一种面向航拍影像的无监督车辆重识别方法与流程
本发明涉及计算机视觉附属装置的技术领域,特别是涉及一种面向航拍影像的无监督车辆重识别方法。
背景技术:
目标重识别技术是目标广域检索与长时跟踪、轨迹预测,以及智慧城市、平安工程等应用的基础,具有重要的研究意义和应用价值。车辆重识别是实现高效交通监控和智能城市监控的重要技术之一。给定查询目标车辆图像,车辆重识别需要在监控摄像头或网络中收集的大规模车辆图像库中查找属于同一车辆的图像。当前的车辆重识别方法主要分为三类:基于度量学习进行全局特征优化;融合局部细节进行高判别力特征学习;基于视角信息学习视角鲁棒特征。虽然车辆重识别已经取得较大发展,但是这些方法都依赖于大量的人工标注数据的训练。
目前,还没有无监督车辆重识别算法的相关工作,但关于行人的无监督重识别算法已经被广泛关注和研究,主要分为两类:减小源数据集和目标数据集的分布差异,然后把在源数据集上学到的模型直接应用到目标数据集上;利用源数据集学到的模型对目标数据集聚类然后标注伪标签,根据得到的伪标签微调网络参数。这些无监督重识别方法都会利用一个或多个源数据集来提高网络模型在目标数据集上的泛化性能。但是,当源数据和目标数据分布差异过大时,这种迁移学习方法和聚类方法就很难获得比较好的性能。如果可以不依赖任何其他相关数据集和标签,直接从原始视频中自动标注车辆id(identification,身份标识号)并学习重识别特征,则会极大地方便重识别技术的扩展和落地。利用无监督跟踪技术自动标注视频中车辆的id可以减轻重识别技术对大量人工标注数据的依赖。而先前的工作并没有类似解决问题的方法。
技术实现要素:
为解决上述技术问题,本发明提供一种可以直接从采集的原始视频中无监督的学得车辆重识别特征表示的面向航拍影像的无监督车辆重识别方法。
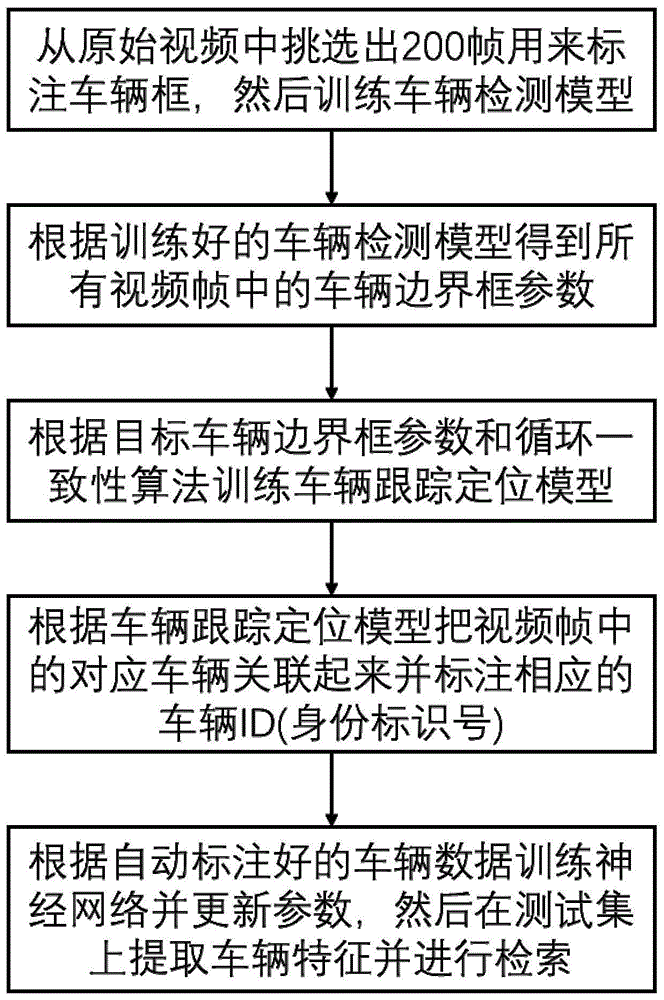
本发明的一种面向航拍影像的无监督车辆重识别方法,包括以下步骤:
(一)、从原始视频中随机挑选出200帧用来标注车辆框,然后训练车辆检测模型;
(二)、根据训练好的车辆检测模型得到所有视频帧中的车辆的位置和边界框参数。
(三)、根据目标车辆边界框参数和循环一致性方法训练车辆跟踪定位模型。
(四)、根据车辆跟踪定位模型把视频帧中的对应车辆关联起来并标注相应的车辆id(身份标识号)。
(五)、根据自动标注好的车辆数据训练神经网络并更新参数,然后在测试集上提取车辆特征并进行检索。
本发明的一种面向航拍影像的无监督车辆重识别方法,所述步骤(一)中,训练车辆检测模型时,选择目标检测任务中广泛使用的ssd作为车辆检测的基础模型。
本发明的一种面向航拍影像的无监督车辆重识别方法,所述步骤(二)中,边界框参数即为车辆目标的四个顶点在帧中的相对位置。
本发明的一种面向航拍影像的无监督车辆重识别方法,所述步骤(四)中,在把对应车辆关联起来并标注相应的车辆id的过程中,采用车辆检测框替代车辆定位区域及时修正跟踪定位结果。
本发明的一种面向航拍影像的无监督车辆重识别方法,所述步骤(三)中,引入自监督三元组损失函数辅助车辆特征表示学习。
本发明的一种面向航拍影像的无监督车辆重识别方法,所述步骤(五)中,把自动标注的车辆数据与人工标注的车辆数据相结合进行网络训练,进一步提高车辆特征的表示能力。
