自动回复对话方法、系统及存储介质与流程
本发明涉及开放域对话系统技术领域,特别涉及一种自动回复对话方法、系统及存储介质。
背景技术:
智能对话系统是人工智能领域的一个重要研究方向,该系统能够实现让人与机器通过自然语言进行交互。当前,根据应用场景的不同,智能对话系统可以分为以下两种:一种是任务型对话系统,另一种是开放域对话系统。任务型对话系统以特定任务为导向,用户使用这类对话系统可以解决特定领域的特定问题,例如:预定机票、预订酒店、网站客服、车载助手等。开放域对话系统则不限制用户提问的特定领域,没有明确目的的对话系统都可以归入此类中,例如:微软的聊天机器人小冰,zo等。相比于任务型对话系统,开放域对话系统的优势在于其能够拉近用户和对话系统间的距离,可以用于情感陪伴等任务型对话系统无法完成的任务。
传统的开放域对话系统主要采用基于检索的方法。这类方法首先定义问题与回复之间的索引,当用户发出询问时,对话系统利用语料库中的索引输出该问题对应的回复。然而,该类方法非常依赖对话语料库的质量,如果所使用对话语料噪声大,则无论模型优劣其回复都不尽人意。并且,这类对话系统回复内容单一,对于用户的问题,只能在语料库中搜索回复,如果语料库中没有对应的回复,系统则无法做出响应。近年来,基于生成模型的开放域对话系统取得了较大进展。这类方法首先利用序列到序列模型对对话语料库数据进行学习,然后基于深度学习模型自动生成回复内容。与基于检索的方法相比,这类方法对于用户提出的问题可以产生新的回复,具有更广泛的应用领域,已经受到了学术界和工业界的共同关注。
但是,基于生成模型的开放域对话系统存在以下两个亟待解决的关键问题:(1)序列到序列模型仅能针对对话数据的局部信息进行学习,难以针对上下文进行处理,因此自动生成的回复易出现上下文无关,前后矛盾等现象。(2)标准的序列到序列模型倾向于生成高频万能回复,例如“好的”、“我不知道”等。这类回复缺乏足够的有用信息,难以给用户提供实质帮助。
技术实现要素:
鉴于上述现有技术的不足之处,本发明的目的在于提供一种自动回复对话方法、系统及存储介质,解决现有技术中自动回复对话体系回复质量不佳的技术问题。
为了达到上述目的,本发明采取了以下技术方案:
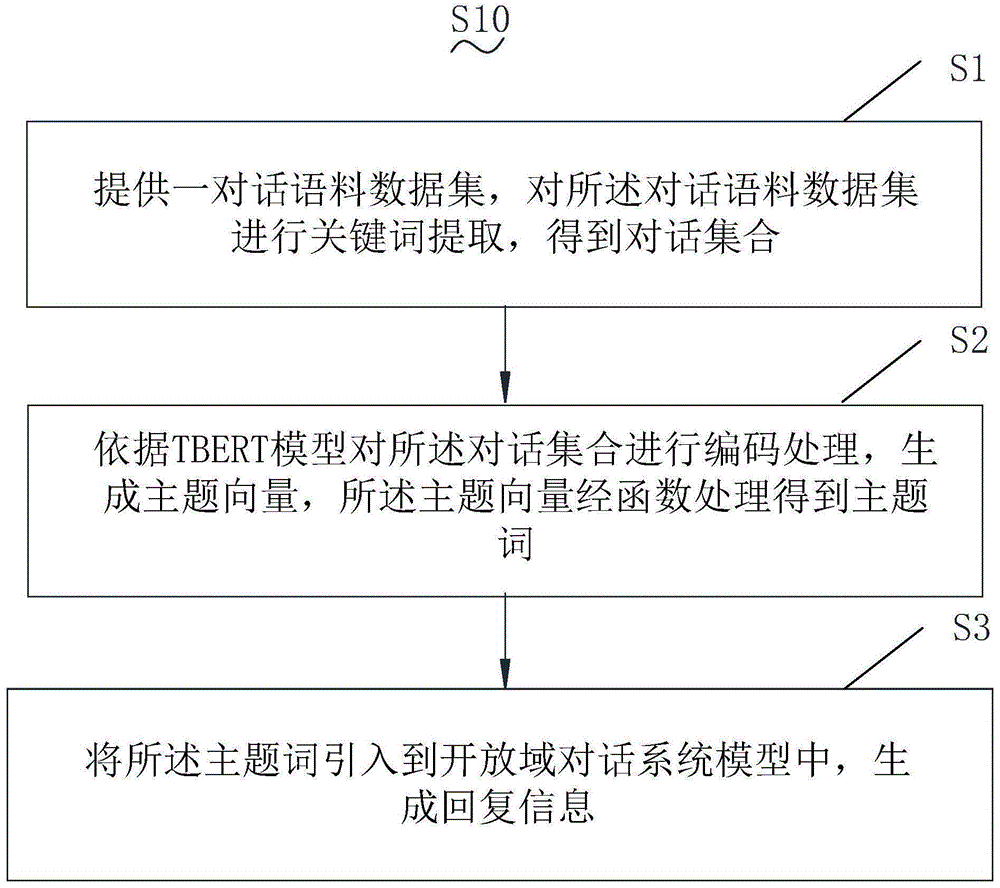
一种自动回复对话方法,包括如下步骤:s1,提供一对话语料数据集,对所述对话语料数据集进行关键词提取,得到对话集合;s2,依据tbert模型对所述对话集合进行编码处理,生成主题向量,所述主题向量经函数处理得到主题词;s3,将所述主题词引入到开放域对话系统模型中,生成回复信息。
优选的,所述s1中所述关键词提取为剔除介词、冠词及修饰词。
优选的,所述s2具体包括以下步骤:s21,依据tbert模型对所述对话集合进行向量化处理,得到字符向量;s22,依据tbert模型的自注意力机制及多头注意力机制对所述字符向量进行编码处理,得到所述字符向量的隐藏状态;s23,将所述字符向量的隐藏状态的第一个字符作为问句向量,所述问句向量通过主题输入矩阵和主题输出矩阵处理得到主题向量;s24,将所述主题向量通过函数处理来预测对话集合中的每个词,得到对话集合对应的主题词。
优选的,所述s3中的所述开放域对话系统模型包括编码器及解码器,所述编码器与所述解码器由两个带门控循环单元的循环神经网络组成。
