基于神经网络识别互联网网站所属业态的方法、装置以及计算机可读存储介质与流程
本发明涉及深度学习技术领域,尤其涉及一种基于神经网络识别互联网网站所属业态的方法、装置以及计算机可读存储介质。
背景技术:
依托互联网的发展,近些年互联网平台和运营的网站数量暴增,给国家相关管理机构的有效监督管理带来了极大困难和挑战。发现新增互联网网站,成为监管的核心前提工作。对于传统的发现互联网平台网站的方法,一是通过企业主动上报,二是通过搜索引擎进行人工搜索这两种手段实现,其具有以下不足:一是,企业主动上报备案是基于企业相对规模较大且运营正规,但对于一大部分非法集资形式、网络诈骗形式、色情资源形式、暴力传销形式等违法犯罪平台,都不会主动上报备案,但这些平台恰恰是管理部门重点关注的对象。二是,通过搜索引擎搜索发现平台网站的手段,需要投入大量的人力,效率低下,且发现平台数量及其有限。如此一来,识别互联网网站的细分业态对于互联网监管而言尤为重要。
现有技术中通常是基于机器学习的方法利用词袋模型对互联网网站的文本信息进行表示,从而识别互联网网站的所属业态,又或者是通过简单的卷积神经网络或循环神经网络识别互联网网站的所属业态。但这几种方式的前提默认了网站源码首页head部分信息与body部分信息的权重相同,但一般来说网站源码head部分信息为精炼、上下文语义通顺的描述,body信息为碎片化、上下文语义不通顺的文本描述且body部分信息很容易导致信息冗余、信息的噪声,因此,head信息与body信息两者间的重要程度也需要有一个衡量标准,默认两者信息同等重要,在不分别对两部分信息进行处理且直接接入模型进行预测势必会导致识别准确率较低。
技术实现要素:
本发明的主要目的在于提供一种基于神经网络识别互联网网站所属业态的方法及、装置以及计算机可读存储介质,旨在解决现有技术中对识别互联网网站所属业态进行识别的准确率较低的技术问题。
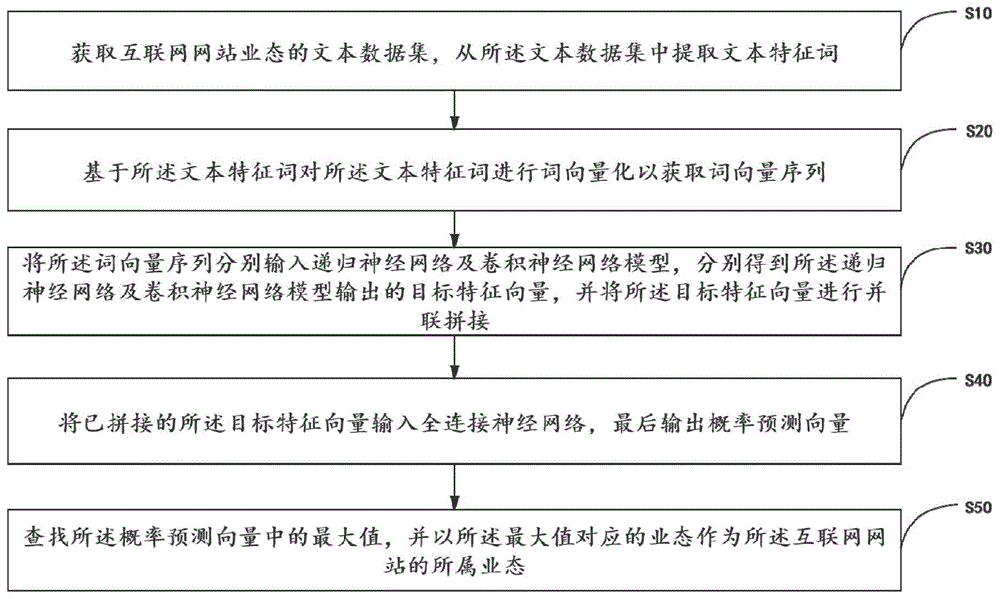
为实现上述目的,本发明实施例提供一种基于神经网络识别互联网网站所属业态的方法,所述基于神经网络识别互联网网站所属业态的方法包括:
获取互联网网站业态的文本数据集,从所述文本数据集中提取文本特征词;
基于所述文本特征词对所述文本特征词进行词向量化以获取词向量序列;
将所述词向量序列分别输入递归神经网络及卷积神经网络模型,分别得到所述递归神经网络及卷积神经网络模型输出的目标特征向量,并将所述目标特征向量进行并联拼接;
将已拼接的所述目标特征向量输入全连接神经网络,最后输出概率预测向量;
查找所述概率预测向量中的最大值,并以所述最大值对应的业态作为所述互联网网站的所属业态。
可选的,所述获取互联网网站业态的文本数据集,从所述文本数据集中提取文本特征词包括:
获取互联网网站的html源码;
对所述互联网网站的html源码进行解析,得到互联网网站的首页源码数据作为互联网网站的文本数据集;
对所述文本数据集进行预处理,所述预处理包括剔除网站的源码body部分所述文本数据集中的无用字符、停用词,通过中文分词及关键词提取技术提取第一文本特征词和/或剔除网站的源码head部分所述文本数据集中的无用字符、停用词,通过中文分词技术提取第二文本特征词。
可选的,所述基于所述文本特征词对所述文本特征词进行词向量化以获取词向量序列包括:
对所述文本特征词分别进行文本的向量化,生成与所述互联网网站对应的词向量序列
可选地,所述基于所述文本特征词对所述文本特征词进行词向量化以获取词向量序列进一步包括:
对所述第一文本特征词进行文本的向量化,得到第一词向量序列;
对所述第二文本特征词进行文本的向量化,得到第二词向量序列。
可选地,所述将所述词向量序列分别输入递归神经网络及卷积神经网络模型,分别得到所述递归神经网络及卷积神经网络模型输出的目标特征向量,并将所述目标特征向量进行并联拼接包括:
将与所述互联网网站对应的词向量序列分别输入所述卷积神经网络模型及递归神经网络模型;
对所述卷积神经网络及递归神经网络模型输出结果进行并联拼接。
可选的,所述将所述词向量序列分别输入递归神经网络及卷积神经网络模型,分别得到所述递归神经网络及卷积神经网络模型输出的目标特征向量,并将所述目标特征向量进行并联拼接进一步包括:
将所述第一词向量序列输入所述卷积神经网络模型,以供所述卷积神经网络模型对所述第一词向量序列进行运算,得到所述卷积神经网络模型输出的第一特征向量;
将所述第二词向量序列输入所述递归神经网络模型,以供所述递归神经网络模型对所述第二词向量序列进行运算,得到所述递归神经网络模型输出的第二特征向量;
将所述第一特征向量与所述第二特征向量进行拼接,得到第三特征向量。
可选地,所述将已拼接的所述目标特征向量输入全连接神经网络,最后输出概率预测向量包括:
对所述递归神经网络及卷积神经网络模型输出的拼接向量接入全连接神经网络层,最后输出目标特征向量,即概率预测向量。
可选的,所述将已拼接的所述目标特征向量输入全连接神经网络,最后输出概率预测向量进一步包括:
将所述第三特征向量接入随机失活层,得到第四特征向量。
