训练方法、信息处理设备和非暂态计算机可读存储介质与流程
本发明涉及训练方法、信息处理设备和非暂态计算机可读存储介质。
背景技术:
深度学习(下文中称为dl)是使用多层神经网络的机器学习。作为深度学习的示例的深度神经网络(下文中称为dnn)是依次布置输入层、多个隐藏层和输出层的网络。每个层具有一个或更多个节点,并且每个节点具有值。一个层中的节点和下一层中的节点通过节点之间的边连接,并且每个边具有变量(或参数),例如权重或偏差。
在dnn中,基于前一层中的节点的值、节点之间的边的权重等通过预定运算来获得每个层中的节点的值。当将输入数据输入到输入层中的节点时,通过预定运算获得下一层中的节点的值,并且此外,使用通过由上述运算获得的数据作为输入通过对后续层的预定操作来获得后续层中的节点的值。然后,作为最后层的输出层中的节点的值变为针对输入数据的输出数据。
用于对dnn执行算术运算的dnn处理器可以使用定点算术单元来执行算术运算,因为作为要由运算处理的一个对象的图像数据具有相对小的位数。由于不使用浮点算术单元,因此这使得可以降低算术运算所需的功耗。此外,使用具有比浮点算术单元更简单的电路的定点算术单元意味着dnn处理器可以被设置成具有更小的电路规模。
然而,由于定点数的位数是固定的,因此动态范围比浮点数的动态范围更窄。为此,由于运算而产生的上溢可能使算术运算的结果值饱和,并且相反,下溢可能使更低位舍入。这导致算术运算的精度降低。
因此,对于dnn的运算,已经提出了可以动态调整通过计算而获得的运算的结果数据的小数点位置的动态定点。例如在日本专利申请公开第2018-124681号中公开了这样的动态定点。例如在日本专利申请公开第2012-203566号、第2009-271598号和第h07-084975号中公开了定点算术运算。
技术实现要素:
在动态定点方法中,在dnn的训练期间,执行每个层的算术运算,并且基于算术运算的结果的有效位的分布来调整算术运算的结果的定点位置。这使得可以抑制上述的上溢和下溢的发生,从而提高了运算的精度。另一方面,由于未将预训练中使用的定点调整为最佳位置,因此可以将dnn的输入数据、每个层的输出数据以及参数(例如权重和偏差)设定为浮点数使得通过浮点算术单元执行预训练。
当使用浮点数执行预训练时,不存在当使用定点数执行预训练时出现的运算结果的上溢或下溢,从而使得可以防止诸如各个层的输出数据和参数的中间数据的精度降低。此外,可以基于浮点算术单元的算术运算的结果的指数部的值将中间数据的定点调整到最佳位置。因此,训练对调整后的定点数使用定点算术单元。
然而,其中用于对dnn执行算术运算的dnn处理器除了配备有定点算术单元之外还配备有浮点算术单元以使用浮点算术单元对dnn执行预训练的配置需要浮点算术单元的硬件,并且还由于浮点算术单元而导致功耗增加。
因此,本实施方式的第一方面的目的是提供了一种能够通过定点运算以高精度执行预训练的训练程序、训练方法和信息处理设备。
本实施方式的一方面是一种使用神经网络执行深度学习的信息处理设备,该信息处理设备包括:存储器;以及算术处理装置,其能够访问存储器,其中,算术处理装置在预定方向上针对神经网络的多个层执行处理,针对多个层的处理包括:
(a)确定第一小数点位置,该第一小数点位置用于设定当多个第二定点数数据的被存储在寄存器中时执行饱和处理或舍入处理的范围,所述多个第二定点数数据是通过由算术处理装置对多个第一定点数数据的片段执行算术运算而获得的;
(b)通过算术处理装置对多个第一定点数数据执行算术运算,
基于使用第一小数点位置设定的范围对多个第二定点数数据执行饱和处理或舍入处理,并且将饱和处理或舍入处理的第一结果值存储在寄存器中,以及
获取关于多个第二定点数数据中的每一个的正数的最左置位的位置或负数的最左零位的位置的分布的第一统计信息;
(c)基于第一统计信息确定第二小数点位置,该第二小数点位置用于设定当多个第二定点数数据被存储在寄存器中时执行饱和处理或舍入处理的范围;以及
(d)基于第一小数点位置与第二小数点位置之间的差确定是否再次执行通过算术处理装置对多个第一定点数数据的算术运算,以及
当确定再次执行算术运算时,基于使用第二小数点位置设定的范围对下述多个第二定点数数据执行饱和处理或舍入处理并且将饱和处理或舍入处理的第二结果值存储在寄存器中,所述多个第二定点数数据是通过由算术处理装置对多个第一定点数数据再次执行算术运算而获得的。
附图说明
图1是示出深度神经网络(dnn)的配置示例的图;
图2是示出dnn训练处理的示例的流程图;
图3是示出根据本实施方式的深度学习(dl)系统的配置示例的图;
图4是示出主机30的配置示例的图;
图5是示出dnn执行机的配置示例的图;
图6是示出要由主机和dnn执行机执行的深度学习处理的概述的序列图;
图7是示出相对于本示例的比较例的深度学习(dl)的流程图的图;
图8是示出图7的比较例的深度学习中的由多个处理器进行的处理的流程图的图;
图9是示出根据第一实施方式的深度学习的流程图的图;
图10是示出图9的深度学习中的由多个处理器进行的处理的流程图的图;
图11是示出用于使用动态定点小数的训练的s61和s63的处理的图;
图12是示出训练中的前向传播处理和后向传播处理的图;
图13和图14是示出关于中间数据的分布的统计信息以及基于该分布来调整小数点位置的方法的图;
图15和图16是示出根据本实施方式的预训练的详细流程图的图;
图17是示出dnn处理器43的配置示例的图;
图18是示出要由dnn处理器执行的获取、聚合和存储统计信息的处理的流程图;
图19是示出统计信息获取单元st_ac的逻辑电路示例的图;
图20是示出由统计信息获取单元取得的运算输出数据的位模式的图;
图21是示出统计信息聚合器st_agr_1的逻辑电路示例的图;
图22是描述统计信息聚合器st_agr_1的运算的图;
图23是示出第二统计信息聚合器st_agr_2和统计信息寄存器文件的示例的图;
图24是示出根据第二实施方式的由多个处理器进行的深度学习的流程图的图;以及
图25是示出根据第二实施方式的预训练中的前向传播处理和后向传播处理的详细流程图的图。
具体实施方式
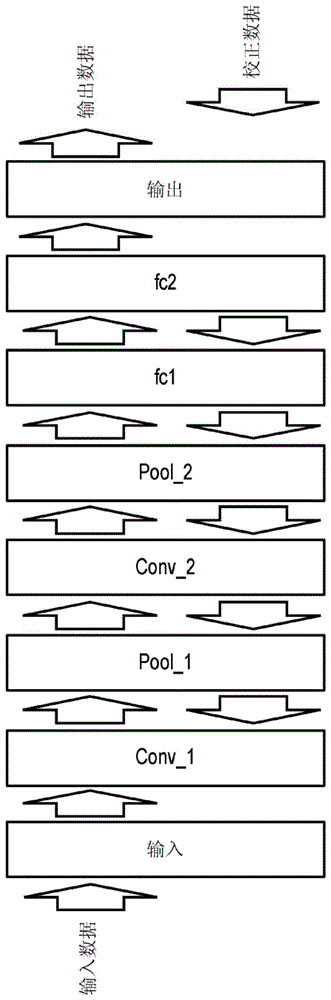
图1是示出深度神经网络(dnn)的配置示例的图。图1中的dnn是根据输入图像的内容(例如,数字)将例如接收到的输入图像分类为有限数量的类别的对象类别识别模型。dnn包括输入层(input)、第一卷积层conv_1、第一池化层pool_1、第二卷积层conv_2、第二池化层pool_2、第一完全连接层fc1、第二完全连接层fc2和输出层(output)。每个层具有一个或更多个节点。
在卷积层conv_1中,例如,对输入到输入层输入中的多个节点的图像的像素数据和节点之间的权重执行积和运算,并且将具有图像特征的输出图像的像素数据输出至卷积层conv_1中的多个节点。这同样适用于卷积层conv_2。
