一种数据管理平台及数据管理方法与流程
本发明属于电子数据技术领域,尤其涉及一种数据管理平台及数据管理方法。
背景技术:
电子智能设备的应用越来越广泛,已经成为人们日常不可缺少的工具,如笔记本电脑、手机、平板电脑、智能手表等等。网络技术的发展进一步将电子智能设备的作用扩展至社会生活的方方面面。人们在使用电子智能设备产生了大量的数据,如何存储管理这些数据成为当前的技术热点。目前出现的数据管理平台功能单一,交互单调,很多都只有数据存储或数据统计功能。而且,目前的数据管理平台在面对海量数据的存储和处理时,效率较低。
技术实现要素:
本发明提供一种数据管理平台。所述数据管理平台接收并存储初始数据,并根据用户需求对所述初始数据进行处理以生成结果数据,并将所述结果数据反馈给所述用户,所述数据管理平台包括大数据处理平台模块以处理所述初始数据,所述大数据处理平台模块采用历史数据处理方式处理当前时间段之前的历史数据并存储历史数据处理结果,所述大数据处理平台模块采用大数据实时分析方式处理实时数据,并展示实时数据处理结果,其中,所述历史数据处理方式采用历史数据n-△n处理方式,所述历史数据n-△n处理方式中,n为当前累计时间,△n为当前时间最小单位;所述大数据实时分析方式采用实时数据m-△m处理方式,所述实时数据m-△m处理方式中,m为全部数据,△m为热数据,m-△m为存档数据。
本发明另一方面提供一种数据管理方法,应用于包括大数据处理平台模块的数据管理平台。所述数据管理方法包括:接收初始数据;存储初始数据;分析所述初始数据;根据用户需求将分析后的结果数据展示给所述用户;其中,所述大数据处理平台模块采用历史数据处理方式处理当前时间段之前的历史数据并存储历史数据处理结果,所述大数据处理平台模块采用大数据实时分析方式处理实时数据,并展示实时数据处理结果,其中,所述历史数据处理方式采用历史数据n-△n处理方式,所述历史数据n-△n处理方式中,n为当前累计时间,△n为当前时间最小单位;所述大数据实时分析方式采用实时数据m-△m处理方式,所述实时数据m-△m处理方式中,m为全部数据,△m为热数据,m-△m为存档数据。
本发明提供的数据处理方法采用n-△n的方式处理历史数据以及m-△m方式处理实时数据,便于批量获取指定数据,方便数据查询和数据存储,能提高数据处理的时效性,同时采用支持向量机对初始数据进行分类处理操作,在实现类标签与数据的映射关系的同时进行至少一个特征维度的权重初始化,可以提高实时数据处理的准确性。
附图说明
图1为本发明实施例提供的数据管理平台示意图。
图2为所述数据管理平台部分模块示意图。
图3为所述数据管理平台更为具体的模块示意图。
图4为本发明实施例提供的数据管理方法的流程示意图。
图5为所述数据管理方法的数据存储的流程示意图。
图6为所述数据管理方法的数据爬取的流程示意图。
图7为所述数据管理方法的数据打标签的流程示意图。
具体实施方式
为使本发明的目的、特征、优点能够更加的明显和易懂,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而非全部实施例。基于本发明中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
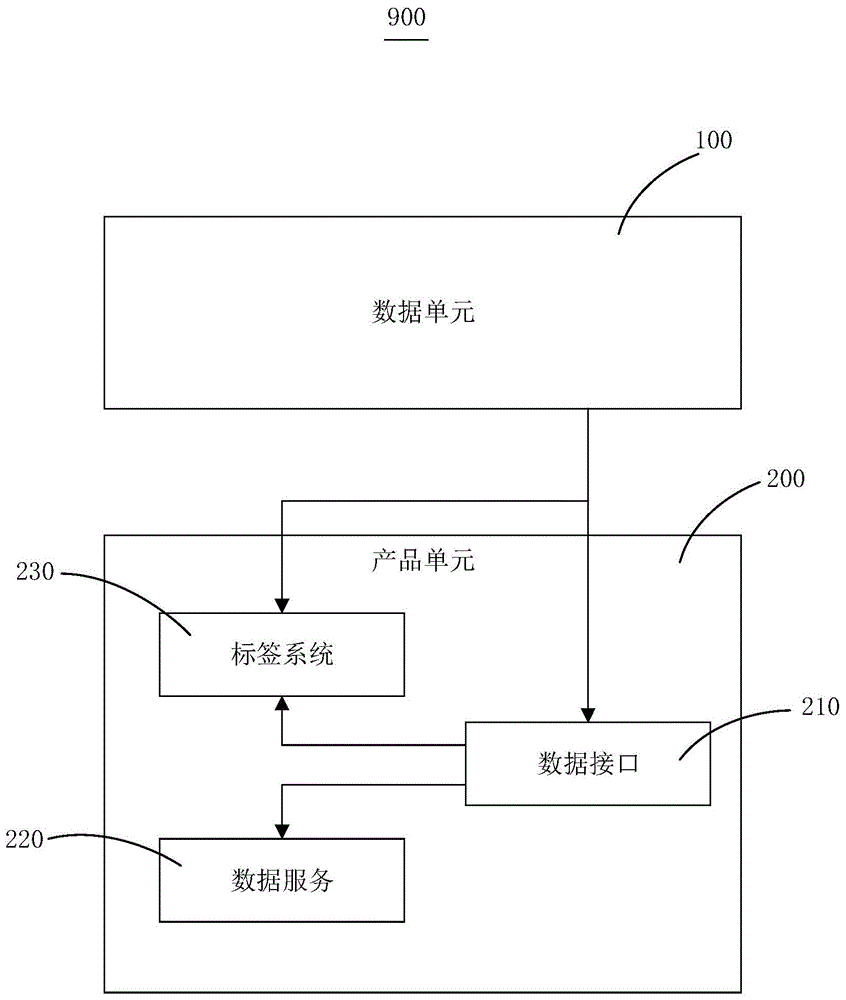