优选的,所述s3具体包括以下步骤:s31,将所述主题词引入到开放域对话系统模型中,所述编码器通过双向gru将所述对话集合编码呈隐藏状态;s32,所述门控单元将所述主题向量引入所述隐藏状态的对话集合中生成语料词汇表;s33,所述语料词汇表与所述主题词组成的主题词表在联合生成单元中提供回复词,所述回复词经解码器解码生成回复。
优选的,所述s22中将字符向量编码为隐藏状态的公式为:
multihead(q,k,v)=concat(head1,head2,…,headh)wo
headi=attention(qwiq,kwik,vwiv)(2)
其中,q、k和v分别表示为查询、键和值,softmax表示逻辑回归函数,concat表示连接操作,
优选的,所述s23中所述问句向量转化为所述主题向量的公式为:
va=softmax(ivq)(3)
vt=otva(4)
其中,
优选的,所述s32中所述门控单元将所述主题向量引入到隐藏状态的所述对话集合中的公式为:
gi=σ(wgtvt+wghhi-1+wgxxi+bg)
vti=gi⊙vt
hi=rnn(vti,hi-1,xi)(5)
其中,wgt、wgh、wgx和bg为模型的参数,σ表示sigmoid非线性激活函数,⊙表示点积操作,vti表示隐藏状态的主题向量,gi表示门控单元,hi表示隐藏状态,hi-1表示前一隐藏状态。
一种自动回复对话系统,包括处理器和存储器;
所述存储器上存储有可被所述处理器执行的计算机可读程序;
所述处理器执行所述计算机可读程序时实现如上所述的自动回复对话方法中的步骤。
一种计算机可读存储介质,所述计算机可读存储介质存储有一个或者多个程序,所述一个多个程序可被一个或者多个处理器执行,以实现如上所述的自动回复对话方法中的步骤。
相较于现有技术,本发明提出了一种基于tbert的自动回复对话方法,该方法首先利用bert学习主题信息;然后将主题信息引入到开放域对话系统模型中,降低万能回复以及前后矛盾回复出现的可能性,进而提高开放域对话系统的性能。
附图说明
图1为本发明提供的自动回复对话方法的一较佳实施例的流程图;
图2为图1中s2的步骤流程示意图;
图3为图1中s3的步骤流程示意图;
图4为本发明设计的tbert模型的结构示意图;
图5为本发明与基准模型的实验比较示意图。
具体实施方式
本发明提供一种自动回复对话方法、系统及存储介质,为使本发明的目的、技术方案及效果更加清楚、明确,以下参照附图并举实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
实施例1
请参阅图1,图1为本发明提供的自动回复对话方法的一较佳实施例的流程图。本发明提供的自动回复对话方法的流程图,s10包括如下步骤:
s1,提供一对话语料数据集,对所述对话语料数据集进行关键词提取,得到对话集合;
s2,依据tbert模型对所述对话集合进行编码处理,生成主题向量,所述主题向量经函数处理得到主题词;
s3,将所述主题词引入到开放域对话系统模型中,生成回复信息。
相较于现有技术,本发明提出了一种基于tbert的自动回复对话方法,该方法首先利用bert学习主题信息;然后将主题信息引入到开放域对话系统模型中,降低万能回复以及前后矛盾回复出现的可能性,进而提高开放域对话系统的性能。
具体的,s1中所述关键词提取为剔除介词、冠词及修饰词。
通过对用户输入的话语料数据集进行关键词提取,得到对话集合,相较于用户初始的输入信息,关键词提取后的信息可以,避免介词、冠词及修饰词等的干扰。
