一种基于时序移位的自纠错人类行为识别方法与流程
本发明涉及计算机视觉技术领域,具体涉及一种基于时序移位的自纠错人类行为识别方法。
背景技术:
基于视频的人类行为识别一直是计算机视觉领域中极具挑战的问题之一。行为识别在现实生活中的多个方面均有重要的应用价值,如视频理解、安防领域、自动驾驶和人机交互等。随着近年来大规模视频数据的出现,传统的通过人工对视频进行人类行为分析和识别,准确率低,处理速度慢,已无法满足视频实时分析的需求,因此,准确且高效的视频行为分析方法显得至关重要。
目前现有的深度学习行为识别方法,包括2d卷积神经网络模型(2dcnn)和3d卷积网络模型(3dcnn)。直接使用2dcnn进行视频行为识别时,其参数量小,计算成本低,但存在的问题是,视频中相邻帧之间相似度高,存在大量冗余;2dcnn仅仅对单帧的图片进行空间特征的提取,无法提取视频中的时序特征,准确度较低。而使用3dcnn可以同时提取视频中的空间特征和时序特征,准确度较高,但是较2dcnn而言,参数量大,计算成本高,难以部署在算力受限的嵌入式设备上。
技术实现要素:
针对上述问题,本发明提供了一种基于时序移位的自纠错人类行为识别方法,使用2dcnn,本发明在不添加参数量的前提下,可以融合视频中的时序特征,实现高效且准确的视频行为识别。
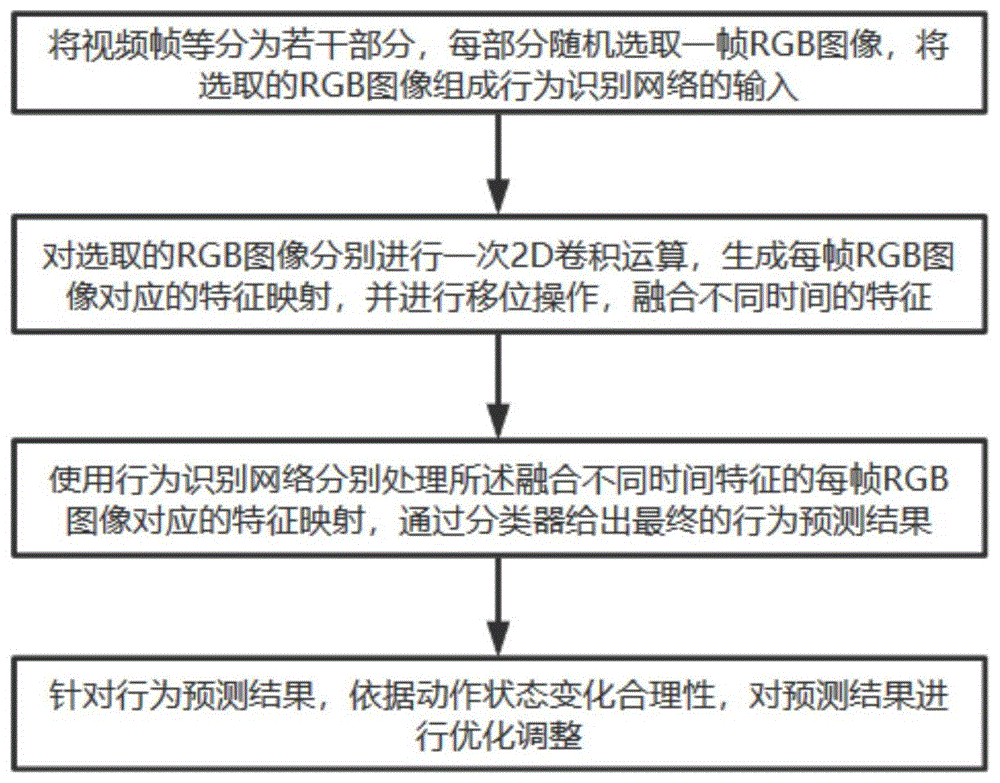
本发明的技术方案是:一种基于时序移位的自纠错人类行为识别方法,操作步骤具体如下:
步骤(1.1),将视频帧等分为若干部分,每部分随机选取一帧rgb图像,将选取的rgb图像组成行为识别网络的输入;
步骤(1.2),对选取的rgb图像分别进行一次2d卷积运算,生成每帧rgb图像对应的特征映射,并进行移位操作,融合不同时间的特征;
步骤(1.3),使用行为识别网络分别处理所述融合不同时间特征的每帧rgb图像对应的特征映射,通过分类器给出最终的行为预测结果;
步骤(1.4),针对所述行为预测结果,依据动作状态变化合理性,对预测结果进行优化调整。
进一步的,所述步骤(1.1)中将rgb图像组成行为识别网络的输入的具体方法:
利用ffmpeg将视频转换为图片帧,并进行等分,记为s1,s2,s3…sn;采取稀疏采样策略,分别对所述视频帧等分后的每个部分,从中随机抽取一帧图片,记为f1,f2,f3…fn,组成行为识别网络的输入,记为(f1,f2,f3…fn)。
进一步的,所述步骤(1.2)的具体操作步骤如下:
步骤(1.2.1)、将所述行为识别网络的输入(f1,f2,f3…fn),进行一次2d卷积运算,生成每帧rgb图像对应的特征映射,记为式(1):
步骤(1.2.2)、在通道维度和时序维度上,对所述每帧rgb图像对应的特征映射,进行移位操作,将第一个通道的特征向左平移,将第二个通道维度的特征向右平移,即不同时间的图片特征发生相互作用;移位之后特征映射的空位使用0进行填充,记为emt,移位生成的最终特征映射记为式(2):
进一步的,所述步骤(1.3)中最终的预测结果如式3所示:
res(f1,f2,f3…fn)=h(g(o(f1;w),o(f2;w),…,o(fn;w))(3)
进一步的,所述步骤(1.4)的具体操作步骤如下:
通过行为识别网络输出最终的预测结果时,产生动作的误判;此时根据动作状态变化合理性,调整所述误判动作类别对应的网络参数权重,重新输出优化调整后的预测结果。
