一种基于开放数据过滤和域适应的视频异常检测方法与流程
本发明涉及计算机视觉的技术领域,特别是涉及一种基于开放数据过滤和域适应的视频异常检测方法。
背景技术:
异常检测是实现智能视频监控的关键技术,可以自动检测视频中的异常事件。现有的视频异常检测方法可按照监督方式分为三类:半监督、无监督和有监督。半监督异常检测方法只使用正常数据训练检测模型,在测试时将不符合正常数据特征的事件确定为异常事件;无监督异常检测方法未使用已知的正常数据,仅通过参照视频上下文估算帧的可分辨性来检测异常。如果可以轻松地将一个帧与同一视频中的其他帧区分开,则将其标记为异常帧;有监督异常检测方法使用大量正常数据和少量异常数据训练异常检测模型,将异常检测视为不平衡二分类问题。
现有的方法通常利用异常事件和正常事件的差异性来衡量视频中的帧是否包含异常事件。但是,由于视频中事件的多样性和开放性,获得所有可能的正常事件并不现实,测试集中未见过的正常事件类型和训练集中的已知正常事件同样可能存在较大的差异性。那么未见过的正常事件将无法满足训练集中已知正常事件的特征,存在较大可能会被误判为异常事件,导致较高的假阳性率。
技术实现要素:
为解决上述技术问题,本发明提供一种基于开放数据过滤和域适应的有监督视频异常检测方法来衡量视频帧内是否存在异常,提高视频异常检测性能。
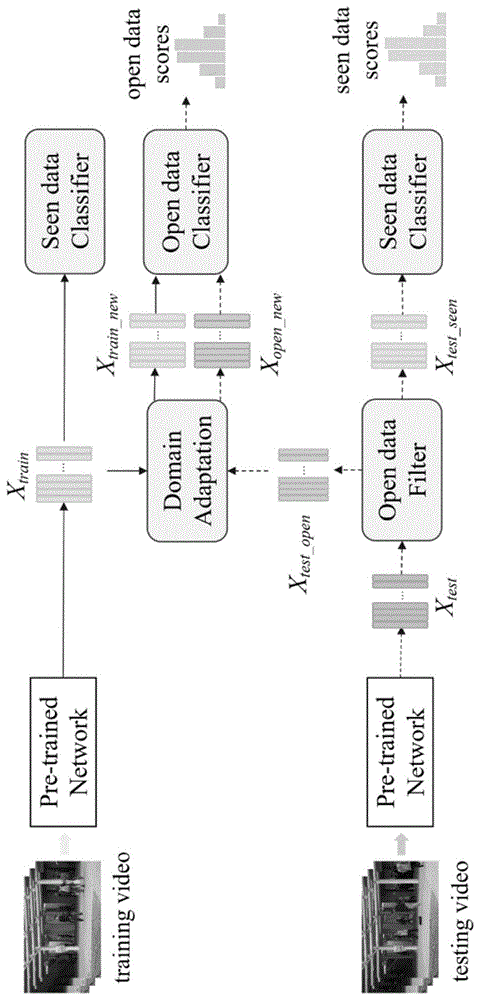
本发明的一种基于开放数据过滤和域适应的视频异常检测方法,包括:
使用在imagenet上训练好的vgg-f模型提取训练视频和测试视频的所有帧的外观特征,并使用训练视频的特征训练用于可见数据的分类器;
设计开放数据过滤器,该模块用于将测试数据分为可见数据和开放数据;该过滤器首先通过k-means聚类方法将已知训练数据分为若干类,然后将测试数据与已知训练数据类中心的最小距离作为测试数据的开放概率,最后在获得测试视频所有帧的开放概率后通过u-test方法确定最佳过滤比例,得到最终的可见数据和开放数据;
同时,引入联合分布适配方法(jointdistributionadaptation,jda),用于缩小开放数据和训练数据之间的分布差异,并获得新的开放数据和训练数据的特征表示;利用新的训练数据特征表示训练用于开放数据的分类器;
使用可见数据分类器生成测试集中可见数据的异常分数,使用开放数据分类器生成测试集中开放数据的异常分数,综合两者的异常得分获取整个测试视频的检测结果。
本发明的有益效果为:在对视频进行异常检测时,不仅考虑到了异常事件和已知正常事件之间的差异性,还考虑到了开放正常事件与已知正常事件之间的差异性,从而能够应对未见过的正常事件会被误判为异常事件的问题,提升异常检测性能;利用开放数据过滤器有效地将测试数据分为可见数据和开放数据,对两种数据采用不同的分类器获得异常得分,有效降低了测试集中的开放事件对异常检测性能造成的影响。
附图说明
图1是本发明的示意图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施用于说明本发明,但不用来限制本发明的范围。
构建训练集和测试集:从测试集中选取一定比例的异常帧加入训练集中,从而得到包含正常事件和异常事件的训练集且测试集中也包含一定比例的开放事件;
在训练阶段,利用预训练神经网络提取训练视频的特征,并使用该特征训练可见数据分类器。
在测试阶段,利用预训练神经网络获得测试视频的特征之后,开放数据过滤器将测试视频的特征分为已知数据和开放数据。该过滤器首先通过k-means聚类方法将已知训练数据分为若干类,然后将测试数据与已知训练数据类中心的最小距离作为测试数据的开放概率:
其中
在获得测试视频所有帧的开放概率后,通过u-test方法确定最佳过滤比例:
其中pnor(r)表示在过滤比例为r时,测试数据中可见数据的均值和训练数据中正常数据的均值之间的p值;pabnor(r)表示在过滤比例为r时,测试数据中可见数据的均值和训练数据中异常数据的均值之间的p值。两个p值之和越大,代表过滤掉测试数据中开放数据之后得到的可见数据和训练数据之间的差异越小,从而可以得到最佳比例的可见数据和开放数据。
由于sigmoid函数可以将实数平滑地映射到[0,1],因此该函数值可以用作测试帧异常的概率。对于可见数据,直接将可见数据分类器输出的测试帧属于异常类的概率作为异常分数:
其中gs表示可见数据分类器,θs表示可见数据分类器的参数,
对于开放数据,首先采用联合分布适配方法,缩小开放数据和训练数据之间的分布差异,并获得开放数据和训练数据的新的特征表示:
xtrain_new=4txs
xopen_new=4txt
其中4表示通过联合分布适配方法获得的最佳变换矩阵,xs是源训练数据的特征表示,xt是开放数据的特征表示。
然后用新的训练数据的特征表示训练开放数据分类器,并使用该分类器产生开放数据的异常分数:
其中gn表示开放数据分类器,θn表示开放数据分类器的参数,
最后综合可见数据和开放数据的异常得分,即可得出整个测试视频的异常检测结果。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变型,这些改进和变型也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!