池化层pool_1是具有带有值的节点的层,该值是根据作为前一层的卷积层conv_1中的本地节点来确定的。例如,池化层pool_1中的节点被设置为本地节点中的最大值以吸收图像中的细微变化。
在输出层(output)中,使用softmax函数等根据节点的值获得图像的每个类别的概率。
图2是示出dnn训练处理的示例的流程图。在训练处理中,例如,使用包括输入数据和由dnn根据输入数据计算出的校正数据的多个训练数据来优化dnn中的诸如权重的参数。在图2的示例中,根据小批量方法将多个训练数据划分为用于多个小批量的训练数据,使得作为输入数据接收每个小批量中的多个训练数据。然后,对诸如权重的参数进行优化以便减少由dnn输出的输出数据与每个小批量中各个输入数据的校正数据之间的差(误差)的平方和。
如图2所示,作为预备,对训练数据进行混洗(s1),并且将混洗后的训练数据划分为用于多个小批量的训练数据(s2)。
在训练s5中,针对经划分的小批量中的每一个重复前向传播处理s6、误差评估s7、后向传播处理s8和参数更新s9。当完成了针对全部小批量的处理时(s11中为“是”),对相同的训练数据重复执行s1至s2、s5至s9和s11的处理直到达到指定次数(s12中为“否”)
代替用相同的训练数据重复s1至s2和s5至s9的处理直到达到指定的次数,可以在训练结果的评估值(例如,输出数据与校正数据之间的差(误差)的平方和)落入一定范围内时完成训练处理。
在前向传播处理s6中,以从dnn的输入侧至输出侧的顺序执行每个层的算术运算。如参照图1的示例所描述的,在第一卷积层conv_1中,使用边权重等对作为输入到输入层(input)的一个小批量中包括的训练数据的输入数据执行卷积算术运算,使得输出多个运算输出数据。然后,在第一池化层pool_1中,执行减弱卷积层conv_1的算术运算结果的局部性的处理。此外,在第二卷积层conv_2和第二池化层pool_2中,执行与上述相同的处理。最后,在完全连接的层fcl和fc2中,利用全部边的权重等执行卷积算术运算,使得将输出数据输出至输出层(output)。
接下来,在误差评估处理s7中,将dnn的输出数据与校正数据之间的差的平方和计算为误差。然后,执行将误差从dnn的输出侧传播至输入侧的后向传播处理s8。在后向传播处理s8中,将误差从输出侧传播至输入侧,并且在每个层中的传播误差通过参数进行微分,使得通过梯度下降法来计算参数的变化数据。然后,在参数更新处理s9中,利用通过梯度下降法而获得的参数的变化值来更新当前参数,使得在最佳值方向上更新权重等(包括每个层的偏差)。
dnn可以被配置成使得由硬件电路实现多个层,并且硬件电路对各个层执行算术运算。替选地,dnn可以被配置成使得用于对dnn的各个层执行算术运算的处理器执行对各个层执行算术运算的程序。
图3是示出根据本实施方式的深度学习(dl)系统的配置示例的图。dl系统包括主机30和dnn执行机40。例如,主机30和dnn执行机40经由专用接口耦接。此外,用户终端50被配置成可由主机30访问,使得用户从用户终端50访问主机30以操作dnn执行机40并且执行深度学习。主机30根据来自用户终端的指令来生成要由dl执行机执行的程序,并且将该程序发送至dnn执行机。因此,dnn执行机执行所发送的程序以执行深度学习。
dnn执行机40包括用于执行定点算术运算的dnn处理器43_1和用于执行浮点算术运算的dnn处理器43_2。在本实施方式中,可以不提供用于执行浮点算术运算的dnn处理器43_2。
在本实施方式中,由用于执行定点算术运算的dnn处理器43_1执行预训练,确定dnn的中间数据的定点位置,并且还由用于执行定点算术运算的dnn处理器43_1执行训练。
用于执行定点算术运算的dnn处理器43_1包括统计信息获取电路,其获取关于中间数据,例如在dnn中计算出的运算结果和通过训练而更新的变量以及存储器中的数据的有效的最高有效位和/或有效的最低有效位的数目等的统计信息。dnn处理器43_1获取在预训练和训练中的每一个中执行训练的同时通过运算而获得的中间数据的统计信息,并且基于统计信息将中间数据的定点位置调整为最佳位置。
图4是示出主机30的配置示例的图。主机30包括处理器31、用于耦接至dnn执行机40的高速输入/输出接口32、主存储器33和内部总线34。主机30还包括耦接至内部总线34的辅助存储设备35(例如大容量hdd)以及用于耦接至用户终端50的低速输入/输出接口36。
主机30的处理器31执行被存储在辅助存储设备35中并且被加载到主存储器33中的程序。高速输入/输出接口32是例如,将处理器31耦接至dl执行机的硬件的接口,例如pciexpress。主存储器33将要由处理器执行的程序和数据存储在其中,并且例如是sdram。
内部总线34将处理器耦接至具有比处理器更低速度的外围设备,以在它们之间中继通信。低速输入/输出接口36用于耦接至例如用户终端的键盘或鼠标,例如usb,或者用于耦接至以太网。
如图4所示,辅助存储设备35例如hdd或sdd将dnn训练程序和训练数据存储在其中。dnn训练程序包括预训练程序和训练程序。处理器31执行dnn训练程序例如以将预训练程序和训练数据发送到dnn执行机,使得dnn执行机执行预训练程序。处理器31还执行dnn训练程序以将训练程序和训练数据发送至dnn执行机,使得dnn执行机执行实际程序。
图5是示出dnn执行机的配置示例的图。dnn执行机40包括高速输入/输出接口41,其中继与主机30的通信;以及控制单元42,其基于来自主机30的命令和数据执行对应处理。dnn执行机40还包括dnn处理器43、存储器访问控制器44和内部存储器45。
dnn处理器43基于从主机发送的程序和数据执行程序以执行深度学习的处理。如上所述,dnn处理器43包括用于执行定点算术运算的dnn处理器43_1和用于执行浮点算术运算的dnn处理器43_2。然而,可以不提供用于执行浮点算术运算的dnn处理器43_2。
高速输入/输出接口41例如是pciexpress,并且中继与主机30的通信。
控制单元42将从主机发送的程序和数据存储在存储器45中,并且响应于来自主机的命令指示dnn处理器执行该程序。存储器访问控制器44响应于来自控制单元42的访问请求或来自dnn处理器43的访问请求控制对存储器45的访问处理。
内部存储器45将要由dnn处理器执行的程序、要处理的数据、处理结果的数据等存储在其中。内部存储器45例如是具有高带宽的sdram、更快的gdr5或hbm2。
如参照图4所述,主机30将预训练程序和训练数据发送至dnn执行机40,并且还发送训练程序和训练数据。这些程序和数据被存储在内部存储器45中。响应于来自主机30的用于执行的指令,dnn执行机的定点处理器执行预训练程序和训练程序。
图6是示出要由主机和dnn执行机执行的深度学习处理的概述的序列图。主机30向dnn执行机40发送用于深度学习的训练程序(用于预训练和训练)(s31)、发送用于一个小批量的训练数据(s32)以及发送用于执行训练程序的指令(s33)。
