文字检测方法及系统与流程
本公开涉及文字识别技术领域,具体地,涉及一种文字检测方法及系统。
背景技术:
自然场景文字检测是指在复杂背景中检测到文字区域,并用包围框对文字区域进行标识。自然场景文字检测的结果在自动驾驶、机器人等领域有广泛应用。自然场景中的文字检测面临分辨率低、背景复杂、字体尺寸多变等困难,使得传统文字检测技术的实际应用效果差。
随着深度学习技术的发展,基于深度学习的自然场景文字检测技术得到了显著提升,该检测技术虽然能够检测任意形状的文字,但是检测结果中包含较多的假阳性检测,并且受文字尺寸多样性问题的影响,其检测精度有待提升。
技术实现要素:
(一)要解决的技术问题
有鉴于此,本公开提供了一种能够提升任意形状场景文字检测精度的文字检测方法及系统。
(二)技术方案
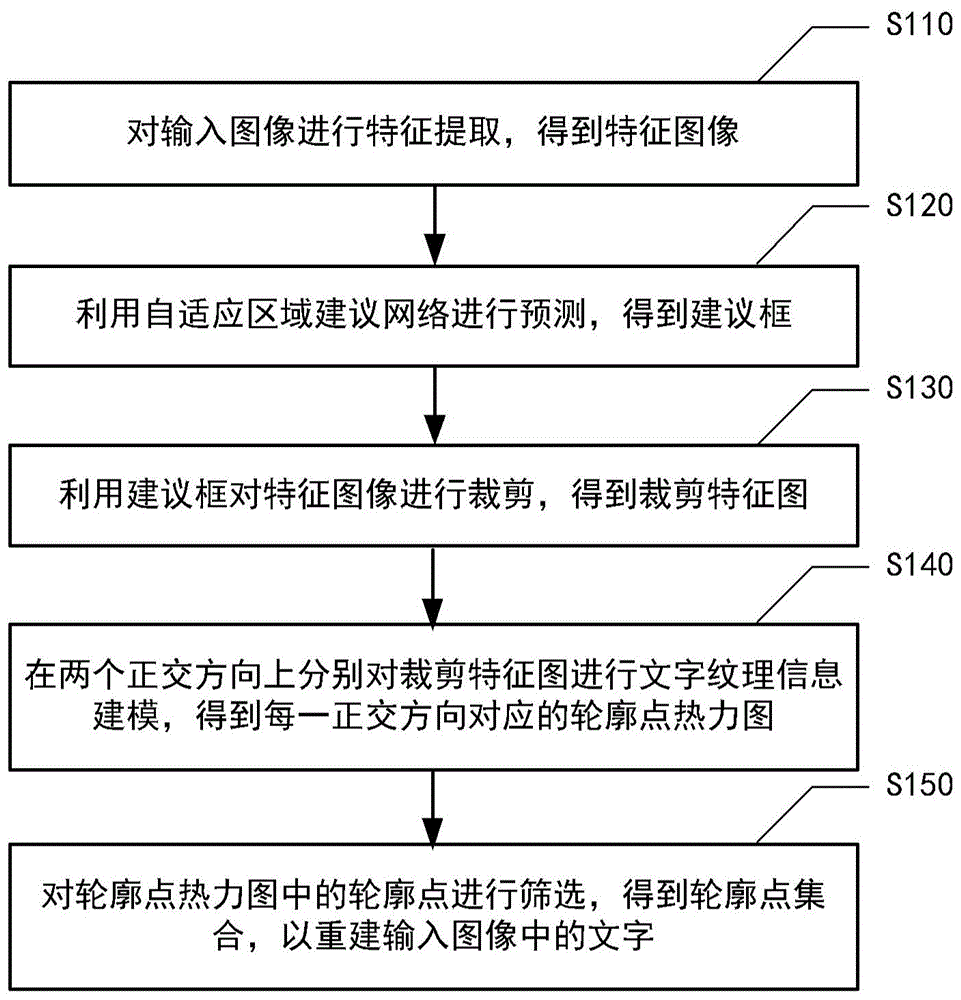
本公开提供了一种文字检测方法,包括:对输入图像进行特征提取,得到特征图像;利用自适应区域建议网络进行预测,得到建议框;利用所述建议框对所述特征图像进行裁剪,得到裁剪特征图;在两个正交方向上分别对所述裁剪特征图进行文字纹理信息建模,得到每一所述正交方向对应的轮廓点热力图;对所述轮廓点热力图中的轮廓点进行筛选,得到轮廓点集合,以重建所述输入图像中的文字。
可选地,所述利用自适应区域建议网络进行预测,得到建议框,包括:利用所述自适应区域建议网络对预置锚框的点进行局部偏置预测,得到相应的预测点;根据所述预测点确定所述建议框。
可选地,所述两个正交方向为水平方向和垂直方向,所述在两个正交方向上分别对所述裁剪特征图进行文字纹理信息建模,包括:根据第一卷积核,建立所述裁剪特征图在所述水平方向上的第一文字纹理信息模型;根据第二卷积核,建立所述裁剪特征图在所述垂直方向上的第二文字纹理信息模型。
可选地,所述第一卷积核的尺寸为1×k,所述第二卷积核的尺寸为k×1,k不大于所述裁剪特征图的尺寸,本公开中k=3。
可选地,所述方法还包括:根据所述裁剪特征图,利用微调网络对所述建议框进行调整,得到调整后的建议框;利用调整后的建议框对所述特征图像进行裁剪,得到调整后的裁剪特征图;对调整后的裁剪特征图进行上采样,得到上采样特征图。
可选地,所述在两个正交方向上分别对所述裁剪特征图进行文字纹理信息建模,包括:在两个正交方向上分别对所述上采样特征图进行文字纹理信息建模。
可选地,所述在两个正交方向上分别对所述裁剪特征图进行文字纹理信息建模,包括:
分别利用所述两个正交方向上的文字纹理信息感知网络对所述裁剪特征图进行文字纹理信息建模;
在对输入图像进行特征提取之前,所述方法还包括:
利用随机梯度下降法,根据损失函数对所述自适应区域建议网络、文字纹理信息感知网络、微调网络进行训练,所述损失函数为:
l=larpn+λhcplhcp+λvcplvcp+λboxclasslboxclass+λboxreglboxreg
其中,l为所述损失函数,larpn为所述自适应区域建议网络的损失函数,lhcp为一正交方向上的文字纹理信息感知网络的损失函数,lvcp为另一正交方向上的文字纹理信息感知网络的损失函数,lboxclass、lboxreg为所述微调网络的损失函数,λhcp为所述一正交方向上的文字纹理信息感知网络的平衡参数,λvcp为所述另一正交方向上的文字纹理信息感知网络的平衡参数,λboxclass、λboxreg为所述微调网络的平衡参数。
可选地,所述对所述轮廓点热力图进行筛选,得到轮廓点集合,包括:利用非极大值抑制法滤除所述轮廓点热力图中的背景像素点;根据预设阈值对所述轮廓点热力图进行筛选,得到所述轮廓点集合。
可选地,所述根据预设阈值对所述轮廓点热力图进行筛选,得到所述轮廓点集合,包括:筛选出在所述两个正交方向对应的轮廓点热力图中的响应值均大于所述预设阈值的像素点,以形成所述轮廓点集合。
