一种面向地质智能问答的数据自动化序列标注识别方法与流程
本发明涉及深度学习知识挖掘过程中的知识图谱应用技术领域,提出了一种实现智能问答平台的金矿数据自动化序列标注方法。
背景技术:
当前,智能问答服务作为人工智能发展阶段的重要应用,其相比于传统的规则匹配与共现检索匹配具有较大的认知能力。在实现过程中首先通过引入知识图谱实现知识的概念及关系关联,然后在用户问答过程中使用深度学习的自动化序列标注方法进行领域识别及意图识别,进而实现智能问答平台。
目前,针对问答系统的实现多依赖于正则模板匹配、elasricsearch的检索匹配,且在通用领域的问答较多,同时由于缺乏深入的语义知识解析,导致在特定领域实现智能问答服务具有挑战性。现有问答系统在处理中文文本时,一般通过分词技术将句子转化为词的表示,然后通过语义相似度计算(编辑距离、tfidf的向量余弦相似度)进行语句的知识库匹配进而实现用户的询问回复。其中分词技术包括基于规则词典匹配、基于统计机器学习与基于深度学习三个发展阶段。基于规则词典匹配包括正向最大匹配、逆向最大匹配双向最大匹配;基于统计机器学习包括n元语言模型、最大熵模型及条件随机场等;随着web2.0向web3.0迈进阶段产生的海量数据信息,基于深度学习的分词方法不断兴起,其包括卷积神经网络、循环神经网络及长短时记忆网络及与条件随机场相结合的方式等,其在识别过程中采用的标签方式为bio或者bioes标签。
现有标注方法的缺点:
(1)对于金矿知识挖掘发现过程中,大量数据信息的人工处理耗时耗力,且处理效率不高。
(2)针对分词工具的应用,严重依赖于词典的构建,当在金矿信息处理过程中,无法达到应用效果,其在通用领域效果较好。
(3)对于海量金矿数据的序列标注,在现有技术方法的基础上还需要借助于特定领域知识类别的结构化信息。
技术实现要素:
本发明旨在金矿数据的智能问答过程中实现用户问答交互效果的准确性,构建基于自动化序列标注的深度学习识别方法,采用金矿领域文献与图谱相结合的方式进行构建。
本发明为了解决上述技术问题,采用以下技术方案:
一种面向地质智能问答的数据自动化序列标注识别方法,包括以下步骤:
步骤1:对金矿文献图谱数据进行整理,得到领域实体分类描述标签(包含实体),作为领域知识实体识别的标注标签;
步骤2:对文献数据内容进行机器自动清洗,包括过滤英文字母、标点符号及无意义符号,得到有效中文文本内容;
步骤3:对清洗后的文本内容以单独的txt文件存放,得到批量文献数据的存放根路径;
步骤4:针对步骤3中得到的文献数据使用bioes标签进行字符数据的机器自动化标注,这里结合整理的图谱实体分类描述数据进行标签组合,得到由b、i、o、e、s开头的金矿数据标注结果;
步骤5:采用深度学习中双向lstm的模型与条件随机场crf结合方式对步骤4金矿数据标注结果字符序列数据进行输入训练,通过调整lstm模型中记忆细胞的结构及整体参数,加入整理的金矿图谱实体数据,得到金矿文献数据的训练结果;
步骤6:将文献数据的训练结果应用于平台用户询问语句识别,得到用户询问语句的标注结果;
步骤7:将用户询问语句的内容减去金矿数据标注结果的内容得到的剩余语句输入到卷积神经网络进行属性分类,得到用户询问语句的分类;
步骤8:将金矿数据识别结果与用户询问语句的分类通过map集合进行组合封装,得到用户询问语句中金矿数据的标注与询问语句语义属性的结果,例如{青藏高原=地质实体gent,的简介是什么=简介};
步骤9:将步骤8中的金矿数据的标注与询问语句语义属性的结果映射到金矿知识图谱,得到用户询问知识结果,进而实现智能问答。
上述技术方案中,对金矿文献图谱数据进行整理包括:
针对金矿文献数据通过地质百科大辞典、搜狗语料的人工整理搜集,并通过金矿领域知识构建分类描述标签,分类描述标签包括地质实体gent、地质作用geff、地质化学gehe、地质方法gmet。
上述技术方案中,步骤4中标签组合包括步骤:
首先对bioes标签进行字符划分,得到单字符字母b、i、o、e、s;
将单字符字母与步骤3中的txt文件内容进行自动化标注,得到由b、i、o、e、s开头的金矿数据标注结果。
