面向分级读物的多尺度难度向量分类方法与流程
本发明涉及自然语言处理中的明确性分析
技术领域:
,具体涉及一种面向分级读物的多尺度难度向量分类方法。
背景技术:
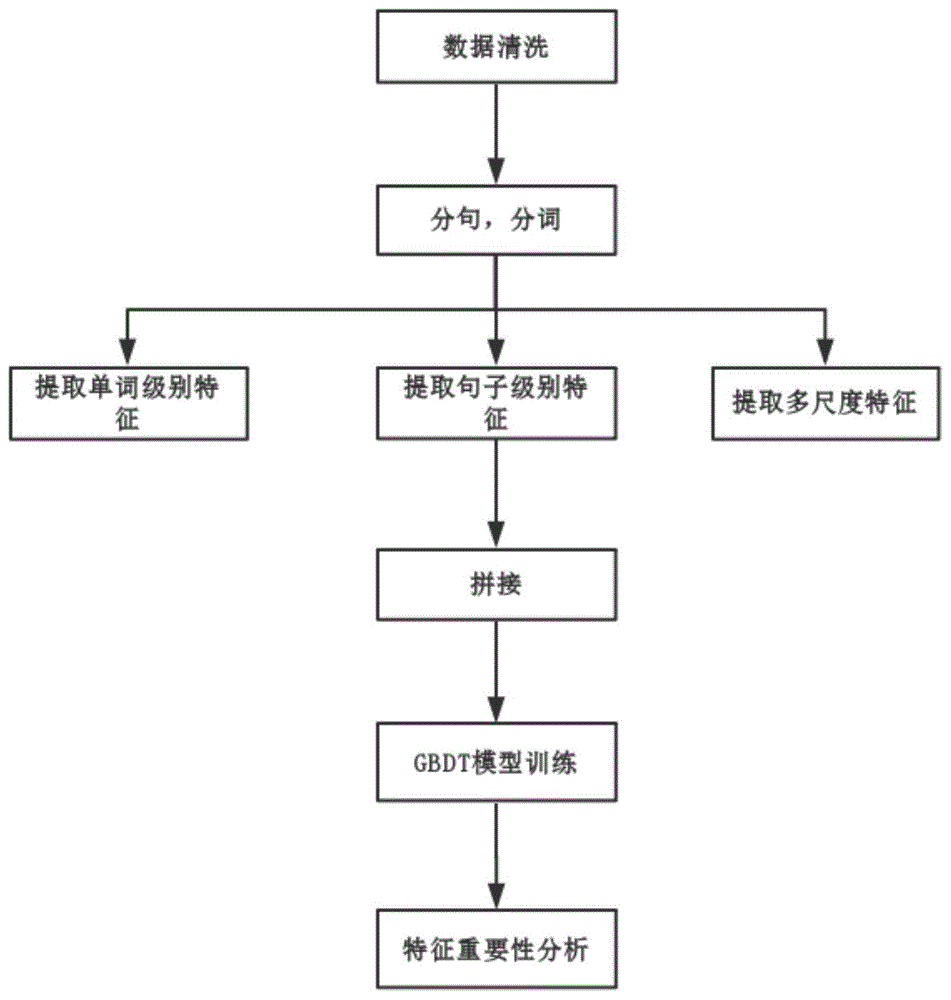
:难度向量分类的任务是,给定一篇文本,通过对文本进行分析,给出该文本的难度值或判断该文本适合哪一水平的读者。应用在教育领域,可以为分级语料和课本素材的选取提供参考依据,对句子的理解难度、复杂性有定量的度量。在通用文本领域如新闻文本,也可对新闻阅读难度、专业性做分析。本难度向量可对文本的理解难度、复杂性做一个较为准确的度量,为句子简化和提炼提供重要的依据,同时也为教育领域分级语料的挑选提供参考。在如今自然语言处理的不断发展下,句子难度分析也有着重要的实践和应用价值。在难度向量的特征提取方面,国内外使用的模型任务可分为基于可读性公式、基于分类、基于排序的方法。可读性公式综合特定文本因素输出文本难度分数,目前主要作为机器学习分类的特征之一。基于分类与排序的方法所使用的特征,主要可分为词汇特征与句法特征。在文献“annielouisandaninenkova,“automaticidentificationofgeneralandspecificsentencesbyleveragingdiscourseannotations.”,inproceedingsofinternationaljointconferenceonnaturallanguageprocessing(ijcnlp).pp.605–613,2011”中,louis等人首先提出了句子明确性分类问题,考虑了句子长度,词语极性,词性等基础特征应用在wsj新闻语料库分类上。在文献“jorgealbertowagnerfilho,rodrigowilkensandalinevillavicencio.“automaticconstructionoflargereadabilitycorpora”,inproceedingsoftheworkshoponcomputationallinguisticsforlinguisticcomplexity(cl4lc).pp.164–173,2016”中,junyijessyli等人在原先基础上通过引入词聚类,tf-idf数值为出现次数较少的单词提供了更多信息,提升了泛化性,并使用半监督方法扩充了语料,开源了speciteller项目。jorge等人扩充了难度特征个数达到89个,包括词语音节数、句法树等其他语言学特征。这些词语特征反映了词语的复杂程度,句法特征反映了句法使用的复杂程度。在构造完句子的特征表示后,使用机器学习分类器如决策树、神经网络等进行分类。在已有的中文专利方面“范舟,白彬,袁敦龙,钱登胜,余夏婷,陈遥.一种评估文本难度的方法[p].中国发明专利,cn105068993a,2015-11-18”中,范舟等人结合统计学原理和中文汉字特点进行了文本难度评估,但其所使用的可读性公式只包含统计特征的线性和对数值的组合,缺乏对文本语义的挖掘,而本专利的研究过程中,发明人在统计语言学特征的基础上融入了句子结构、语义、句义等的多尺度语义的难度衡量信息,解决了教育分级读物和新闻文本分类的需求。目前该领域存在的问题是,为了获得丰富的句子特征,构造特征、模型学习需要花费较多的时间,使用的特征大多局限于词汇与句法级别,对句子信息的提取不够全面。技术实现要素:本发明的目的是为了解决现有技术中的上述缺陷,提供一种面向分级读物的多尺度难度向量分类方法,该分类方法首先构造词语搭配特征、上下文特征、主题特征等丰富了特征表示,结合之前研究中效果最突出的特征,获得一个轻量、全面的句子难度向量,再输入到分类器如梯度提升树(gbdt)中,可以在教育分级读物语料、通用语料上达到很好的效果。