一种基于加权协同表示的人脸识别方法与流程
本发明涉及一种图像识别方法,特别是一种基于加权协同表示的人脸识别方法,属于图像识别
技术领域:
。
背景技术:
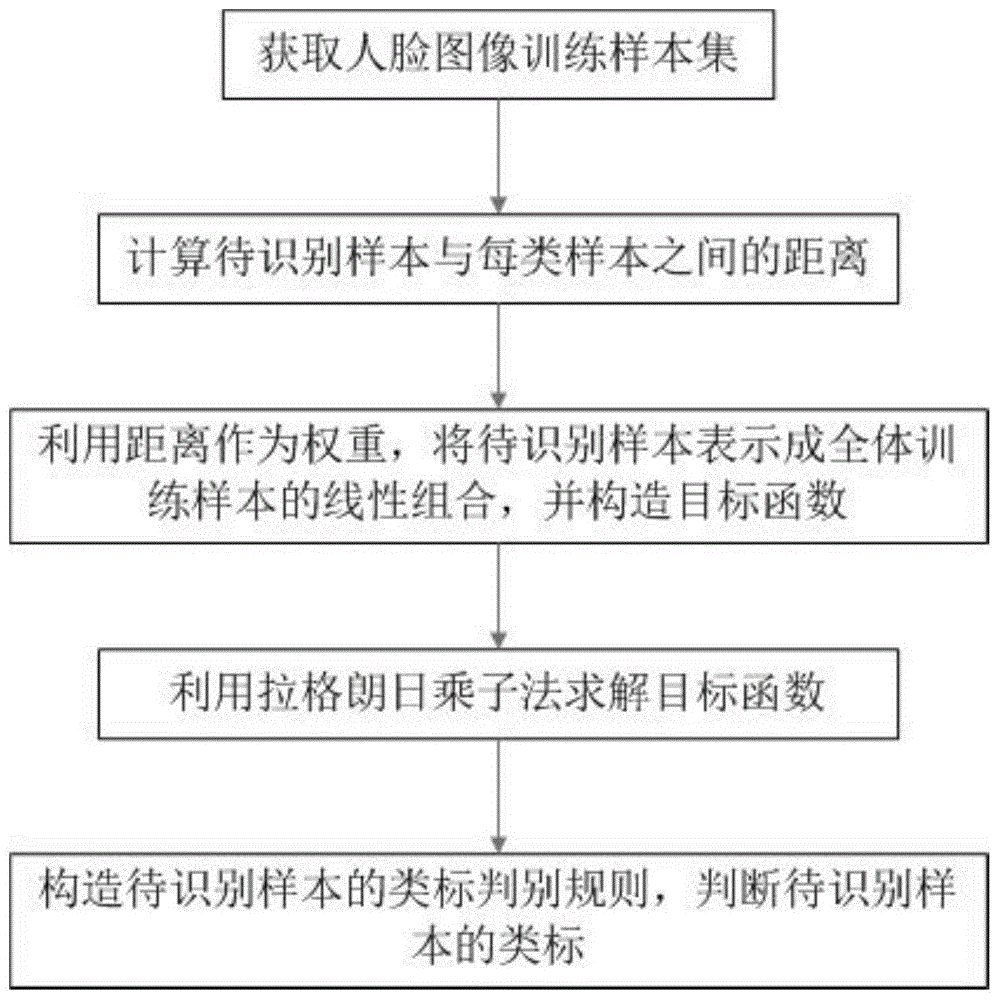
:人脸识别是身份鉴别的一种重要方法,在档案管理系统、安全验证系统、信用卡验证、公安系统的罪犯身份识别、银行和海关的监控、人机交互等领域有着广泛的应用前景。在过去的几十年里,研究者们提出了诸多人脸识别方法,其中基于表示学习的图像分类方法被广泛应用于人脸识别。比较著名的基于表示学习的图像分类方法有:(1)稀疏表示分类器(src),记载于j.wright,a.y.yang,a.ganesh,s.s.sastry,y.ma于2009年在ieeetransactionsonpatternanalysisandmachineintelligence第31卷第2期210-2272页发表的《robustfacerecognitionviasparserepresentation》,该方法假定待识别图像可由全体训练图像稀疏线性表示而成,通过求解l1范数最优化问题获得稀疏重构系数,然后根据待识别图像与每类训练图像的重构残差大小判断待识别图像的类别。(2)线性回归分类器(lrc),记载于i.naseem,r.togneri,m.bennamoun于2010年在ieeetransactionsonpatternanalysisandmachineintelligence第32卷11期2106-2112发表的《linearregressionforfacerecognition》,该方法假定待识别图像可由某类训练图像线性组合而成,通过求解l2范数最优化问题获得重构系数,然后根据待识别图像与每类训练图像的重构残差大小判断待识别图像的类别。(3)协同表示分类器(crc),记载于l.zhang,m.yang,x.feng于2011年在ieeeconferenceoncomputervision第471-478发表的《sparserepresentationorcollaborativerepresentation:whichhelpsfacerecognition》,该方法将待识别图像线性表示成全体训练图像的线性组合,利用最小二乘法求解重构系数,然后根据待识别图像与每类训练图像的重构残差大小判断待识别图像的类别。这三类方法基本思想较为相近,都是将待识别图像表示成某部分训练图像的线性组合,其中src需基于l1范数求解最优化问题,求解过程较为复杂,所耗时间较长;lrc与crc均是基于l2范数求解最优化问题,只需利用最小二乘法求解表示系数,求解过程简单,相较于src所耗时间较少。然而,lrc是假定待识别图像可由某类样本线性表示而成,其特征表达能力与每类样本的数目相关,当某类样本数较少时,其特征表达能力较弱,识别能力也会下降。crc在利用全体训练图像线性表示待识别图像时,并没有考虑不同类别样本之间的差异性,导致特征表达能力较弱,识别能力也会因此受到影响。技术实现要素:本发明所要解决的技术问题是,针对目前基于表示学习的图像分类方法中存在的缺陷,设计一种基于加权协同表示的图像分类方法并用于解决人脸识别问题,使得求解过程简单,计算速度较快,识别率较高。