将所述第四特征向量接入全连接神经网络层,全连接神经网络层通过连接卷积神经网络及递归神经网络模型的输出结果,通过构造交叉熵构造损失函数及反向传播算法算法计算,实现了卷积神经网络和递归神经网络两部分内容的自主找权功能,自动对网站的body及head两部分内容赋予不同的权重,从而更好地表示文本的语义信息及语义信息的重要性程度,实现了高精度识别互联网网站的所属业态。最后输出维数为n的目标特征向量,即概率预测向量。
此外,为实现上述目的,本发明实施例还提供一种识别互联网网站所属业态的装置,所述基于神经网络识别互联网网站所属业态的装置包括:
预处理模块,用于获取互联网网站的文本数据集,从所述文本数据集中提取文本特征词;
向量化模块,用于基于所述文本特征词对所述文本特征词进行词向量化以获取词向量序列;
第一输入模块,用于将所述词向量序列分别输入递归神经网络及卷积神经网络模型,分别得到所述递归神经网络及卷积神经网络模型输出的目标特征向量,并将并将所述目标特征向量进行并联拼接;
第二输入模块,用于将已拼接的所述目标特征向量输入全连接神经网络,最后输出概率预测向量;
查找模块,用于查找所述概率预测向量中的最大值,并以所述最大值对应的业态作为所述互联网网站的所属业态。
可选的,所述预处理模块用于:
获取互联网网站的html源码;
对所述互联网网站的html源码进行解析,得到互联网网站的首页源码数据作为互联网网站的文本数据集;
对所述文本数据集进行预处理,所述预处理包括剔除网站的源码body部分所述文本数据集中的无用字符、停用词,通过中文分词及关键词提取技术提取第一文本特征词和/或剔除网站的源码head部分所述文本数据集中的无用字符、停用词,通过中文分词技术提取第二文本特征词。
可选的,所述向量化模块用于:
对所述文本特征词分别进行文本的向量化,生成互联网网站对应的词向量序列。
可选的,所述向量化模块进一步用于:
对所述第一文本特征词进行文本的向量化,得到第一词向量序列;
对所述第二文本特征词进行文本的向量化,得到第二词向量序列。
可选的,所述第一输入模块用于:
将所述互联网网站对应的词向量序列分别输入所述卷积神经网络模型及递归神经网络模型;
对所述卷积神经网络及递归神经网络模型输出结果进行并联拼接。
可选的,所述第一输入模块进一步用于:
将所述第一词向量序列输入所述卷积神经网络模型,以供所述卷积神经网络模型对所述第一词向量序列进行运算,得到所述卷积神经网络模型输出的第一特征向量;
将所述第二词向量序列输入所述递归神经网络模型,以供所述递归神经网络模型对所述第二词向量序列进行运算,得到所述递归神经网络模型输出的第二特征向量;
将所述第一特征向量与所述第二特征向量进行并联拼接,得到第三特征向量。
可选的,所述第二输入模块用于:
对所述递归神经网络及卷积神经网络模型输出的拼接向量接入全连接神经网络层,最后输出目标特征向量,即概率预测向量。
可选的,所述第二输入模块进一步用于:
将所述第三特征向量接入随机失活层,得到第四特征向量。
将所述第四特征向量,接入全连接神经网络层,通过构造交叉熵构造损失函数及反向传播算法算法计算,实现了卷积神经网络和递归神经网络两部分内容的自主找权功能,自动对网站的body及head两部分内容赋予不同的权重,从而更好地表示文本的语义信息及语义信息的重要性程度,实现了高精度识别互联网网站的所属业态。最后输出维数为n的目标特征向量,即概率预测向量。
此外,为实现上述目的,本发明实施例还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现所述的基于神经网络识别互联网网站所属业态的方法。
本发明中,获取互联网网站业态的文本数据集,从所述文本数据集中提取文本特征词;基于所述文本特征对文本特征进行词向量化;将所述词向量序列分别输入递归神经网络及卷积神经网络模型,分别得到所述递归神经网络及卷积神经网络模型输出的目标特征向量,并将向量进行并联拼接;将已拼接的所述目标特征向量输入全连接神经网络,最后输出的概率预测向量;查找所述概率预测向量中的最大值,并以所述最大值对应的业态作为所述互联网网站的所属业态。通过本发明,实现了高精度识别互联网网站的所属业态。通过本发明,预处理阶段和建模阶段将网站快照文本的head部分提取及body部分分别处理。其中,head部分提取了title、keywords、descriptions三部分信息拼接,在保持语义顺序及上下文关系的前提下充分利用了递归神经网络提取具有记忆优势的上下文特征的优势,重点提取文本当中的中心语义,生成文本在特定场景下的特征向量;其中,body部分提取了采用tf-idf提取技术,在自动去噪的前提下充分利用了卷积神经网络提取局部特征的优势,重点提取文本当中的关键词汇,生成文本在特定场景下的特征向量。最后将递归神经网络及卷积神经网络的特征向量进行并联拼接通过全连接神经网络自动对网站两部分内容赋予不同的权重,从而更好地表示文本的语义信息及语义信息的重要性程度,实现了高精度识别互联网网站的所属业态。
附图说明
图1为本发明基于神经网络识别互联网网站所属业态的方法一实施例的流程示意图;
图2为本发明基于神经网络识别互联网网站所属业态的装置一实施例的功能模块示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
