基于数据增强的卷积神经网络运动想象脑电分类方法与流程
本发明涉及脑机接口与模式识别领域,具体涉及一种基于数据增强的卷积神经网络的运动想象脑电信号分类方法。
背景技术:
脑机接口(braincomputerinterface,bci)技术是一项新兴的技术,近年来受到了广泛的关注。bci创建了一个新的非肌肉交互通道,人类可以通过使用由脑部活动产生的信号,与周围环境进行交互,而不需要周围神经和肌肉的参与。通过对信号的模式识别,实现将人的意图传递给外部设备,如计算机、语音合成器、辅助设备和神经修复。脑机接口在医学领域,神经生物学领域和心理学领域都有重要的应用。基于运动想象(motorimagery,mi)的脑电信号(electroencephalogram,eeg)是一种内源性自发脑电信号,具有操作简单、范式灵活、成本较低、移植性好、风险小等优点,已经得到了广泛的研究,尤其在神经康复、神经修复和游戏等领域具有广泛应用潜力。不仅可以帮助中风偏瘫等有严重运动障碍的患者进行康复训练,控制设备实现自理,还可以娱乐普通大众,如与虚拟现实技术相结合的各种脑记游戏。
脑机接口系统一般由信号采集部分、预处理或信号增强部分、特征提取部分、分类判别部分、控制接口部分五部分组成。提高脑电信号分类准确率是整个系统的核心,即有效的信号特征提取与分类方法以将运动想象的脑电信号转化为设备或者应用程序的控制。由于其信号具有个体差异大、信噪比低、信号不平稳等特点,影响信号的分类性能和模型训练的准确率。当前基于运动想象的脑电信号数据稀缺,脑电数据收集相对昂贵,同时又涉及隐私安全问题,基于运动想象的脑电信号公开数据集较少且样本数量也较少。
技术实现要素:
有鉴于此,本发明的目的是一方面提供一种基于卷积神经网络(convolutionalneuralnetworks,cnn)的模型训练方法;另一方面,在此卷积神经网络模型的基础上进一步提供了一种数据增强方法,通过该方法可弥补基于运动想象的脑电数据匮乏,并提高了信号的分类准确率。
一种运动想象脑电信号分类方法,包括如下步骤:
在physionet数据集中获得至少两类运动想象任务的脑电信号数据;
将所述脑电信号数据输入到卷积神经网络中进行训练,由此实现对脑电信号数据的分类;
其中,所述卷积神经网络的第一层为卷积层,对脑电信号数据沿时间轴执行卷积操作,且输出数据尺寸与输入时一致;
第二层为卷积层,对脑电信号沿着eeg通道轴进行卷积,输出尺寸减为输入的一半;
第三层为最大池化层,用于对脑电信号沿时间轴进行池化,核的大小为30个样本,步长为15;层后的结构进行扁平化处理,形成6300个单维神经元;
最后三层为三个完全连接层,第一个全连接层将神经元的个数从6300降到100,第二个全连接层将神经元的个数从100降到32,最后一个全连接层为softmax层,将神经元的个数从32降到要分类的数据中的神经元数量。
进一步的,对所述脑电信号数据进行数据增强再进行训练,具体为:
对于physionet数据集中的原始脑电数据,对每次试验的每个通道的脑电数据进行归一化;
随机选择两组以上同类标签的脑电信号数据,将这些脑电信号数据按通道进行叠加并标准化,生成新的脑电信号数据。
较佳的,卷积神经网络的第一层,采用100个滤波器,核的大小为30个样本,步长为1。
较佳的,采用samepadding方法,对脑电信号数据填充0,以使卷积操作后输出尺寸与输入相同。