本发明为解决上述技术问题采用以下技术方案:本发明提出一种基于加权协同表示的人脸识别方法,包括如下步骤:步骤1、获取人脸图像训练样本集;所述训练样本集包括c个不同的类,对训练样本集中每个训练样本和待识别样本进行归一化处理,并利用基于主成分分析pca方法降低训练样本与待识别样本的数据维数;步骤2、计算待识别样本与每类样本之间的距离;步骤3、利用待识别样本与每类样本之间的距离作为权重,将待识别样本表示成全体训练样本的线性组合,并构造目标函数;步骤4、利用拉格朗日乘子法求解目标函数,获得训练样本对重构待识别样本的表示系数;步骤5、依据表示系数构造待识别样本的类标判别规则,判断待识别样本的类标。进一步的,本发明所提出的一种基于加权协同表示的人脸识别方法,步骤1所述对训练样本集中每个训练样本和待识别样本进行归一化处理,具体如下:假设每幅图像的大小为w×h,训练样本来自于c个图像类,每类人脸样本数均为n0,将每幅人脸图像进行矩阵向量化操作,得到第i幅人脸图像样本为xi∈rd,其中d=w×h;将训练样本集表示为x=[x1,x2,...,xn],将待识别样本可表示为y,其中i=1,2,...,n;n表示人脸图像训练样本数,且满足n=n0c;对于训练样本xi,进行模为1的归一化操作:xi=xi/||xi||2,同样,对于待识别样本y,也需进行归一化操作:y=y/||y||2。进一步的,本发明所提出的一种基于加权协同表示的人脸识别方法,步骤1所述利用基于主成分分析pca方法降低训练样本与待识别样本的数据维数,具体为:(1).令z=[x1-m,x2-m,…,xn-m],计算前d个非零特征值对应的特征向量,令λ1>λ2…>λd为前d个非零最大特征值,v1,v2,…,vd为相应的特征向量;(2).将pca投影向量表示为:(3).令apca=[a1,a2,…,ad],则pca预处理后的训练样本xi与待识别样本y为:xi=apcaτxi,y=apcaτy。进一步的,本发明所提出的一种基于加权协同表示的人脸识别方法,步骤2所述计算待识别样本与每类样本之间的距离,具体为:令di表示待识别样本y与第i类样本距离,则di计算式为:其中xij表示第i类第j个样本,||y-xij||2为y与xij的欧式距离,n0表示每类人脸样本数。进一步的,本发明所提出的一种基于加权协同表示的人脸识别方法,步骤3利用待识别样本与每类样本之间的距离作为权重,将待识别样本表示成全体训练样本的线性组合,并构造目标函数,具体为:令w=[w1,w2,…,wn]τ∈rn×1表示线性组合系数向量,其中wi表示训练样本xi对重构待识别样本y的表示系数;其中i=1,2,...,n;n表示人脸图像训练样本数;根据样本的类别,设w=[w1,w2,…,wc]∈rn×1,其中,为第i类样本对待识别样本y的重构表示系数向量,n0表示每类人脸样本数,c代表训练样本的图像类别,且满足n=n0c;结合待识别样本与每类样本之间的距离信息,对于待识别样本y,其可由全体训练样本协同表示为:y=d1x1w1+d2x2w2+…+dcxcwc=xλw;其中λ为对角矩阵,对角线上的元素λii=di,xi为第i类样本的集合且x=[x1,x2,…,xc];根据最小二乘法,线性重构向量w可通过求解以下目标函数获得:argminw||w||2,s.t.||y-xλw||2<ε其中ε>0表示重构误差。