输入至主题训练模型获取对应的主题词,摘要文本生成模块330可以根据多个句子文本和主题词,生成热搜词对应的摘要文本。
主题训练模型是指用于对文本进行训练得到对应的主题词的模型。
主题训练模型的训练过程可以为:
1、预先获取多个(如800个或1000个等)训练样本,每个训练样本包括内容文本和内容文本对应的初始主题词;
2、将多个训练样本依次输入初始主题训练模型(即还未进行训练的模型),由初始主题训练模型输出每个训练样本所对应的预测主题词;
3、根据初始主题词和预测主题词的相似性,计算得到损失值;
4、在损失值处于预设范围内的情况下,则将初始主题训练模型作为训练后的主题训练模型;
5、在损失值未处于预设范围内的情况下,可以根据预先获取的训练样本再次输入至初始训练模型中执行训练过程,直至损失值处于预设范围内。
当然,在执行上述训练的过程中,在每次将一个训练样本输入至初始主题训练模型之后,均执行一次损失值获取,及与预设范围的比较过程,在获取的损失值未处于预设范围内的情况下,则获取下一个训练样本进行训练,依次类推,直至获取的损失值处于预设范围内。
在训练得到主题训练模型之后,可以将得到的内容文本输入至主题训练模型,由主题训练模型输出内容文本所对应的主题词。
在本公开实施例中,主题训练模型可以为lda(latentdirichletallocation,文档主题生成模型)或者textrank等主题模型,在具体实现中,业务人员可以根据实际需要选择具体的主题训练模型,本公开实施例对此不加以限制。
本公开实施例通过生成与热搜词对应的摘要文本,用户可以直接通过摘要文本得知热搜词关联的具体信息,能够提高用户的感知度。
本公开实施例提供的摘要生成装置,通过从数据源中筛选出具有热点属性的热搜词,从数据源获取与热搜词关联的内容文本,并基于内容文本生成与热搜词对应的摘要文本。本公开实施例可以通过挖掘的热搜词自动提取出爆点信息,无需人工参与,节省了人力资源;并且,通过将挖掘的热搜词的爆点信息以摘要形势展现,可以使用户能够快速得知热搜词背后的具体信息,通过上述实现方式,能够解决仅展示搜索词的方式所导致展示的信息量比较匮乏的问题,且无需人工提取热搜词的相关信息,减少了人力运营成本。
实施例四
参照图4,示出了本发明实施例提供的一种摘要生成装置的结构示意图,该摘要生成装置400可以包括:热搜词获取模块410、内容文本获取模块420、摘要文本生成模块430和摘要文本关联展示模块440。
热搜词获取模块410可以用于从数据源中筛选出具有热点属性的热搜词。
本公开实施例可以应用于生成与热搜词对应的摘要信息的场景中。
数据源是指可以自主产生文本内容,且具有热搜榜单的网站,而且,数据源中的网页信息更新频率可以保证能够追逐的上热点新闻,信息内容可以是来自用户或网站内部人员上传的,例如:微信公众号、新浪微博、百度新闻、搜狗新闻等主流媒体网站,在这些网站上提供有供用户查看热点信息的热门榜单、实时搜索热点等热点版块,在热点版块内可以由网站内部人员或其他用户实时上传最热门的信息内容。
可以理解地,上述示例仅是为了更好地理解本公开实施例的技术方案而列举的示例,不作为对本公开实施例的唯一限制。
热点属性是指热搜词在当前一段时间内的搜索热度和搜索量等较高,且具有提取摘要意义的属性。
在某些示例中,热点属性可以反映出从未上过热搜榜单的搜索词,在一个固定周期(如一周或一个月等)内,搜索量突然增加(如在一周内的搜索量超过800次或1000次等),并且进入了热搜榜单,可以将该搜索词在固定周期内的搜索量作为热点属性,则将该搜索词作为热搜词。
在某些示例中,热点属性可以反映出一个曾经出现在热搜榜单上的热搜词的搜索量,例如,在当前一段时间内的曾经出现的一个热搜词的搜索量突然增加,并再次进入了热搜榜单,可以将该热搜词在当前一段时间段内的搜索量作为该热搜词的热点属性,并将该热搜词重新作为具有热点属性的热搜词。
当然,不仅限于此,在具体实现中,还可以筛选出其它形式的具有热点属性的热搜词,具体地,可以根据实际情况而定,本公开实施例对此不加以限制。
本公开实施例通过获取热搜词的摘要信息,可以更好地为用户展示热搜词的摘要信息,以使用户得知热搜词背后的具体信息。