本发明的有益效果是:本发明使用稀疏采样策略,在对视频进行抽帧时,去除了一部分冗余信息,在保证准确率的前提下,显著减少了计算量。对特征映射采用了移位操作,可以使不同时间的特征发生相互作用,在不增加参数的前提下,高效地捕捉到了时序特征,并能针对行为预测结果,依据动作状态变化的合理性,对预测结果进行优化调整,提高了预测准确率。
附图说明
图1为本发明的结构流程图;
图2为本发明中移位操作的实例示意图;
图3为本发明中网络框架的结构示意图;
图4为本发明中对预测结果优化调整的结构示意图。
具体实施方式
为了更清楚地说明本发明的技术方案,下面将对本发明中进行进一步的叙述;显而易见地,下面描述中的仅仅是一部分的实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些将本发明所述的技术方案应用于其它类似情景;为了更清楚地说明本发明的技术方案,下面结合附图对本发明的技术方案做进一步的详细说明:
如图1所示,一种基于时序移位的自纠错人类行为识别方法,其特征在于,操作步骤具体如下:
步骤(1.1),将视频帧等分为若干部分,每部分随机选取一帧rgb图像,将选取的rgb图像组成行为识别网络的输入,
利用ffmpeg将视频转换为图片帧,并进行等分,记为s1,s2,s3…sn;采取稀疏采样策略,分别对所述视频帧等分后的每个部分,从中随机抽取一帧图片,记为f1,f2,f3…fn,组成行为识别网络的输入,记为(f1,f2,f3…fn);
步骤(1.2),对选取的rgb图像分别进行一次2d卷积运算,生成每帧rgb图像对应的特征映射,并进行移位操作,融合不同时间的特征;其具体步骤如下:
步骤(1.2.1)、将所述行为识别网络的输入(f1,f2,f3…fn),进行一次2d卷积运算,生成每帧rgb图像对应的特征映射,记为式(1):
具体地,其中f1_c1表示第一帧第一个通道的特征,f1_c2表示第一帧第二个通道的特征,依次类推,fn_cn表示第n帧第n个通道的特征;
步骤(1.2.2)、在通道维度和时序维度上,对所述每帧rgb图像对应的特征映射,进行移位操作,将第一个通道的特征向左平移,将第二个通道维度的特征向右平移,即不同时间的图片特征发生相互作用;移位之后特征映射的空位使用0进行填充,记为emt,移位生成的最终特征映射记为式(2):
所述不同的图片特征发生相互作用,表示进行移位操作后,当前帧的图片特征融合了前一帧的图片特征以及后一帧的图片特征;
步骤(1.3),使用行为识别网络分别处理所述融合不同时间特征的每帧rgb图像对应的特征映射,通过分类器给出最终的行为预测结果;
最终的预测结果如式3所示:
res(f1,f2,f3…fn)=h(g(o(f1;w),o(f2;w),…,o(fn;w))(3)
式3中,其中(f1,f2,f3…fn)为网络输入;w表示网络参数;o(f1;w)表示行为识别网络对移位生成的每帧图片最终特征映射进行处理后的输出,即预测的每个行为类别对应的得分;g表示融合函数,对所有输出属于同一类别的得分取平均;h表示使用softmax分类器根据得分计算每个类别对应的概率;
所述softmax分类器,可将多个输出得分,记为(k1,k2,k3…kn),映射成(0,1)区间内的值,记为(p1,p2,p3…pn),即每个行为类别对应的预测概率,且p1+p2+p3+…+pn=1,并选取概率最高项;
