轻量级卷积时空简单循环单元模型的驾驶动作识别方法与流程
本发明涉及一种驾驶动作识别方法,尤其涉及一种轻量级卷积时空简单循环单元模型的驾驶动作识别方法。
背景技术:
驾驶员在驾驶过程中普遍存在的危险驾驶行为,是引发交通事故的一个重要原因。例如,在驾驶过程中看手机、打电话、喝水、吃东西等行为大大增加了发生交通事故的风险。每年美国发生近1100万起交通事故,据估计,如果驾驶员不存在危险驾驶行为,则可以避免其中近36%的交通事故发生,为了最大程度地减少交通事故的发生,危险驾驶行为识别系统已成为各国专家研究的热点。
目前,在对驾驶行为识别方法的研究中,采集驾驶员数据的设备主要有单目摄像头和kinect深度相机。在基于单目摄像头的研究中,能够被应用于实际场景中的方法大多数集中于对驾驶员头部的监控,没有关注到驾驶员的肢体运动情况。基于kinect深度相机的研究方法,虽然能够通过三维骨骼数据很好的关注驾驶员的肢体运动情况,并且对多类危险驾驶行为也具有很好的性能。
然而,kinect深度相机价格昂贵、体积大,不能满足实际应用中嵌入式设备或系统的低成本、小尺寸的要求。因此,基于kinect的方法难以普及,实用性和市场推广性较差。目前将驾驶行为识别算法运行在低成本、小尺寸的嵌入式设备上,并且要求较高的准确性、实时性、鲁棒性,并不是一件容易的事,这仍然是一个需要继续深入研究的问题。
同时,人体姿态估计技术是一种能够替代kinect相机来获取人体关节点坐标的方法,通过人体姿态估计技术对rgb图像提取出驾驶员的上肢关节点坐标并进行分析,可以弥补目前基于单目摄像头的方法中很少能识别驾驶员肢体运动情况的不足。基于卷积神经网络的姿态估计算法能够取得很好的效果并且也是目前的主流方法。然而,为了到达很好的性能,用于姿态估计的cnn模型通常具有复杂的网络结构和很深的深度,由于网络层数深、参数多、计算量大,往往需要通过gpu加速才能够实时运行,这对硬件配置有较高要求。
因此,研究用于计算能力较低的嵌入式设备上的轻量级姿态估计算法,也是当前发展的方向之一。
近年来,深度学习技术发展迅猛,尤其是深度学习在移动端和嵌入式设备上的应用已经取得了突破性进展,涌现处理许多具有实用性的算法。mobilenet是一种针对移动端设备执行图像分类任务而设计的cnn模型,并且经过两年的优化和改进,2019年发展到了最新的mobilenetv3模型。tao等于2018年提出的简单循环单元(simplerecurrentunits,sru)是一种计算效率高、推理速度快的循环网络,可以在许多序列处理任务替换lstm模型,被广泛应用在机器翻译、语音识别、动作识别等领域。
有鉴于上述的缺陷,本设计人,积极加以研究创新,以期创设一种轻量级卷积时空简单循环单元模型的驾驶动作识别方法,使其更具有产业上的利用价值。
技术实现要素:
为解决上述技术问题,本发明的目的是提供一种轻量级卷积时空简单循环单元模型的驾驶动作识别方法。
本发明的轻量级卷积时空简单循环单元模型的驾驶动作识别方法,其特征在于包括以下步骤:
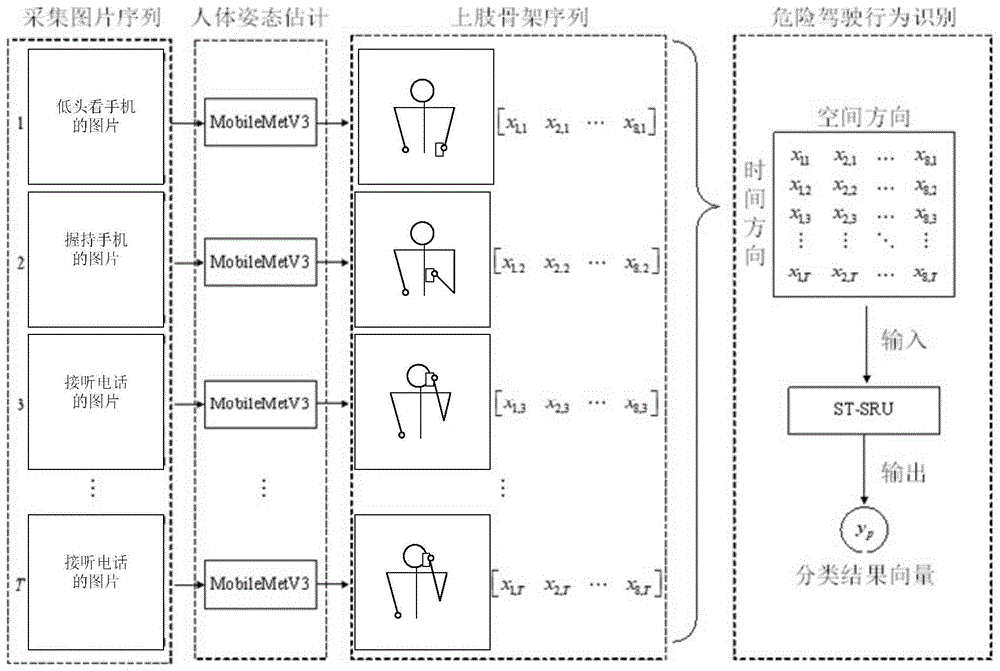
步骤一,对单目摄像头采集的rgb图像序列,采用基于mobilenetv3网络的人体姿态估计算法,逐帧提取驾驶员上肢的关节点坐标,得到与图像序列对应的骨架序列;
步骤二,构建时空域sru简单循环单元st-sru模型,针对同一帧中不同关节点的时间和空间依赖关系,建立st-sru模型;
