一种新闻自动拆条的自适应条件随机场算法的训练方法与流程
本发明涉及广播电视新闻自动拆条领域,尤其是一种新闻自动拆条的自适应条件随机场算法的训练方法。
背景技术:
近年来,随着我国广播电视行业的迅猛发展,电视新闻类节目逐渐增多。电视新闻作为一种重要的信息报道形式,具有受众广、时效性快、可信度高等特点。整档的电视新闻通常包含多个新闻故事,而观众或视频编辑人员通常需要快速定位到某一个或几个新闻故事,纯粹的人工搜索电视新闻视频中的新闻故事将会费时费力。因此,找到一种能够快速将整档的电视新闻自动拆条的方法,具有重要的意义。
条件随机场(conditionrandomfield,crf)算法作为一种有监督算法,通常用于序列数据的标注。电视新闻的自动拆条,本质上就是从电视新闻的众多拆条片段中组合成新闻故事,因此条件随机场算法已经应用在广播电视新闻自动拆条领域。该算法首先需将训练数据根据新闻故事的真实情况人工标记为bs(beginscene)、ms(middlescene)、es(endscene)、ss(singlescene);然后根据训练数据当前拆分条以及其前后若干条的标记,结合当前拆分条以及其前后若干条的特征数据(如是否检测演播室、临近拆分条语义相似度等),利用梯度下降法,求出训练数据的最大似然估计值,从而得出最优模型。最后利用该最优模型进行标签预测,根据预测标签将电视新闻的自动拆条。
然而,在实际工程应用中,条件随机场算法的效果受到了一定的制约,主要是因为条件随机场算法在训练时采用学习模板来进行固定步长的学习。例如,当学习模板确定为学习当前条及前后n条时,所有的拆条都会利用当前条以及前后n条的特征数据来进行学习。但是,固定步长的学习就可能会造成学习过多其他非临近新闻故事的特征数据,而对当前条及临近条新闻故事的特征数据造成掩盖,所以固定步长的条件随机场算法的准确性较差。
技术实现要素:
本发明所要解决的技术问题是:针对上述存在的问题,提供一种新闻自动拆条的自适应条件随机场算法的训练方法。
本发明采用的技术方案如下:
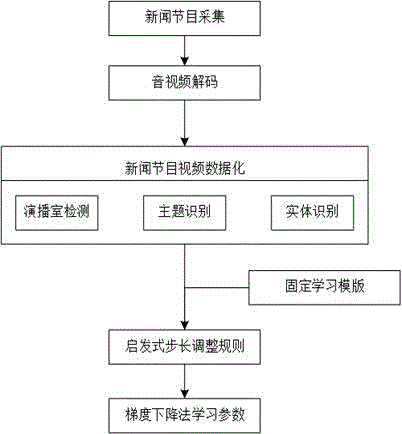
一种新闻自动拆条的自适应条件随机场算法的训练方法,其特征在于,包括如下步骤:
步骤1,新闻节目视频数据化,并根据新闻节目视频提取新闻拆条特征数据,以及新闻拆条标签;其中,新闻拆条特征数据包括是否演播室、演播室变化信息、前后临近拆条主题相似度、前后临近拆条实体识别相似度;新闻拆条标签包括bs/ms/es/ss四种类型;
步骤2,明确固定学习模板,学习模板中记录学习的步长,包括特征步长和标签步长;其中,特征步长是指步长内的新闻拆条特征数据对当前新闻拆条拆条标签的影响,标签步长是指步长内的其他标签数据对当前新闻拆条标签的影响;
步骤3,根据固定学习模板以及训练数据新闻拆条标签,采用启发式方法自适应的调整步长;
步骤4,根据步骤三中自适应方法学得的数据,采用梯度下降法,学习条件随机场算法中的参数。
进一步,步骤1包括如下子步骤:
步骤101,从新闻节目视频中的音频停顿点首先将该视频进行切割,所有的音频停顿点就是新闻故事的候选切割点;
步骤102,根据每条切割片段的视频信息,提取该切割片段是否是演播室,若是演播室,则置1,非演播室,则置2;然后在根据当前条切割片段和下一条切割片段的演播室新闻,提取演播室变化信息,其中演播室变化信息包括演播室转演播室、演播室转非演播室、非演播室转非演播室3类;
步骤103,根据每条切割片段的音频信息,提取该切割片段的语音;利用语音信息,结合文档主题生成模型,提取每条切割片段的主题分布与关键词;然后根据当前条切割片段和下一条切割片段的主题分布,使用余弦距离计算相邻两个切割片段的主题相似度;根据当前条切割片段和下一条切割片段的关键词,使用word2vect计算关键词相似度;最后根据所有切割片段的主题相似度值、关键词相似度值,分别计算各自的分位数,根据分位数将连续的主题相似度和关键词相似度离散化;