如图1所示,采用本发明实施例提供的一种数据管理平台900。数据管理平台900接收并存储初始数据,并根据用户需求对所述初始数据进行处理以生成结果数据,并将所述结果数据反馈给所述用户。数据管理平台900包括数据单元100与产品单元200。其中,数据单元100接收并存储初始数据,产品单元200根据用户需求对初始数据进行处理以生成结果数据,并将结果数据反馈给用户。
如图2所示,数据单元100包括爬虫平台模块110、数据系统模块120、rpc服务模块130、数据接收平台模块140及大数据处理平台模块150。爬虫平台模块110从数据源自动爬取初始数据,并进行处理传送给数据系统模块120。数据系统模块120将初始数据进行分类,并经由rpc服务模块130提供初始数据给数据接收平台模块140。大数据处理平台模块150接收来自数据接收平台模块140的数据并进行相应处理。大数据处理平台模块150将初始数据缓冲到数据集群,并进行校验分析后进行存储。
图1中产品单元200还包括数据接口模块210、数据服务模块220和标签系统模块230。数据接口模块接收来自数据单元100的初始数据并分析初始数据。数据服务模块220根据用户需求将分析后的结果数据展示给用户。标签系统模块230基于数据平台的数据提取标签,并对结果数据打标签。
图3给出更为具体的示意图。爬虫平台模块110从数据源爬取初始数据,经数据处理后传送至数据系统模块120。数据系统模块120将初始数据区分为交通数据、小区商圈poi(pointofinterest,兴趣点)数据、天气数据、路网数据等分类数据。rpc(remoteprocedurecallprotocol,远程过程调度协议)服务模块130经由交通服务、小区商圈poi服务、天气服务、路网服务将分类数据传送至数据接收平台模块140。数据接收平台模块140对经由kafkacluster(卡夫卡集群,图3中用缩写kc表示)和sparkstreaming(图3中用缩写ss表示)的数据进行数据验证,将验证通过的数据传至hbasecluster(图3中用缩写hc表示),将验证失败的异常数据一方面通过统计服务后展示给客户,另一方面经异常数据库后进行数据修复,之后也传至hbasecluster。大数据处理平台模块150包括存储平台、数据收集平台、实时计算平台、离线计算平台。大数据处理平台模块150对来自数据接收平台模块140的数据进行数据清洗过滤,并对未通过清洗过滤的异常数据进行数据修复后,得到熟数据。其中,数据存储平台其一将数据按照类别(数据质量、数据种类、数据频率等)进行分类存储,便于数据查询和分析,更加方便管理和升级;其二对于大数据进行缓冲存储,通过采用缓冲机制以降低单位时间内数据量巨大造成的冲击。
在数据处理方面,大数据处理平台模块150采用历史数据处理方式处理当前时间段之前的历史数据并存储历史数据处理结果,所述大数据处理平台模块采用大数据实时分析方式处理实时数据,并展示实时数据处理结果。其中,所述历史数据处理方式采用历史数据n-△n处理方式,所述历史数据n-△n处理方式中,n为当前累计时间,△n为当前时间最小单位;所述大数据实时分析方式采用实时数据m-△m处理方式,所述实时数据m-△m处理方式中,m为全部数据,△m为热数据,m-△m为存档数据。
当采用历史数据n-△n的方式处理历史数据时,针对n-△n的数据,也就是过去式数据进行分析、分类、保存,数据的存储均按照类别索引算法,该算法具有高效海量和高可用等特点,每段数据均有自己的序列索引,每个索引均按照时间、空间、分类标签等属性设置,既方便数据查询又方便数据存储。在历史数据处理中采用n-△n的方式,能提高处理的时效性。