参照图1,图1为本发明基于神经网络识别互联网网站所属业态的方法一实施例的流程示意图。互联网网站是指在互联网上根据一定的规则,使用html(标准通用标记语言)等工具制作的用于展示特定内容相关网页的集合。人们可以通过网页浏览器来访问网站,获取自己需要的资讯或者享受网络服务。总的来说,互联网网站html的源码特征主要由head和body两部分信息构成,其中,head信息主要为精炼、上下文语义通顺的描述,至少包含了title、keywords、descriptions三部分描述信息,body信息为碎片化、上下文语义不通顺的文本描述,同时还包含了噪声文本数据。上述源码信息的构成是互联网网站的通性,可以适用于游戏、电竞、博彩、论坛、社交、新闻资讯、电商、日用服饰、化妆品、移民、教育、体育、旅游、美食、婚恋、工业公司、制造业公司、房地产、培训、影视、小说读物、建筑、科技、传销、催收、诈骗、配资、p2p、网贷、交易所、私募、公募、资产管理、外汇、黄金、股票、期货、证券投资、保险、银行、数字货币、信托、众筹、典当、融资租赁、保理、支付、门户导航等一系列的互联网网站的分类业态里。在一实施例中,基于神经网络识别互联网网站所属业态的方法包括以下步骤。
步骤s10,获取互联网网站业态的文本数据集,从所述文本数据集中提取文本特征词。
本本发明的优选实施例中,所述互联网网站优选是金融网站,特别优选是私募业态属性网站。获取包含私募业态的互联网网站的文本数据集,数据集变量依次为head文本信息、body文本信息、label正负样本标签(是私募网站标记为1,非私募网站标记为0),其中,私募网站的文本数据集包括该私募网站的网站html首页源码下的head及body部分的文本信息。
某一互联网私募业态网站的head文本信息主要为:“<head>……<title>xxx股权投资有限公司</title><metaname="keywords"content="私募,股权投资企业">、<metaname="descriptions"content="在私募领域有着丰富的投资经验,是一家专业的私募股权投资公司,具备私募投资基金管理人资格(中国证券投资基金业协会登记),注册资本500万元人民币。公司拥有一支专业投资人员组成的投资团队,核心团队拥有十年以上的投资经验,主要团队均有在国内一线投资机构和金融机构多年工作经验,具备融资、投资、管理、退出各环节的丰富投资经验和成功案例。">……</head>”;可见除去英文符号外,该部分的文本内容十分精炼,且语句通顺,同时也为所有互联网网站head信息的通性。
某一互联网私募业态网站的body文本信息主要为:“<body>……<li><ahref="#">公司概况</a>……<li><ahref="about.php">公司简介</a></li>……<li><ahref="organization.php">xx股权投资有限公司公司架构</a></li>……<li><ahref="coming-soon.php">公司规划</a></li>……<imgsrc="http://www.cashcapitaldl.com/data/images/banner/20170515151014_620.png"title="战略梳理"alt="战略梳理"border="0"><p>战略梳理</p></div><divclass="back_box"><span>战略梳理</span><p>核定企业的资源能力,提供相应的产业分析、商业案例分析,让企业树立产业思维,合理调度资源以顺应产业趋势并准确定位,从而实现收入、利润的良性提升。</p></div>……<imgsrc="http://www.cashcapitaldl.com/data/images/banner/20170515151033_370.png"title="并购重组及资源整合"alt="并购重组及资源整合"border="0"><p>并购重组及资源整合</p></div><divclass="back_box"><span>并购重组及资源整合</span><p>帮助企业筛选并购标的、核定并购价格,协助并购谈判、并购整合,驱动企业实现外延扩张。同时我们也会利用自身的资源与信息优势,为企业提供合适的渠道资源。</p><ahref="#">业务介绍</a>……<li><ahref="servie.php">核心的投资业务</a></li>……<li><ahref="coming-soon.php">股权投资私募基金</a></li>……<inputtype="text"placeholder="搜索资讯"id="findby">……<h5>uvleder再度起航,定能再创辉煌!