基于节点签名的保留标签信息的异质网络嵌入方法与流程
本发明属于图数据处理的技术领域。
背景技术:
在当今信息时代,数据在各类应用中常以网络图模型进行表示。有效分析图数据中的结构信息和标签信息有助于发现复杂网络数据的内在关系,进而有助于对图数据中隐含的信息加以有效利用,包括但不限于科学搜索、个性化推荐等。随着人工智能技术的发展,机器学习算法为数据分析和预测提供了通用且有效的手段。
由于图数据具有的特性,在原始图上直接进行数据分析是困难的。一方面,图数据传统的以邻接矩阵存储的方式难以直接作为机器学习算法的输入进行数据的分析和预测;另一方面,由于维度高、体量大,图数据分析的计算复杂度高。因此,网络嵌入技术,这种在保留原始图信息、获得良好推断能力的基础上,将高维图数据降维映射到适用于机器学习的低维向量空间的方法,成为图数据处理领域中一个重要的研究方向。
异质网络在同质网络的基础上包含节点和边标签信息,在现实中广泛存在。很多大型应用场景,如社交媒体用户关系、学术研究论文引用关系、电子商务用户兴趣网络、生物基因演化关系等,都可以用异质网络结构来进行表示。这些标签信息直接表明了节点和边在语义上的类型,对于网络中节点和边的相似性具有非常重要的作用。
近些年来,同质网络嵌入方法已经得到较充分的发展,但现有的异质网络嵌入方法在标签信息的保留上仍具有一定的局限性。一方面,现有的主流异质网络嵌入方法利用节点标签引导随机游走,游走规则的选择依赖数据本身的领域先验知识,并且不同游走策略的选择可能生成具有较大差异的结果;另一方面,现有的异质网络嵌入方法基于边标签依赖节点标签的假设,关注的主要是节点标签,缺乏对边标签独立性的考虑,对下游任务准确度造成影响。
为解决上述问题,满足在下游机器学习任务中提升推断准确性的需求,保留异质网络标签信息的网络嵌入技术成为一项具有重要意义的研究问题。
技术实现要素:
本发明的目的是解决现有的异质网络嵌入方法对于网络数据的专业领域知识依赖、随机游走策略选择的依赖和标签信息独立性考虑不足的问题,并满足提升下游机器学习任务准确度的需求,提出一种基于节点签名的保留标签信息的异质网络嵌入方法。本发明通过对图数据不同标签类型的质数表示以及节点邻域签名的计算,将异质网络数据的拓扑结构信息和标签信息分别压缩在节点基础向量和节点的数字签名向量中,保留了网络结构和标签信息,使得到的节点表示能够支持下游的各项推断预测任务。
本发明的技术方案
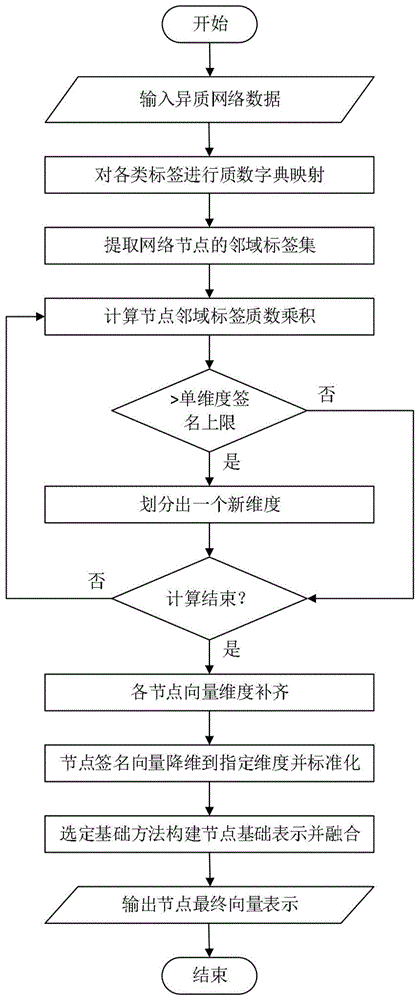
基于节点签名的保留标签信息的异质网络嵌入方法,以数字签名思想为基础,构建出的节点签名向量可以在使用现有同质或异质网络嵌入方法保留图拓扑结构信息的基础上进行普适性地扩展和提升,保留原始图上点和边的标签信息,达到提升下游各项通用机器学习任务的准确度的目的;同时,由于边标签质数的独立指派,使节点向量可以保留独立的边标签信息,提升异质网络嵌入中边标签的灵活度,同时能够适应边标签分类的特殊需求;具体步骤如下:
第1、对网络中所有的标签类型进行质数字典映射
指派标签质数的目的是为了对节点标签和边标签信息进行编码表示。本发明利用质数的特性来区别不同类型的标签信息。一方面,使得边标签可以在不依赖节点标签语义的基础上,保留独立的语义信息;另一方面,使得在保留多个标签信息时能够对标签的内容进行区分。因此,在构建节点签名向量之前,需要针对网络中出现的所有节点标签和边标签类型统一进行质数映射。具体方法如下:
第1.1、确定网络中所有的节点标签和边标签类型
已知给定输入数据图中的节点标签类型总数为nv,边标签类型总数为ne,标签类型可表示为[l1,l2,…,lnv,lnv+1,lnv+2,…,lnv+ne]。对于未知标签类型信息的网络,可以通过对数据进行统计,得出网络中全部的不同标签类型。
第1.2、根据标签类型建立质数映射字典
在确定了网络中的标签类型信息后,将不同类型的标签类型一一对应地映射到生成的自小到大的nv+ne个质数上,采用字典结构f(l)保留标签和质数的映射关系。
第2、提取网络节点的邻域标签集