与现有技术相比,本发明侧重于提取轻量、全面的句子难度向量,使用机器学习方法拟合已有的分类数据,从而具有更好的泛化性和准确性,且对于不同语言均适用。本发明的目的可以通过采取如下技术方案达到:一种面向分级读物的多尺度难度向量分类方法,该方法包括以下步骤:s1、预先对webhtml文本格式的原始文本数据进行清洗,再进行分句,分类每一个样本;s2、将文本切分为句子s=(s1,s2,…st)(t为分句后的句子数量),每个句子切分为词w=(w1,w2,…ws)(s为每个句子的词语数量);s3、将文本句子输入到特征提取器m1中,特征提取器m1提取先前研究提出的特征中15个效果上最为显著的基础词法特征和句法特征(词频(出现频次)、音节数(发音时的音节数)、单词字符个数、词极性(情感词典分数)、idf值(逆文档概率)、词向量(word2vec向量)、词聚类(词向量的聚类标签)、单词含义个数、句子长度、特殊符号个数(标点、数字等)、停用词个数、句子中特性词个数(名词、形容词、动词、连词)),将以上基础特征中的词法特征求和并用句子长度做归一化得到词法向量ew,与以上基础特征中的句法特征es拼接,得到每个句子的基础特征表示为特征向量,上标为向量维度;s4、将文本句子输入到特征提取器m2中,特征提取器m2提取本专利新提出来的6个特征:句子困惑度(度量一个概率分布或概率模型预测样本的好坏程度)、句子主题类型(通过主题模型隐含狄利克雷分布获得)、词语学会年龄(人学会该单词的平均年龄)、句法树宽度(依存句法分析树的宽度)、前后句子相似度(前后句词向量的余弦相似度)、前后句子使用词汇的重叠度,将以上的词法特征求和并用句子长度做归一化得到词法向量ew,与句法特征es拼接,得到每个句子的多尺度特征表示s5、将句子的基础特征表示和多尺度特征表示拼接起来,获得句子最终的特征表示s6、将特征表示输入梯度提升树(gbdt)(梯度提升树是用于回归和分类问题的机器学习技术,其以弱预测模型(通常是决策树)的集合的形式产生预测模型)中,根据模型输出结果和训练数据真实结果训练模型,利用训练好的模型在测试数据上得到最终结果的准确率accuracy值,并计算特征重要性排序。进一步地,所述的步骤s3中,将句子中每个词的词法特征求和并用句子长度做归一化得到词法向量ew的过程如下:遍历每一个单词,获取每一个单词的以下信息:词频(出现频次)、音节数(发音时的音节数)、单词字符个数、词极性(情感词典分数)、idf值(逆文档概率)、词向量(word2vec向量)、词聚类(词向量的聚类标签)、单词含义个数,将以上信息求和并用句子长度做归一化得到词法向量ew。进一步地,所述的步骤s3中,句法特征es的获取过程如下:遍历每一个句子,统计以下信息:句子长度、特殊符号个数(标点、数字等)、停用词个数、句子中特性词个数(名词、形容词、动词、连词),获得句法特征es。进一步地,所述的步骤s3中,部分特征(词频(出现频次)、单词字符个数、词极性(情感词典分数)、idf值(逆文档概率)、词聚类(词向量的聚类标签)、特殊符号个数(标点、数字等)、停用词个数))使用工具speciteller获取,单词相关特征单词含义个数、单词音节数使用nltk库获取,句法相关特征句子中特性词个数使用spacy包获取。进一步地,所述的步骤s4中,使用在英国国家语料库(britishnationalcorpus)上预训练的srilm工具(语言模型训练工具)产生每个句子的句子困惑度,衡量每一个n-gram窗口(句子中连续的n个单词)搭配在语言模型中的困惑程度。困惑度体现了词语搭配的好坏程度。遍历每一个单词,通过外部词典获取词语学会年龄,求和并用句子长度做归一化得到词法向量ew。词语学会年龄体现为越晚学会的单词会相对复杂。