</h5>……<p>周一、周二、周三、周四、周五</p>……<h1>联系我们</h1>……<h4><iclass="fi-marker"></i>xx市xx区xx路xx号xx大厦c座x-xx</h4>……传真</h6><h4>010-xxxxxxx</h4></li>……<li><h6>邮箱</h6><ahref="mailto:xxxxxxx@126.com"target="_blank"></a><h4>……<ahref="#"class="bds_more"data-cmd="more"></a>……<ahref="#"class="bds_mshare"data-cmd="mshare"title="分享到一键分享"></a><ahref="#"class="bds_tsina"data-cmd="tsina"title="分享到新浪微博"></a><ahref="#"class="bds_tqq"data-cmd="tqq"title="分享到腾讯微博"></a><ahref="#"class="bds_kaixin001"data-cmd="kaixin001"title="分享到开心网"></a><ahref="#"class="bds_tieba"data-cmd="tieba"title="分享到百度贴吧"></a><ahref="#"class="bds_qzone"data-cmd="qzone"title="分享到qq空间"></a><ahref="#"class="bds_weixin"data-cmd="weixin"title="分享到微信"></a><ahref="#"class="bds_sohu"data-cmd="sohu"title="分享到搜狐白社会"></a>……</body>”;可见除去英文符号外,文本内容并不精炼,譬如“帮助企业筛选并购标的、核定并购价格,协助并购谈判、并购整合,驱动企业实现外延扩张。同时我们也会利用自身的资源与信息优势,为企业提供合适的渠道资源。”这类信息不具有私募属性。文本内容不具有上下文语义关系,内容呈现片状、碎片化分布,譬如“核心的投资业务股权投资私募基金”与“搜索资讯uvleder再度起航,定能再创辉煌!”、“帮助企业筛选并购标的、核定并购价格,协助并购谈判、并购整合,驱动企业实现外延扩张。同时我们也会利用自身的资源与信息优势,为企业提供合适的渠道资源。”三者相比,单看内容可理解但是两者并没有上下文关系,此外,文本中还存在类似于“周一、周二、周三、周四、周五”、“分享到腾讯微博”等等这类的噪声信息。同时也为所有互联网网站body信息的通性。
进一步地,一实施例中,步骤s10包括:
获取互联网网站的html源码;对所述互联网网站的html源码进行解析,得到互联网网站的首页源码数据作为互联网网站的文本数据集;对所述body文本数据集进行预处理,即所述预处理一:剔除所述文本数据集中的无用字符、停用词,通过中文分词及tf-idf技术提取第一文本特征词;对所述head文本数据集进行预处理,即所述预处理二:剔除网站的源码head部分所述文本数据集中的无用字符、停用词,通过中文分词技术提取第二文本特征词。
本实施例中,以识别互联网站私募业态为例,互联网网站私募业态的文本数据集包括所述互联网网站首页的html源码下的head及body部分的文本信息。首先,获取body文本的方式为:第一步,获取某一互联网网站私募业态首页的html源码,源码格式形如:“<!doctypehtml><html><head>……<title>xxx股权投资有限公司</title><metaname="keywords"content="私募,股权投资企业">、<metaname="descriptions"content="在私募领域有着丰富的投资经验,是一家专业的私募股权投资公司,具备私募投资基金管理人资格(中国证券投资基金业协会登记),注册资本500万元人民币。公司拥有一支专业投资人员组成的投资团队,核心团队拥有十年以上的投资经验,主要团队均有在国内一线投资机构和金融机构多年工作经验,具备融资、投资、管理、退出各环节的丰富投资经验和成功案例。">……</head><body>……<li><ahref="#">公司概况</a>……<li><ahref="about.php">公司简介</a></li>……<li><ahref="organization.php">xx股权投资有限公司公司架构</a></li>……<li><ahref="coming-soon.php">公司规划</a></li>……<imgsrc="http://www.cashcapitaldl.com/data/images/banner/20170515151014_620.png"title="战略梳理"alt="战略梳理"border="0"><p>战略梳理</p></div><divclass="back_box"><span>战略梳理</span><p>核定企业的资源能力,提供相应的产业分析、商业案例分析,让企业树立产业思维,合理调度资源以顺应产业趋势并准确定位,从而实现收入、利润的良性提升。</p></div>……<imgsrc="http://www.cashcapitaldl.com/data/images/banner/20170515151033_370.png"title="并购重组及资源整合"alt="并购重组及资源整合"border="0"><p>并购重组及资源整合</p></div><divclass="back_box"><span>并购重组及资源整合</span><p>帮助企业筛选并购标的、核定并购价格,协助并购谈判、并购整合,驱动企业实现外延扩张。