本公开另一方面提供了一种文字检测系统,包括:提取模块,用于对输入图像进行特征提取,得到特征图像;预测模块,用于利用自适应区域建议网络进行预测,得到建议框;裁剪模块,用于利用所述建议框对所述特征图像进行裁剪,得到裁剪特征图;建模模块,用于在两个正交方向上分别对所述裁剪特征图进行文字纹理信息建模,得到每一所述正交方向对应的轮廓点热力图;筛选模块,用于对所述轮廓点热力图中的轮廓点进行筛选,得到轮廓点集合,以重建所述输入图像中的文字。
(三)有益效果
本公开提供的文字检测方法及系统,通过设计自适应区域建议网络,能够更好地适应文字的尺度变化,在正交方向上进行文字纹理信息建模,能够抑制假阳性的轮廓点,从而有效地解决了文字尺度变化和假阳性预测的问题,提升了任意形状场景文字检测的精度。
附图说明
图1示意性示出了本公开实施例提供的文字检测方法的流程图;
图2示意性示出了本公开实施例提供的文字检测方法中预测裁剪框的示意图;
图3示意性示出了本公开实施例提供的文字检测方法中文字纹理信息建模的示意图;
图4示意性示出了本公开实施例提供的文字检测系统的结构框图;
图5示意性示出了本公开实施例提供的微调网络的示意图。
具体实施方式
为使本公开的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本公开进一步详细说明。
图1示意性示出了本公开实施例提供的文字检测方法的流程图。
参阅图1,同时结合图2-图3,对图1所示方法进行详细说明。如图1所示,该文字检测方法包括操作s110-操作s150。
操作s110,对输入图像进行特征提取,得到特征图像。
本实施例中,利用深度神经网络(deepneuralnetworks,dnn)进行文字检测,该深度神经网络包括resnet50特征提取网络、自适应区域建议网络、微调网络、水平方向上的文字纹理信息感知网络、垂直方向上的文字纹理信息感知网络等。
在操作s110之前,应对该深度神经网络进行训练。具体地,例如采用随机梯度下降法(stochasticgradientdescent,sgd)进行端到端的训练,该深度神经网络整体的损失函数l为:
l=larpn+λhcplhcp+λvcplvcp+λboxclasslboxclass+λboxreglboxreg
其中,larpn为自适应区域建议网络的损失函数,lhcp为一正交方向(例如水平方向)上的文字纹理信息感知网络的损失函数,lvcp为另一正交方向(例如垂直方向)上的文字纹理信息感知网络的损失函数,lboxclass、lboxreg为微调网络的损失函数,λhcp为一正交方向上的文字纹理信息感知网络的平衡参数,λvcp为另一正交方向上的文字纹理信息感知网络的平衡参数,λboxclass、λboxreg为微调网络的平衡参数。
进一步地,自适应区域建议网络的损失函数larpn为:
larpn=larpnclass+larpnreg
其中,larpnclass为分类损失函数,larpnreg为回归损失函数,pi为预置的锚框是目标框(即建议框)的概率,lcls为交叉熵损失函数,npos为正锚框的个数,intersection为锚框与目标框的交集,union为锚框与目标框的并集,锚框与目标框的交并比大于0.5时,
水平方向上的文字纹理信息感知网络的损失函数lhcp和垂直方向上的文字纹理信息感知网络的损失函数lvcp为:
其中,yi为轮廓点的标签,qi为轮廓点的预测值,nneg为预测为背景像素点的个数,npos为预测为轮廓点的个数。
微调网络的损失函数lboxclass、lboxreg为:
其中,pi1为box分支中锚框是目标框的概率,lcls为交叉熵损失函数,npos1为box分支和标签正确匹配预测框的个数,box分支中锚框与目标框的交并比大于0.5时,