响应于这些传送,dnn执行机40将训练数据和训练程序存储在内部存储器45中,并且响应于用于执行训练程序的指令对存储在存储器45中的训练数据执行训练程序(s40)。训练程序由dnn处理器43_1执行。同时,主机30等待直到由dl执行机完成训练程序的执行。
当用于深度学习的训练程序的执行完成时,dnn执行机40将指示训练程序的执行完成的通知发送至主机30(s41)。
主机30发送用于下一小批量的训练数据(s32),并且发送用于执行训练程序的指令(s33)。然后,dnn执行机40执行训练程序(s40),并且发送完成的通知(s41)。重复这些处理以推进用于深度学习的训练。
在dnn的训练中,在dnn的前向方向上执行每个层的算术运算(前向传播处理);在dnn的逆向方向上传播输出层的输出数据与校正数据之间的误差以计算每个层中的误差并且计算变量的变化数据,使得减小误差(后向传播处理);并且使用该变量的变化数据更新变量(参数更新)。dnn的这些训练处理可以全部由dnn执行机40执行,或者部分处理可以由主机30执行。
比较例的深度学习
图7是示出相对于本示例的比较例的深度学习(dl)的流程图的图。在比较例中,用于执行浮点算术运算的dnn处理器执行预训练,并且用于执行定点算术运算的dnn处理器执行训练。
首先,dnn处理器使用浮点数执行预训练,并且确定每个中间数据(各个层中的算术运算结果、参数等)的初始小数点位置(s50)。对于具有浮点数的预训练,由于dnn中的中间数据是浮点数,因此生成了与中间数据的大小对应的指数部。因此,不需要像定点数那样调整小数点位置。然后,基于浮点数的中间数据,确定每个中间数据的定点数的最佳小数点位置。
接下来,dnn处理器使用定点数开始训练(s5)。在训练中,dnn处理器在执行小批量训练的同时获取并存储关于中间数据的分布的统计信息(s61)。用于执行定点算术运算的dnn处理器包括统计信息获取电路,该统计信息获取电路获取诸如定点算术单元的算术运算输出的有效位的分布的统计信息。因此,通过使处理器执行包括统计信息获取处理的算术运算的指令,可以在小批量训练期间获取并存储中间数据的统计信息。每当执行了k次小批量训练时(在s10中为“是”),基于中间数据的分布的统计信息来调整dnn中的每个中间数据片段的定点位置(s63)。
后面将详细描述处理器中的统计信息获取电路和基于分布的统计信息调整定点位置的方法。
然后,直到完成全部小批量训练之前(s11中为“否”),dnn处理器重复s61、s10和s63。当全部小批量训练完成时(s11中为“是”),处理返回至第一s5以在直到达到预定次数之前(s12中为“否”)重复全部小批量训练。注意,图7中的s11和s12的处理等同于图2中的s11和s12的处理。
图8是示出图7的比较例的深度学习中由多个处理器进行的处理的流程图的图。与图7中的处理相同的处理由相同的处理标记来表示。首先,主处理器31生成dnn中的诸如权重和偏差的参数的初始值(s70)。初始值为浮点数。
然后,主处理器31调用用于浮点处理器的预训练程序(s51),并且响应于此,用于执行浮点算术运算的dnn处理器43_2执行预训练(s52)。通过浮点算术运算进行的预训练包括例如多次执行小批量训练。
此外,主处理器31基于通过预训练而获得的中间数据的浮点数来确定定点数的初始小数点位置,并且读取用于将中间数据的浮点数转换为定点数的程序(s53)。响应于此,用于执行浮点算术运算的dnn处理器43_2将中间数据的浮点数转换成定点数(s54)。浮点处理器43_2包括用于将浮点数转换为整数的电路,并且使用该电路以通过程序将浮点数转换为定点数。
接下来,主处理器31调用用于使用动态定点数的训练的程序,并且将各种数据及其小数点位置信息发送至定点处理器43_1(s71)。响应于此,用于执行定点算术运算的dnn处理器43_1执行在动态地调整定点数的小数点的同时执行的训练(s5)。
根据第一实施方式的深度学习
图9是示出根据第一实施方式的深度学习的流程图的图。在本实施方式中,预训练和训练由用于执行定点算术运算的dnn处理器执行。
首先,主处理器根据训练数据的输入数据和dnn中的诸如权重和偏差的参数的初始值确定初始小数点位置(s80)。然后,主处理器将初始值转换为定点数。
接下来,用于执行定点算术运算的dnn处理器43_1开始预训练(s81)。在预训练中,dnn处理器执行预训练,同时确定dnn中的中间数据(卷积层的输出数据、池化层的输出数据、完全连接层的输出数据、输出层的输出数据、诸如各个层的权重和偏差的参数、参数的更新值等)的小数点位置。
在预训练中,定点dnn处理器43_1依次对dnn中的每个层执行前向传播处理,同时确定层的中间数据的小数点位置(s81_1)。前向传播处理是按照从输入层至输出层的顺序对各个层执行算术运算的处理。
接下来,在预训练中,定点dnn处理器依逆序对dnn中的每个层执行后向传播处理,同时确定层的中间数据的小数点位置(s81_2)。后向传播处理根据输出层的输出数据与校正数据之间的误差(差)按照从输出层至输入层的逆序计算dnn中的各个层的误差梯度,并且计算参数的变化差数据使得使每个层中的误差最小化。
最后,在预训练中,定点dnn处理器使用各个层的变化差数据依次更新参数,并且更新更新后的参数的小数点位置(s81_3)。
在上述的预训练中,针对中间数据确定临时小数点位置。然后,定点dnn处理器43_1在预训练中执行各个层的算术运算的同时获取关于中间数据的分布的统计信息。此外,定点dnn处理器基于每个层中的统计信息的分布信息来确定中间数据的最佳小数点位置。如后面所述,在前向传播和后向传播中各个层的中间数据的最佳小数点位置之后,如果确定的小数点位置与临时小数点位置不匹配,或者如果位置彼此相差等于或大于阈值,则使用确定的小数点位置的定点数再次执行对应层的算术运算。这使得可以在预训练期间提高每个层的中间数据的精度。
在预训练完成之后,定点dnn处理器开始训练(s5)。用于训练的s61、s10、s63、s11和s12的处理与图7中的处理相同。
也就是说,在训练中(如图7所示),定点dnn处理器对k个小批量的训练数据执行前向传播处理s6、误差评估s7、后向传播处理s8和参数(权重、偏差等)的更新s9,同时获取中间数据的统计信息(s61)。然后,定点dnn处理器基于通过k次小批量训练而获取的中间数据的统计信息调整中间数据的小数点位置(s63)。定点dnn处理器重复执行k个小批量训练s61和中间数据的小数点位置的调整s63直到完成全部小批量训练(s11)。当全部小批量训练完成时(s11中为“是”),重复执行s5至s11的处理直到达到预定次数。