在建立了标签类型的质数表示后,需要提取不同节点的邻域标签信息。确定节点邻域的目的是为了保留不同节点的邻域标签信息的相似性,具有相似的邻域标签集的节点应当具有相似的语义信息,在网络中距离较近,即表现为具有相似的向量表示。对比传统的异质网络嵌入方法来说,传统方法考虑指定元路径上的标签语义,而元路径需要基于不同网络数据的专业领域知识进行合理的选择,本发明通过提取邻域标签集能对各类网络的标签语义信息进行统一的考虑。因此,在构建节点签名向量之前,需要提取网络中节点的邻域标签集。具体分为两种情况,分别是提取网络节点的直连邻域标签集和提取网络节点的自我中心网络标签集,具体方法如下:
(1)提取网络节点的直连邻域标签集
节点的直连邻域是指,当前节点和与当前节点连接的所有边,以及与当前节点直接相连的所有节点。节点的直连邻域标签集即为节点直连邻域中所有节点和边上的标签信息。针对不同领域的异质网络数据,考虑节点直连邻域中的标签信息包含了与当前节点相关的节点标签语义及其之间关系类型的语义,能够对各类网络语义相似性进行通用的考虑。
第2.1、确定节点的邻域集合
给定输入数据图的边集为e,点集为v,e(i,j)表示节点i与节点j之间的边。当前节点v的直连邻域节点集表示为
v的直连邻域表示为n1(v),则:
第2.2、根据质数映射字典确定节点的邻域标签集合
对得到的节点邻域集合中的每个节点或边x上的标签l(x),根据第1步中得到的质数映射字典f(l)进行节点标签和边标签的质数转化,从而得到直连邻域的标签集合p1(v),则:
p1(v)={p|p=f(l(x)),x∈n1(v)};
(2)提取网络节点的自我中心网络标签集
节点的自我中心网络是指,当前节点、当前节点上所有的边和与当前节点直接相连的所有节点,以及这些节点之间互相连接的边。节点的自我中心网络标签集即为节点自我中心网络中所有节点和边上的标签信息。相比于直连邻域,考虑节点的自我中心网络包含了与当前节点相关的节点标签语义和自我中心网络内所有节点之间的关系类型的语义,能够保存更多的节点邻域标签语义信息。
第2.1、确定节点的邻域集合
给定输入数据图的边集为e,点集为v,e(i,j)表示节点i与节点j之间的边。当前节点v的邻域节点集表示为
v的自我中心网络表示为n2(v),则:
第2.2、根据质数映射字典确定节点的邻域标签集合
对得到的节点邻域集合中的每个节点或边x上的标签l(x),根据第1步中得到的质数映射字典f(l)进行节点标签和边标签的质数转化,从而得到节点的自我中心网络的标签集合p2(v),则:
p2(v)={p|p=f(l(x)),x∈n2(v)};
第3、构建节点签名向量
在得到节点邻域标签集后,本发明利用数字签名的思想,将标签信息的保留与拓扑结构的保留分离考虑,构建节点的签名向量,在签名向量中保留使用质数表示的网络中节点和边的标签信息,从而达到对现有异质图上网络嵌入方法进行通用性扩展的目的。
第3.1、根据节点的邻域标签集计算节点签名
基于第2步中得到的节点邻域标签集p1(v)或p2(v),在此统一表示成p(v),本发明采用质数乘积的方式计算节点的邻域签名。对当前节点v的邻域标签集中的所有标签的质数表示进行累乘,得到包含多标签乘积的签名s,即:
s=πp∈p(v)p;
第3.2、根据单维签名上限对溢出部分进行维度划分
对于现有的异质网络数据规模,节点的邻域标签集信息可能较多,从而在计算签名时,质数乘积较大。由于计算机处理中整型变量的大小约束,节点签名需要使用多个整数进行表示。
本发明采用维度划分的方式,将节点签名整数转化为多维度的向量表示。在维度划分的过程中,需要保留标签信息的完整,即以单个标签质数为元进行拆分。根据给定的单维度签名上限值smax,以质数为单元,在当前维度的签名超过smax时,增加新的一个维度,将超出上限的部分拆分到新的签名维度中,当前维度保留最后一次不超过上限的签名计算结果。
第3.3、根据最长维度对多维节点签名进行维度补齐
在完成维度划分后得到的多维节点签名结果长度不一,需要进一步通过向右补零的方式,将维度不足的向量补齐至多维节点签名中的最长维度。
第3.4、根据签名维度要求进行签名向量降维
在补齐签名维度得到长度一致的签名向量后,需要进一步将高维度的节点签名向量降维到模型指定的签名向量空间中。给定节点表示的总维度为n,节点签名向量占比为α,节点签名向量维度i满足:
本发明采用主成成分分析法,选取计算得到的节点签名向量中差异最大的i维作为降维后的节点签名向量。
第3.5、对降维后的签名向量进行标准化处理
在完成节点签名向量的降维后,本发明需要进一步对降维后的节点签名向量进行标准化处理,得到节点签名向量(x1,x2,…,xi),使得节点签名向量能够与现有方法生成的基础向量融合。
第4、根据维度要求和选定基础方法构建网络节点最终向量表示
在得到节点签名向量后,需要根据选定的一种基础网络嵌入方法生成节点的基础向量保留异质网络中的拓扑结构信息。对比选定的网络嵌入方法,异质网络嵌入需要保留更多、更灵活的标签信息,又不能丢失其拓扑结构相似性。为了实现这个目的,本发明根据节点表示的维度要求,融合两部分向量构建最终的网络节点表示。具体步骤如下:
第4.1、根据节点表示的总维度和签名占比要求生成指定维度的节点基础向量
给定节点表示的总维度为n,节点签名向量占比为α,节点基础向量维度j满足:
选用现有的任意一种能够保留网络图拓扑结构信息的同质网络或异质网络嵌入方法,如基于元路径引导随机游走的方法,使用该方法得到j维的节点基础向量(y1,y2,…,yj)。
第4.2、融合基础向量和签名向量构建网络节点最终向量表示
将第3步中得到的节点签名向量(x1,x2,…,xi)拼接在节点基础向量(y1,y2,…,yj)之后,得到节点的最终向量表示(y1,y2,…,yj,x1,x2,…,xi)。
本发明的优点和积极效果:
本发明开创性地提出了通过计算节点数字签名来保留异质网络标签信息的方法,能够在不依赖专业领域知识和随机游走策略选择的情况下,针对任意现有同质或异质网络嵌入方法进行普适性地扩展和提升。相比现有的网络嵌入方法,本发明能够在保留网络中拓扑结构信息的基础上,更灵活地保留网络中的标签语义信息,从而有效提升了下游各项机器学习任务的准确度。特别地,本发明通过对边标签质数的独立指派,使节点向量可以保留独立的边标签信息,提升异质网络嵌入中边标签的灵活度,同时能够进一步适应边标签分类的特殊需求。
附图说明
图1为异质网络嵌入技术过程示意图。
图2为电话通信网络图。
图3为节点直连邻域示意图。
图4为基于节点直连邻域的节点签名向量生成过程示意图。
图5为构建网络最终节点向量表示的过程示意图。
图6为节点自我中心网络示意图。
图7为基于节点自我中心网络的节点签名向量生成过程示意图。
具体实施方式
本发明提出了一种基于节点签名的保留标签信息的异质网络嵌入方法,方法的主要过程如图1所示。下面将以如图2所示的异质网络为例,说明本发明的具体实施方式。
实施例1:基于节点直连邻域的保留标签信息的异质网络嵌入方法
一、对网络中所有的标签类型进行质数字典映射
我们对如图2所示的异质网络,按照本发明的方法进行质数字典映射。图2选自一部分电话通信网络图。原图中节点标签包括核心用户和边缘用户两种标签,边标签包括短时通话和长时通话两种标签。核心用户以lc表示,边缘用户以lp表示,长时通话以ll表示,短时通话以ls表示。
因此,将标签类型一一对应地映射到自小到大的4个质数上,即{2,3,5,7}。将对应关系以标签类型作为索引,以字典形式存储。假设如图4所示lc、lp、ll、ls四个标签分别依次映射到{2,3,5,7},例如,查询索引“lp”得到类型质数为3。
二、提取网络节点的直连邻域标签集
对当前节点v0提取其直连邻域,如图3所示,图中实线部分为节点v0的直连邻域,包括v0和与v0直接相连的边{e1,e2,e3,e4},以及与v0直接相连的节点{v1,v2,v3,v4},得到v0的直连邻域为{v0,v1,v2,v3,v4,e1,e2,e3,e4}。检查领域中节点和边上的标签,得到直连邻域上的标签包括[lc,lp,lc,lc,lp,ll,ls,ls,ls]。根据上一步得到的质数映射字典,可以得到网络节点的直连邻域标签集对应为[2,3,2,2,3,5,7,7,7],如图4所示。
三、构建节点签名向量