较佳的,卷积神经网络的使用100个滤波器,核的大小为30个样本,步长为1。
较佳的,卷积神经网络的第三层,核的大小为30个样本,步长为15。
较佳的,卷积神经网络采用adam优化器、relu激活和分类交叉熵的代价函数。
本发明具有如下有益效果:
本发明的一种基于数据增强的卷积神经网络的运动想象脑电信号分类方法,对所有受试者的64通道信号进行五倍交叉验证得其二、三和四类分类任务的平均准确性分别达到87.32%,76.26%,64.72%。利用迁移学习使全局分类器应用到单个受试者脑电信号分类中,其平均准确率达到了91.06%,82.76%,73.46%。与dose的工作相比,本发明提出的架构性能更好。
在数据增强之后,对四类分类数据进行数据增强。其平均准确率分别从64.72%提高到66.73%(全局模型),73.46%提高到76.78%(受试者模型),这表明该数据增强方法可以有效地提高脑电信号分类准确率。
附图说明
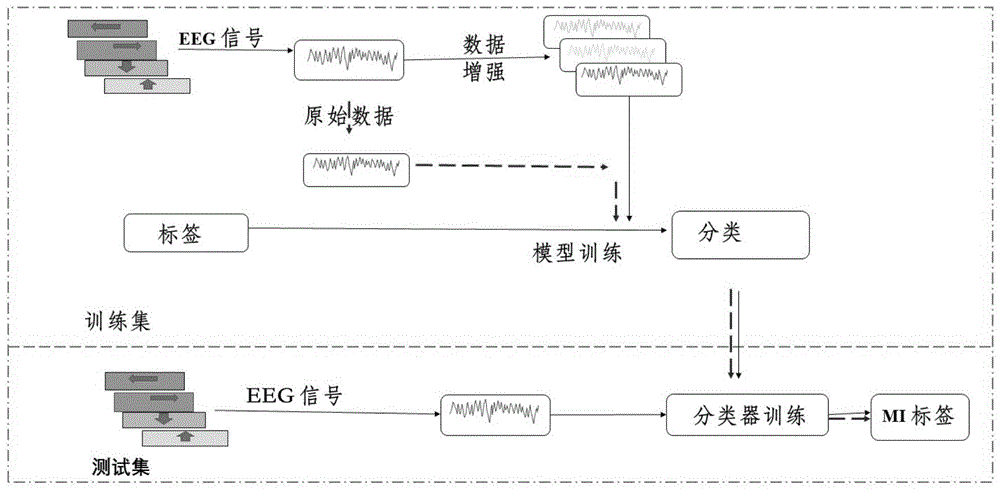
图1为本发明的训练流程框图;
图2为在全局模式下数据增强后的平均准确率;
图3为在受试者模式下数据增强后的平均准确率;
图4为数据增强前后两种训练模型的平均准确率;
图5为卷积神经网络框架示意图;
图6为数据增强原理图。
具体实施方式
下面结合附图并举实施例,对本发明进行详细描述。
本发明分为两部分,第一部分为卷积神经网络结构的研究,第二部分为在此网络结构的基础上数据增强方法的研究。
整个实验流程如图1所示。本发明采用的是公开数据集:physionet数据集(当受试者想象身体任何部位的运动时,脑电信号被采集)。在模型训练过程中,先是只采用了卷积神经网络方法进行训练,接着在此卷积神经网络的基础上进一步提出了一种新的数据增强方法进行训练。都采用五倍交叉验证方法,以上模型统称为全局模式。此外,在以上两种训练模型中都引入了迁移学习方法,将上述的全局分类器应用到单个受试者脑电信号分类中,并采用四倍交叉验证方法。即在全局分类器的基础上,在对单个受试者3/4的数据进行训练,剩余1/4进行测试。对进行迁移学习后的模型统称为受试者模型。
1、数据集:
当前基于运动想象的脑电信号数据稀缺,脑电数据收集相对昂贵,同时又涉及隐私安全问题,其公开数据集少。本发明使用的是公开数据集:physionet数据集,该数据集由超过1500个一分钟和两分钟的脑电图组成,共有109名受试者参与实验。每个受试者进行14次大组实验,包括运动执行任务和运动想象任务两部分,使用bci2000系统记录了64通道的脑电数据。本实施例中仅采用了运动想象任务的数据,包括4项想象运动(想象左手掌的开闭、想象右手掌的开闭、想象双手掌的开闭、想象双脚的开闭)和一项基线任务(睁眼或闭眼静息阶段)。
数据分类情况如示,对于二分类:数据集包含右手和左手开合的试验数据,每类21组实验数据,每位受试者共42组数据。对于三分类:在二分类数据中加入21组静息状态任务数据,即受试者在睁眼或闭眼情况下不执行任何运动想象任务,每位受试者共63组数据。对于四分类:在三分类数据中加入21组双脚开合的数据,即每位受试者共84组数据。每组数据包含6秒(960个样本)的数据长度,4秒的运动想象和前后1秒的空闲时间。
2、卷积神经网络结构:
卷积神经网络结构示意图如图5所示,从左到右表现为:c100@30×1–c100@1×30–p@30×1–flatten–fc@100–fc@32–softmax.