优选地,对通过划分用于深度学习的训练数据而获得的一个小批量或几个小批量的多个训练数据执行上述的具有定点数的预训练。然后,基于前向传播处理中的每个层和后向传播处理中的每个层中的统计信息来调整中间数据的小数点位置。另一方面,在训练中,每当对k个小批量的训练数据执行并完成训练时,基于关于中间数据的分布的统计信息来调整中间数据的小数点位置。在训练中,重复执行k个小批量训练和中间数据的小数点位置的调整直到dnn达到所需状态(直到达到预定次数或误差收敛到小于参考值)。当全部小批量训练完成时,更新学习率,重新布置训练数据,并且然后重复执行训练。
图10是示出图9的深度学习中由多个处理器进行的处理的流程图的图。与图9中的处理相同的处理由相同的处理标记来表示。
首先,主处理器31生成dnn中的诸如权重和偏差的参数的初始值(s70)。初始值为浮点数。接下来,主处理器确定输入数据以及诸如权重和偏差的参数的初始小数点位置,并且使用初始小数点位置将浮点数转换为定点数(转换为定点数)(s80_1)。由于输入数据和参数是浮点数,因此主处理器基于指数部或者基于最大值和最小值来确定最佳定点位置。
然后,主处理器31调用用于定点dnn处理器的预训练程序(s80_2),并且响应于此,定点dnn处理器43_1执行预训练程序以执行预训练(s81)。通过定点算术运算进行的预训练包括例如执行一次或多次小批量训练,并且包括图9中的s81_1、s81_2和s81_3的处理。还使用动态定点数执行预训练,并且在执行每个层的算术运算的同时确定每个层的中间数据的小数点位置。尽管后面将描述细节,但是定点dnn处理器获取关于中间数据的分布的统计信息,并且基于中间数据的分布来确定最佳小数点位置。
接下来,主处理器调用用于定点dnn处理器的训练程序(s71),并且响应于此,定点dnn处理器43_1使用动态定点数执行训练程序以执行训练(s5)。在使用动态定点数的训练中,重复执行k个小批量训练直到完成全部小批量训练,并且包括图9的s61、s10、s63、s11和s12的处理。使用动态定点数的训练与比较例中的训练相同,并且因此不再重复其描述。
使用动态定点数的实际训练的概述
在日本公开(日本专利申请公开第2018-124681号)中公开了使用动态定点数的训练,并且该公开的公开内容通过引用并入本文中。
图11是用于示出使用动态定点数的训练的s61和s63的处理的图。在图9所示的用于训练的s61的处理中,定点dnn处理器重复执行小批量训练k次。在每次小批量训练中,处理器在针对小批量的多个训练数据依次对各个层执行前向传播处理、后向传播处理以及更新参数的处理的同时,针对每个层获取并存储关于每个层的中间数据的分布的统计信息。
接下来,在用于训练的s63的处理中,定点dnn处理器基于在所存储的统计信息中包括的多个中间数据的有效位的分布来确定并更新每个层的中间数据的最佳小数点位置。
图12是示出训练中的前向传播处理和反向传播处理的图。在前向传播处理中,处理器中的定点算术单元将偏差b加至与通过将更靠近输入侧的层l1中的每个节点的数据x0至xn乘以它们之间的链路的权重wij而获得的值的累积和,以计算更靠近输出侧的层l2中的节点的输出数据z0至zj……。此外,定点算术单元通过层l2的激活函数来计算针对输出数据z0至zj……的激活函数的输出数据u0至uj……。从输入侧至输出侧重复层l1和l2中的计算。
另一方面,在反向传播处理中,处理器中的定点算术单元根据更靠近输出侧的层l6中的误差梯度δ0(6)至δi(6)至δn(6)(输出数据与校正数据之间的差的传播梯度)来计算更靠近输入侧的层l5中的误差梯度δ0(5)至δj(5)……。然后,定点算术单元根据通过用诸如权重wij的参数对层l5中的误差梯度δ0(5)至δi(5)至δn(5)求微分而获得的值的梯度方向来计算权重的差更新数据δwij。从输出侧至输入侧重复层l6和l5中的计算。
此外,在依次更新每个层的参数的处理中,通过将差更新数据δwij与现有权重wij相加来计算更新后的权重wij。
如图12所示,层l2中的输出数据z0至zj……、激活函数的输出数据u0至uj……、层l6中的误差梯度δ0(6)至δi(6)至δn(6)、层l5中的误差梯度δ0(5)至δj(5)……、权重的差更新数据δwij和更新后的权重wij全部是dnn中的中间数据。通过将这些中间数据的小数点位置调整到最佳位置,可以提高每个中间数据的运算精度,并且还可以提高训练的精度。
图13和图14是示出关于中间数据的分布的统计信息以及基于该分布调整小数点位置的方法的图。如后面所述,定点dnn处理器包括多个定点算术单元以及统计信息获取电路,该统计信息获取电路获得关于中间数据(例如每个算术单元的输出和存储在存储器45中的运算的结果数据)的有效位的分布的统计信息。
关于中间数据的有效位的分布的统计信息例如如下。
(1)正数的最左置位的位置和负数的最左零位的位置的分布
(2)非零最低有效位的位置的分布
(3)正数的最左置位的位置和负数的最左零位的位置的最大值
(4)非零最低有效位的位置的最小值
(1)正数的最左置位的位置和负数的最左零位的位置是中间数据的有效位的最高有效位的位置。在此,正数包括零。
(2)非零最低有效位的位置是中间数据的有效位的最低有效位的位置。如果符号位为0(正),非零最低有效位的位置是非零最低有效位“1”的位置,并且如果符号位为1(负)则还为最低有效位“1”的位置。如果符号位为1,则除符号位以外的位用二进制补码表示,并且将二进制补码转换为原始数的处理包括从二进制补码减去1并将1转换为0和将0转换为1的处理。因此,最低有效位“1”通过减1变为“0”,并且通过位反转变为“1”,并且因此最低有效位“1”位于有效位中的最低有效位的位置。
(3)正数的最左置位的位置和负数的最左零位的位置的最大值是多个中间数据的有效位中的最高有效位的位置中的最大位置。类似地,(4)非零最低有效位的位置的最小值是多个中间数据的有效位中的最低有效位的位置中的最小位置。
作为示例,图13和图14示出了(1)正数的最左置位或负数的最左零位的位置的分布的直方图。横轴表示与直方图的每个仓对应的中间数据的有效最高有效位,并且纵轴表示具有每个仓的有效最高有效位的中间数据的数目。在这些示例中,仓的数目为-15至+24,即总共40。
分布中的最高有效仓对应于(3)正数的最左置位或负数的最左零位的位置的最大值。
注意,在图13和图14的水平轴上指示的数值表示相对于输出数据的小数部的最低有效位的相对位位置。例如,“1”指示比输出数据的最低有效位高的数字1,而“-1”指示比输出数据的最低有效位低的数字1。
对于16位定点数,除符号位以外的位数为15位。用于定点数的格式表示为qn.m。具体地,qn.m具有n位的整数部和m位的小数部。小数点位置位于整数部与小数部之间。
另一方面,正数的最左置位或负数的最左零位的位置分布的扩展(直方图中的仓数)取决于多个中间数据而变化。图13中的直方图分布的扩展是从-12的仓至+20的仓,即仓数为32(=12+20),其没有落入15位的定点数(可表示为定点数的区域)之内。最左置位位置大于15的数据被上溢并使其饱和,而最左置位位置小于0的数据被下溢并舍入。另一方面,在图14的直方图中,从0的仓至+12的仓的仓数是13,其落入15位的定点数之内。
