一种基于异构多分支深度卷积神经网络的监控视频人头检测方法与流程
本发明涉及计算机视觉中智能视频监控技术领域,具体涉及一种基于异构多分支深度卷积神经网络的监控视频人头检测方法。
背景技术:
在大型的视频监控场所,如机场、火车站、停车场、银行等,摄像机数量很多,捕获的视频非常庞大,却给人们搜索有用信息带来了巨大的挑战。
目前,智能视频监控技术已被应用于对视频进行自动处理和分析以节省昂贵的人力资源和时间成本。监控摄像头中的人头检测是智能视频监控系统的一个关键技术,是后续很多视频识别和分析任务的基础,比如人头部属性识别、人流量检测和行人跟踪等。
在监控摄像头中,人头部尺寸往往较小,尤其是距离较远的行人,在遮挡和各种复杂的背景下,其检测难度较大,这种检测属于视频监控中的小目标检测范畴。目前已有的方法检测精度不高,误检和漏检较多。基于此,本发明提出了一种新的深度学习网络结构dense_yolo的小目标检测方法,用于精确地实现监控视频中的行人头部检测。与已有的方法相比,本发明所提出的方法通过融合不同结构主干网络之间的特征,获得更加抽象和丰富的特征表达,提高了检测效果,尤其对小尺度目标的检测效果,减少了误检和漏检。
技术实现要素:
本发明的目的是提供一种适用于摄像机网络中行人头部检测及视频监控中其他小目标检测、提高检测精度的基于异构多分支深度卷积神经网络的监控视频人头检测方法。
为了达到上述目的,本发明通过以下技术方案来实现:
一种基于异构多分支深度卷积神经网络的监控视频人头检测方法,包括如下步骤:
s1)数据增强
使用mixup方法对人头检测数据进行数据增强操作,使用线性插值的方法构建新的训练样本和标签来代替原样本和标签;
s2)人头部位检测
s2-1)构建卷积神经网络dense_yolo
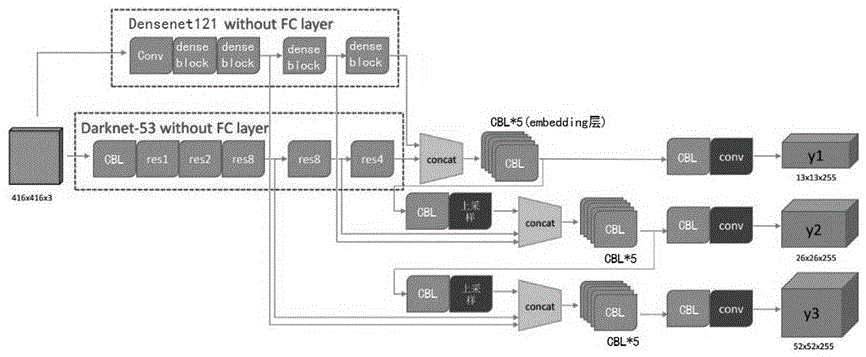
修改yolov3主干网络结构为双分支结构,其中一个分支以densenet121网络作为主干网络,去掉其最后一层fc层,另一个分支以darknet53作为主干网络,去掉其最后一层fc层;将densenet121的基础结构由cbl结构修改为brc结构,而darknet53分支的brc结构不作修改;
s2-2)特征图层次选择与融合
利用s2-1)中的双主干网络对增强后的训练数据进行训练;
将两个主干网络获得的特征图进行融合,得到三层特征图,对应的输入通道数分别为256、512和1024;
对最后一层特征图进行如下操作:首先,将它放进makeembedding层中,通过后面的5层cbl结构后通道数减少一半;然后,分成两条路径,一条路径通过3×3卷积升维到原先的维度,再通过一个1×1卷积得到最终的255维输出,另一条路径通过1×1卷积通道数降维至一半,再通过上采样层得到特征图和主干网络输入的下一层次特征图进行拼接;
以此类推,得到第二层、第三层的输出;这三个层次的输出共同构成最终的输出结果;
s2-3)行人头部目标框预测
从s2-2)得到的三个特征图分别通过µ×(4+1+c)个1×1卷积进行卷积预测,其中µ为预设边界框的数量,c为待预测的目标类别数;
预设边界框的尺寸可根据训练数据集通过聚类得到,根据网络预测得到的目标边框内包含目标的概率和目标框中心点偏移量以及宽和高,最终得到目标真实的边界框,实现对目标的准确定位。
本发明与现有技术相比,具有以下优点:
本发明一种基于异构多分支深度卷积神经网络的监控视频人头检测方法,不仅适用于摄像机网络中行人头部检测,也适用于视频监控中其他小目标检测。为了提高目标检测算法的检测精度,本发明对yolov3结构进行改造,将其主干网络修改为双主干网络结构,其中一个分支以densenet121网络为主干网络,去掉其最后的fc层,然后将其基础结构由cbl修改为brc结构;另外一个分支采用darknet53为主干网络,去掉其最后fc层,该分支的brc结构不作修改。本发明设计的双主干结构网络模型取名为dense_yolo网络,通过两个不同结构的主干网络提取的特征进行特征融合,提高了检测效果,减少了误检和漏检,适用于小目标检测,效果优于以darknet53作为主干网络的yolov3模型。
附图说明
图1是本发明一种基于异构多分支深度卷积神经网络的监控视频人头检测方法的dense_yolo网络结构示意图。
具体实施方式
下面结合附图,对本发明的实施例作进一步详细的描述。
一种基于异构多分支深度卷积神经网络的监控视频人头检测方法,包括如下步骤:
s1)数据增强
使用mixup方法对人头检测数据进行数据增强操作,使用线性插值的方法构建新的训练样本
其中,
s2)人头部位检测
s2-1)构建卷积神经网络dense_yolo
修改yolov3主干网络结构为双分支结构,其中一个分支以densenet121网络作为主干网络,去掉其最后一层fc层,另一个分支以darknet53作为主干网络,去掉其最后一层fc层;
为了减少训练难度,提高精度,将densenet121的基础结构由cbl(conv2d-bn-leakyrelu)结构修改为brc(bn-relu-conv)结构,而darknet53分支的brc结构不作修改;
本发明设计的双主干结构网络模型取名为dense_yolo网络,其效果优于原yolov3以darknet53作为主干网络的模型;yolov3是目标检测网络youonlylookoncev3:unified,real-timeobjectdetection;densenet121是密集连接卷积网络,即denselyconnectedconvolutionalnetworks,网络中使用了121个convolutionallayers;darknet53是一个较为轻型的完全基于c与cuda的开源深度学习框架,即darknet:opensourceneuralnetworksinc,使用了53个convolutionallayers;
s2-2)特征图层次选择与融合
利用s2-1)中的双主干网络对增强后的训练数据进行训练;
如图1所示,将两个主干网络获得的特征图进行融合,得到三层特征图
对最后一层特征图
以此类推,重复上述类似操作得到第二层的输出y2、第三层的输出y3;三个特征图
s2-3)行人头部目标框预测
从s2-2)得到的三个特征图
最终预测的目标框为:
根据网络预测得到的目标边框内包含目标的概率和目标框中心点偏移量以及宽和高,最终得到目标真实的边界框,实现对目标的准确定位。
以上所述仅是本发明优选实施方式,应当指出,对于本技术领域的普通技术人员,在不脱离本发明构思的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!