一种基于随机游走采样的社交网络模式挖掘方法与流程
本发明属于社交网络挖掘
技术领域:
,具体涉及在社交网络中通过随机游走采样实现挖掘社交网络模式的方法。
背景技术:
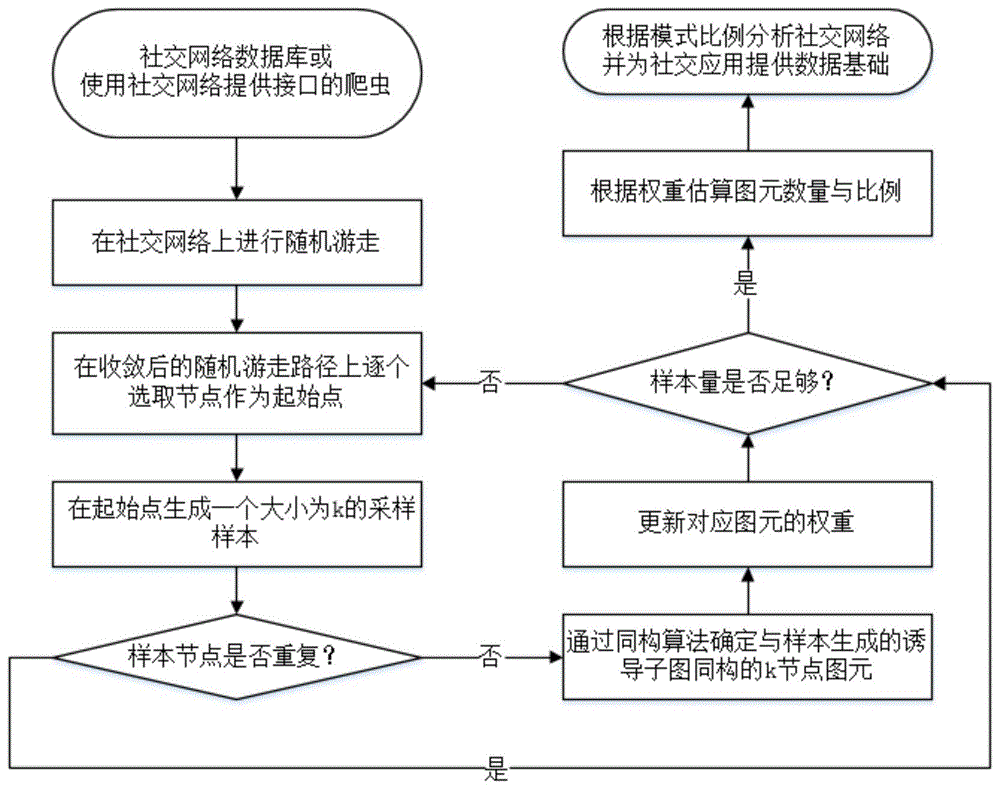
:目前主流的社交网络数据挖掘方法通常用图来表示社交网络,节点表示构成网络的人或者其他实体,边表示实体之间的关系。分析社交网络的一种方法是计算其对应的图的图元分布,后者能很好地描述图的拓扑结构特征。图元是指图中连通、非同构的诱导子图,图元的数量是指图中同构于各种图元的诱导子图的数量。通过计算图元数量得到图中子图模式的数量和比例,挖掘子图模式可以有效的分析社交网络中的实体之间的交互模式。随着社交网络规模的增大,其对应的图也越来越复杂,图元数目也呈现出爆发式增长,获取各种图元在图中的确切数量耗时过大,通过采样的方法进行估计可以大大减少时间消耗,同时近似的精度也能够满足大多数应用的需要。使用随机游走进行采样是当今一种流行的采样方式,例如在第32届国际数据工程大会(32thieeeinternationalconferenceondataengineering,icde2016)的“waddlingrandomwalk:fastandaccurateminingofmotifstatisticsinlargegraphs”中提出的方法,通过随机生成样本来估计图元数量。现有的基于随机游走采样的社交网络模式挖掘方法缺乏对复杂的多节点图元分析的支持,例如对节点数目大于5的图元数量的估计就没有很好的方法。不支持任意节点数的子图模式挖掘,是目前社交网络模式挖掘面临的一大挑战。另外,现有的社交网络规模越来越大,但服务商提供的接口访问量有限,如何在有限的时间内通过提供的接口访问部分社交网络来挖掘整个社交网络信息也是一个极大的挑战。技术实现要素:本发明的目的是提出一种基于随机游走采样的社交网络模式挖掘方法,支持任意节点数目子图模式的挖掘,既能直接应用在社交网络数据库中,也能支持限制访问的社交网络上的在线挖掘。本发明基于随机游走采样的社交网络模式挖掘方法,其特征在于包括以下步骤:第一步:在社交网络上进行随机游走给定一个社交网络,和所需要挖掘的模式的节点数目k和采样样本量n,将社交网络看成图,将实体看做节点,将与实体有关系的实体集合看做节点的邻居节点集合;在社交网络数据库中随机选取节点作为起始点,或者在限制访问的社交网络中使用python中的scrapy模块构建爬虫通过社交网络提供的有限接口随机选取节点作为起始点,在其邻居节点集合中任意选取一个节点作为下一跳,将下一跳作为起始点继续跳转,直至随机游走收敛;第二步:在收敛后的随机游走路径上进行采样在收敛后的随机游走路径上逐个选择节点作为样本起始点进行采样,采样方法如下:在样本起始点v1的邻居节点集合n1中随机选取一个节点作为第二个节点v2,将v2的邻居节点集合与n1合并得到一个新的集合n′1,再在n′1中随机选取下一个节点v3,将v3的邻居节点集合与n′1合并得到更新后的n′1,重复以上步骤,直至得到给定节点数目的选取节点组成的节点序列sk:sk=<v1,v2,v3,…,vk>,该节点序列中的节点根据社交网络的原有关系,生成诱导子图g′k,记作一个样本,转至第三步对单个样本进行分析;第三步:对单个样本进行分析首先判断节点序列sk中是否有重复节点,如果有,将样本记作无效样本,直接转至第四步;如果没有,将样本记作有效样本,进行同构判断并更新对应图元的权值:使用同构