在选定数据源之后,热搜词获取模块410可以从选定的数据源中提取信息文本,获取具有热点属性的热搜词。
在一种可实现的示例中,热搜词获取模块410可以按照预先设置的文本提取模板从数据源中提取出信息文本,进而根据提取的信息文本筛选出具有热点属性的热搜词。具体地,结合下述具体实现方式进行详细描述。
在本公开的一种具体实现中,如图5所示,所述热搜词获取模块410包括:信息文本提取子模块411、热搜词获取子模块412。
信息文本提取子模块411可以用于从数据源的热搜榜单中提取信息文本。
信息文本是指从数据源的热搜榜单中提取的文本,可以理解地,在具有热搜榜单的数据源中,具有一个专门的版块用以提供热度较高的信息,从这个版块中可以提取出信息文本,如将这个版块内的所有信息均进行提取,以作为热搜榜单对应的信息文本。
当然,也可以预先设置一个提取模板,信息文本提取子模块可以按照提取模板提取出相应的信息文本,具体地,可以参照下述具体实现方式的描述。
在本公开的另一种具体实现中,如图7所示,上述信息文本提取子模块411可以包括:数据源选定子模块4112、提取模板生成子模块4114、以及信息文本获取子模块4116。
数据源选定子模块4112可以用于选定具有热搜榜单的数据源。
在本公开实施例中,可以由数据源选定子模块预先从多个数据源中选取具有热搜榜单的数据源,例如,数据源包括数据源a、数据源b和数据源c,数据源a和数据源c具有热搜榜单,则可以将数据源a和数据源c作为选定的数据源。
可以理解地,上述示例仅是为了更好地理解本公开实施例的技术方案而列举的示例,不作为对本公开实施例的唯一限制。
在由数据源选定子模块选定具有热搜榜单的数据源之后,执行提取模板生成子模块。
提取模板生成子模块4114可以用于解析所述数据源的网页元素配置,生成文本提取模板。
文本提取模板是指由业务人员预先设置的,用于提取信息文本的模板。
对于不同的数据源可能具有不同的网页元素配置,也即不同的数据源对应的文本内容的格式是不相同的,可以针对不同网页元素配置的数据源配置不同的文本提取模板,例如,配置与网页元素配置为a的文本提取模板为:“content\:body\>div\>div\>div\>div\>div\.lemma-summary,title\:body\>div\>div\>a”。
在数据源选定子模块4112选定具有热搜榜单的数据源之后,可以对数据源的网页元素配置进行解析,并由提取模板生成子模块4114根据解析的数据源的网页元素配置,生成与数据源对应的文本提取模板,进而,执行信息文本获取子模块4116。
信息文本获取子模块4116可以用于在达到设定时间时,根据所述文本提取模板从所述数据源提取信息文本。
设定时间是指预先设置的用于从热搜榜单提取信息文本的时间。
设定时间可以为预先设置的定时时间,如每天上午十点,或,每隔一天的上午十点等。
设定时间也可以为预先设置的等间隔时间,如每间隔两小时,或者每间隔四小时等。
设定时间还可以为根据数据源的特征,预先设置的不等间隔的时间,例如,数据源在白天的访问量比较大,数据源内的信息更新频率较高,设定时间可以设置为:从早上六点到夜间十二点的时间段内,每隔一个小时;而夜间的访问量较小,信息更新频率比较低,设定时间可以设置为:从夜间十二点至早上六点的时间段内,每隔两个小时。
在达到设定时间时,信息文本获取子模块4116可以采用网络爬虫按照文本提取模板从网页中提取信息文本,例如,承接上述子步骤a2中的示例,配置的模板为:“content\:body\>div\>div\>div\>div\>div\.lemma-summary,title\:body\>div\>div\>a”,可以采用爬虫服务按照这个模板解析网页上的对应html元素结构下的数据,并赋值给content和title两个变量。
可以理解地,上述示例仅是为了更好地理解本公开实施例的技术方案而列举的示例,不作为对本公开实施例的唯一限制。
当然,在具体实现中,信息文本获取子模块4116还可以采用其它方式从数据源的热搜榜单中提取信息文本,具体地,可以根据业务需求而定,本公开实施例对此不加以限制。