与现有技术相比本发明的有益效果为:设计了一个循环一致性学习方法,用来无监督的学习一个车辆跟踪定位模块,并引入三元组损失函数优化跟踪定位模块的训练,同时加速网络收敛;训练阶段可以挖掘海量的无标签视频数据的内在对应关系,测试阶段可以根据前一帧中目标车辆的位置推断出目标车辆在下一帧中出现的位置;利用学到的车辆跟踪定位模块,解决视频中无标签车辆数据自动分配标签的问题;能根据海量的无标签视频数据,自动标注视频中各个车辆的id信息,减轻车辆重识别技术对大量人工标注数据的依赖;在自动标注车辆数据集的过程中,采用车辆检测框替代车辆定位区域及时修正跟踪定位结果;使得从视频帧中抠出和标注的车辆图片更加准确,进而可以获得更好的车辆特征表示能力;在自动标注车辆数据集后,利用同标签之间特征距离关系去除一些噪声图片;使得自动标注的车辆数据集更加干净、准确,进而有利于获得更好的车辆特征表示能力;将自动标注的车辆数据与人工标注的车辆数据相结合进行模型训练;首先利用自动标注的车辆数据预训练网络,然后再在人工标注的车辆数据上做微调,可以极大地提高车辆特征的表示能力;相比于之前基于迁移学习或聚类的无监督重识别算法依赖相关源数据集来辅助训练,该方法可以直接从采集的原始视频中无监督的学得车辆重识别特征表示。不需要相关的辅助数据集可以极大地方便重识别系统的扩展和落地应用。另外采用循环一致性方法,把原始视频中各个车辆的图片序列关联起来,进而自动获得各车辆的身份标签信息,可以极大地缓解再识别任务对人工标注数据的依赖。
附图说明
图1是本发明的流程图;
图2是循环一致性学习算法装置图;
图3是定位模块结构图;
图4是训练数据量的大小对再识别性能的影响结果图;
图5是车辆序列自动标注结果展示图;
图6是三元组损失对最终车辆再识别性能的影响表;
图7是采用车辆检测框替代车辆定位区域及时修正跟踪定位结果对最终车辆再识别性能的影响表;
图8是结合自动标注数据和有监督数据的性能展示表;
附图中标记:
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
实施例:
由图1可知,包括如下步骤:
1、从原始视频中随机挑选出200帧用来标注车辆框,然后训练车辆检测模型。具体而言,在步骤1训练车辆检测模型时,选择目标检测任务中广泛使用的ssd作为车辆检测的基础模型。把从训练视频中随机抽取的200帧图像和对应的车辆框标注文件作为输入(输入图像尺寸缩放到512*512大小),训练检测模型ssd,模型收敛后保存模型参数。
2、根据训练好的车辆检测模型得到所有视频帧中的车辆的位置和边界框参数θ。边界框参数即为车辆目标的四个顶点在帧中的相对位置。例如,以帧的左上角为(0,0),右下角为(1,1)进行坐标归一化。
3、根据目标车辆边界框参数和循环一致性方法训练车辆跟踪定位模型lm(localizationmodel)。在训练时,通过无监督的方式,在每一帧中选取一个三元组构建三元损失函数,进而辅助车辆跟踪定位模型更好更快地收敛。
由图2和图3可知,具体而言,前向跟踪定位时,根据两张连续帧图片it,it+1及图片it中对应的车辆位置参数θt,从it中随机选择一个车辆位置
其中
根据
l=lθ+λ1lsim+λ2ltri
其中,λ1与λ2为权重系数。
4、根据车辆跟踪定位模型lm把视频帧中的对应车辆关联起来并标注相应的车辆id(identification,身份标识号)。其中,在把对应车辆关联起来并标注相应的车辆id的过程中,采用车辆检测框替代车辆定位区域及时修正跟踪定位结果。同时在自动标注车辆数据集后,利用同标签之间特征距离关系去除一些噪声图片,使得自动标注的车辆数据集更加干净、准确。