判断算法将单个样本的诱导子图g′k与所有k节点图元gk进行比较,直至找到与g′k同构的图元,记作原图中所有的节点度数之和记作d,vi的度数记作di,根据第二步的采样过程得到g′k的采样概率p:将与g′k对应图元的权重相加(初始为零),更新权重转至第四步;第四步:根据所有样本分析关系模式若有效和无效的样本总量小于n,转至第一步继续采样;若样本总量等于n,则根据已得到的n个样本对图元数量进行无偏估计:每个图元根据第二步的采样过程都有自己的重复系数,重复系数对应样本采样过程中与图元同构的子图的不同生成方式的个数;对于任意一个k图元其重复系数记为根据权重计算该图元数量的无偏估计得到所有k节点图元的估计数量后,计算各图元所占估计总数的占比,此占比即为社交网络中所有k个实体之间关系模式的占比估计值。上述本发明基于随机游走采样的社交网络模式挖掘方法,包含了在社交网络上进行随机游走、在收敛后的随机游走路径上进行采样、对单个样本进行分析、根据所有样本分析关系模式等步骤。首先,本方法面向社交网络,支持任意节点数目的子图模式挖掘,突破了现有的基于随机游走的社交网络模式挖掘方法不能挖掘任意图元模式的限制;其次,本发明方法支持采用爬虫通过社交网络提供的有限接口对社交网络上进行在线挖掘,也支持直接在社交网络数据库上进行模式挖掘,无需读取全部社交网络数据库,仅需要全社交网络的总关系数这一信息,访问代价与内存需求低;最后,本方法面向微信朋友圈、新浪微博等社交应用,可以挖掘社交网络中实体之间的交互模式,为商品推荐、社交分析、兴趣推广等服务提供数据支持。附图说明图1是本发明基于随机游走采样的社交网络模式挖掘方法的操作流程示意图。图2是所有5节点图元示意图。图3表示实施例1中某个样本所在的部分子图示意图。图4表示实施例1中某个样本的诱导子图示意图。图5是部分7节点图元示意图。图6表示实施例2中某个样本所在的部分子图示意图。图7表示实施例2中某个样本的诱导子图示意图。具体实施方式下面结合附图通过具体实施例对本发明基于随机游走采样的社交网络模式挖掘方法作进一步的详细说明。实施例1:本实施例基于随机游走采样的社交网络模式挖掘方法,是在一台主机上对一个社交网络进行5节点图元模式的挖掘。图1是本发明基于随机游走采样的社交网络模式挖掘方法的操作流程示意图。图2给出了所有5节点图元示意图:5节点图元共有21种,第i种图元记作给定一个社交网络和采样样本量大小n,社交网络中所有实体之间的关系总数为|e|。本实施例基于随机游走采样的社交网络模式挖掘方法,首先给定所要估计图元的节点数量,通过数据库的查询借口或者使用爬虫通过限制访问的社交网络提供的接口在图上进行随机游走,通过采样的方法估计图中所有给定节点数量图元的数量,最后根据数量得到给定节点数量的图元的占比。具体包括以下步骤:第一步:在社交网络上进行随机游走将社交网络看成图g,将实体看做节点,将与实体有关系的实体集合看做节点的邻居节点集合;在社交网络数据库中随机选取节点作为起始点,或者在限制访问的社交网络中使用python中的scrapy模块构建爬虫通过社交网络提供的有限接口随机选取节点作为起始点,在其邻居节点集合中任意选取一个节点作为下一跳,将下一跳作为起始点继续跳转,直至随机游走收敛;第二步:在收敛后的随机游走路径上进行采样在收敛后的随机游走路径<t1,t2,t3,…,tn>上逐个选择节点作为样本起始点进行采样,由于随机游走已经收敛,节点t出现在路径上的概率为其中dt为节点t的度数,即与对应实体的有关系的实体的数量。