进一步地,如图2所示,所述s2包括以下步骤:
s21,依据tbert模型对所述对话集合进行向量化处理,得到字符向量;
s22,依据tbert模型的自注意力机制及多头注意力机制对所述字符向量进行编码处理,得到所述字符向量的隐藏状态;
s23,将所述字符向量的隐藏状态的第一个字符作为问句向量,所述问句向量通过主题输入矩阵和主题输出矩阵处理得到主题向量;
s24,将所述主题向量通过函数处理来预测对话集合中的每个词,得到对话集合对应的主题词。
对于给定的对话集合q={x1,x2…,xn},其中n表示问句长度,该步骤旨在利用bert模型对输入的对话集合进行编码,并得到该问句的主题向量。具体来说,通过向量化过程之后,e=(e1,e2,…,en)代替字符集合q作为主题生成模块的输入。bert模型利用自注意力和多头注意力机制将字符向量e编码为隐藏状态h=(t1,t2,…,tn)。
自注意力机制将每个字符转换成查询(query)、键(key)和值(value)并通过公式(1)计算矩阵的输出;
多头注意力在一个问句中学习不同的连接以增加多样性,并通过公式(2)连接并决定最终隐藏状态:
multihead(q,k,v)=concat(head1,head2,…,headh)wo
headi=attention(qwiq,kwik,vwiv)(2)
其中,q、k和v分别表示为查询、键和值,softmax表示逻辑回归函数,concat表示连接操作,
两个查询矩阵中存储着主题相关信息,分别是:主题输入矩阵
va=softmax(ivq)(3)
其中,
vt=otva(4)
在公式(4)中,
在上述的一种基于tbert的自动回复对话方法,将问句的主题信息引入到开放域对话系统模型中,从而自动生成信息丰富的回复。
所述s3中的所述开放域对话系统模型包括编码器及解码器,所述编码器与所述解码器由两个带门控循环单元(gatedrecurrentunit,gru)的循环神经网络(recurrentneuralnetwork,rnn)组成。在编码器中,输入问句q和前一个隐藏状态
进一步的,如图3所示,所述s3具体包括以下步骤:
s31,将所述主题词引入到开放域对话系统模型中,所述编码器通过双向gru将所述对话集合编码呈隐藏状态;
s32,所述门控单元将所述主题向量引入所述隐藏状态的对话集合中生成语料词汇表;
s33,所述语料词汇表与所述主题词组成的主题词表在联合生成单元中提供回复词,所述回复词经解码器解码生成回复。
所述s32中所述门控单元gi将所述主题向量vt引入到隐藏状态hi的所述对话集合中的公式为:
gi=σ(wgtvt+wghhi-1+wgxxi+bg)
vit=gi⊙vt
hi=rnn(vti,hi-1,xi)(5)
其中,wgt、wgh、wgx和bg为模型的参数,σ表示sigmoid非线性激活函数,⊙表示点积操作,vti表示隐藏状态的主题向量,gi表示门控单元,hi表示隐藏状态,hi-1表示前一隐藏状态。
上下文向量vc可由公式(6)计算得出:
其中,
联合生成单元的作用是提高主题词在回复中出现的概率。问句的主题词包含对话的上下文信息,在回复中提高主题词出现的概率有助于降低无实际意义的安全回复以及上下文矛盾回复出现的概率。具体来说,自动生成的回复r中的每个词除了从语料词汇表f={f1,f2,...,fm}中生成之外,还可以通过主题词表q={q1,q2,...,qz}生成。主题词表q由主题词组成。在tbert模型中,回复中的每个词由这两种模式(f中的词汇表生成模式和q的主题词生成模式)联合生成。