上述技术方案中,进行自动化标注在金矿数据标注的基础上,首先使用金矿数据基于word2vec训练字符向量,然后使用深度学习中的双向神经网路lstm与条件随机场crf结合方式对金矿数据标注结果进行训练学习,通过调整模型参数得到金矿数据的训练结果。
上述技术方案中,用户询问语句识别,通过将用户询问语句输入到模型中,使用训练结果模型对用户语句信息的序列自动识别,得到用户询问语句的标注结果;
上述技术方案中,用户询问语句识别包括以下步骤:
(1)将用户询问语句通过http接口输入到平台中,首先得到用户语句的字索引(如青:15,藏:23,高:54,原:113等);
(2)将用户语句字索引通过步骤5的lstm与crf的组合模型训练结果进行进一步调用输出,得到由字符组合的词,即用户询问语句的标注结果。
上述技术方案中,用户语句分类,将输入到序列识别模型的其他未识别部分输入到卷积神经网络对其进行属性分类,这里通过标注数据的机器训练自动实现,得到用询问户语句分类。
本发明因为采用上述技术方案,因此具备以下有益效果:
1、金矿文献数据需要专业的知识技能进行处理应用,现采用机器的自动化序列标注识别,一方面降低减少了人工处理的复杂性;另一反面使得领域知识集中于内部,用户在使用过程中快速扩展而不需要专注于底层内部。
2、基于图谱金矿数据的自动化序列标注识别方法在智能问答过程中,为用户提供了便捷的交互方式,只需要输入询问语句即可,极大提高了金矿领域知识在应用过程中的便捷性。
3、自动化序列标注识别过程中不依赖于分词工具,只依赖于自动化的模型训练,极大减少了人力资源,同时在使用过程中模型只需要训练一次,期间使用都无需训练,只需调用即可。
4、对于模型技术的迁移只依赖于提供的文献数据,可根据不同数据方便快捷的定制化训练模型,降低了模型迁移风险。
5、采用图谱金矿数据的自动化序列标注识别方法使得智能问答相比于基于正则模板匹配与基于检索匹配更具有泛化能力。
附图说明
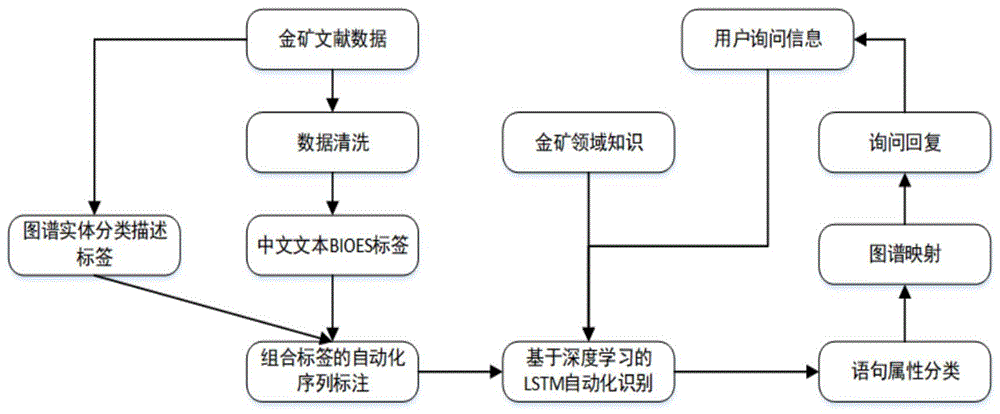
图1智能问答服务流程图;
图2基于bioes与金矿数据分类描述标签组合的序列标注图;
图3基于分词工具的标注处理流程;
图4自动化序列标注识别流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明,即所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。
因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,术语“第一”和“第二”等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
本申请为实现金矿智能问答平台所采用的基于图谱金矿数据自动化序列标注识别方法通过结合领域特征知识实现了用户的询问的及时准确回复。首先针对金矿数据文献进行搜集,通过去除无效符号及无意义标签得到中文文本内容;接着结合领域知识的分类结构信息构建出知识描述分类信息;之后通过对文本内容进行字符标签的自动化序列标注,这里结合领域知识分类描述标签进行字符的组合标签标注;接下来使用深度学习模型中的双向神经网络对金矿文本数据进行训练学习,通过调整参数达到满足自动化序列标注识别的阈值模型;紧接着使用得到的模型进行用户语句的序列识别,将去除序列识别的数据进行意图类,将分类结果与序列识别结果映射到金矿知识图谱进行用户询问查询,进而实现用户反馈。问答服务如图1所示。
上述步骤:
(1)数据整理。针对金矿文献数据进行整理搜集,并通过金矿领域知识构建分类描述标签,如地质实体gent、地质作用geff、地质化学gehe、地质方法gmet。
(2)数据清洗。将整理的文献数据通过文本批量处理得到文本内容,再经过正则匹配表达式的方式对文本内容格式清洗,得到有效的中文文本。
(3)批量存放数据。针对批量文本内容按照文章篇数使用python统一存放于一个固定根目录,以utf-8及txt文件形式存放。
(4)组合标签的自动化标注。通过对金矿数据文本内容逐条内容、逐个字符的读取,结合整理的金矿领域知识分类描述标签与传统的bioes标签进行组合标注,得到由b、i、o、e、s开头的金矿数据字符标注结果。如图2所示。