基于上一步得到的节点邻域标签,对邻域标签集中所有的标签质数进行累乘,计算节点v0的邻域签名整数即为:s=2×3×2×2×3×5×7×7×7=123480。在具有更大邻域的节点上,节点的邻域签名较大,需要将单维度的整数拆分成多个维度的向量表示。
假设给定的单维度签名上限值smax=10000。由于s=123480>10000,需要对s进行以质数为单元的维度拆分。在s的计算过程中s7=2×3×2×2×3×5×7=2520<10000<s8=s7×7=17640,如图4所示,在s7处将签名进行分割,将超出单维签名上限的部分拆分到新的签名维度中。超出部分为
网络中各个节点具有不同的邻域标签信息,如图4所示,经过上述步骤得到一组长度不一的多维节点签名。假设节点签名中最长的维度为dmax>2,以节点v0为例,将v0的签名向量填补0,使得维度扩充到dmax,即(2520,49,0,…,0)。
对经过维度对齐的签名向量组采用主成成分分析的方法降维到指定的维度,之后对降维得到的签名向量进行标准化。假设节点总维度n要求为4,节点签名占比α为0.3,则各个节点的签名向量经过处理后降维到i维度,其中,
四、根据维度要求和选定基础方法构建网络节点最终向量表示
在现有的任意能够保留网络拓扑结构信息的嵌入方法中选取一种作为选定的基础方法,例如同质网络嵌入的node2vec方法、异质网络嵌入的metapath2vec方法等,指定其生成的节点向量表示维度
五、提升下游图分析任务准确度
具体实验中采用了四个不同的真实数据集,分别为网站中提供的数据集phone(http://crawdad.org/mit/reality/20050701/)和数据集enron(http://www.ahschulz.de/enron-email-data/)、论文(yuxiaodong,niteshv.chawla,andananthramswami.metapath2vec:scalablerepresentationlearningforheterogeneousnetworks.kdd,2017.)中使用的数据集dbis、论文(ranahussein,dingqiyang,andphilippecudre-mauroux.aremeta-pathsnecessary?revisitingheterogeneousgraphembeddings.cikm,2018.)中使用的数据集foursquare。实验中选取的基础方法分别为node2vec、metapath2vec和just三种网络嵌入方法,并在相同的节点向量表示维度的基础上进行了对比实验,节点最终向量表示的总维度n均设置为100,节点签名占比α在[0,0.3]中调节,比较增加签名技术前后,节点的向量表示在下游的节点分类、节点聚类任务中的准确度,以macro-f1和micro-f1衡量节点分类效果,以nmi衡量节点聚类效果。
以foursquare数据集为例,节点最终向量表示的总维度n均设置为100,节点签名占比α为0.1。在增加签名技术后,签名占用维度为10,拓扑结构占用维度为90。实验效果如下表所示,表中sig表示基于节点直连邻域的构建节点签名向量的方法。由表中数据可知,节点聚类任务nmi提升12~17倍,节点分类任务macro-f1提升0.9~1.8倍、micro-f1提升13%~26%。
在上述实验设置中,节点最终向量表示的生成时间包括节点基础向量和节点签名向量两部分的生成时间。实验分别统计了上述两部分的生成时间,其中节点签名向量生成时间仅占总时间的0.09~0.15。因此,本发明提出的基于节点直连邻域的保留标签信息的异质网络嵌入方法能够在不增加大量额外开销的基础上,对下游图分析任务的准确度进行提升。
六、支持边标签分类任务
根据学习到的节点向量表示,将边的两个端点的向量表示进行拼接,得到边的向量表示。由于在节点签名中充分考虑了边标签的作用,节点签名向量能够反映边标签的相似性,具有相同标签的边将能够拥有相近的向量表示。因此,在边标签的分类任务中能达到较高的预测准确度。根据第五步中的实验设置,边标签分类任务准确度以macro-f1和micro-f1衡量,实验效果如下表所示,可知macro-f1提升24%~70%、micro-f1提升13%~56%。