取ti为第i次取样的样本起始点,暂时记作v1。图3表示第i次样本所在的部分子图示意图:在第i次采样中共出现8个实体,各实体用节点v表示,实体之间的关系用边表示。根据采样方法,在v1的邻居节点集合n1={v2,v3,v4,v8}中任意选取一个节点,此时n1的大小为4,选取到了v2,选取概率为将v2的邻居节点集合{v1,v5,v6}与n1合并,得到一个新的集合n′1={v1,v2,v3,v4,v5,v6,v8},此时n′1的大小为7,同理在n′1中以的概率任意选取一个节点,选取到了v3,将v3的邻居节点集合{v1,v4,v7}与n′1合并,更新n′1={v1,v1,v2,v3,v4,v4,v5,v6,v7,v8}。重复上述过程,直至得到一个长度为5的已选取节点序列s5=<v1,v2,v3,v4,v5>。该节点序列中的节点生成的诱导子图g′5={v′,e′},v′={v1,v2,v3,v4,v5},e′={(v1,v2),(v1,v3),(v1,v4),(v2,v5),(v3,v4)}。图4表示该样本的诱导子图g′5示意图。第三步:对单个样本进行分析。由于s5无重复节点,g′5记作有效样本,对g′5进行同构判断并更新对应图元的权值。使用同构判断算法将g′5与所有5节点图元g5进行比较,直至找到与g′5同构的图元,对应图元在附图2中为原图中所有的节点度数之和d=2|e|,vi的度数记作di,根据第二步的采样过程得到样本g′5的采样概率p:将与g′k对应图元的权重相加(初始为零),更新权重第三步:根据所有样本分析关系模式此时样本量未达到n,转至第一步在收敛后的随机游走路径上选择下一个节点ti+1作为起始点进行采样,直至样本总量为n。每个5节点图元根据采样过程都有自己的重复系数重复系数对应样本采样过程中与图元同构的子图的不同生成方式的个数。下面是所有5节点图元的重复系数表,图元编号对应图1中的5节点图元编号:图元编号1234567重复系数48281048872220264图元编号891011121314重复系数528166022480224488图元编号15161718192021重复系数17639694450499217282880对于任意一个5图元根据得到的权重值计算该图元数量的无偏估计得到所有5节点图元的估计数量后,计算各图元所占总数的估计占比,此占比即为该社交网络中所有5实体之间关系模式的占比估计值。在本实施例中,可以采用爬虫通过社交网络提供的有限接口对社交网络进行在线挖掘,也可以直接在社交网络数据库上进行挖掘,无需读取整个社交网络数据库,仅需要全社交网络的总关系数这一信息,访问代价与内存需求低,可以根据精度需求调整n的大小在有限的访问时间内估算5节点图元数量;另外基于社交网络,面向微信朋友圈、新浪微博等应用,挖掘社交网络中的5个人之间的关系模式,为商品推荐、社交分析、兴趣推广等服务提供数据支持。实施例2:本实施例基于随机游走采样的社交网络模式挖掘方法,在一台主机上对一个社交网络进行7节点图元模式的挖掘。图5给出了部分7节点图元示意图:7节点图元共有853种,第i种图元记作由于数量过多,仅给出4个7节点图元结构。给定一个社交网络和采样样本量n,社交网络中所有实体之间的关系总数为|e|。