该深度神经网络训练过程中,选择初始学习率为0.0025,当训练次数达到120000-160000次时,学习率下降为原来的0.1倍,本实施例中例如训练180000次,此时该深度神经网络整体的损失函数l满足需求,即可利用该训练好的深度神经网络进行文字检测。
根据本公开的实施例,利用resnet50特征提取网络对输入图像进行特征提取,得到特征图像。
操作s120,利用自适应区域建议网络进行预测,得到建议框。
根据本公开的实施例,操作s120包括子操作s120a和子操作s120b。
子操作s120a,利用自适应区域建议网络对预置锚框的点进行局部偏置预测,得到相应的预测点。具体地,得到的预测点为:
其中,n为预置锚框中点的数量,xl′为第l个预测点的横坐标,yl′为第l个预测点的纵坐标,xl为预置锚框中第l个点的横坐标,yl为预置锚框中第l个点的纵坐标,ωc为预置锚框的长,hc为预置锚框的宽,δxl为自适应区域建议网络输出的预置锚框中第l个点的横坐标偏移量,δyl为自适应区域建议网络输出的预置锚框中第l个点的纵坐标偏移量。
参阅图2,将预置锚框中点的数量n设置为9,表示一个中心点和八个边界点(包括左上点、中上点、右上点、右中点、右下点、中下点、左下点以及左中点)。
子操作s120b,根据预测点确定建议框。具体地,通过最大值最小值筛选得到四个最值坐标(包括最小横坐标、最小纵坐标、最大横坐标以及最大纵坐标)对应的预测点来确定建议框,如图2所示。用这四个最值坐标表示建议框(proposal)位置:
本实施例中,得到的建议框的数量为一个及以上。预测得到多个建议框,可以进一步提高文字检测的精度。
操作s130,利用建议框对特征图像进行裁剪,得到裁剪特征图。
本实施例中,建议框的数量为多个时,分别利用每个建议框裁剪特征图像,得到多个裁剪特征图,对这多个裁剪特征图进行归一化处理,以得到多个相同尺寸大小的裁剪特征图。
根据本公开的实施例,操作s130之后,该文字检测方法还包括:根据裁剪特征图,利用微调网络对建议框进行调整,得到调整后的建议框;利用调整后的建议框对特征图像进行裁剪,得到调整后的裁剪特征图。
参阅图5,利用微调网络对裁剪特征图进行计算,输出调整建议框的调整参数,利用该调整参数调整建议框,调整后的建议框为:
其中,x为调整后的建议框的中心点横坐标,y为调整后的建议框的中心点纵坐标,w为调整后的建议框的宽度,h为调整后的建议框的高度,xc为调整前的建议框的中心点横坐标,yc为调整前的建议框的中心点纵坐标,wc为调整前的建议框的宽度,hc为调整前的建议框的高度,xc、yc、wc、hc可以根据建议框(proposal)的最值坐标计算得到,t1、t2、t3、t4为微调网络输出的调整参数。
进一步地,该文字检测方法还包括:对调整后的裁剪特征图进行上采样,得到上采样特征图。上采样特征图的尺寸大于调整后的裁剪特征图的特征尺寸。
操作s140,在两个正交方向上分别对裁剪特征图进行文字纹理信息建模,得到每一正交方向对应的轮廓点热力图。
具体地,在两个正交方向上分别对调整后的上采样特征图进行文字纹理信息建模,得到每一正交方向对应的轮廓点热力图。
参阅图3,该两个正交方向为水平方向和垂直方向,操作s140包括子操作s140a和子操作s140b。
子操作s140a,根据第一卷积核,建立裁剪特征图在水平方向上的第一文字纹理信息模型。具体地,根据第一卷积核,滑动建立调整后的上采样特征图在水平方向上的第一文字纹理信息模型。第一卷积核的尺寸为1×k,k大于0且不大于裁剪特征图的尺寸,k例如为3。
子操作s140b,根据第二卷积核,建立裁剪特征图在垂直方向上的第二文字纹理信息模型。具体地,根据第二卷积核,滑动建立调整后的上采样特征图在垂直方向上的第二文字纹理信息模型。第二卷积核的尺寸为k×1。
进一步地,利用sigmoid函数对第一文字纹理信息模型和第二文字纹理信息模型进行归一化处理,以得到水平方向的轮廓点热力图hmap以及得到垂直方向的轮廓点热力图vmap。