遍历每一个句子,统计以下信息:词语学会年龄(人学会该单词的平均年龄,通过外部词典获得)、句子困惑度(n-gram窗口搭配的好坏程度,通过srilm工具获得)、句法树宽度(构建的依存句法分析树的宽度,通过spacy包获得)、前后句子相似度(词向量余弦相似度)、前后句子使用词汇的重叠度、句子主题模型(通过隐含狄利克雷分布获得),获得句法特征es。其中句法树宽度体现了句法结构的复杂程度。前后句子相似度和前后句子用词重叠度是引入了上下文信息。句子主题模型体现在若语料库中包含不同话题和风格的文章会影响难度向量,如louis等人曾提到新闻类文章总体为写得更加笼统,难度相对简单。进一步地,所述的步骤s5中,句子的基础特征表示和多尺度特征表示通过同时遍历句子、遍历单词获得。进一步地,所述的步骤s6中,将向量输入到分类器梯度提升树(gbdt)中,训练模型后获取准确率,并且计算每个特征对节点分裂的收益,节点分裂时收益越大,该节点对应的特征的重要度越高。通过计算特征重要性排序,可以获得每个难度特征对模型的重要程度,也可以根据语料情况进行动态调整。本发明相对于现有技术具有如下的优点及效果:本发明公开的面向分级读物的多尺度难度向量分类方法,简化了特征表示,只需要21个向量就能体现句子难度,引入了多尺度特征丰富了难度特征表示,增强了模型泛化性;结合新使用的上下文信息构建了对句子级别和文章级别都适用的难度向量表示系统,在句子级别和文章级别的两个数据集都获得了较好的效果;分类器使用梯度提升树,训练速度快,可以获得特征重要性排序。附图说明图1是本发明公开的面向分级读物的多尺度难度向量分类方法的流程图;图2是本发明公开的面向分级读物的多尺度难度向量分类方法的概要图;图3是特征重要性示意图。具体实施方式为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。实施例图1是本发明的流程图,如图1所示,本实施例公开的一种面向分级读物的多尺度难度向量分类方法包括以下步骤:数据清洗、分句,分词、提取单词级别特征,提取句子级别特征,提取多尺度特征、拼接、gbdt模型训练、特征重要性分析,具体如下:t1、预先对webhtml文本格式的原始文本数据进行清洗,再进行分句,分类每一个样本。中文语句可以用jieba工具进行分词,但不限于此。在这里以英文数据为例,如图2下方分句与分词层的句子缩写“anditwas...said”所示将句子“<p>‘anditwasonly10rublesforallthis,’shesaid.‘i'mtakingitbackforthegirlsatthefactorytotry.’<p>”去除html标签后切分为两个句子“‘anditwasonly10rublesforallthis,’shesaid.”和“i'mtakingitbackforthegirlsatthefactorytotry.”,句子内再进行分词,如第一句可分为该句的词语列表:[and,it,was,only,10,rubles,for,all,this,she,said],对应图2下方分句与分词层,每一个矩形表示每一个词语。t2、遍历句子s=(s1,s2,…st)中的每个单词w=(w1,w2,…wt),获取基础特征和多尺度特征中单词级别的属性。以第一句“‘anditwasonly10rublesforallthis,’shesaid.”为例,其中部分特征使用工具speciteller获取,该句的复杂度得分是0.11(0到1),单词相关特征使用nltk库获取,如词频累计值为4.00,单词平均含义数为3.91,单词平均音节数为1.00,获取单词级别属性ew[0.11,4.00,3.91,1.00...],对应图2特征提取层左侧词法特征矩形和右侧多尺度特征矩形的一部分。