同时我们也会利用自身的资源与信息优势,为企业提供合适的渠道资源。</p><ahref="#">业务介绍</a>……<li><ahref="servie.php">核心的投资业务</a></li>……<li><ahref="coming-soon.php">股权投资私募基金</a></li>……<inputtype="text"placeholder="搜索资讯"id="findby">……<h5>uvleder再度起航,定能再创辉煌!</h5>……<p>周一、周二、周三、周四、周五</p>……<h1>联系我们</h1>……<h4><iclass="fi-marker"></i>xx市xx区xx路xx号xx大厦c座x-xx</h4>……传真</h6><h4>010-xxxxxxx</h4></li>……<li><h6>邮箱</h6><ahref="mailto:xxxxxxx@126.com"target="_blank"></a><h4>……<ahref="#"class="bds_more"data-cmd="more"></a>……<ahref="#"class="bds_mshare"data-cmd="mshare"title="分享到一键分享"></a><ahref="#"class="bds_tsina"data-cmd="tsina"title="分享到新浪微博"></a><ahref="#"class="bds_tqq"data-cmd="tqq"title="分享到腾讯微博"></a><ahref="#"class="bds_kaixin001"data-cmd="kaixin001"title="分享到开心网"></a><ahref="#"class="bds_tieba"data-cmd="tieba"title="分享到百度贴吧"></a><ahref="#"class="bds_qzone"data-cmd="qzone"title="分享到qq空间"></a><ahref="#"class="bds_weixin"data-cmd="weixin"title="分享到微信"></a><ahref="#"class="bds_sohu"data-cmd="sohu"title="分享到搜狐白社会"></a>……</body>”;第二步,对该html源码进行解析,提取body文本信息,得到由网站首页源码文本构成的body文本数据集(某一互联网网站私募业态body信息形如:“<body>……<li><ahref="#">公司概况</a>……<li><ahref="about.php">公司简介</a></li>……<li><ahref="organization.php">xx股权投资有限公司公司架构</a></li>……<li><ahref="coming-soon.php">公司规划</a></li>……<imgsrc="http://www.cashcapitaldl.com/data/images/banner/20170515151014_620.png"title="战略梳理"alt="战略梳理"border="0"><p>战略梳理</p></div><divclass="back_box"><span>战略梳理</span><p>核定企业的资源能力,提供相应的产业分析、商业案例分析,让企业树立产业思维,合理调度资源以顺应产业趋势并准确定位,从而实现收入、利润的良性提升。</p></div>……<imgsrc="http://www.cashcapitaldl.com/data/images/banner/20170515151033_370.png"title="并购重组及资源整合"alt="并购重组及资源整合"border="0"><p>并购重组及资源整合</p></div><divclass="back_box"><span>并购重组及资源整合</span><p>帮助企业筛选并购标的、核定并购价格,协助并购谈判、并购整合,驱动企业实现外延扩张。同时我们也会利用自身的资源与信息优势,为企业提供合适的渠道资源。</p><ahref="#">业务介绍</a>……<li><ahref="servie.php">核心的投资业务</a></li>……<li><ahref="coming-soon.php">股权投资私募基金</a></li>……<inputtype="text"placeholder="搜索资讯"id="findby">……<h5>uvleder再度起航,定能再创辉煌!