具体而言,因为学到的lm可以根据当前帧中目标车辆的位置定位出目标车辆在下一帧中出现的位置,所以我们可以连续的使用lm来得到目标车辆在之后帧中出现的所有序列图片,然后把它们标注成相同的id。但是,lm可能出现误差,连续使用可能会使误差放大,所以利用定位结果附近的车辆检测框来修正lm的跟踪定位结果可以使得自动获得的车辆序列更加准确。当定位结果附近没有检测框时或者是最相近的车辆检测框不对时,自动标注的序列里会出现车辆框不准或id标注错误的干扰图片。如果能去除这些干扰图片再训练网络,会更加有利于提升车辆再识别的性能。首先利用自动标注的车辆序列训练一个车辆特征编码网络,然后提取出序列中所有车辆图片的特征,对于相同id的车辆序列,计算序列中所有图片到初始目标(序列中第一个车辆图)的特征距离,超过一定阈值的就从序列中去除掉。
5、根据自动标注好的车辆数据训练神经网络并更新参数,然后在测试集上提取车辆特征并进行检索。结合少量人工标注的数据,可以进一步大幅提升车辆再识别性能。
该实施例中的实验结果是根据无人机拍摄的车辆图片数据库(uav-veri)上测试得出。经试验得到体现技术效果的表格如下:
图6为三元组损失(tripletloss)对最终车辆再识别性能的影响,其中:
cclm-w/o-tl代表不使用三元组损失的方法;
cclm-w/-tl代表使用三元组损失的方法。
从图6可以看出,使用三元组损失可以提升最终的车辆再识别性能。
图7为采用车辆检测框替代车辆定位区域及时修正跟踪定位结果对最终车辆再识别性能的影响,其中:
sllm-w/o-rvs代表不修正车辆跟踪序列的方法;
sllm-w/-rvs代表修正车辆跟踪序列的方法。
从图7可以看出,采用车辆检测框替代车辆定位区域及时修正跟踪定位结果可以提升最终的车辆再识别性能。
由图4可以看出,随着训练帧数的增多,性能也逐渐上升。因为这些训练用的视频帧都是不需要手动标注id的,所以表明我们的方法非常容易扩展。
由图5可以看出,其中每一行为自动标注的连续10帧中的相同id的车辆图片。前5个图片为不使用车辆检测框修正车辆跟踪序列的结果,后5个图片为使用车辆检测框修正车辆跟踪序列的结果。可以看出,我们方法的有效性。
图8为结合自动标注数据和有监督数据,联合训练以提升再识别性能的结果,其中:
fullysupervised代表只使用有标签数据来训练神经网络,然后在测试集上测试的方法;
weaklysupervised代表只使用自动标注数据来训练神经网络,然后在测试集上测试的方法;
s+w代表把自动标注数据和有标签数据混在一起之后训练神经网络,然后在测试集上测试的方法;
s->w代表先用有标签数据训练神经网络,然后再用自动标注数据进行微调网络的方法;
w->s代表先用自动标注数据训练神经网络,然后再用有标签数据进行微调网络的方法。
从图8可以看出,w->s相较于fullysupervised性能上有极大地提升。这表明我们提出的无监督再识别方法,既可以达到有监督方法的良好性能,又可以辅助有监督数据进一步提升性能。
附件:
[1]h.liu,y.tian,y.wang,l.pang,andt.huang,“deeprelativedistancelearning:tellthedifferencebetweensimilarvehicles,”incvpr,jun.2016,pp.2167–2175.
[2]y.bai,y.lou,f.gao,s.wang,y.wu,andl.-y.duan,“groupsensitivetripletembeddingforvehiclereidentification,”tmm,pages2385–2399,sep.2018.