第一层对脑电信号沿时间轴执行卷积。使用了100个滤波器,核的大小为30个样本,步长为1,并采用samepadding方法,即在输入的数据周围填充0,以使卷积操作后输出尺寸与输入相同,用于保留体系结构的维度。这一层相当于对每个通道的脑电信号进行线性预滤波,被称作时间过滤(temporalfiltering)。
第二层沿着脑电信号的eeg通道轴进行卷积。使用了100个滤波器,核的大小为30个样本,步长为1,采用了validpadding方法即未在输入周围填充,卷积操作后输出尺寸会变小,将通道大小减半,以减少低效通道的影响。这一层可以减少通道之间的维数以及与运动无关的区域的影响,被称作空间过滤(spatialfiltering)。
第三层是最大池化层(maxpoolinglayer)。沿时间轴进行池化,核的大小为30个样本,步长为15。使用最大的池层来执行降维,在特征映射中有一些特性可以很好地概括,并提供一个更健壮的体系结构。
接着对最大池化层后的结构进行扁平化处理(flatten),形成6300个单维神经元。接着是三个完全连接(fc)层。第一个全连接层将神经元的个数从6300降到100,第二个全连接层将神经元的个数从100降到32,最后一个全连接层也称为softmax层,将神经元的个数从32降到要分类的数据中的神经元数量(n-class)。
在该体系结构中,使用了adam优化器、relu激活和分类交叉熵的代价函数。
基于该卷积神经网络结构对所有受试者的64通道信号进行五倍交叉验证得到的模型称为全局模型(globalmodel),其二、三和四类分类任务的平均准确性分别达到87.32%,76.26%,64.72%。利用迁移学习使全局分类器应用到单个受试者脑电信号分类中,经过迁移学习后得到的模型称为受试者模型(subjectmodel),其平均交叉验证准确性达到了91.06%,82.76%,73.46%。当去除bci文盲(分类准确率低于盲猜率的受试者)的数据集后,在全局模型中,104名被试的二、三、四类分类任务的平均准确率分别为88.32%、78.02%、66.36%。基于主题模型的二、三、四类分类任务的平均准确率分别为91.92%、83.78%、74.60%。与dose的工作相比,我们提出的架构性能更好。
仅选取与运动区域相关的16个通道数据,运用与上述同样的方法进行数据处理,得全局模式中二、三、四类分类任务的平均准确率分别为83.57%,72.23%,59.74%。受试者模式中二、三、四类分类任务的平均准确率分别为87.88%,79.64%,68.03%。如表1所示,与其他文献的神经网络结构性能对比,可见本发明的神经网络结构性能更优秀。
表1:不同研究在physionet数据集上的左手/右手运动想象的二分类结果。包括所使用的脑电通道数量、训练模式(全局模型或受试者模型)、所达到的平均精度以及用于特征提取和分类的方法。
3、数据增强:
训练一个有效的深度学习模型需要大量的训练数据,因为在深度学习模型中大量的参数需要调整,而数据增强技术能很好的解决数据不足的问题。在众多领域,它是将现有的训练数据经过移位、缩放、旋转等变换,人为地生成新的数据样本。但因为脑电信号具有非平稳性,这些相似的几何变换并不适用于脑电信号。因此,选择合适的数据增强方法,能保留原始信号的特征显得尤为重要。
pfurtscheller等人的研究结果表明,右手运动想象会伴有对侧β事件相关去步和同侧β事件相关同步现象。基于此,我们发明了一种新的数据扩充方法,即叠加方法,其主要思想是将具有同类标签的运动想象脑电数据叠加并归一化以生成新的人工数据。具体步骤如下:
按第一部分数据集的要求,提取109个受试者的64个脑电通道的基于运动想象的原始脑电数据及其对应的标签;
对每次试验的每个通道的脑电数据进行归一化。(某通道的本次试验的原始脑电信号值减去此通道此次试验原始脑电信号平均值,然后除以此通道此次试验原始脑电信号的标准差)。
随机选择n个(n为参数)同类标签的试验,将着n组脑电数据按通道进行叠加并标准化,生成新的人工数据。
如图6所示,其左侧脑电信号是随机选取的physionet数据集中右手运动想象脑电信号标准化后的曲线。可见,右手运动想象可能伴随有对侧beta事件相关去同步和同侧beta时间相关同步现象,特别是在a),b),w)中很明显。对这些随机选取得到的右手运动想象脑电信号进行上述的数据增强方法后,得到如图6右侧所示的曲线。可见,经过数据增强的人工脑电信号还伴有对侧beta事件相关去同步和同侧beta事件相关同步现象。
由此可见,该数据增强方法可以保留脑电信号的固有特性,已可证明该方法的有效性。
本发明所提出的数据增强方法可产生大量保留特征的脑电人工样本,并将该方法在所有受试者(109名)的64通道数据中进行四分类测试。图2显示了全局模型在不同参数下的平均准确率,横坐标表示同类信号叠加的层数,颜色条表示数据增强的倍数,蓝色虚线表示数据增强前的平均准确率(即未进行数据增强的平均准确率)。从图2可以看出,在全局模型中该数据增强方法可以提高信号分类性能。当数据增强倍数小于20,同类标签叠加层数小于10时,精度将显著提高。且经过20倍的数据增强和5倍的标签叠加,达到了66.73%的最高平均准确率。
和图2类似,图3是在受试者模式下数据增强后的平均准确率。从图2可以看出,无论数据增强倍数和信号叠加层数是多少,数据增强后的分类性能都有显著提高。但是,随着数据增强倍数的增加,代码的内存占用会增加,代码运行时间也会更长。因此当考虑电脑内存和运行时间的情况下,10倍的数据增强和5层的信号叠加是一个较好的选择。但是纵观全局,20倍的数据增强和5层的信号叠加,达到最高平均准确率:76.78%。
数据增强前后训练的全局模型和受试者模型的准确率如图3所示。从图3可以看出,数据增强可以有效地提高卷积神经网络算法的分类准确率。全局模型和受试者模型的四分类平均准确率分别从64.72%提高到66.73%,73.46%提高到76.78%,这说明了该数据增强方法的可行性以及有效性,尤其是在引入迁移学习后的受试者模型中。
综上所述,以上仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!