一种基于高可配可变更的数据处理方法与流程
本发明涉及大数据技术领域,特别涉及一种基于高可配可变更的数据处理方法。
背景技术:
随着互联网发展,云计算,物联网,大数据不断的融入我们的生活,现如今已经有越来越多的行业和技术领域需求大数据分析系统,例如金融行业需要使用大数据系统结合var(valueatrisk)或者机器学习方案进行信贷风控,零售、餐饮行业需要大数据系统实现辅助销售决策,各种iot场景需要大数据系统持续聚合和分析时序数据,各大科技公司需要建立大数据分析中台等等。
抽象来看,支撑这些场景需求的分析系统,面临大致相同的技术挑战:
1、业务分析的数据范围横跨实时数据和历史数据,既需要低延迟的实时数据分析,也需要对pb级的历史数据进行探索性的数据分析;
2、可靠性和可扩展性问题,用户可能会需要存储多个位置的历史数据,同时数据规模有持续增长的趋势,需要引入多位置存储系统来满足可靠性和可扩展性需求;
3、技术栈深,需要组合流式组件、存储系统、计算组件和调度管理;
4、可运维性要求高,复杂的大数据架构难以维护和管控。
技术实现要素:
本发明的目的旨在至少解决所述技术缺陷之一。
为此,本发明的目的在于提出一种基于高可配可变更的数据处理方法。
为了实现上述目的,本发明的实施例提供一种基于高可配可变更的数据处理方法,包括如下步骤:
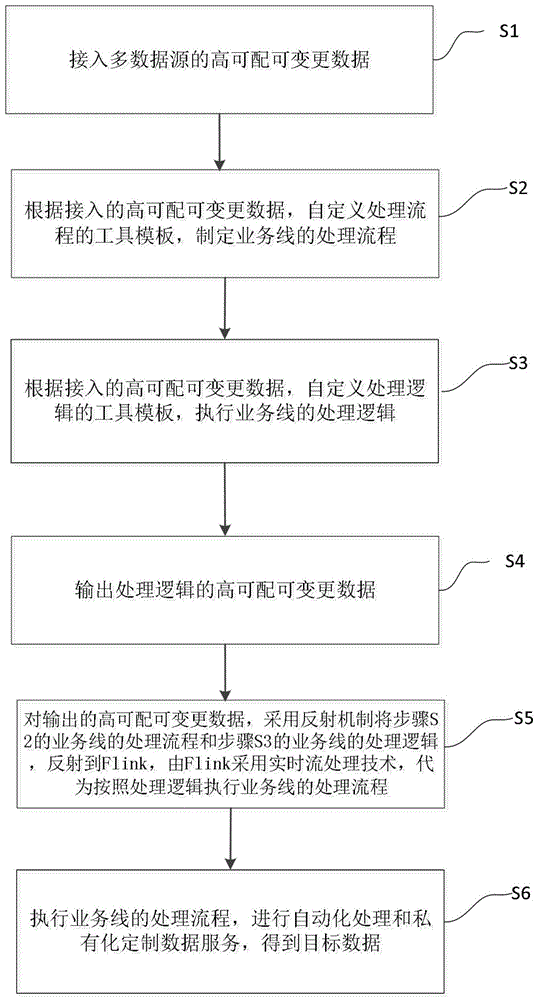
步骤s1,接入多数据源的高可配可变更数据;
步骤s2,根据接入的高可配可变更数据,自定义处理流程的工具模板,制定业务线的处理流程;
步骤s3,根据接入的高可配可变更数据,自定义处理逻辑的工具模板,执行业务线的处理逻辑;
步骤s4,输出处理逻辑的高可配可变更数据;
步骤s5,对输出的高可配可变更数据,采用反射机制将步骤s2的业务线的处理流程和步骤s3的业务线的处理逻辑,反射到flink,由flink采用实时流处理技术,代为按照处理逻辑执行业务线的处理流程;
步骤s6,执行业务线的处理流程,进行自动化处理和私有化定制数据服务,得到目标数据。
进一步,在所述步骤s2和步骤s3中,采用java技术自定义处理流程的工具模板和处理逻辑的工具模板。
进一步,在所述步骤s1中,依次采用工厂模式和抽象模式对高可配可变更数据进行处理,以进行多个等级数据的处理,实现高可配可可变更多数据源的数据接入。
进一步,在所述步骤s3中,在基于已定义的数据处理逻辑的基础上,进一步增加制定针对多数据源的不同处理逻辑,包括但不限于文本、图片、视频、指纹的数据类型。
进一步,在所述步骤s4中,对不同数据输出位置采用不同的数据处理逻辑,包括但不限于关系型数据库、非关系型数据库和文件存储系统。
进一步,(1)对objcet进行基础配置;
(2)对接数据请求方数据;
(3)flink通过广播实现对数据请求方数据的具体消费;
(4)object对自定义接口实现配置输入输出;
(5)通过执行器反射技术完成对业务class类方法的加载;
(6)执行器获取object基础配置和对业务class类方法的加载,远程实现实例化接口对象;
(7)自定义接口对目标数据实现具体接口逻辑。
根据本发明实施例的基于高可配可变更的数据处理方法,实现有效过滤垃圾数据以及在各系统间实时的采集,处理,存储等数据之间的互动,为各类数据、数据源已经存储位置提供高效稳定的数据支持与服务。本可以实现对多模块自定义,可移动,多配置等特点,且模块之间可随意移动,增加操作的便捷性和简单性,而不影响业务。