</h5>……<p>周一、周二、周三、周四、周五</p>……<h1>联系我们</h1>……<h4><iclass="fi-marker"></i>xx市xx区xx路xx号xx大厦c座x-xx</h4>……传真</h6><h4>010-xxxxxxx</h4></li>……<li><h6>邮箱</h6><ahref="mailto:xxxxxxx@126.com"target="_blank"></a><h4>……<ahref="#"class="bds_more"data-cmd="more"></a>……<ahref="#"class="bds_mshare"data-cmd="mshare"title="分享到一键分享"></a><ahref="#"class="bds_tsina"data-cmd="tsina"title="分享到新浪微博"></a><ahref="#"class="bds_tqq"data-cmd="tqq"title="分享到腾讯微博"></a><ahref="#"class="bds_kaixin001"data-cmd="kaixin001"title="分享到开心网"></a><ahref="#"class="bds_tieba"data-cmd="tieba"title="分享到百度贴吧"></a><ahref="#"class="bds_qzone"data-cmd="qzone"title="分享到qq空间"></a><ahref="#"class="bds_weixin"data-cmd="weixin"title="分享到微信"></a><ahref="#"class="bds_sohu"data-cmd="sohu"title="分享到搜狐白社会"></a>……</body>”)后,首先对文本数据集进行预处理,预处理包括剔除所述文本数据集中的无用字符、停用词。最后再利用分词技术将文本进行分词处理,最后再依据tf-idf(termfrequency–inversedocumentfrequency,是一种用于信息检索与数据挖掘的常用加权技术。tf意思是词频termfrequency,idf意思是逆文本频率指数inversedocumentfrequency)进行关键词提取,得到body对应的第一文本特征词,本例中某一互联网私募业态网站的第一文本特征词形如:[投资,有限公司,私募,资讯,简介,公司,……,规划]的特征词列表。
由于body隐藏了稀疏且碎片化的文本信息,文本本身不具备上下文语义关系。与传统的文本分类相比,每条文本中的特征具有多样性,可能面临特征稀疏的问题,即文本之间很少含有相同的特征。不具备上下文语义关系的特性使得文本不同于一般的文章段落,如所述“核心的投资业务股权投资私募基金”与“搜索资讯uvleder再度起航,定能再创辉煌!”两者的内容单看可理解但是两者并没有上下文关系,再加上非私募特有属性词汇(譬如“周一”、“微信”、“微博”等)的特征较多,造成了噪声特征较多,这些特殊的性质为文本分类任务增添了极大的困难。单纯地从普通文本分类任务中移植的算法有时并不能得到很好的效果,我们必须要将更多的精力放在去除噪音数据上。因此,本实施例中,预处理过程包括对文本的规范性检查,通过分词,去噪声,结合停用词表去除停用词,得到可以直接使用的数据格式。再基于body内容碎片化、不具备上下文语义这一特征,利用tf-idf进行关键特征提取,能有效过滤无效信息。
本实施例中,head文本可直接获取。获取文本的方式为:首先获取所述互联网网站私募业态首页的html源码,然后对该html源码进行解析,分别提取head部分中的title、keywords、descriptions三部分文本信息,即某一互联网私募业态的head部分源码“<head>……<title>xxx股权投资有限公司</title><metaname="keywords"content="私募,股权投资企业">、<metaname="descriptions"content="xx股权投资有限公司在私募领域有着丰富的投资经验,是一家专业的私募股权投资公司,具备私募投资基金管理人资格(中国证券投资基金业协会登记),注册资本500万元人民币。公司拥有一支专业投资人员组成的投资团队,核心团队拥有十年以上的投资经验,主要团队均有在国内一线投资机构和金融机构多年工作经验,具备融资、投资、管理、退出各环节的丰富投资经验和成功案例。">……</head>”中,令title=“xxx股权投资有限公司”、keywords=“私募,股权投资企业”,descriptions=“在私募领域有着丰富的投资经验,是一家专业的私募股权投资公司,具备私募投资基金管理人资格(中国证券投资基金业协会登记),注册资本500万元人民币。公司拥有一支专业投资人员组成的投资团队,核心团队拥有十年以上的投资经验,主要团队均有在国内一线投资机构和金融机构多年工作经验,具备融资、投资、管理、退出各环节的丰富投资经验和成功案例”。再将title、keywords、descriptions三部分文本信息进行拼接,即得到“xx股权投资有限公司私募,股权投资企业在私募领域有着丰富的投资经验,是一家专业的私募股权投资公司,具备私募投资基金管理人资格(中国证券投资基金业协会登记),注册资本500万元人民币。公司拥有一支专业投资人员组成的投资团队,核心团队拥有十年以上的投资经验,主要团队均有在国内一线投资机构和金融机构多年工作经验,具备融资、投资、管理、退出各环节的丰富投资经验和成功案例。”。得到由title、keywords、descriptions文本构成的head文本数据集后,对文本数据集进行预处理,预处理包括剔除所述文本数据集中的无用字符、停用词。最后再利用分词技术将文本进行分词处理,得到第二文本特征词,本例中某一互联网私募业态网站的第二文本特征词形如:[xx,股权投资,有限公司,私募,股权投资,企业,在,私募,领域,有,丰富,投资经验,是,专业,私募,股权投资,公司,……,投资经验,和,成功案例]的特征词列表。