而针对实时性要求较高的模型,可采用大数据实时分析模块进行处理,以实时展示数据。在大数据实时分析方式中,所述实时数据m-△m处理方式针对存档数据几乎没有再索引可能性,但是仍然有很大的数据分析价值性,因此需要建立分析索引,其采用的分析索引算法的索引结构有时间段和基础分类标签,便于批量获取指定数据。在实时数据处理中采用m-△m的方式,也能提高处理的时效性。
其中,所述大数据实时分析方式进一步包括实时抽样处理及实时数据分析,所述实时抽样处理针对海量数据进行分、时、天三个维度的实时抽样分析,所述实时数据分析对数据的标签画像进行实时分析,对失效的进行清除或更新。因此,大数据处理平台模块150可以提供百亿的数据毫秒级分析效率,提供准实时的数据分析报表和数据分析报告,并且通过实时数据分析可以保证大数据分析的准确性和时效性。针对大数据实时处理方式,在m-△m方式提高处理时效性的同时,大数据处理平台模块150还采取以下方式以保证数据处理准确性。
大数据处理平台模块150将源数据进行支持向量机(supportvectormachine,svm)划分,从而实现数据的分类处理,以将数据单元100的数据与预先设定的一系列类标签进行多对多的映射;与此同时,根据源数据的时间、地域、位置等至少一个特征维度进行权重的初始化。当然,该权重是可以动态更新的。这样,通过类标签的设定,创新性的增加了数据单元100与产品单元200之间的沟通体系,提高了数据的活性,同时也让数据与标签以及原始数据之间的联系更加紧密,提高了数据索引的准确性。对于匿名标签而言,对所述随机组合的源数据进行分类处理,得到多个类数据,包括:利用第一特定分类算法将所述随机组合的源数据按照不同的特征维度进行一次分类处理,得到一次分类处理结果;采用第二特定分类算法进行特征维度的细化的方式来对一次分类处理结果进行二次分类处理,得到多个类数据。其中,所述第一特定分类算法包括如下算法至少之一:聚类、分类树、rd森林。相应地确定每一个类数据对应类标签的权重,包括:在采用第二特定分类算法进行每一个特征维度的细化的方式来对一次分类处理结果进行二次分类处理的过程中,根据多个类数据中每一个类数据的占比来对每一个类数据对应类标签的权重进行确定。其中,所述第二特征分类算法包括如下算法至少之一:贝叶斯、逻辑回归训练。
在一应用示例中,可以以第一特定分类算法和第二特定分类算法分别为聚类和贝叶斯来实现对源数据的分类处理。总体分类思路为:将数据按照不同的特征维度进行聚类,如:地域维度、时间维度、工作维度、住宅维度等等;之后再使用贝叶斯进行每个特征维度的细化和初始化每个细化之后的匿名标签权重。举例来说,步骤1,首先根据坐标向量将所有的数据进行系列化和归一化,主要是方便后期计算相似度和计算的复杂度;步骤2,计算数据向量之间的相似度,根据相似度进行聚类,每一类独立为一个匿名标签,然后对每个类进行内部在分类,以此类推,直到每个类内部的元素差距足够小(默认会配置相似度进行判断);步骤3,将时间段粗暴的划分为24个段,1小时为1个时间区间,针对每个区间执行步骤2,将每个标签的权重进行计算,计算的方法有很多,这里给一种比较好理解的:将每个时间区间的相似的类进行元素个数求和,记为:s;每个时间区间的对应的类的元素个数记为:e;权重为:e/s*100%;步骤4,对所有的标签执行相同的过程得到每个标签的20权重。这样的操作方式可以进一步提高实时数据处理的准确性。