所述最终的预测结果res(f1,f2,f3…fn)即为h中概率最高项对应的类别;
步骤(1.4),针对所述行为预测结果,依据动作状态变化合理性,对预测结果进行优化调整,
所述动作状态变化合理性,表示执行动作的主体,在一段时间间隔内从第一所述状态变化到第二所述状态,再从第二所述状态变化到第三所述状态,直至变化到最终所述状态,这种动作状态转变的过程是符合客观现实中动作执行先后顺序的,是无法从第一所述状态变化到除第二所述状态的其他状态的;
具体操作步骤如下:
通过行为识别网络输出最终的预测结果时,产生动作的误判;此时根据动作状态变化合理性,调整所述误判动作类别对应的网络参数权重,重新输出优化调整后的预测结果。
如图2所示,本发明提供一个移位操作实例示意图;所述一个移位操作实例示意图,是由5个不同时刻(t=0,t=1,t=2,t=3,t=4)的5张rgb图像(f1,f2,f3,f4,f5)作为输入,进行一次2d卷积运算后,生成的每帧图像对应的特征映射组合而成的,记为(4):
其中f1_c1表示第一帧第一个通道的特征,f1_c2表示第一帧第二个通道的特征,依次类推,f5_c5表示第5帧第5个通道的特征;在通道维度和时序维度上,对所述每帧rgb图像对应的特征映射,进行移位操作,将第一个通道的特征向左平移,将第二个通道维度的特征向右平移,即不同时刻的每帧rgb图像特征发生相互作用;移位之后特征映射的空位使用0进行填充,记为emt,移位生成的最终特征映射记为(5):
所述移位操作结束后,当前帧的rgb图像特征融入了前一帧的rgb图像特征和后一帧的rgb图像特征。
如图3所示,本发明提供一个网络框架示意图;所述行为识别网络框架,表示将视频帧等分为若干部分,记为s1,s2,s3…sn;采取稀疏采样策略,分别对所述视频帧等分后的每个部分,从中随机抽取一帧图片,组成行为识别网络的输入,记为(f1,f2,f3…fn);将所述行为识别网络的输入,进行一次2d卷积运算,生成每帧rgb图像对应的特征映射,并利用移位操作,再对所述移位操作生成的每帧rgb图像最终特征映射进行处理。
如图4所示,本发明提供一个对预测结果优化调整示意图示意图;所述对预测结果优化调整示意图,针对一段时间间隔内的跳远动作,执行动作的主体,从第一所述站立备跑状态变化到第二所述奔跑状态,再从第二所述奔跑状态变化到第三所述跳跃状态,最后从第三所述状态变化到最终所述落地状态,所述动作状态转变的过程是合理且符合客观现实中动作执行先后顺序的,是无法从第一所述站立备跑状态变化到除第二所述奔跑状态的其他状态的;行为识别网络输出预测结果时,即输出类别为:“站立备跑”,“跳跃”,“跳跃”,“落地”,产生了动作的误判,且不符合所述动作状态变化合理性。此时会根据所述动作状态变化合理性,调整所述误判动作类别“跳跃”对应的网络参数权重w,提高第二所述状态中“奔跑”的动作权重,重新输出优化调整后的预测结果,即输出类别为:“站立备跑”,“奔跑”,“跳跃”,“落地”,提高了预测准确率。
最后,应当理解的是,本发明中所述实施例仅用以说明本发明实施例的原则;其他的变形也可能属于本发明的范围;因此,作为示例而非限制,本发明实施例的替代配置可视为与本发明的教导一致;相应地,本发明的实施例不限于本发明明确介绍和描述的实施例。
- 还没有人留言评论。精彩留言会获得点赞!