进一步的,本发明所提出的一种基于加权协同表示的人脸识别方法,步骤4所述利用拉格朗日乘子法求解目标函数,具体为:利用拉格朗日乘子法,目标函数等价于:其中β>0为可调节参数;令然后对目标函数求对w的偏导数,并将其设置为0,可得:求解以上目标方程,可得:且其中i∈rn×n为单位矩阵。进一步的,本发明所提出的一种基于加权协同表示的人脸识别方法,步骤5所述构造待识别样本的类标判别规则,判断待识别样本的类标,具体如下:待识别样本y与第i类样本的重构残差为:其中为向量中关于第i类样本的部分向量,将待识别样本的类标判别为具有最小重构残差的那一类,即:若γk=argminiγi,i=1,2,…,c,则可将待识别样本y归为第k类。本发明采用以上技术手段,与现有技术相比,具有以下技术效果:(1)基于l2范数求解重构系数向量,因此相较于src计算速度较快。(2)将待识别样本表示成全体训练样本的线性组合,而全体训练样通常远远多于每类样本数,因此相较于lrc方法,当每类样本数较少时,本发明仍具有较强的特征表达能力。(3)在构造目标函数时引入了训练样本的类别信息及待识别样本与每类训练样本先验的距离信息,因此相较于crc在面对人脸图像的表情、姿态、光照等变化时,特征表达能力较强,识别率较高。附图说明图1是本发明基于加权协同表示的人脸识别方法的流程图。图2是本发明实施例中人脸库中某人的16幅图片样例。具体实施方式下面详细描述本发明的实施方式,所述实施方式的示例在附图中示出,通过参考附图描述的实施方式是示例性的,仅用于解释本发明,而不能解释为对本发明的限制。本发明提供了一种基于加权协同表示的人脸识别方法,其将待识别图像线性表示成全体训练图像的线性组合,同时将待识别图像与每类样本的距离信息作为先验信息引入到特征表示函数中,增强了距离待识别图像较近的某类样本的重构权重,然后利用最小二乘法求解表示系数,最后根据待识别图像与每类训练图像的重构残差大小判断待识别图像的类别。具体流程如图1所示。(一)获取人脸图像训练样本集。假设每幅图像的大小为w×h,训练样本来自于c个图像类,每类人脸样本数均为n0,将每幅人脸图像进行矩阵向量化操作,得到第i幅人脸图像样本为xi∈rd,其中d=w×h。训练样本集可表示为x=[x1,x2,...,xn],待识别样本可表示为y,其中n表示人脸图像训练样本数且满足n=n0c。对于训练样本xi,进行模为1的归一化操作:xi=xi/||xi||2,(i=1,2,...,n)(1)同样,对于待识别样本y,也需进行归一化操作:y=y/||y||2(2)利用pca方法对归一化后的样本进行预处理以降低数据维数,基于主成分分析(pca)的人脸识别方法,记载于m.turk与a.pentland于1991年在journalofcognitiveneuroscience第3卷第1期71-86页发表的《eigenfacesforrecognition》中,该方法旨在寻找一个投影方向,使得人脸样本投影后总体散度最大。为方便起见,仍用x=[x1,x2,...,xn]和y代表pca预处理后的训练样本集和待识别样本,则计算步骤为:(4).令z=[x1-m,x2-m,…,xn-m],计算前d个非零特征值对应的特征向量。令λ1>λ2…>λd为前d个非零最大特征值,v1,v2,…,vd为相应的特征向量。