在信息文本获取子模块4116从数据源的热搜榜单中提取信息文本之后,执行热搜词获取子模块412。
热搜词获取子模块412可以用于从所述信息文本中,筛选出具有热点属性的热搜词。
热点属性是指热搜词在当前一段时间内的搜索热度和搜索量等较高,且具有提取摘要意义的属性。
热点属性可以反映出从未上过热搜榜单的搜索词,在一个固定周期(如一周或一个月等)内,搜索量突然增加(如在一周内的搜索量超过800次或1000次等),并且进入了热搜榜单,可以将该搜索词在固定周期内的搜索量作为热点属性,则将该搜索词作为热搜词。
热点属性也可以反映出一个曾经出现在热搜榜单上的热搜词,在当前一段时间内的搜索量突然增加,并再次进入了热搜榜单,则可以将该搜索词在当前时间段内的搜索量作为该热搜词的热点属性。
当然,不仅限于此,在具体实现中,还可以筛选出其它形式的具有热点属性的热搜词,具体地,可以根据实际情况而定,本公开实施例对此不加以限制。
本公开实施例通过获取热搜词的摘要信息,可以更好地为用户展示热搜词的摘要信息,以使用户得知热搜词背后的具体信息。
在信息文本提取子模块4116从数据源的热搜榜单中提取出信息文本之后,可以根据提取的信息文本筛选出具有热点属性的热搜词,具体地,可以结合下述具体实现方式进行详细描述。
在本公开的另一种具体实现方式中,如图8所示,所述热搜词获取子模块412包括:分词文本获取子模块4122、过滤文本获取子模块4124、以及热搜词筛选子模块4126。
分词文本获取子模块4122可以用于对所述信息文本进行分词处理,得到多个分词文本;
过滤文本获取子模块4124可以用于对多个所述分词文本进行通用词过滤处理,得到过滤信息文本;以及
热搜词筛选子模块4126可以用于依据所述过滤信息文本,筛选出具有热点属性的热搜词。
在本公开实施例中,分词处理的方式可以为采用预先训练好的分词处理模型,即将信息文本输入至分词处理模型,通过分词处理模型对信息文本进行分词。
分词处理模型是指对信息文本进行分词的模型,分词处理模型的训练过程可以参照步骤:
1、预先获取多个(如800个或1000个等)训练样本,每个训练样本包括信息文本和信息文本对应的初始分词文本;
2、将多个训练样本依次输入初始分词处理模型(即还未进行训练的模型),由初始分词模型输出每个训练样本对应的预测分词文本;
3、根据初始分词文本和预测分词文本,计算得到损失值;
4、在损失值处于预设范围内的情况下,则将初始分词处理模型作为训练后的分词处理模型;
5、在损失值未处于预设范围内的情况下,可以根据预先获取的训练样本再次输入至初始分词处理模型中执行训练过程,直至损失值处于预设范围内。
当然,在执行上述训练的过程中,在每次将一个训练样本输入至初始分词处理模型之后,均执行一次损失值获取,及与预设范围的比较过程,在获取的损失值未处于预设范围内的情况下,则获取下一个训练样本进行训练,依次类推,直至获取的损失值处于预设范围内。
在训练得到分词处理模型之后,分词文本获取子模块4122可以将得到的信息文本输入至分词处理模型,由分词处理模型输出信息文本所对应的多个分词文本。
当然,分词处理的方式还可以为其它分词方式,本公开实施例对此不加以限制。
分词文本是指对信息文本进行分词处理之后,所得到的多个分词对应的文本,例如,信息文本为“米其林轮胎的质量比较好”,在对信息文本进行分词处理之后,得到的分词文本为:“米其林”、“轮胎”、“的”、“质量”、“比较”、“好”等。
可以理解地,上述示例仅是为了更好地理解本公开实施例的技术方案而列举的示例,不作为对本公开实施例的唯一限制。
在由分词文本获取子模块4122对信息文本进行分词处理,从而得到多个分词文本,执行过滤文本获取子模块4124。
通用词过滤是指过滤掉分词文本中的通用词,如语气词“的”、“吗”、“哦”等,也可以是其它类型的词,如感叹词等,具体地,可以根据实际情况而定。
过滤信息文本是指在将多个分词文本中的通用词过滤掉之后,剩余的分词文本即为过滤信息文本。例如,承接上述示例,对信息文本为“米其林轮胎的质量比较好”进行分词之后,得到的多个分词文本为:“米其林”、“轮胎”、“的”、“质量”、“比较”、“好”,过滤掉其中的通用词“的”、“比较”,剩余的分词文本为:“米其林”、“轮胎”、“质量”、“好”,这些剩余的分词文本即为过滤信息文本。