本实施例基于随机游走的图元估计算法,具体包括以下步骤:第一步:在社交网络上进行随机游走将社交网络看成图g,将实体看做节点,将与实体有关系的实体集合看做节点的邻居节点集合;在社交网络数据库中随机选取节点作为起始点,或者在限制访问的社交网络中使用python中的scrapy模块构建爬虫通过社交网络提供的有限接口随机选取节点作为起始点,在其邻居节点集合中任意选取一个节点作为下一跳,将下一跳作为起始点继续跳转,直至随机游走收敛;第二步:在收敛后的随机游走路径上进行采样在收敛后的随机游走路径<t1,t2,t3,…,tn>上逐个选择节点作为样本起始点进行采样,由于随机游走已经收敛,节点t出现在路径上的概率为其中dt为节点t的度数,即与对应实体的有关系的实体的数量。取ti为第i次取样的样本起始点,暂时记作v1。图6表示第i次样本所在的部分子图示意图:在第i次采样中共出现8个实体,各实体用节点v表示,实体之间的关系用边表示。根据采样方法,在v1的邻居节点集合n1={v2,v3,v4,v5,v6,v7,v8}中任意选取一个节点,此时n1的大小为7,选取到了v2,选取概率为将v2的邻居节点集合{v1}与n1合并,得到一个新的集合n′1={v1,v2,v3,v4,v5,v6,v7,v8},此时n′1的大小为8,同理在n′1中以的概率任意选取一个节点,选取到了v3,将v3的邻居节点集合{v1}与n′1合并,更新后得到新的n′1={v1,v1,v2,v3,v4,v5,v6,v7,v8}。重复上述过程,直至得到一个长度为7的选取节点序列s7=<v1,v2,v3,v4,v5,v6,v7>。该节点序列中的节点生成的诱导子图g′7={v′,e′},其中v′={v1,v2,v3,v4,v5,v6,v7},e′={(v1,v2),(v1,v3),(v1,v4),(v1,v5),(v1,v6),(v1,v7),(v4,v5)}。图7表示该样本的诱导子图g′7示意图。第三步:对单个样本进行分析。由于s7无重复节点,g′7记作有效样本,对g′7进行同构判断并更新对应图元的权值。使用同构判断算法将g′7与所有7节点图元g7进行比较,直至找到与g′7同构的图元,对应图元在附图4中为原图中所有的节点度数之和d=2|e|,vi的度数记作di,根据第二步的采样过程得到样本g′7的采样概率p:将与g′k对应图元的权重相加(初始为零),更新权重第三步:根据所有样本分析关系模式此时样本量未达到n,转至第一步在收敛后的随机游走路径上选择下一个节点ti+1作为起始点进行采样,直至样本总量为n。每个图元根据第二步的采样过程都有自己的重复系数重复系数对应样本采样过程中与图元同构的子图的不同生成方式的个数。下面是部分7节点图元的重复系数表,图元编号对应图4中的7节点图元编号:图元编号123853重复系数144076829763628800对于任意一个7图元根据得到的权重值计算该图元数量的无偏估计得到所有7节点图元的估计数量后,计算各图元所占估计总数的占比,此占比即为社交网络中所有7实体之间关系模式的占比估计值。在本实施例中,可以采用爬虫通过社交网络提供的有限接口对社交网络上进行在线挖掘,也可以直接在社交网络数据库上进行挖掘,无需读取整个社交网络数据库,仅需要全社交网络的总关系数这一信息,访问代价与内存需求低,可以根据精度需求调整n的大小在有限的访问时间内估算7节点图元数量;另外基于社交网络,面向微信朋友圈、新浪微博等应用,挖掘社交网络中的7个人之间的关系模式,为商品推荐、社交分析、兴趣推广等服务提供数据支持。当前第1页12
相关技术
网友询问留言
已有1条留言
-
 0181119... 来自[中国] 2021年07月01日 15:58附有代码吗?
0181119... 来自[中国] 2021年07月01日 15:58附有代码吗?
1