由于head文本为短文本,文本的特征信息相对集中,因此,本实施例中,预处理过程包括对简介文本的规范性检查,在此过程中解决缺失项和重复项的问题。通过分词,去噪声,结合停用词表去除停用词,得到可以直接使用的数据格式。
本实施例中,对每个剔除了无效信息的文本数据进行分词处理可以通过维特比算法、基于信息熵的无字典分词算法完成,或借助现有的中文分词工具完成,中文分词工具例如jieba分词工具,snownlp分词工具,pkuseg分词工具,thulac分词工具,hanlp分词工具等。
两类文本提取方式解决了网站首页源码文档中head部分信息精炼且具有上下文语义关系、body部分信息碎片化有噪声且无显著上下文语义关系等问题。
步骤s20,基于所述文本特征词对所述文本特征词进行词向量化以获取词向量序列。
本实施例中,分别对所述body文本的提取信息及head文本的提取信息进行文本的向量化,得到文本的向量序列。
进一步地,一实施例中,步骤s20包括:
对所述第一文本特征词进行文本的向量化,得到第一词向量序列;
对所述第二文本特征词进行文本的向量化,得到第二词向量序列。
本实施例中,针对于互联网网站私募业态的首页源码,利用分词工具进行切词、剔除停用词、tf-idf关键词提取形成body文本对应的第一文本特征词。采用word2vec工具中的skip-gram算法,对每个网站对应的词组信息进行词汇模型训练,生成每个网站对应的第一词向量序列,对某一互联网私募业态网站的第一文本特征词——[投资,有限公司,私募,资讯,简介,公司,……,规划],按照“,”号得到第一词向量序列(每个向量长度均为m),具体格式如下:
“投资,[0.03,0.10,……,0.95]有限公司,[0.00,0.52,……,0.00]私募,[0.03,0.02,……,0.89]资讯,[0.53,0.49,……,0.00]……”
本实施例中,利用分词工具进行切词、剔除停用词形成head文本对应的第二文本特征词。采用word2vec工具中的skip-gram算法,对每个网站对应的词组信息进行词汇模型训练,生成每个网站对应的第二词向量序列,对某一互联网私募业态网站的第二文本特征词——[xx,股权投资,有限公司,私募,股权投资,企业,在,私募,领域,有,丰富,投资经验,是,专业,私募,股权投资,公司,……,投资经验,和,成功案例],按照“,”号得到第二词向量序列(每个向量长度均为m),具体格式如下:
“xx,[0.00,0.00,……,0.00]股权投资,[0.03,0.05,……,0.72]有限公司,[0.00,0.52,……,0.00]……”
本实施例中,在得到每个网站对应的词组信息后,进一步通过word2vec工具中的skip-gram算法,对每个网站对应的词组信息进行词汇模型训练,生成每个网站对应的词向量。即假设互联网网站文本分词后的词汇为x,x为有序序列,x=[股权投资,有限公司,在,私募领域,有着,丰富,的,投资经验,是,一家,专业,的,……,成功案例……],有z个词汇,即设第一个位置的词汇x1“股权投资”的词向量为[1,0,0,……0],其中词向量的长度为z,第二个位置词汇x2“有限公司”的词向量为[0,1,0,……0],以此类推,共计z个词向量,每个词向量独立于其余词向量。再通过skip-gram算法,设定输出每一词向量的长度为m,找到一个shape=(z,m)的矩阵m,使得每次输入一个词向量xi后,找到xi对应的(xi-k,……,xi-2,xi-1,xi+1,xi+2,……,xi+k)出现的概率最大,譬如输入“有着”一词,则前后出现[股权投资,有限公司,私募领域,丰富,的,投资经验]的概率应该最大,并根据所有输入的xi构建联合概率,使得联合概率最大,使得矩阵m为网站所求的对应词向量矩阵,矩阵m具备网站词向量的特征。应用矩阵m,假设想找到“股权投资”对应的词向量,“股权投资”对应的one-hot向量为[1,0,0,……0],可用[1,0,0,……0]与m的向量乘机进行表示,最后得到“股权投资”对应的词向量,其他词向量以此类推。其中,word2vec工具是一款用于词向量计算的工具。最终将词语由一个高维稀疏的向量转为一个低维稠密的向量,使得相似特征的词语在空间中的距离更近。
步骤s30,将所述词向量序列分别输入递归神经网络及卷积神经网络模型,分别得到所述递归神经网络及卷积神经网络模型输出的目标特征向量,并将所述目标特征向量进行并联拼接。