在分词文本获取子模块4122得到信息文本对应的多个分词文本之后,可以由过滤文本获取子模块4124对多个分词文本进行通用词过滤处理,即过滤掉多个分词文本中的通用分词文本,从而得到过滤信息文本。
在过滤文本获取子模块4124对多个分词文本进行通用词过滤处理得到过滤信息文本之后,执行热搜词筛选子模块4126。
在得到的信息文本对应的过滤信息文本之后,热搜词筛选子模块4126可以根据过滤信息文本,筛选出具有热点属性的热搜词,例如,可以从过滤信息文本中提取当前时间出现频率比较高的一个过滤信息文本作为热搜词,具体地,可以参照下述具体实现方式的描述。
在本公开的另一种具体实现方式中,如图9所示,所述热搜词筛选子模块4126包括:目标信息文本获取子模块41262、热搜词确定子模块41264。
目标信息文本获取子模块41262可以用于从所述过滤信息文本中,获取距离当前时间的预设时间段内出现频度大于频度阈值的至少一个目标信息文本;以及
热搜词确定子模块41264可以用于获取所述至少一个目标信息文本对应的热度值,并将热度值为最大的目标信息文本作为热搜词。
在本公开实施例中,目标信息文本是指过滤信息文本中出现频度大于频度阈值的一个或多个过滤信息文本。
当前时间可以是指终端系统当前的时间。
预设时间段是指由业务人员预先设置的与当前时间距离的时间段,预设时间段可以为1天、3天或6天等,具体地,可以根据业务需求而定,本公开实施例对此不加以限制。
频度阈值是指由业务人员预先设置文本出现频度的阈值。
在目标信息文本获取子模块41262获得过滤信息文本之后,可以从过滤信息文本中,获取距离当前时间的预设时间段内出现频度大于频度阈值的至少一个目标信息文本,例如,过滤信息文本包括文本a、文本b、文本c和文本d,频度阈值为0.6,文本a在距离当前时间的预设时间段内出现的频度为0.7,文本出现的频度为0.5,文本c出现的频度为0.8,文本d出现的频度为0.3,则可以将文本a和文本c作为目标信息文本。
可以理解地,上述示例仅是为了更好地理解本公开实施例的技术方案而列举的示例,不作为对本公开实施例的唯一限制。
在目标信息文本获取子模块41262得到至少一个目标信息文本之后,执行热搜词确定子模块41264。
热度值是指信息文本的热度分值,热度值可以是结合距离当前时间的预设时间段内信息文本的搜索量得到的,例如,在一个固定周期内如一周或一个月内从未出上过榜单的搜索词,突然搜索量增加,可以根据搜索量确定该搜索词的热度值。
在具体实现方式中,还可以采用其它方式获取信息文本的热度值,具体地,可以根据业务需求而定,本公开实施例对此不加以限制。
在热搜词确定子模块41264获取至少一个目标信息文本对应的热度值之后,可以将热度值最大的目标信息文本作为热搜词,例如,目标信息文本包括文本1、文本2和文本3,文本1的热度值为0.8,文本2的热度值为0.6,文本3的热度值为0.5,则将文本1作为热搜词;而在文本1和文本2的热度值均为0.7,文本3的热度值为0.5时,则将文本1和文本2作为热搜词。
可以理解地,上述示例仅是为了更好地理解本公开实施例的技术方案而列举的示例,不作为对本公开实施例的唯一限制。
在另一种可实现的示例中,热搜词获取模块410可以对热搜榜单实时监听,从选定的数据源中筛选出具有热点属性的热搜词,具体地,结合下述具体实现方式进行详细描述。
在本公开的另一种具体实现中,如图6所示,所述热搜词获取模块410包括:热搜榜单监听子模块413和热搜词监听子模块414。
热搜榜单监听子模块413可以用于监听数据源中的热搜榜单。
热搜词监听子模块414可以用于从所述数据源的热搜榜单中筛选出具有热点属性的热搜词。
在本公开实施例中,可以在系统中预先设置热搜榜单对应的热搜榜单监听子模块413,通过热搜榜单监听子模块413可以实时对数据源中的热搜榜单进行监听,具体地,可以预先设置监听程序,通过监听程序对热搜榜单中出现的信息内容进行实时监听,以监听到在热搜榜单中出现的搜索词。