数据接口模块210包括数据层211、基础api(applicationprogramminginterface,应用程序编程接口)212、进阶api213、高阶api214、基础模型215与高级模型216。其中基础模型215针对基础性同属数据模型,而高级模型216针对定制业务需求。数据服务模块220包括用户标签服务、电子围栏、ubi+(usagebasedinsurance,基于驾驶行为的保险)服务、安全驾驶辅助及设备行为分析。标签系统模块230包括数据抽取、标签数据聚合、数据标签化及标签库。
图4所示为本发明实施例提供的一种数据管理方法的流程示意图。所述数据管理方法包括以下步骤:
步骤310,数据单元100接收初始数据。
步骤312,数据单元100存储初始数据。
步骤314,产品单元200接收来自数据单元100的初始数据并分析初始数据。
步骤316,产品单元200根据用户需求将分析后的结果数据展示给用户。
其中,数据单元100的大数据处理平台模块150采用历史数据处理方式处理当前时间段之前的历史数据并存储历史数据处理结果,所述大数据处理平台模块采用大数据实时分析方式处理实时数据,并展示实时数据处理结果,其中,所述历史数据处理方式采用历史数据n-△n处理方式,所述历史数据n-△n处理方式中,n为当前累计时间,△n为当前时间最小单位;所述大数据实时分析方式采用实时数据m-△m处理方式,所述实时数据m-△m处理方式中,m为全部数据,△m为热数据,m-△m为存档数据。所述历史数据n-△n处理方式针对过去式数据进行分析、分类、保存,其中所述保存操作采用类别索引算法。所述类别索引算法每段数据均有对应的序列索引,每个序列索引均按照时间、空间、分类标签设置。所述实时数据m-△m处理方式针对所述存档数据建立分析索引算法,所述分析索引算法中的索引结构包括时间段及基础分类标签。
图5所示为所述数据管理方法的数据存储的流程示意图,其包括以下步骤:
步骤410,将初始数据缓冲到数据集群。
步骤412,对初始数据进行校验分析,若校验失败,程序进入步骤414;若校验成功,程序进入步骤416。
步骤414,对初始数据进行修复处理。
步骤416,对初始数据进行分批存储。
图6所示为所述数据管理方法的数据爬取的流程示意图,其包括以下步骤:
步骤510,确定数据源。
步骤512,自动化爬取初始数据。
步骤514,对初始数据进行处理和分类。
步骤516,对初始数据进行存储。
图7所示为所述数据管理方法的数据打标签的流程示意图,其包括以下步骤:
步骤610,通过api提起初始数据的标签。
步骤612,对结果数据打标签。
步骤614,根据用户权限提供相应的特定服务。
采用本方案的数据管理平台,可提供更为丰富的功能,包括数据处理、模型生成、服务配置等。每一部分处理数据的功能明确,数据规则明确。此外,自定义模型和服务,可以更方便客户使用,方便数据的分析和挖掘。动态模型和服务,可以实时控制模型生命周期和服务的权限。本发明提供的数据处理方法采用n-△n的方式处理历史数据以及m-△m方式处理实时数据,便于批量获取指定数据,方便数据查询和数据存储,能提高数据处理的时效性,同时采用支持向量机对初始数据进行分类处理操作,在实现类标签与数据的映射关系的同时进行至少一个特征维度的权重初始化,可以提高实时数据处理的准确性。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或隐含地包括至少一个该特征。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!