操作s150,对轮廓点热力图中的轮廓点进行筛选,得到轮廓点集合,以重建输入图像中的文字。
本实施例中,利用轮廓点再评分算法对轮廓点热力图进行筛选,以得到同时在上述两个轮廓点热力图中具有高响应值的像素点,形成轮廓点集合。
根据本公开的实施例,操作s150包括子操作s150a和子操作s150b。
子操作s150a,利用非极大值抑制法滤除轮廓点热力图中的背景像素点。具体地,例如利用1×3的滑窗对水平方向的轮廓点热力图进行处理,利用3×1的滑窗对垂直方向的轮廓点热力图进行处理,并输出当前窗口中最大的像素点,其余像素点受到抑制。
子操作s150b,根据预设阈值对轮廓点热力图进行筛选,得到轮廓点集合。具体地,对非极大值抑制后的轮廓点热力图中每个像素点位置进行遍历,筛选出在水平方向和垂直方向对应的轮廓点热力图中的响应值均大于预设阈值的像素点,以形成轮廓点集合。预设阈值例如为0.5。
进一步地,根据筛选出的轮廓点集合重建输入图像中的文字区域,从而检测出输入图像中的文字。
本公开实施例中,利用该文字检测方法对大量任意形状场景下的文字进行检测,检测结果均表明,该文字检测方法具有非常好的检测性能。例如该文字检测方法在icdar2015数据集上的召回率、准确率、f值分别为86.1%、87.6%、86.9%,fps为3.5;在total-text数据集上的召回率、准确率、f值分别为83.9%、86.9%、85.4%,fps为3.8;在ctw1500数据集上的召回率、准确率、f值分别为84.1%、83.7%、83.9%,fps为4.5。
图4示意性示出了本公开实施例提供的文字检测系统的结构框图。
本公开实施例还提供了一种文字检测系统。该文字检测系统400包括提取模块410、预测模块420、裁剪模块430、建模模块440以及筛选模块450。
提取模块410例如可以执行操作s110,用于对输入图像进行特征提取,得到特征图像。
预测模块420例如可以执行操作s120,用于利用自适应区域建议网络进行预测,得到建议框。
裁剪模块430例如可以执行操作s130,用于利用建议框对特征图像进行裁剪,得到裁剪特征图。
建模模块440例如可以执行操作s140,用于在两个正交方向上分别对裁剪特征图进行文字纹理信息建模,得到每一正交方向对应的轮廓点热力图。
筛选模块450例如可以执行操作s150,用于对轮廓点热力图中的轮廓点进行筛选,得到轮廓点集合,以重建输入图像中的文字。
本实施例未尽之细节,请参阅前述图1-图3所示实施例中的文字检测方法。
综上所述,本公开实施例中的文字检测方法及系统,对输入图像进行特征提取,得到特征图像,利用自适应区域建议网络进行预测,得到建议框,利用建议框对特征图像进行裁剪,得到裁剪特征图,微调网络根据裁剪特征图对建议框进行调整,根据调整后的建议框对特征图像进行裁剪,得到调整后的裁剪特征图,在两个正交方向上分别对调整后的裁剪特征图进行文字纹理信息建模,得到每一正交方向对应的轮廓点热力图,对轮廓点热力图中的轮廓点进行筛选,得到轮廓点集合,以重建输入图像中的文字,通过设计自适应区域建议网络,能够更好地适应文字的尺度变化,在正交方向上进行文字纹理信息建模,能够抑制假阳性的轮廓点,从而有效地解决了文字尺度变化和假阳性预测的问题,提升了任意形状场景文字检测的精度。
以上所述的具体实施例,对本公开的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本公开的具体实施例而已,并不用于限制本公开,凡在本公开的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本公开的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!