因此,基于作为直方图的统计信息确定小数点位置的方法取决于直方图的水平宽度(仓数)是未落入可表示区域(15位)之内(图13),即,超过15位,还是落入可表示区域之内(图14)而不同。
当图13的直方图的32的水平宽度(仓数)未落入可表示区域(15位)之内,即,超过15位时,如下确定定点数格式(小数点位置)。具体地,较高位侧上的最大位数bmax被确定成使得其满足直方图的较高位侧上的数据数与数据总数的比率小于预定阈值rmax,并且定点数格式被确定成具有比所确定的位数bmax低的位。换句话说,允许由于在所确定的位数bmax之内的数据上溢而导致饱和。
在图13的示例中,现有的定点数格式q5.10包含0至+15的位,而更新之后,定点数格式被更新为包含-2至+13的位的q3.12。作为该变化的结果,对于具有位于+13至+22的正数的最左置位或负数的最左零位的中间数据,其值由于上溢而导致饱和,而对于具有位于-1或-2的正数的最左置位或负数的最左零位的中间数据,至少不对正数的最左置位或负数的最左零位进行舍入。
在图14的示例中,由于将现有的定点数格式q4.11变更为直方图的较高位侧,因此更新之后定点数格式变更为q1.14。对于q1.14,格式q1.14的中心位位于直方图的峰位置。因此,对于具有在1、0或+1中的正数的最左置位或负数的最左零位的中间数据,至少不对正数的最左置位或负数的最左零位进行舍入。
在图9和图10的预训练中,临时确定中间数据的初始小数点位置,并且在用于小批量训练的前向传播处理、后向传播处理以及参数更新处理中的每一个中获取关于中间数据的分布的统计信息。然后,基于统计信息,以与图13和图14相同的方式确定中间数据的小数点位置。
当在前向传播处理、后向传播处理中的每一个中基于统计信息确定的小数点位置与基于统计信息临时确定的小数点位置不匹配或它们之间相差等于或大于阈值时,使用基于统计信息确定的小数点位置再次执行用于小批量训练的前向传播处理和后向传播处理。通过以这种方式再次执行处理,可以提高前向传播处理的精度,还可以提高下一后向传播处理的精度,并且还可以提高参数更新处理的精度。
根据本实施方式的预训练的细节
图15和图16是示出根据本实施方式的预训练的详细流程图的图。图15示出了图9的s80的处理的细节。图16示出了图9的s81、s81_1、s81_2和s81_3的处理的细节。
图15示出了在深度学习中确定初始小数点位置并将其转换为定点数的s80、预训练s81和训练s5的处理。在s80(s80_1)的处理中,将作为dnn中的初始值给出的输入数据以及诸如各个层的权重和偏差的参数转换为定点数。为此,主处理器获取诸如输入数据、权重和偏差的参数中的每一个的最大值和最小值(s100),并且确定整数部的位数使得最大值和最小值的绝对值中的较大一个不会由于上溢而导致饱和(s101)。
例如,当较大的绝对值为+2.25时,log2(2.25)=1.169925001,并且因此,如果整数部为2位,则最大值为0b11=3,使得绝对值+2.25不会上溢。即,初始小数点位置以具有2位的整数部和13位的小数部的格式q2.13来确定。
然后,主处理器以确定的格式qn.m将诸如输入数据、权重和偏差的参数中的每一个从浮点数转换为定点数(s102)。
图16示出了预训练s81中的前向传播处理s81_1、后向传播处理s81_2以及诸如各个层的权重和偏差的参数的更新处理s81_3的详细处理。在预训练s81中,执行一次或若干次小批量训练。
在前向传播处理s81_1中,定点dnn处理器依次对dnn中的每个层重复以下处理。首先,dnn处理器将每个层的中间数据的临时小数点位置确定为qn.m(s110)。临时小数点位置的确定例如是如以与各个层的输入数据的小数点位置等的确定相同的方式进行的。在卷积层中,由于通过将偏差加至与通过将输入数据乘以权重而获得的值的累积和来生成中间数据,因此上述确定被有效地认为是中间数据的临时小数点位置。
接下来,定点dnn处理器对目标层执行前向传播操作,并且获取通过算术运算而获得的中间数据的统计信息(s111)。该前向传播操作是如参照图12所述的。优选地针对一个小批量的训练数据执行前向传播处理。然而,可以将一个小批量的训练数据进行划分使得执行几次操作。替选地,可以针对两个或更多个小批量的训练数据执行操作。然后,定点dnn处理器基于所获取的中间数据的统计信息来确定多个中间数据中的每一个的最佳小数点位置qn'.m'(s112)。确定最佳小数点位置的处理是如参照图13和14所述的。
此外,定点dnn处理器将临时小数点位置qn.m与确定的小数点位置qn'.m'进行比较(s113),并且当它们不匹配时(s113中的“否”),将小数点位置qn.m替换为确定的小数点位置qn'.m',并且然后再次执行前向传播处理(s114)。在再次执行前向传播处理s114中获得的中间数据被重写在s111的处理中获得的中间数据上。通过使用确定的小数点位置再次执行前向传播处理,可以提高目标层的中间数据的精度。当临时小数点位置qn.m与确定的小数点位置qn'.m'匹配时(s113中为“是”),不执行s114的处理。
s113中的确定可以是关于临时小数点位置qn.m与确定的小数点位置qn'.m'之间的差是否小于阈值而不是它们是否匹配的确定。
在针对每个层的前向传播处理中获得多个中间数据的情况下,s113中的确定优选地是适于提高前向传播处理的精度的确定,例如,关于以下的确定:(1)针对全部中间数据,临时小数点位置是否与确定的小数点位置相匹配(即,对于至少一个中间数据,临时小数点位置是否与确定的小数点位置不匹配)、(2)针对预定数目的中间数据,临时小数点位置是否与确定的小数点位置匹配,或(3)针对特定的中间数据,临时小数点位置是否与确定小数点位置匹配。此外,s113中的上述(1)至(3)中的确定可以是关于临时小数点位置qn.m与确定的小数点位置qn'.m'之间的差是否小于阈值而不是它们是否匹配的确定。
定点dnn处理器依次对dnn中的每个层重复执行上述的s110至s114的处理。当针对全部层执行了s110至s114的处理时,处理器执行后向传播处理s81_2。
在后向传播处理s81_2中,定点dnn处理器以逆序对dnn中的每个层重复以下处理。将每个层的中间数据(诸如误差或权重的差值)的临时小数点位置确定为qn.m(s120)。临时小数点位置的确定例如是如以与针对每个层的输入数据的小数点位置的确定相同的方式进行的。
接下来,定点dnn处理器对目标层执行后向传播操作,并且获取通过操作而获得的中间数据的统计信息(s121)。该后向传播操作如参照图12所述。还针对一个或若干个小批量的训练数据执行后向传播操作。然后,定点dnn处理器基于所获取的中间数据的统计信息来确定多个中间数据中的每一个的最佳小数点位置qn'.m'(s122)。