本发明实施例的基于高可配可变更的数据处理方法,具有以下有益效果:
(1)在解决业务分析的数据范围横跨实时数据和历史数据,既需要低延迟的实时数据分析,也需要对pb级的历史数据进行探索性的数据分析。针对这一问题,本发明解决的方法是通过在执行模块中运用flink实时流处理技术,即可保证业务分析对数据的实时性要求,也可以解决对于tb、pb级别的历史数据进行探索性的数据分析。
(2)在解决对于可靠性和可扩展性问题,用户可能会需要存储多个位置的历史数据,同事数据规模由持续增长的趋势,需要引入多位置存储徐通来满足可靠性和可扩展性需求的问题,针对可靠性和可扩展性问题,本发明解决的方法是可以通过模块的基础配置,进行多数据位置进行配置,通过处理方法,解决需要各种数据落到指定位置的问题。
(3)在解决技术栈问题,本发明统一了技术栈,通过java、flink技术,完成了组合流式组件,存储系统,计算组件,以及从数据采集到数据处理再到数据落地等一系列调度管理。
(4)针对在解决现阶段大数据方向的运维性要求高,负责的大数据架构难以维护和管控问题,本发明实现了可不停机更新,通过对模块的高可配、可变更等特性,实现了在不停机的情况下,完成更新和增加处理业务的能力。
本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
图1为根据本发明实施例的基于高可配可变更的数据处理方法的流程图;
图2为根据本发明实施例的基于高可配可变更的数据处理方法的架构图;
图3为根据本发明实施例的基于高可配可变更的数据处理方法的示意图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
如图1和图2所示,本发明实施例的基于高可配可变更的数据处理方法,包括如下步骤:
步骤s1,接入多数据源的高可配可变更数据。
在本步骤中,依次采用工厂模式和抽象模式对高可配可变更数据进行处理,以进行多个等级数据的处理,实现高可配可可变更多数据源的数据接入。
具体来说,对简单工厂模式的进一步抽象化,可以使系统不修改原来的代码的情况下引进新的产品,实现不停机维护。采用工厂模式处理数据只能处理同一等级的数据,而升级后的抽象模式则可以处理多个等级的数据,实现高可配可可变更多数据源的数据接入。
步骤s2,根据接入的高可配可变更数据,自定义处理流程的工具模板,制定业务线的处理流程。
在本步骤中,采用java技术自定义处理流程工具模板,实现对业务线模块中处理流程的制定。
步骤s3,根据接入的高可配可变更数据,自定义处理逻辑的工具模板,执行业务线的处理逻辑。
在本步骤中,采用java技术自定义处理逻辑工具模板,实现对业务线模块中处理逻辑的执行。
在基于已定义的数据处理逻辑的基础上,进一步增加制定针对多数据源的不同处理逻辑,包括但不限于文本、图片、视频、指纹等数据类型。
步骤s4,输出处理逻辑的高可配可变更数据。
在基于数据存储位置的多样性的前提下,对不同数据输出位置采用不同的数据处理逻辑,包括但不限于关系型数据库、非关系型数据库和文件存储系统。例如,mysql、hdfs、hbase、oracle等。
步骤s5,对输出的高可配可变更数据,采用反射机制将步骤s2的业务线的处理流程和步骤s3的业务线的处理逻辑,反射到flink,由flink采用实时流处理技术,代为按照处理逻辑执行业务线的处理流程,实现flink对数据进行实时的流处理方法,保证数据的一致和实时的特点。
步骤s6,执行业务线的处理流程,进行自动化处理和私有化定制数据服务,得到目标数据。