步骤三,采用st-sru模型对骨架序列进行分类,实现对多类驾驶动作的识别,并针对步骤一获取的驾驶员上肢关节点的骨架序列,采用步骤二建立的st-sru模型,对骨架序列进行分类。
进一步地,上述的轻量级卷积时空简单循环单元模型的驾驶动作识别方法,其中,所述步骤一中,首先,定义输入是长宽为224×224的三通道rgb图片,通过基于mobilenetv3网络的人体姿态估计算法,输出一个大小为224×224×3j的张量;然后,该张量按照第3个维度,分为3j个224×224的图,分别为j个热力图,j个x方向偏移量图和j个y方向偏移量图;最后,从热力图、x方向偏移量图和y方向偏移量图计算出j个关节点坐标的预测值,对于第j个关节点的预测位置,计算公式如下:
pxj=mxj+oxj(mxj,myj);(2)
pyj=myj+oyj(mxj,myj);(3)
其中,hj是第j张热力图,(mxj,myj)是hj的像素值最大的位置,表示最有可能在第j个关节点附近的位置,oxj表示第j张x方向上的偏移量图,oyj表示第j张y方向上的偏移量图,由于(mxj,myj)是一个粗略的预测位置,如式(2)和(3)所示,在给(mxj,myj)加上预测的偏移量后,得到相对精确的第j个关节点的预测位置(pxj,pyj)。
更进一步地,上述的轻量级卷积时空简单循环单元模型的驾驶动作识别方法,其中,所述步骤二中,
用j∈{1,2,...,j}和t∈{1,2,...,t}分别表示骨架序列和同一个骨架中关节点的下标,
st-sru模型在时空步(j,t)接收了三种输入数据,包括对应于第t个骨架与第j个节点的特征信息ij,t、前一个空间步的内部状态cj-1,t和前一个时间步的内部状态cj,t-1,
st-sru模型涉及的计算公式如下:
rj,t=sigmoid(wrij,t+br);(7)
hj,t=rj,tetanh(cj,t)+(1-rj,t)eij,t;(9)
其中,w是输入数据的线性变换矩阵,
所述矩阵的大小都为d×d,其中,d是st-sru模型内部状态的尺寸大小,e表示矩阵的点积运算;
所述st-sru模型拥有两个遗忘门,分别用来忘记时间域和空间域上过去的上下文信息:
再进一步地,上述的轻量级卷积时空简单循环单元模型的驾驶动作识别方法,其中,所述步骤三中,对于一个长度为t的骨架序列,步骤一获得的第t个骨架的特征表示为xt,t∈{1,2,…,t},通过3层叠加的st-sru模型,上一层st-sru模型层的输出作为下一层st-sru模型层的输入,在逐步处理完骨架序列后,将最后一层的输出状态hi,t输入到softmax分类器,计算出驾驶动作的分类结果向量yp,
yp=softmax(wh3,t+b);(10)
其中,softmax是归一化指数函数,w是全连接层的权重矩阵,b是偏置向量,它们用于调整h3,t的大小,当st-sru模型内部状态的尺寸大小为d时,对于k个类别的驾驶动作,则w的大小为k×d,b的大小为1×b。
借由上述方案,本发明至少具有以下优点:
1、采用基于mobilenetv3的轻量级卷积神经网络获取驾驶员关节点坐标,相对于现有的深层的cnn模型,所提方法大大降低了参数数量,提高了算法的运行速度。
2、使用st-sru模型对二维关节点坐标序列进行分类,利用st-sru模型综合考虑同一帧中不同关节点的时间和空间依赖关系,具有计算效率高、推理速度快的优势,用于对获得的关节点坐标序列进行分类,能够克服lstm、gru等循环网络由于存在计算顺序依赖导致推理速度缓慢的问题。