此外,定点dnn处理器将临时小数点位置qn.m与确定的小数点位置qn'.m'进行比较(s123),并且当它们不匹配时(s123中为“否”),将小数点位置qn.m替换为确定的小数点位置qn'.m',并且然后再次执行后向传播处理(s124)。在再次执行后向传播处理中获得的中间数据被重写在s121的处理中获得的中间数据上。通过使用确定的小数点位置再次执行后向传播处理,可以提高目标层的中间数据(诸如误差或权重的差值)的精度。当它们匹配时(s123中的“是”),则不执行s124的处理。
确定s123可以是以上确定s113所例示的确定(1)至(3)中的任何一个。它们是否匹配可以通过m与m'或n与n'之间的差是否小于阈值来确定。
接下来,定点dnn处理器依次对每个层重复以下处理。即,处理器通过将在反向传播处理s81_2中获得的每个层的权重和偏差差更新值δwij和δb与原始权重和偏差相加来更新权重和偏差,并且获取更新后的权重和偏差的统计信息(s130)。然后,基于统计信息来确定并更新更新后的权重和偏差的小数点位置qn'.m'(s131)。当诸如全部层的权重和偏差的参数的更新及其小数点位置的更新完成时,预训练结束,并且然后处理器进行到训练。
在训练中,每当执行k次小批量训练时,处理器基于在小批量训练期间获取的统计信息来调整中间数据的小数点位置。用于在训练中调整中间数据的小数点位置的条件可以与用于在预训练中调整中间数据的小数点位置的条件不同(当临时小数点位置qn.m与确定的小数点位置qn'.m'不匹配时)。该条件可以例如是调整之前的小数点位置和确定的小数点位置彼此相差等于或大于预定阈值rmax的条件。
定点dnn处理器的配置和统计信息的获取
接下来,将描述根据本实施方式的定点dnn处理器的配置和统计信息的获取。
图17是示出dnn处理器43的配置示例的图。dnn处理器或dnn运算处理设备43包括指令控制单元inst_con、寄存器文件reg_fl、特定寄存器spc_reg、标量算术单元或电路sc_ar_unit、矢量算术单元或电路vc_ar_unit以及统计信息聚合器或聚合电路st_agr_1和st_agr_2。
在dnn处理器43中,矢量算术单元包括:整数算术单元或电路int,其各自对定点数进行运算;以及浮点算术单元或电路fp,其各自对浮点数进行运算。换句话说,dnn处理器43包括定点dnn处理器43_1和浮点dnn处理器43_2。
此外,指令存储器45_1和数据存储器45_2经由存储器访问控制器(mac)44耦接至dnn处理器43。mac44包括指令mac44_1和数据mac44_2。
指令控制单元inst_con包括例如程序计数器pc和指令译码器dec。指令控制单元通过参考程序计数器pc的地址从指令存储器45_1获取指令,通过指令译码器dec对获取的指令进行译码,并且将译码后的指令发布到算术单元。
寄存器文件reg_fl包括由标量算术单元sc_ar_unit使用的标量寄存器文件sc_reg_fl和标量累积寄存器sc_acc。寄存器文件reg_fl还包括由矢量算术单元vc_ar_unit使用的矢量寄存器文件vc_reg_fl和矢量累积寄存器vc_acc。
例如,标量寄存器文件sc_reg_fl包括例如32位标量寄存器sr0-sr31和32+α位标量累积寄存器sc_acc。
矢量寄存器文件vc_reg_fl包括例如八组寄存器reg00-reg07到reg70-reg77,其中每个组包括32位寄存器regn0至regn7的八个元素。矢量累积寄存器vc_acc包括例如作为八个元素的32+α位寄存器a_reg0至a_reg7。
标量算术单元sc_ar_unit包括一组整数算术单元int、数据转换器d_cnv以及统计信息获取单元或电路st_ac。数据转换器将从整数算术单元int输出的定点数的输出数据转换为浮点数。标量算术单元sc_ar_unit使用标量寄存器文件sc_reg_fl中的标量寄存器sr0至sr31和标量累积寄存器sc_acc来执行算术运算。例如,整数算术单元int对存储在标量寄存器sr0至sr31中的任一个中的输入数据进行运算,并且将输出数据存储在另一寄存器中。当执行乘积和运算时,整数算术单元int将乘积和运算的结果存储在标量累积寄存器sc_acc中。标量算术单元的运算结果被存储在标量寄存器、标量累积寄存器和数据存储器45_2中的任何一个中。
矢量算术单元vc_ar_unit包括算术单元或电路的八个元素el0至el7。el0至el7中的每个元素包括整数算术单元int、浮点算术单元fp和数据转换器d_cnv。矢量算术单元接收例如矢量寄存器文件vc_reg_fl中的任何一组八元素寄存器regn0至regn7中的输入数据,与八元素算术单元并行地执行算术运算,并且将算术运算的结果存储在另一组八元素寄存器regn0至regn7中。
矢量算术单元还使用八元素算术单元执行乘积和运算,并且将乘积和运算的结果累积和存储在矢量累积寄存器vc_acc的八元素寄存器a_reg0至a_reg7中。
在矢量寄存器regn0至regn7和矢量累积寄存器a_reg0至a_reg7中,运算元素的数量取决于要运算的数据的位数是32位、16位还是8位而增加到8、16或32。
矢量算术单元包括八个统计信息获取单元或电路st_ac,其分别从八元素整数算术单元int获取输出数据的统计信息。统计信息是来自整数算术单元int的输出数据的正数的最左置位或负数的最左零位的位置信息。将统计信息获取为后面参照图20描述的位模式。统计信息获取单元st_ac可以被配置成不仅接收来自整数算术单元int的输出数据,而且还接收存储器45_2中的数据以及标量寄存器或标量累积寄存器中的数据以获取统计信息。
如后面所述的图23所示,统计信息寄存器文件st_reg_fl包括例如八组寄存器str0_0-str0_39到str7_0-str7_39,其中每个组包括32位×40元素的统计信息寄存器str0至str39。
标量寄存器sr0至sr31将例如地址和dnn参数存储在其中。矢量寄存器reg00-reg07到reg70-reg77将矢量算术单元的输入数据和输出数据存储在其中。矢量累积寄存器vc_acc将矢量寄存器的乘积结果和加法结果存储在其中。
统计信息寄存器str0_0-str0_39到str7_0-str7_39将属于最多八种类型直方图的多个仓的数据的数目存储在其中。在整数算术单元int的输出数据是40位的情况下,在例如统计信息寄存器str0_0至str0_39中存储在每40位中具有正数的最左置位或负数的最左零位的数据的数目。
标量算术单元sc_ar_unit具有算术运算、移位运算、分支、加载/存储等的四种类型的功能。如上所述,标量算术单元包括统计信息获取单元st_ac,该统计信息获取单元st_ac从整数算术单元int的输出数据中获取具有正数的最左置位或负数的最左零位的位置的统计信息。