在实际应用中,还可以采用其它监听方式,具体地,可以根据业务需求而定,本公开实施例对此不加以限制。
在本公开中,热搜榜单监听子模块413可以对预先选取的具有热搜榜单的数据源中的热搜榜单进行实时监听,以实时监听出现在热搜榜单中的搜索词。
在热搜榜单监听子模块413实时监听到数据源中的热搜榜单中出现的搜索词之后,可以由热搜词监听子模块414采用预先设置的规则而进行判定,以筛选出具有热点属性的热搜词。
预先设置的规则可以是如搜索热度判定、词性过滤、复合词调整等,从而提取出有摘要意义的热搜词,例如,在一个固定周期内如一周或一个月内从未出上过榜单的搜索词,突然搜索量增加,则必然存在一定的热点事件,如某个poi(pointofinterest,兴趣点)被评为米其林或某地新开了某家网红poi,此时就比较需要在榜单上加上辅助的摘要信息进行用户引导。
在由热搜词获取模块410从数据源中筛选出具有热点属性的热搜词之后,执行内容文本获取模块420。
内容文本获取模块420可以用于从所述数据源获取与所述热搜词关联的内容文本。
内容文本是指与热搜词关联的热点事件的信息文本,内容文本可以是如通过热搜词在数据源中搜索到的新闻事件等热点事件,在点击热点事件对应的链接后,可以展示一个详细介绍热搜词关联事件的信息文本,这些信息文本可以作为与热搜词关联的内容文本。
在热搜词获取模块410筛选出具有热点属性的热搜词之后,可以由内容文本获取模块420根据热搜词在数据源中进行搜索,可以得到与热搜词相关的内容文本。
在本公开中,内容文本获取模块420可以采用网络爬虫的方式爬取数据源中与热搜词关联的内容文本,或者,由内容文本获取模块420实时监听数据源中与热搜词关联的ugc(usergeneratedcontent,用户生成内容),即实时监听用户原创的与热搜词关联的内容文本。
在具体实现中,还可以由内容文本获取模块420采用其它方式获取与热搜词关联的内容文本,具体地,可以根据业务需求而定,本公开实施例对此不加以限定。
在内容文本获取模块420从数据源获取与热搜词关联的内容文本之后,执行摘要文本生成模块430。
摘要文本生成模块430可以用于基于所述内容文本,生成与所述热搜词对应的摘要文本。
摘要文本是指用于描述热搜词对应的热点事件的文本信息。
在从数据源中获取与热搜词关联的内容文本之后,可以结合内容文本生成与热搜词对应的摘要文本,具体地,可以将内容文本进行拆分,得到多个句子文本,并将内容文本输入至主题训练模型获取对应的主题词,根据多个句子文本和主题词,生成热搜词对应的摘要文本。
在本公开的一种示例性的实现方式中,可以按照内容文本拆分得到的句子文本和内容文本对应的主题词,生成对应的摘要文本,具体地,结合下述具体实现方式进行详细描述。
在本公开的一种具体实现中,如图10所示,摘要文本生成模块430包括:句子文本获取子模块431、主题词获取子模块432、以及摘要文本生成子模块433。
句子文本获取子模块431可以用于按照句格式对所述内容文本进行拆分,得到与所述内容文本对应的多个句子文本;其中,所述句格式是指按照特殊标点符号拆分文本的格式。
句格式是指按照特殊标点符号拆分文本的格式,特殊标点符号可以为“。”、“?”、“!”等,具体地,可以根据业务需求而定。
句子文本是指在将内容文本按照句格式进行拆分之后,得到的多个文本。
在内容文本获取模块420从数据源获取与热搜词关联的内容文本之后,可以由句子文本获取子模块431按照句格式对内容文本进行拆分,从而可以得到多个句子文本,例如,内容文本为:“根据化石研究,地球上最早出现的动物源于海洋。早期的海洋动物经过漫长的地质时期,逐渐演化出各种分支,丰富了早期的地球生命形态。”,在按照句格式进行拆分之后,得到的句子文本分别为:“根据化石研究,地球上最早出现的动物源于海洋”和“早期的海洋动物经过漫长的地质时期,逐渐演化出各种分支,丰富了早期的地球生命形态”。
可以理解地,上述示例仅是为了更好地理解本公开实施例的技术方案而列举的示例,不作为对本公开实施例的唯一限制。
在句子文本获取子模块431按照句格式对所述内容文本进行拆分,得到与内容文本对应的多个句子文本之后,执行主题词获取子模块432。