3、本发明使用st-sru模型进行动作分类,提升了驾驶动作识别的准确率和速度。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,并可依照说明书的内容予以实施,以下以本发明的较佳实施例并配合附图详细说明如后。
附图说明
图1是轻量级卷积时空简单循环单元模型的驾驶动作识别方法的实施构示意图。
图2是mobilenetv3模型的基本构建块的结构示意图。
图3是st-sru模型的内部结构示意图。
图4是基于st-sru模型的动作分类流程示意图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
如图1至4的轻量级卷积时空简单循环单元模型的驾驶动作识别方法,其与众不同之处在于包括以下步骤:
步骤一,对(常规普通的)单目摄像头采集的rgb图像序列,采用基于mobilenetv3网络的人体姿态估计算法,逐帧提取驾驶员上肢的关节点坐标,得到与图像序列对应的骨架序列。
具体来说,首先,定义输入是长宽为224×224的三通道rgb图片,通过基于mobilenetv3网络的人体姿态估计算法,输出一个大小为224×224×3j的张量。
然后,该张量按照第3个维度,分为3j个224×224的图,分别为j个热力图,j个x方向偏移量图和j个y方向偏移量图。
最后,从热力图、x方向偏移量图和y方向偏移量图计算出j个关节点坐标的预测值,对于第j个关节点的预测位置,计算公式如下:
pxj=mxj+oxj(mxj,myj);(2)
pyj=myj+oyj(mxj,myj);(3)
其中,hj是第j张热力图,(mxj,myj)是hj的像素值最大的位置,表示最有可能在第j个关节点附近的位置。oxj表示第j张x方向上的偏移量图,oyj表示第j张y方向上的偏移量图。
结合实际实施来看,由于(mxj,myj)是一个粗略的预测位置,结合公式(2)和(3)来看,在给(mxj,myj)加上预测的偏移量后,得到相对精确的第j个关节点的预测位置(pxj,pyj)。
本发明基于mobilenetv3的轻量级卷积神经网络模型的结构如表1所示。
同时,基本构建块的结构如图2所示,nl表示非线性激活函数,dwise表示深度可分离卷积操作,pool表示池化层,fc表示全连接层。
步骤二,构建时空域sru简单循环单元st-sru模型,针对同一帧中不同关节点的时间和空间依赖关系,建立st-sru模型。st-sru模型的循环计算过程如图3所示,其中每个圆圈表示在时空步(j,t)的内部状态cj,t,并且cj,t同时依赖于同一帧的前一个关节点的内部状态cj-1,t和前一帧的同一个关节点的内部状态cj,t-1。
结合实际实施来看,在步骤二中,可用j∈{1,2,...,j}和t∈{1,2,...,t}分别表示骨架序列和同一个骨架中关节点的下标。st-sru模型在时空步(j,t)接收了三种输入数据,包括对应于第t个骨架与第j个节点的特征信息ij,t、前一个空间步的内部状态cj-1,t和前一个时间步的内部状态cj,t-1。具体来说,st-sru模型涉及的计算公式如下:
rj,t=sigmoid(wrij,t+br);(7)
hj,t=rj,tetanh(cj,t)+(1-rj,t)eij,t;(9)
其中,w是输入数据的线性变换矩阵,
本发明所采用的矩阵的大小都为d×d,其中,d是st-sru模型内部状态的尺寸大小,e表示矩阵的点积运算。配置的时候,st-sru模型拥有两个遗忘门,分别用来忘记时间域和空间域上过去的上下文信息:
步骤三,采用st-sru模型对骨架序列进行分类,实现对多类驾驶动作的识别,并针对步骤一获取的驾驶员上肢关节点的骨架序列,采用步骤二建立的st-sru模型,对骨架序列进行分类。