矢量算术单元vc_ar_unit使用矢量累积寄存器等执行浮点算术运算、整数算术运算、乘积和运算。矢量算术单元还执行矢量累积寄存器的清除、乘积和累积(mac)、累加、转移到矢量寄存器等。此外,矢量算术单元执行加载和存储。如上所述,矢量算术单元包括统计信息获取单元st_ac,该统计信息获取单元st_ac从八个元素中的每一个的整数算术单元int的输出数据中获取具有正数的最左置位或负数的最左零位的位置的统计信息。
统计信息的获取、聚合、存储
接下来,将描述通过dnn处理器对运算输出数据的统计信息的获取、聚合和存储。统计信息的获取、聚合和存储是要从主处理器发送的指令,并且将使用由dnn处理器执行的指令作为触发器来执行。因此,除了用于dnn中的每个层的运算指令之外,主处理器还将用于获取、聚合和存储统计信息的指令发送至dnn处理器。替选地,主处理器向dnn处理器发送用于包括获取、聚合和存储统计信息的处理的操作的指令以用于每个层的运算。
图18是示出要由dnn处理器执行的获取、聚合和存储统计信息的处理的流程图。首先,矢量算术单元中的八个统计信息获取单元st_ac各自输出指示中间数据的正数的最左置位或负数的最左零位的位置的位模式,该中间数据是整数算术单元int通过执行每个层的算术运算而输出的(s170)。后面将描述位模式。
接下来,统计信息聚合器st_agr_1将由八个int输出的八位模式的每个位中的“1”相加以对其进行聚合(s171)。
此外,统计信息聚合器st_agr_2将在s171中通过加法和聚合而获得的值与在统计信息寄存器文件st_reg_fl中的统计信息寄存器的值相加,并且将结果值存储在统计信息寄存器中(s172)。
每当生成中间数据时,重复执行上述s170、s171和s172的处理,该中间数据是由矢量算术单元中的八个元件el0至el7对每个层执行的算术运算的结果。
在预训练中,当针对一个(或多个)小批量中的多个中间数据完成了上述获取、聚合和存储统计信息的处理时,在统计信息寄存器中生成指示一个小批量中的中间数据的正数的最左置位或负数的最左零位的直方图的各个仓的值的统计信息。因此,针对每个位获得一个小批量中的中间数据中的正数的最左置位或负数的最左零位的位置的和。根据统计信息,调整每个中间数据片段的小数点位置。
另一方面,在训练中,针对k个小批量中的多个中间数据获取统计信息,并且基于所获取的统计信息调整每个中间数据的小数点位置。
统计信息的获取
图19是示出统计信息获取单元st_ac的逻辑电路示例的图。图20是示出由统计信息获取单元获取的运算输出数据的位模式的图。统计信息获取单元st_ac接收从整数算术单元int输出的n位(n=40)中间数据的输入,in[39:0](例如,在前向传播处理中的卷积算术运算的运算输出数据、在后向传播处理中的误差或权重的更新差),并且输出位模式输出,out[39:0],其中正数的最左置位或负数的最左零位的位置用“1”表示而其他位用“0”表示。
如图20所示,统计信息获取单元st_ac将输出out[39:0]作为位模式输出,其中针对正数的最左置位或负数的最左零位的位置设置为“1”(与符号位不同的1或0),并且针对作为中间数据的输入in[39:0]中的其他位置设置为“0”。然而,当输入in[39:0]的全部位与符号位相同时,最高有效位out[39]被异常设置为“1”。图22示出了统计信息获取单元st_ac的真值表。
根据真值表,前两行是下述示例,其中输入in[39:0]的全部位与符号位“1”或“0”相匹配,而输出out[39:0]的其最高有效位out[39]为“1”(0x8000000000)。接下来两行是下述示例,其中输入in[39:0]的第38位in[38]与符号位“1”或“0”不同,并且输出out[39:0]的第38位out[38]为“1”而其他位为“0”。最后两行是下述示例,其中输入in[39:0]的第0位in[0]与符号位“1”或“0”不同,并且输出out[39:0]的第0位out[0]为“1”而其他位为“0”。
图19所示的逻辑电路如下检测正数的最左置位的位置或负数的最左零位的位置。首先,当符号位in[39]和位in[38]不匹配时,异或门38的输出变为“1”并且输出out[38]变为“1”。当异或门38的输出变为“1”时,其他输出out[39]和out[38:0]通过逻辑和或门37至或门0、逻辑乘积与门37至与门0和反相门inv变为“0”。
当符号位in[39]与in[38]匹配但与in[37]不匹配时,异或门38的输出变为“0”,异或门37的输出变为“1”,并且输出out[37]变为“1”。当异或门37的输出变为“1”时,其他输出out[39:38]和out[36:0]通过逻辑和或门36至或门0、逻辑乘积与门36至与门0和反相门inv变为“0”。在下文中同样适用。
如从图19和图20可以理解,统计信息获取单元st_ac将包括与作为运算输出的中间数据的符号位(正数的最左置位或负数的最左零位)不同的最高有效位“1”或“0”的位置的分布信息作为位模式输出。
统计信息的聚合
图21是示出统计信息聚合器st_agr_1的逻辑电路示例的图。图22是描绘统计信息聚合器st_agr_1的运算的图。统计信息聚合器st_agr_1接收由矢量算术单元获取的八个统计信息,位模式bp_0至bp_7的输入,并且输出通过将八个位模式的每个位中的“1”相加而获得的out0至out39。例如,位模式bp_0至bp_7各自为40位,并且out0至out39各自为4位。
如图21的逻辑电路所示,统计信息聚合器st_agr_1将在由矢量算术单元的统计信息获取电路st_ac获取的位模式bp_0至bp_7的每个位中的“1”输入到对应的加法电路sgm_0至sgm_39中之一,并且将加法结果作为输出out0至out39输出。输出out0至out39各自表示为图22所示的输出。每个输出具有log2(元素数=8)+1位,使得可以为40位中的每一个计数具有“1”的元素数,并且当具有“1”的元素数为8时,out[39:0]的每个输出具有4(=3+1)位。
统计信息聚合器st_agr_1可以原样输出由标量算术单元中的统计信息获取电路st_ac获取的一个位模式bp。为此,提供了各自选择加法电路sgm_0至sgm_39的对应输出或标量算术单元的位模式的选择器sel。
图23是示出第二统计信息聚合器st_agr_2和统计信息寄存器文件st_reg_fl的示例的图。第二统计信息聚合器st_agr_2将已经由第一统计信息聚合器st_agr_1聚合为对应于各个位的输出out0至out39的值加至统计信息寄存器文件st_reg_fl中的一个寄存器组strn_39至strn_0的值以进行存储。