主题词获取子模块432可以用于将所述内容文本输入主题训练模型,获取与所述内容文本对应的主题词。
主题训练模型是指用于对文本进行训练得到对应的主题词的模型。
主题训练模型的训练过程可以为:
1、预先获取多个(如800个或1000个等)训练样本,每个训练样本包括内容文本和内容文本对应的初始主题词;
2、将多个训练样本依次输入初始主题训练模型(即还未进行训练的模型),由初始主题训练模型输出每个训练样本所对应的预测主题词;
3、根据初始主题词和预测主题词的相似性,计算得到损失值;
4、在损失值处于预设范围内的情况下,则将初始主题训练模型作为训练后的主题训练模型;
5、在损失值未处于预设范围内的情况下,可以根据预先获取的训练样本再次输入至初始训练模型中执行训练过程,直至损失值处于预设范围内。
当然,在执行上述训练的过程中,在每次将一个训练样本输入至初始主题训练模型之后,均执行一次损失值获取,及与预设范围的比较过程,在获取的损失值未处于预设范围内的情况下,则获取下一个训练样本进行训练,依次类推,直至获取的损失值处于预设范围内。
在训练得到主题训练模型之后,可以由主题词获取子模块432将得到的内容文本输入至主题训练模型,由主题训练模型输出内容文本所对应的主题词。
在本公开实施例中,主题训练模型可以为lda(latentdirichletallocation,文档主题生成模型)或者textrank等主题模型,在具体实现中,业务人员可以根据实际需要选择具体的主题训练模型,本公开实施例对此不加以限制。
在主题词获取子模块432将内容文本输入主题训练模型,获取与内容文本对应的主题词之后,执行摘要文本生成子模块433。
摘要文本生成子模块433可以用于基于与所述内容文本对应的主题词和多个句子文本,生成所述热搜词对应的摘要文本。
在摘要文本生成子模块433得到内容文本对应的主题词和多个句子文本之后,可以对句子文本中语句较长的句子执行分隔、相似语句去重、多次主题提取等步骤,最终得到热搜词对应的摘要文本。
摘要文本可以作为热搜词登上热搜榜单的理由,以为用户提供指引。
在摘要文本生成模块430基于内容文本,生成与热搜词对应的摘要文本之后,执行摘要文本关联展示模块440。
摘要文本关联展示模块440可以用于将所述热搜词和所述摘要文本进行关联及展示。
在摘要文本关联展示模块440得到热搜词对应的摘要文本之后,可以由摘要文本关联展示模块440将热搜词与摘要文本关联存储于缓存中,app(application,应用程序)端可以实时读取缓存中的摘要文本,也可以实时展示于客户端,例如,在用户移动鼠标光标至该热搜词至上时,可以弹出一个透明窗口,在透明窗口中可以展示热搜词关联的摘要文本;或者是,在热搜榜单所处的版块,可以在热搜词的附近位置处,展示与热搜词关联的摘要文本。
在具体实现中,摘要文本关联展示模块440还可以采用其它热搜词和摘要文本的关联展示方式,本公开实施例对此不加以限制。
本公开实施例通过将热搜词和摘要文本关联展示,可以使用户及时得知热搜词背后的具体信息,提高了用户的感知度。
本公开实施例提供的摘要生成装置,除了具备上述实施例三提供的摘要生成装置所具备的有益效果外,还可以实时监听热搜词,及时将挖掘出的摘要信息推送至客户端榜单页面,可以使用户及时了解热搜词关联的具体信息,提高了用户的感知度。
本公开的实施例还提供了一种电子设备,包括:处理器、存储器以及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序时实现前述实施例的摘要生成方法。
本公开的实施例还提供了一种计算机可读存储介质,存储有计算机指令,当所述计算机指令由电子设备的处理器执行时,使得电子设备能够执行前述实施例的摘要生成方法。
对于装置实施例而言,由于其与方法实施例基本相似,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