具体来说,对于一个长度为t的骨架序列,设步骤一获得的第t个骨架的特征表示为xt,t∈{1,2,...,t}。这样,通过三层叠加的st-sru模型,上一层st-sru模型层的输出作为下一层st-sru模型层的输入,在逐步处理完骨架序列后,将最后一层的输出状态hi,t输入到softmax分类器,计算出驾驶动作的分类结果向量yp。
在此期间,可以利用公式一下的公式:
yp=softmax(wh3,t+b);(10)
其中,softmax是归一化指数函数,w是全连接层的权重矩阵,b是偏置向量,它们可用于调整h3,t的大小。当st-sru模型内部状态的尺寸大小为d时,对于k个类别的驾驶动作,则w的大小为k×d,b的大小为1×b。
简单来说,发明的研究思路是综合考虑mobilenetv3和st-sru分类模型的优点,首先采用mobilenetv3卷积网络提取人体关节点的特征,其次同时考虑同一帧中不同关节点的时间和空间依赖关系,建立时空简单循环单元(spatio-temporalsru,st-sru)模型,进而对骨架序列特征进行分类。
本发明的工作原理如下:
假设要识别j个骨节点,本发明采用改进的mobilenetv3倒数第三层滤波器个数为3j的1×1卷积层,作用是将上一层输出的特征图的通道数从576调整为3j,此时特征图的大小为72×3j,分辨率仍然很低。
接着,我们添加了一个转置卷积层(transposeconvolutionlayer)来提升特征图的大小,我们将经过转置卷积层后的特征图大小设计为562×3j,是因为224正好是56的4倍。
最后一层是双线性插值层,它通过双线性插值(bilinearinterpolation)将特征图的大小调整为2242×3j并作为输出值。
最终得到的mobilenetv3的可训练参数数量为2863360,相比于其他姿态估计结构,参数量有了很大减少。
通过上述的文字表述并结合附图可以看出,采用本发明后,拥有如下优点:
1、采用基于mobilenetv3的轻量级卷积神经网络获取驾驶员关节点坐标,相对于现有的深层的cnn模型,所提方法大大降低了参数数量,提高了算法的运行速度。
2、使用st-sru模型对二维关节点坐标序列进行分类,利用st-sru模型综合考虑同一帧中不同关节点的时间和空间依赖关系,具有计算效率高、推理速度快的优势,用于对获得的关节点坐标序列进行分类,能够克服lstm、gru等循环网络由于存在计算顺序依赖导致推理速度缓慢的问题。
3、本发明使用st-sru模型进行动作分类,提升了驾驶动作识别的准确率和速度。
此外,本发明所描述的指示方位或位置关系,均为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或构造必须具有特定的方位,或是以特定的方位构造来进行操作,因此不能理解为对本发明的限制。
同样,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。在本发明的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。
以上所述仅是本发明的优选实施方式,并不用于限制本发明,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变型,这些改进和变型也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!