t3、遍历样本中的每个句子s=(s1,s2,…st),获取基础特征和多尺度特征中词语搭配级别、句子级别、主题级别的属性。以新提出的特征为例:通过srilm工具产生示例句子的句子困惑度为85,主题模型超参数主题个数为3的情况下产生的主题向量为[0.08,0.82,0.08],句法树宽度为0.45,前后句子词汇重叠度为2,前后句子词向量的余弦相似度为0.93,由此获得句法特征es,对应图2特征提取层中间的句法特征矩形和右侧多尺度特征矩形除词语多尺度特征外的剩余部分。t4、将词法特征ew和句法特征es拼接起来,得到难度向量对应图2拼接层中连接起来的特征矩形。表1.wsj+ap+nyt新闻语料中句子明确性分类的准确率作者+难度特征数(个)准确率(%)louis+25个77.40jessy+10-20个,引入半监督信息81.58本专利+21个87.15表2.wikibooks语料中文章明确性分类的准确率作者+难度特征数(个)准确率(%)jorge+89个75.00本专利+21个81.48表3.wsj+ap+nyt新闻语料多尺度消融实验难度特征准确率(%)本专利提出的模型87.15去掉词语学会年龄特征86.03去掉句法树宽度特征86.15去掉句子困惑度特征86.59去掉主题模型特征87.15表4.wikibooks语料多尺度消融实验t5、将难度向量和难度标签输入梯度提升树(gbdt)中训练,获取最佳模型,计算模型在测试集上分类准确率,对应图2中模型训练与分类层中的gbdt分类器。在本具体实施方式中选取的语料库,分类任务为区分句子为general(通用性文本)或specific(包含较难理解的信息),所使用的训练语料为wsj+ap+nyt新闻语料句子明确性分类和wikibooks语料文章明确性分类。在表1中,在句子明确性分类任务中本专利使用21个难度特征在训练后的准确率达到了87.15%,超过了现有的技术。在表2中,在文章明确性分类任务中本专利使用21个难度特征在训练后的准确率达到了87.15%,同样得到了最佳结果81.48%,可见本专利提出的方法能较好地提取句子难度和文章难度。表3和表4为明确性分类任务的多尺度消融实验,在本专利模型的基础上去掉不同多尺度特征,准确率都有不同程度的下降,说明本专利新提出的多尺度特征对准确率都有一定的贡献。上述例句“<p>‘anditwasonly10rublesforallthis,’shesaid.‘i'mtakingitbackforthegirlsatthefactorytotry.’<p>”的分类标签为general,即难度较低,可作为较低年级的分类读物选择。而例句“<p>thousandsofqueue-hardenedsovietsonwednesdaycheerfullylineduptogetatasteof‘gamburgers’,‘chizburgers’and‘filay-o-feesh’sandwichesasmcdonald'sopenedinthelandofleninforthefirsttime.<p>”的分类标签为specific,即理解难度较高,可作为较高年级的分类读物选择。t6、计算特征重要性排序,可以获得每个难度特征对模型的重要程度,也可以根据语料情况进行动态调整。以上述语料集为例,重要的特征包括speciteller工具输出得分、词语频次、句子长度、词语平均音节数等。综上所述,本实施例提出的多尺度难度向量提取方法先构造了词语搭配特征,上下文特征,主题特征等丰富了特征表示,结合之前研究中效果最突出的特征,获得一个轻量、全面的句子难度向量,再输入到分类器如梯度提升树(gbdt)中,可以在教育分级读物语料、通用语料上达到很好的效果。上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1