实施例2:基于节点自我中心网络的保留标签信息的异质网络嵌入方法
一、对网络中所有的标签类型进行质数字典映射
我们对如图2所示的异质网络,按照本发明的方法进行质数字典映射。图2选自一部分电话通信网络图。原图中核心用户、边缘用户、长时通话、短时通话四种标签分别以lc、lp、ll、ls表示。将标签类型一一对应地映射到自小到大的四个质数{2,3,5,7}上,假设如图4所示,lc、lp、ll、ls四个标签分别依次映射到{2,3,5,7}。对应关系以标签类型作为索引,以字典形式存储。
二、提取网络节点的自我中心网络标签集
对当前节点v0提取其自我中心网络,如图6所示,图中实线部分为节点v0的自我中心网络,包括v0和与v0直接相连的边{e1,e2,e3,e4},以及与v0直接相连的节点{v1,v2,v3,v4},以及v0直连节点集合中各个节点之间的边{e5,e6},得到v0的自我中心网络为{v0,v1,v2,v3,v4,e1,e2,e3,e4,e5,e6}。检查领域中节点和边上的标签,得到自我中心网络上的标签包括[lc,lp,lc,lc,lp,ll,ls,ls,ls,ll,ll]。根据上一步得到的质数映射字典,如图7,可以得到网络节点的自我中心网络标签集对应为[2,3,2,2,3,5,7,7,7,5,5]。
三、构建节点签名向量
对上一步得到的邻域标签集中所有的标签质数进行累乘,计算节点v0的邻域签名整数即为:s=2×3×2×2×3×5×7×7×7×5×5=3087000。
假设给定的单维度签名上限值smax=10000。如图7所示,在s的计算过程中s7=2×3×2×2×3×5×7=2520<10000<s8=s7×7=17640,在s7处将签名进行分割,将超出单维签名上限的部分拆分到新的签名维度中。超出部分为
假设节点签名中最长的维度为dmax>2,以节点v0为例,将v0的签名向量填补0,使得维度扩充到dmax,即(2520,1225,0,…,0)。
对经过维度对齐的签名向量组采用主成成分分析的方法降维到指定的维度,之后对降维得到的签名向量进行标准化。假设节点总维度n要求为7,节点签名占比α为0.3,则各个节点的签名向量经过处理后降维到i维度,其中,
四、根据维度要求和选定基础方法构建网络节点最终向量表示
任意选取一种现有的网络嵌入方法作为选定的基础方法,用来保留图的拓扑结构信息,例如同质网络嵌入的node2vec方法、异质网络嵌入的metapath2vec方法等,指定其生成的节点向量表示维度
五、提升下游图分析任务准确度
具体实验采用与实施例1相同的实验设置,包括使用的四个真实数据集、三种基础方法,节点最终向量表示的总维度n=100和节点签名占比α的取值范围为[0,0.3]。在总维度相同的情况下,分别进行对比实验,比较增加签名技术前后,节点的向量表示在下游的节点分类、节点聚类任务中的准确度,以macro-f1和micro-f1衡量节点分类效果,以nmi衡量节点聚类效果。
以dbis数据集为例,总维度n均设置为100,节点签名占比α为0.1。在增加签名技术后,签名占用维度为10,拓扑结构占用维度为90。实验效果如下表所示,表中ego表示基于节点自我中心网络的构建节点签名向量的方法。由表中数据可知,节点聚类任务nmi可提升8~25倍,节点分类任务macro-f1可提升0.87~1.02倍、micro-f1可提升17%~28%。
在上述实验设置中,节点最终向量表示的生成时间包括节点基础向量和节点签名向量两部分的生成时间。实验分别统计了上述两部分的生成时间,其中节点签名向量生成时间仅占总时间的0.05~0.15。因此,本发明提出的基于节点自我中心网络的保留标签信息的异质网络嵌入方法能够在不增加大量额外开销的基础上,对下游图分析任务的准确度进行提升。
六、支持边标签分类任务
边的向量表示由边的两个端点的向量表示进行拼接得到。对边的向量表示按边标签进行分类,能够获得较高的预测准确度。根据第五步中的实验设置,边标签分类任务准确度以macro-f1和micro-f1衡量,实验效果如下表所示,可知macro-f1提升9%~112%、micro-f1提升7%~42%。
- 还没有人留言评论。精彩留言会获得点赞!