统计信息寄存器文件st_reg_fl包括例如八组40个32位寄存器strn_39至strn_0(n=0至7)。因此,统计信息寄存器文件st_reg_fl可以将各自具有40个仓数的八种类型的直方图存储在其中。假设要聚合的统计信息被存储在40个32位寄存器str0_39至str0_0中,其中n=0。第二统计信息聚合器st_arg_2包括加法器add_39至add_0,其将由第一统计信息聚合器st_agr_1聚合的聚合值in[39:0]中的每一个与存储在40个32位寄存器str0_39至str0_0中的对应的累加值中之一相加。加法器add_39至add_0的输出分别被重新存储在40个32位寄存器str0_39至str0_0中。因此,目标直方图的仓中的采样数被存储在40个32位寄存器str0_39至str0_0中。
利用图17、图19、图21和图23所示的算术单元或电路中设置的统计信息获取单元或电路st_ac和统计信息聚合器或聚合电路st_agr_1和st_agr_2的硬件电路,可以获取在dnn中的每个层中进行运算的中间数据的正数的最左置位的位置或负数的最左零位的位置(有效位的最高有效位的位置)的分布(在直方图的仓的采样数)。
利用dnn处理器的硬件电路,可以以上述相同的方式获取非零最低有效位的位置的分布以及正数的最左置位或负数的最左零位的位置的分布。此外,可以以相同的方式获取正数的最左置位或负数的最左零位的位置的最大值和非零最低有效位的位置的最小值。
由于可以通过dnn处理器的硬件电路获取统计信息,因此可以在工时略有增加的情况下实现在预训练中调整中间数据的小数点位置以及在训练中调整中间数据的小数点位置。
第二实施方式
在本实施方式的预训练中,临时确定dnn中的诸如权重和偏差的中间数据的小数点位置;在执行一次或多次小批量训练的同时获取中间数据的统计信息;基于统计信息将中间数据的小数点位置设定为最佳位置,以及使用相同的训练数据再次执行小批量训练。
由于在深度学习的初始阶段执行预训练,因此通过基于统计信息的小数点位置调整而调整的小数点位置可能在相对大的波动范围内变化。由于小数点位置的调整而导致的大的波动范围意味着使用调整之前的小数点位置通过算术处理而获得的定点数发生了上溢或下溢。
因此,在第二实施方式中,在预训练中确定由于小数点位置的调整而导致的波动范围是否大于允许范围。如果波动范围较大,则再次执行小批量训练。重复执行预训练直到dnn中的每个层的小批量训练的重复次数达到预定阈值。
图24是示出根据第二实施方式的由多个处理器进行的深度学习的流程图的图。与图10中的处理相同的处理由相同的处理标记来表示。
首先,主处理器31生成dnn中的诸如权重和偏差的参数的初始值(s70)。初始值为浮点数。接下来,主处理器确定输入数据和包括诸如权重和偏差的参数的中间数据的初始小数点位置,并且将初始小数点位置转换成定点数(到定点数的转换)(s80_1)。由于输入数据和参数是浮点数,因此主处理器基于指数部或者基于最大值和最小值来确定最佳定点位置。
然后,主处理器31调用用于定点dnn处理器的预训练程序(s80_2),并且响应于此,定点dnn处理器43_1执行预训练(s81)。通过定点算术运算进行的预训练包括例如执行一次或多次小批量训练,并且包括图9中的s81_1、s81_2和s81_3的处理。还使用动态定点数执行预训练,并且基于统计信息确定或调整中间数据的小数点位置。
在第二实施方式中,dnn处理器43_1向主处理器发送当在预训练s81中确定的小数点位置的波动范围超出预定的允许范围时执行的小批量训练的重复次数。当小批量训练的重复次数小于预定阈值时,主处理器再次调用预训练程序(s80_2)。响应于此,dnn处理器43_1再次执行预训练(s81)。另一方面,当小批量训练的重复次数达到预定阈值时,主处理器调用定点dnn处理器的训练程序(s71)。响应于此,定点dnn处理器43_1使用动态定点数执行训练(s5)。当小批量训练的重复次数小于预定阈值时,这意味中间数据的小数点位置的波动范围已减小,预训练结束并且然后处理进行到训练。
在训练中是否更新小数点位置的条件可以是使得调整之前的小数点位置与基于统计信息确定的小数点位置之间的差等于或大于预定允许值rmax。在预训练中是否更新小数点位置的条件可以是使得差等于或大于与用于训练的预定允许值不同的预定允许值rmax'。
图25是示出根据第二实施方式的预训练中的前向传播处理和后向传播处理的详细流程图的图。图25对应于上述图16,并且相同的处理由相同的处理标记表示。在图25中,部分地改进了图16的前向传播处理和后向传播处理。在图25中,前向传播处理s81_1中的s110_a、s113_a和s113_b的处理以及后向传播处理81_2中的s120_a、s123_a和s123_b的处理与图16中的处理不同,并且其他处理与图16中的处理相同。在下文中,将描述与图16不同的处理。
dnn处理器依次对每个层执行前向传播处理(s81_1)。在第一预训练中,dnn处理器确定中间数据(例如dnn中的诸如权重和偏差的参数以及每个层的输出数据)的临时小数点位置qn.m,并且在第二和随后预训练中设定前一次已确定的小数点位置qn.m(s110_a)。
在前向传播操作和统计获取s111以及基于统计信息确定小数点位置qn'.m's112之后,dnn处理器将确定之前和确定之后的小数点位置的波动范围设定为|m-m'|(s113_a),并且确定波动范围是否小于允许值(rmax')(s113_b)。如果波动范围不小于允许值(s113_b中为否),则dnn处理器将小数点位置qn.m更新为调整后的小数点位置qn'.m',并且再次执行前向传播处理操作(s114))。相反,如果波动范围小于允许值(s113_b中为是),则小数点位置qn.m不变并且不再执行前向传播处理操作。在完成前向传播处理s81_1之后,处理进行到后向传播处理s81_2。
后向传播处理s81_2中的s120_a、s123_a和s123_b的处理与前向传播处理中的s110_a、s113_a和s113_b的处理相同。
dnn处理器依次针对每个层将在后向传播处理中获得的诸如权重和偏差的参数的差更新值加上,从而更新权重和偏差(s81_3)。然后,dnn处理器将在前向传播处理和后向传播处理中执行的运算的重复次数输出至主处理器(s132)。
如上所述,根据本实施方式,定点处理器执行预训练,并且基于数据的统计信息确定预定数据的定点数的小数点位置。然后,在训练中,定点处理器利用在预训练中确定的定点位置的定点数多次执行小批量训练。即使在训练中,也基于数据的统计信息动态地调整预定数据的定点数的小数点位置。因此,对于预训练不需要使用浮点处理器,并且因此可以抑制浮点处理器的功耗。此外,当不需要执行其他浮点数算术运算时,可以减少浮点处理器的硬件。
根据本实施方式,在预训练中,基于dnn中的前向传播处理中针对每个层的算术运算和后向传播处理中针对每个层的算术运算中的数据的统计信息来确定数据的小数点位置,并且如果在预训练开始时确定的临时小数点位置与确定的小数点位置之间的差等于或大于允许值,则使用确定的小数点位置再次执行针对每个层的算术运算。这使得可以提高针对随后层的算术运算的精度。
根据实施方式,可以通过定点算术运算以高精度执行预训练。
- 还没有人留言评论。精彩留言会获得点赞!