(5).pca投影向量可表示为:(6).令apca=[a1,a2,…,ad],则可得pca预处理后的训练样本与待识别样本为:xi=apcaτxi,(i=1,2,...,n)(4)y=apcaτy(5)(二)计算待识别样本与每类样本之间的距离。令di表示待识别样本y与第i类样本距离,则di计算式为:其中xij表示第i类第j个样本,||y-xij||2为y与xij的欧式距离。(三)利用待识别样本与每类样本之间的距离作为权重,将待识别样本表示成全体训练样本的线性组合,并构造目标函数。令w=[w1,w2,…,wn]τ∈rn×1表示线性组合系数向量,其中wi表示训练样本xi对重构y的表示系数。根据样本的类别,可将w改写成w=[w1,w2,…,wc]∈rn×1,其中,为第i类样本对y的重构表示系数向量。结合待识别样本与每类样本之间的距离信息,对于待识别样本y,其可由全体训练样本协同表示为:y=d1x1w1+d2x2w2+…+dcxcwc=xλw(7)其中λ为对角矩阵,对角线上的元素λii=di,xi(i=1,2,…,c)为第i类样本的集合且x=[x1,x2,…,xc]。根据最小二乘法,线性重构向量w可通过求解以下目标函数获得:argminw||w||2,s.t.||y-xλw||2<ε(8)其中ε>0表示重构误差。(四)利用拉格朗日乘子法求解目标函数。利用拉格朗日乘子法,目标函数(8)等价于:其中β>0为可调节参数。令然后对目标函数(9)求对w的偏导数,并将其设置为0,可得:求解以上目标方程,可得:且其中i∈rn×n为单位矩阵。(五)构造待识别样本的类标判别规则,判断待识别样本的类标。待识别样本y与第i类样本的重构残差为:其中为向量中关于第i类样本的部分向量。所提发明的决策规则是将待识别样本的类标判别为具有最小重构残差的那一类,即:若γk=argminiγi,i=1,2,…,c,则可将待识别样本y归为第k类。为验证本发明的有效性,我们在常用的extendedyale-b人脸库上进行了实验,该库共有2432幅图片,包含38个人,每个人有64幅图片(均在不同光照环境下进行拍摄),每幅图像的分辨率为84×96,图2为该人脸库中某人的16幅图片样例。实验中,我们分别选择每人的前4、8、12、16、20、24幅图像作为训练样本,其余图像作为待识别样本用于测试。实验时,首先利用步骤1对训练图像和测试图像进行归一化处理,并利用pca方法将图像维数压缩至150,然后将参数β设为0.1。下表列出了本发明的人脸识别率:每人的训练样本数每人的待识别样本数识别率(%)46069.9185674.01125276.21164877.47204482.66244088.22综上,本发明基于l2范数求解最优化问题,因此求解过程简单,计算速度较快;另一方面,本发明利用了训练样本的类别信息及待识别样本与每类训练样本先验的距离信息,作为权重用于构造特征表示方程,因此相较于传统的crc方法,在一定程度上可增强所提模型的特征表达能力,从而可有效避免图像光照、人脸姿态、表情等变化对识别效果的影响,因此在面对人脸图像的表情、姿态、光照等变化时,特征表达能力较强,识别率较高。以上实例仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1