如图3所示,本发明实施例的基于高可配可变更的数据处理方法,数据处理流程如下:
(1)通过拖拉拽的方式,对业务线模块进行基础配置,如:运用kafka进行数据源对接,需要进行对应的kafka工具模块、插件模块、执行模块进行拉取,配置;
(2)根据数据源进行对接数据请求方的数据,例:运用kafka进行对数据源进行对接,需要设定kafka相应的topic,其中包括producer,consumer,broker,zookeeper等,相关组件的配置;
(3)通过fink接收kafka发来的数据,flink会对集群中所有节点进行广播变量的发送,各个节点接收到flink广播变量后,会启动执行器;
(4)执行器调用java的反射机制,实现对hdfs的处理程序jar包中的类进行反射调取到flink集群的各个节点,完成对业务class类方法的加载,之后执行器获取object基础配置和对业务class类方法的加载,远程实现实例化接口对象;
(5)自定义接口(封装对数据源中的数据处理的一个或者多个逻辑),调用之定义接口,完成对目标数据处理的具体逻辑,如:
数据格式为:“1473981773~#!@200248~#!@finup~#!@122112”,
对该数据处理进行按指定分隔符进行切分,使其数据格式变成结构化数据,其处理后的数据格式为:
“1473981773200248finup122112”,已完成对数据的处理,其中可以包括流式处理和批量处理;
基于以上操作流程,将最终结果输出到目标数据位置。
根据本发明实施例的基于高可配可变更的数据处理方法,实现有效过滤垃圾数据以及在各系统间实时的采集,处理,存储等数据之间的互动,为各类数据、数据源已经存储位置提供高效稳定的数据支持与服务。本可以实现对多模块自定义,可移动,多配置等特点,且模块之间可随意移动,增加操作的便捷性和简单性,而不影响业务。
本发明实施例的基于高可配可变更的数据处理方法,具有以下有益效果:
(1)在解决业务分析的数据范围横跨实时数据和历史数据,既需要低延迟的实时数据分析,也需要对pb级的历史数据进行探索性的数据分析。针对这一问题,本发明解决的方法是通过在执行模块中运用flink实时流处理技术,即可保证业务分析对数据的实时性要求,也可以解决对于tb、pb级别的历史数据进行探索性的数据分析。
(2)在解决对于可靠性和可扩展性问题,用户可能会需要存储多个位置的历史数据,同事数据规模由持续增长的趋势,需要引入多位置存储徐通来满足可靠性和可扩展性需求的问题,针对可靠性和可扩展性问题,本发明解决的方法是可以通过模块的基础配置,进行多数据位置进行配置,通过处理方法,解决需要各种数据落到指定位置的问题。
(3)在解决技术栈问题,本发明统一了技术栈,通过java、flink技术,完成了组合流式组件,存储系统,计算组件,以及从数据采集到数据处理再到数据落地等一系列调度管理。
(4)针对在解决现阶段大数据方向的运维性要求高,负责的大数据架构难以维护和管控问题,本发明实现了可不停机更新,通过对模块的高可配、可变更等特性,实现了在不停机的情况下,完成更新和增加处理业务的能力。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在不脱离本发明的原理和宗旨的情况下在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。本发明的范围由所附权利要求及其等同限定。
- 还没有人留言评论。精彩留言会获得点赞!