(5)深度学习的自动化序列识别。在数据标注的基础上,首先使用金矿数据基于word2vec训练字符向量,然后使用深度学习中的双向神经网路lstm与条件随机场crf结合方式对标注数据进行训练学习,通过调整模型参数得到金矿数据的训练结果(checkpoint文件保存)。这里不使用分词工具中对词语特征权重打分的识别方式,如图3所示。
(6)用户询问语句序列识别。通过将用户询问语句输入到模型中,使用训练结果模型对用户语句信息的序列自动识别,得到用户数据的标注结果。如图4所示。
(7)用户语句分类。将输入到序列识别模型的其他未识别部分输入到卷积神经网络对其进行属性分类,这里通过标注数据的机器训练自动实现,得到用户语句分类。
(8)用户序列标注结果与语句属性分类获取。通过将步骤6与步骤7中的结果组合实现用户语句信息理解,得到二者组合结果。
(9)图谱映射查询。将步骤8中的组合结果映射到金矿知识图谱中,通过知识图谱机构化查询得到反馈信息。
实施例
本发明提供了一种面向地质智能问答的数据自动化序列标注识别方法,包括以下步骤:
步骤1:对金矿文献图谱数据进行整理,得到领域实体分类描述标签(包含实体),作为领域知识实体识别的标注标签;
步骤2:对文献数据内容进行机器自动清洗,包括过滤英文字母、标点符号及无意义符号,得到有效中文文本内容;
步骤3:对清洗后的文本内容以单独的txt文件存放,得到批量文献数据的存放根路径;
步骤4:针对步骤3中得到的文献数据使用bioes标签进行字符数据的机器自动化标注,这里结合整理的图谱实体分类描述数据进行标签组合,得到由b、i、o、e、s开头的金矿数据标注结果;
步骤5:采用深度学习中双向lstm的模型与条件随机场crf结合方式对步骤4金矿数据标注结果字符序列数据进行输入训练,通过调整lstm模型中记忆细胞的结构及整体参数,加入整理的金矿图谱实体数据,得到金矿文献数据的训练结果(checkpoint文件保存)。;
步骤6:将文献数据的训练结果应用于平台用户询问语句识别,得到用户询问语句的标注结果;
步骤7:将用户询问语句的内容减去金矿数据标注结果的内容得到的剩余语句输入到卷积神经网络进行属性分类,得到用户询问语句的分类;
步骤8:将金矿数据标注结果与用户询问语句的分类通过用户询问语句相结合,得到用户询问语句中金矿数据的标注与询问语句语义属性的结果;金矿数据标注结果是指金矿文献中的实体部分,例如地质实体(青藏高原、火山机构)、地质作用、地质化学、地质方法;用户询问语句的分类是指用户针对实体部分询问的属性类别,例如:简介、种类、大小、关系、区域范围;
步骤9:将步骤8中的金矿数据的标注与询问语句语义属性的结果映射到金矿知识图谱,得到用户询问知识结果,进而实现智能问答。
上述方案中,对金矿文献图谱数据进行整理包括:
针对金矿文献数据通过地质百科大辞典、搜狗语料的人工整理搜集,并通过金矿领域知识构建分类描述标签,分类描述标签包括地质实体gent、地质作用geff、地质化学gehe、地质方法gmet。
上述方案中,步骤4中标签组合包括步骤:
首先对bioes标签进行字符划分,得到单字符字母b、i、o、e、s;
将单字符字母与步骤3中的txt文件内容进行自动化标注,得到由b、i、o、e、s开头的金矿数据标注结果。
上述方案中,进行自动化标注在金矿数据标注的基础上,首先使用金矿数据基于word2vec训练字符向量,然后使用深度学习中的双向神经网路lstm与条件随机场crf结合方式对金矿数据标注结果进行训练学习,通过调整模型参数得到金矿数据的训练结果。
上述方案中,用户询问语句识别包括以下步骤:
将用户询问语句通过http接口输入到平台中,首先得到用户语句的字索引(如青:15,藏:23,高:54,原:113等);
将用户语句字索引通过步骤5的lstm与crf的组合模型训练结果进行进一步调用输出,得到由字符组合的词,即用户询问语句的标注结果。
上述方案中,用户语句分类,将输入到序列识别模型的其他未识别部分输入到卷积神经网络对其进行属性分类,这里通过标注数据的机器训练自动实现,得到用询问户语句分类。
- 还没有人留言评论。精彩留言会获得点赞!