步骤104,根据每个切割片段的语音信息,提取每个切割片段的实体,包括人物、时间、地点及组织机构;根据当前条切割片段和下一条切割片段的对应实体类别,计算两者的jaccard距离,最后根据所有切割片段的不同实体类别,计算jaccard距离的分位数,根据分位数将连续的实体相似度值离散化。
进一步,步骤2中的学习模板包含unigram和bigram,分别代表条件随机场算法目标函数中的状态特征函数和转移特征函数;unigram状态特征函数即为特征步长,bigram转移特征函数即为标签步长。
进一步,步骤2中固定学习模板为当前条切割片段向前及向后分别学习n个切割片段,n≥5。
进一步,步骤3包括如下子步骤:
步骤301,抽取第一条切割片段的特征数据与标签,作为当前条;
步骤302,向前学习以当前条切割片段为基础,抽取出当前条切割片段之前n个切割片段的标签;
步骤303,将抽取出的n个切割片段的标签从后往前看;
步骤304,取最后一个切割片段的标签;
步骤305,当最后一个切割片段的标签是bs/es/ss三种中任意一种时,则再往前推导k个切割片段,k<n,以该最后一个切割片段之前的k个切割片段至当前条切割片段前一条作为向前学习的自适应步长模板,然后退出当前条切割片段的向前学习;
步骤306,当最后一个切割片段是ms时,且切割片段的标签数量大于1时,则将最后一个切割片段的标签删除,并跳转到步骤304;当最后一个切割片段是ms时,且切割片段的标签数量等于1时,则直接将这n个切割片段都作为当前条切割片段的前向学习切割片段,然后退出当前条切割片段的向前学习;
步骤307,向后学习以当前条切割片段为基础,抽取出当前条切割片段之后n个切割片段的标签;
步骤308,将抽取出的n个切割片段的标签从前往后看;
步骤309,取第一个切割片段的标签;
步骤310,当第一个切割片段的标签是bs/es/ss三种中任意一种时,则再往后推导k个切割片段,k<n,以当前条切割片段后一条至当前切割片段之后的k个切割片段作为向后学习的自适应步长模板,然后退出当前条切割片段的向后学习;
步骤311,当第一个切割片段的标签是ms时,且切割片段的标签数量大于1时,则将第一个切割片段的标签删除,并跳转到步骤309;当第一个切割片段的标签是ms时,且切割片段的标签数量等于1时,则直接将这n个切割片段都作为当前条切割片段的后向学习切割片段,然后退出当前条切割片段的向后学习;
步骤312,组合前向学习和后向学习的切割片段,作为当前切割片段的学习数据;
步骤313,判断当前条是否为该新闻节目视频的最后一条切割片段,若是,则结束;若不是,则将当前条的下一条切割片段作为新的当前条,并转302。
进一步,步骤4包括如下子步骤:
步骤401,根据条件随机场算法的目标函数的原始形式,将转移特征参数λ、状态特征参数μ合并为一个状态-转移特征参数ω,同时将状态特征函数
其中,i代表输入训练数据索引,i∈(1,2,…,i),i为输入训练数据的条数;k代表转移特征函数的索引,一共有k个转移特征函数;l代表状态特征函数的索引,一共有l个状态特征函数;m=k+l,代表一共有m个状态-特征转移函数;z(x)代表规范化因子,是在由bs/ms/es/ss四种类型的新闻拆条标签组成的所有可能的输出序列上求得;
步骤402,根据极大似然估计,得到该目标函数的对数似然函数:
步骤403,对对数似然函数的ωm求导,得到:
再将此导数的后半部展开,可得:
因此,对数似然函数对ωm的导数可以简化为:
其中,
步骤404,使用梯度下降法,求取参数ωm。
进一步,步骤1中,新闻节目视频数据化是指从某一个或几个电视频道的新闻节目中获取历史视频。
综上所述,由于采用了上述技术方案,本发明的有益效果是:
本发明可从新闻节目中抽取数据并训练得到自适应学习步长条件随机场模型;随后,可利用该模型对未知标签的新闻节目进行标注,从而将新闻故事从新闻节目中自动拆分。本发明根据训练数据自身的情况自适应的学习当前条和前后若干条,从而更加关注于当前条及临近条新闻故事特征数据的学习,减少非临近新闻故事的特征数据的学习,对于提升条件随机场算法在电视新闻自动拆条的准确率具有重要意义。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
图1为本发明的新闻自动拆条的自适应条件随机场算法的训练方法的流程框图。
图2为本发明的启发式方法自适应的调整步长的流程框图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明,即所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,本实施例提供的一种新闻自动拆条的自适应条件随机场算法的训练方法,包括如下步骤:
步骤1,新闻节目视频数据化,并根据新闻节目视频提取新闻拆条特征数据,以及新闻拆条标签;其中,新闻拆条特征数据包括是否演播室、演播室变化信息、前后临近拆条主题相似度、前后临近拆条实体识别相似度;新闻拆条标签包括bs/ms/es/ss四种类型;
步骤2,明确固定学习模板,学习模板中记录学习的步长,包括特征步长和标签步长;其中,特征步长是指步长内的新闻拆条特征数据对当前新闻拆条标签的影响,标签步长是指步长内的其他标签数据对当前新闻拆条拆条标签的影响;
步骤3,根据固定学习模板以及训练数据新闻拆条标签,采用启发式方法自适应的调整步长;
步骤4,根据步骤三中自适应方法学得的数据,采用梯度下降法,学习条件随机场算法中的参数。
所述的步骤1中,新闻节目视频数据化是指从某一个或几个电视频道的新闻节目中获取历史视频。考虑到不同的新闻故事之间切换时,都会出现短暂的音频停顿,因此本方案采用音频停顿点作为新闻故事切割候选点,也就是说,新闻拆条的本质就是从这些候选音频切割点中找到真实的新闻故事切割点。具体地,步骤1包括如下子步骤:
步骤101,从新闻节目视频中的音频停顿点首先将该视频进行切割,所有的音频停顿点就是新闻故事的候选切割点;
步骤102,根据每条切割片段的视频信息,提取该切割片段是否是演播室,若是演播室,则置1,非演播室,则置2;然后在根据当前条切割片段和下一条切割片段的演播室新闻,提取演播室变化信息,其中演播室变化信息包括演播室转演播室、演播室转非演播室、非演播室转非演播室3类;
步骤103,根据每条切割片段的音频信息,提取该切割片段的语音;利用语音信息,结合文档主题生成模型,提取每条切割片段的主题分布与关键词;然后根据当前条切割片段和下一条切割片段的主题分布,使用余弦距离计算相邻两个切割片段的主题相似度;根据当前条切割片段和下一条切割片段的关键词,使用word2vect计算关键词相似度;最后根据所有切割片段的主题相似度值、关键词相似度值,分别计算各自的分位数,根据分位数将连续的主题相似度和关键词相似度离散化;
步骤104,根据每个切割片段的语音信息,提取每个切割片段的实体,包括人物、时间、地点及组织机构;根据当前条切割片段和下一条切割片段的对应实体类别,计算两者的jaccard距离,最后根据所有切割片段的不同实体类别,计算jaccard距离的分位数,根据分位数将连续的实体相似度值离散化。
步骤2中的学习模板包含unigram和bigram,分别代表条件随机场算法目标函数中的状态特征函数和转移特征函数。
其中,unigram状态特征函数即为特征步长,也即步长内的新闻拆条特征数据对当前新闻拆条标签的影响;bigram转移特征函数即为标签步长,也即步长内的其他标签数据对当前新闻拆条标签的影响。为了使固定学习模板尽可能的包含较多的新闻故事,因此本实施例中,步骤2中固定学习模板为当前条切割片段向前及向后分别学习n个切割片段,n≥5。例如,u00:[-n,0]代表以当前新闻拆条为基准,前n个新闻拆条特征数据对当前新闻拆条标签的影响;u01:[n,0]代表以当前新闻拆条为基准,后n个新闻拆条特征数据对当前新闻拆条标签的影响。b00:[-n,0]代表当前新闻拆条为基准,前n个新闻拆条的标签数据对当前新闻拆条标签的影响;b01:[n,0]代表当前新闻拆条为基准,后n个新闻拆条的标签数据对当前新闻拆条标签的影响。