在时刻t,回复词yt的联合生成概率如公式(7)所示:
其中,pφ代表词汇表生成模式的生成概率,pθ代表主题词生成模式的生成概率,具体定义如公式(8)所示:
其中,ff(yt)代表词汇表生成模式的生成函数,fq(yt)代表主题词生成模式的生成函数,a表示归一化项。
词汇表生成模式中回复词yt为词ft的概率如公式(9)所示:
其中,ft表示词汇表中回复词的词向量,wf为模型参数。
主题词生成模式中回复词yt为词qt的概率如公式(10)所示:
其中,qt表示主题词中回复词的词向量,wq为模型参数。对于只存在f中而不在q中的词,联合生成单元中的主题词生成模式不起作用,仅使用词汇表生成模式。而对于q中的主题词,主题词生成模式被激活,从而提高主题词在回复中出现的概率。
实施例2
本发明还提供了自动回复对话系统,包括处理器以及存储器,所述存储器上存储有计算机程序,所述计算机程序被所述处理器执行时,实现实施例1提供的自动回复对话方法。
本实施例提供的自动回复对话系统,用于实现自动回复对话方法,因此,上述自动回复对话方法所具备的技术效果,自动回复对话系统同样具备,在此不再赘述。
实施例3
本发明的实施例3提供了计算机存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现实施例1自动回复对话方法。
本实施例提供的计算机存储介质,用于实现自动回复对话方法,因此,上述自动回复对话方法所具备的技术效果,计算机存储介质同样具备,在此不再赘述。
综上所述,如图4所示,本发明提出了一种基于tbert的自动回复对话方法、设备及存储介质,该方法首先利用bert学习主题信息;然后将主题信息引入到开放域对话系统模型中,降低万能回复以及前后矛盾回复出现的可能性,进而提高开放域对话系统的性能。本发明所提出的方法和基准模型通过实验比较可以验证本发明方法的先进性。基准模型包括带有注意力机制的双向lstm模型bilstm和使用最大互信息函数作为目标函数的双向rnn模型mmir。本发明使用开放域对话系统常用的评价指标包括困惑度、distinct-1和distinct-2对实验结果进行分析。本发明实验使用公开的康奈尔电影对话数据集作为实验所用的数据集。本发明随机选择其中70%数据作为训练数据,剩余30%作为测试数据。在主题生成模块中,本发明使用预训练bertbase模型,使用gelu作为激活函数,使用adam优化器,学习率设置为5e-5,dropout概率设置为0.2,主题数目为150。在对话生成模块中,本发明使用预训练300维的fasttext词向量作为输入,rnn的层数设置为2,隐藏状态的维度位置为80。
实验结果如图5所示,本发明所提出的方法在3个评价指标上均有优于2种基准模型,从而验证了本发明的先进性。
当然,本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关硬件(如处理器,控制器等)来完成,所述的程序可存储于一计算机可读取的存储介质中,该程序在执行时可包括如上述各方法实施例的流程。其中所述的存储介质可为存储器、磁碟、光盘等。
可以理解的是,对本领域普通技术人员来说,可以根据本发明的技术方案及其发明构思加以等同替换或改变,而所有这些改变或替换都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!