[3]b.he,j.li,y.zhaoandy.tian.part-regularizednear-duplicatevehiclere-identification.incvpr,2019.
[4]z.wang,l.tang,x.liu,z.yao,s.yi,j.shao,j.yan,s.wang,h.liandx.wang.orientationinvariantfeatureembeddingandspatialtemporalregularizationforvehiclere-identification.incvpr,2017.
[5]r.chu,y.sun,y.li,z.liu,c.zhang,y.wei.vehiclere-identificationwithviewpoint-awaremetriclearning.iniccv,2019.
[6]p.khorramshahi,a.kumar,n.peri,s.rambhatla,j.chenandr.chellappa.adual-pathmodelwithadaptiveattentionforvehiclere-identification.iniccv,2019.
[7]l.qi,l.wang,j.huo,l.zhou,y.shi,andy.gao.anovelunsupervisedcamera-awaredomainadaptationframeworkforpersonre-identification.iniccv,2019.
[8]a.wu,w.-s.zheng,andj.-h.lai.unsupervisedpersonre-identificationbycamera-awaresimilarityconsistencylearning.iniccv,2019.
[9]y.lin,x.dong,l.zheng,y.yan,andy.yang.abottom-upclusteringapproachtounsupervisedpersonre-identification.inaaai,2019.
[10]y.fu,y.wei,g.wang,y.zhou,h.shi,andt.s.huang.selfsimilaritygrouping:asimpleunsupervisedcrossdomainadaptationapproachforpersonre-identification.iniccv,2019.
[11]w.liu,d.anguelov,d.erhan,c.szegedy,s.reed,c.-y.fu,anda.c.berg.ssd:singleshotmultiboxdetector.ineccv,2016.
[12]i.rocco,r.arandjelovic,andj.sivic.convolutionalneuralnetworkarchitectureforgeometricmatching.incvpr,2017.
[13]i.rocco,r.arandjelovi′c,andj.sivic.end-to-endweaklysupervisedsemanticalignment.incvpr,2018.
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变型,这些改进和变型也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!