如图2所示,所述的步骤3中,采用启发式方法自适应的调整步长包括向前学习和向后学习两部分,具体包括如下子步骤:
步骤301,抽取第一条切割片段的特征数据与标签,作为当前条;
步骤302,向前学习以当前条切割片段为基础,抽取出当前条切割片段之前n个切割片段的标签;
步骤303,将抽取出的n个切割片段的标签从后往前看;
步骤304,取最后一个切割片段的标签;
步骤305,当最后一个切割片段的标签是bs/es/ss三种中任意一种时,则再往前推导k个切割片段,k<n,以该最后一个切割片段之前的k个切割片段至当前条切割片段前一条作为向前学习的自适应步长模板,然后退出当前条切割片段的向前学习;
步骤306,当最后一个切割片段是ms时,且切割片段的标签数量大于1时,则将最后一个切割片段的标签删除,并跳转到步骤304;当最后一个切割片段是ms时,且切割片段的标签数量等于1时,则直接将这n个切割片段都作为当前条切割片段的前向学习切割片段,然后退出当前条切割片段的向前学习;
步骤307,向后学习以当前条切割片段为基础,抽取出当前条切割片段之后n个切割片段的标签;
步骤308,将抽取出的n个切割片段的标签从前往后看;
步骤309,取第一个切割片段的标签;
步骤310,当第一个切割片段的标签是bs/es/ss三种中任意一种时,则再往后推导k个切割片段,k<n,以当前条切割片段后一条至当前切割片段之后的k个切割片段作为向后学习的自适应步长模板,然后退出当前条切割片段的向后学习;
步骤311,当第一个切割片段的标签是ms时,且切割片段的标签数量大于1时,则将第一个切割片段的标签删除,并跳转到步骤309;当第一个切割片段的标签是ms时,且切割片段的标签数量等于1时,则直接将这n个切割片段都作为当前条切割片段的后向学习切割片段,然后退出当前条切割片段的向后学习;
步骤312,组合前向学习和后向学习的切割片段,作为当前切割片段的学习数据;
步骤313,判断当前条是否为该新闻节目视频的最后一条切割片段,若是,则结束;若不是,则将当前条的下一条切割片段作为新的当前条,并转302。
根据步骤3自适应的调整步长后的所有切割片段的学习数据即为训练数据,可以采用梯度下降法对条件随机场算法的目标函数进行参数估计,具体地,步骤4包括如下子步骤:
步骤401,根据条件随机场算法的目标函数的原始形式,将转移特征参数λ、状态特征参数μ合并为一个状态-转移特征参数ω,同时将状态特征函数
其中,i代表输入训练数据索引,i∈(1,2,…,i),i为输入训练数据的条数;k代表转移特征函数的索引,一共有k个转移特征函数;l代表状态特征函数的索引,一共有l个状态特征函数;m=k+l,代表一共有m个状态-特征转移函数;z(x)代表规范化因子,是在由bs/ms/es/ss四种类型的新闻拆条标签组成的所有可能的输出序列上求得;
步骤402,根据极大似然估计,得到该目标函数的对数似然函数:
步骤403,对对数似然函数的ωm求导,得到:
再将此导数的后半部展开,可得:
因此,对数似然函数对ωm的导数可以简化为:
其中,
步骤404,使用梯度下降法,求取参数ωm。
综上步骤1~4,即可从新闻节目中抽取数据并训练得到自适应学习步长条件随机场模型;随后,可利用该模型对未知标签的新闻节目进行标注,从而将新闻故事从新闻节目中自动拆分。本发明根据训练数据自身的情况自适应的学习当前条和前后若干条,从而更加关注于当前条及临近条新闻故事特征数据的学习,减少非临近新闻故事的特征数据的学习,对于提升条件随机场算法在电视新闻自动拆条的准确率具有重要意义。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!