在此提供的算法和显示不与任何特定计算机、虚拟系统或者其它设备固有相关。各种通用系统也可以与基于在此的示教一起使用。根据上面的描述,构造这类系统所要求的结构是显而易见的。此外,本公开的实施例也不针对任何特定编程语言。应当明白,可以利用各种编程语言实现在此描述的本公开的实施例的内容,并且上面对特定语言所做的描述是为了披露本公开的实施例的最佳实施方式。
在此处所提供的说明书中,说明了大量具体细节。然而,能够理解,本公开的实施例可以在没有这些具体细节的情况下实践。在一些实例中,并未详细示出公知的方法、结构和技术,以便不模糊对本说明书的理解。
类似地,应当理解,为了精简本公开并帮助理解各个发明方面中的一个或多个,在上面对本公开的示例性实施例的描述中,本公开的实施例的各个特征有时被一起分组到单个实施例、图、或者对其的描述中。然而,并不应将该公开的方法解释成反映如下意图:即所要求保护的本公开的实施例要求比在每个权利要求中所明确记载的特征更多的特征。更确切地说,如下面的权利要求书所反映的那样,发明方面在于少于前面公开的单个实施例的所有特征。因此,遵循具体实施方式的权利要求书由此明确地并入该具体实施方式,其中每个权利要求本身都作为本公开的实施例的单独实施例。
本领域那些技术人员可以理解,可以对实施例中的设备中的模块进行自适应性地改变并且把它们设置在与该实施例不同的一个或多个设备中。可以把实施例中的模块或单元或组件组合成一个模块或单元或组件,以及此外可以把它们分成多个子模块或子单元或子组件。除了这样的特征和/或过程或者单元中的至少一些是相互排斥之外,可以采用任何组合对本说明书(包括伴随的权利要求、摘要和附图)中公开的所有特征以及如此公开的任何方法或者设备的所有过程或单元进行组合。除非另外明确陈述,本说明书(包括伴随的权利要求、摘要和附图)中公开的每个特征可以由提供相同、等同或相似目的替代特征来代替。
本公开的实施例的各个部件实施例可以以硬件实现,或者以在一个或者多个处理器上运行的软件模块实现,或者以它们的组合实现。本领域的技术人员应当理解,可以在实践中使用微处理器或者数字信号处理器(dsp)来实现根据本公开的实施例的动态图片的生成设备中的一些或者全部部件的一些或者全部功能。本公开的实施例还可以实现为用于执行这里所描述的方法的一部分或者全部的设备或者装置程序。这样的实现本公开的实施例的程序可以存储在计算机可读介质上,或者可以具有一个或者多个信号的形式。这样的信号可以从因特网网站上下载得到,或者在载体信号上提供,或者以任何其他形式提供。
应该注意的是上述实施例对本公开的实施例进行说明而不是对本公开的实施例进行限制,并且本领域技术人员在不脱离所附权利要求的范围的情况下可设计出替换实施例。在权利要求中,不应将位于括号之间的任何参考符号构造成对权利要求的限制。单词“包含”不排除存在未列在权利要求中的元件或步骤。位于元件之前的单词“一”或“一个”不排除存在多个这样的元件。本公开的实施例可以借助于包括有若干不同元件的硬件以及借助于适当编程的计算机来实现。在列举了若干装置的单元权利要求中,这些装置中的若干个可以是通过同一个硬件项来具体体现。单词第一、第二、以及第三等的使用不表示任何顺序。可将这些单词解释为名称。
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统、装置和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
以上所述仅为本公开的实施例的较佳实施例而已,并不用以限制本公开的实施例,凡在本公开的实施例的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本公开的实施例的保护范围之内。
以上所述,仅为本公开的实施例的具体实施方式,但本公开的实施例的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本公开的实施例揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本公开的实施例的保护范围之内。因此,本公开的实施例的保护范围应以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!