本实施例中,由于body部分文本信息语义并不连贯,不具备上下文语义关系,具有局部碎片化的特征,而这类文本的性质与卷积神经网络模型识别数据局部特征的特点十分匹配,因此将所述body部分的词向量序列输入所述卷积神经网络模型;由于head部分文本信息为一个网站的内容精准的属性表述,因此head部分文本分词后的语义连贯,具有上下文含义,而这类文本的性质与递归神经网络模型识别带有上下文关系的语义特征的特点十分匹配。因此将所述head部分的词向量序列输入所述递归神经网络模型。最后卷积神经网络模型和递归神经网络模型的输出层进行并联拼接。
进一步地,一实施例中,步骤s30包括:
将所述body部分第一词向量序列输入所述卷积神经网络模型,以供所述卷积神经网络模型对所述第一词向量序列进行运算,得到所述卷积神经网络模型输出的第一特征向量;将所述head部分第二词向量序列输入所述递归神经网络模型,以供所述递归神经网络模型对所述第二词向量序列进行运算,得到所述递归神经网络模型输出的第二特征向量;将所述第一特征向量与所述第二特征向量进行拼接,得到第三特征向量。
本实施例中,将第一词向量序列作为卷积神经网络模型的输入。在某一互联网私募业态网站的条件下,其中,卷积神经网络模型可以选用textcnn模型。textcnn模型进行卷积、激活、池化方法对输入的第一词向量序列进行运算,其中激活函数选用relu激活函数(计算公式为relu(x)=max(0,x)),池化的方法选择了最大池化。在某一互联网私募业态网站的条件下,设某卷积核为ω,ω∈zhm,其中h为滑窗的词数,m为词向量的长度,z为一个shape=(h,m)的矩阵;xi为一个句子中的第i个词向量,shape=(1,m)(接上例,设“投资”一词的x1=[0.03,0.10,……,0.95],长度为m);xi:j为在长度为n的文本中,第[i,j]个词语的词向量的拼接(接上例,x1:2=[[0.03,0.10,……,0.95],[0.00,0.52,……,0.00]]);b为偏置项;ci为每一次滑窗结果,ci=relu(ω·xi:i+h-1+b),使得构造不同权重的卷积核,提取出不同的局部信息(接上例,c1提取到了body文本中公司相关的内容信息,c2提取到了body文本中私募相关的内容信息,c3提取到了body文本中资讯相关的内容信息,……,cn-h+1提取到了body文本中地址相关的内容信息。根据relu激活函数的性质,找到的是卷积核中某类内容信息最大的数值);因此,c=[c1,c2,...,cn-h+1],由于本例想识别的是私募业态,因此,最大池化的公式为
本实施例中,将第二词向量序列作为递归神经网络模型的输入,递归神经网络可选用lstm模型,利用lstm模型对输入的第二词向量序列进行运算,激活函数选择relu激活函数(计算公式为relu(x)=max(0,x)),在某一互联网私募业态网站的条件下,设ft表示需要我们忘记的信息概率值,xt为输入的第二词向量(接上例,假设x2=[0.03,0.05,……,0.72],表示“股权投资”),ht-1为前一个文本的输出的向量(接上例,假设h1=[0.01,0.02,……,0.44],表示包含了“xx”信息的向量,xx表示公司的具体名称),w及b为模型参数,σ为sigmoid激活函数,设it为信息要记住的概率值,
ft=σ(wf·[ht-1,xt]+bf)
it=σ(wi·[ht-1,xt]+bt)
οt=σ(wo·[ht-1,xt]+bo)
ht=οt·relu(ct)
根据公式,输入relu函数其实是分段线性函数,把所有的负值都变为0,而正值不变,这种操作被成为单侧抑制。即relu函数在递归神经网络中神经元的值大于零的时候,relu的梯度恒定为1,梯度在大于零的时候可以一直被传递,防止所述互联网网站私募业态head部分精炼信息随着递归神经网络层数的加深导致使用传统的tanh激活函数使得信息解析的遗漏损失的情况发生,因为我们希望识别的是私募业态,其对应的主体为公司企业而非是类似于私募排行榜性质的资讯网站,因此若递归神经网络中使用tanh导致公司企业的具备上下文语义关系的信息丢失,则会将私募排行榜这类的资讯网站识别出来,导致模型预测的准确率下降。而且relu得到的收敛速度会比tanh快很多。得到的输出经过非线性激活层的运算后,得到具有记忆优势的上下文特征向量,即得到lstm模型输出的第二特征向量。
本实施例中,将得到textcnn模型输出的第一特征向量以及lstm模型输出的第二特征向量后,首先对这两个特征向量进行并联拼接,得到一个新的特征向量(即第三特征向量)。使得第三特征向量前段包含body特征信息、后端包含head特征信息的组合。某一互联网私募业态网站中,设卷积神经网络的输出向量为v-textcnn=[k1,k2,……,kp];递归神经网络的输出向量为v-lstm=[h1,h2,……,hm],[k1,k2,……,kp,h1,h2,……,hm]为并联后的向量表示,得到的并联拼接向量包含了私募特征的信息。
步骤s40,将已拼接的所述目标特征向量输入全连接神经网络,最后输出概率预测向量。
例如,在本发明的优选实施例中,将所述包含body特征信息、head特征信息的向量接入随机失活层,根据随机失活层数据结果将其接入全连接神经网络层,最后输出目标特征向量,即概率预测向量。
进一步地,一实施例中,步骤s40包括:
将所述第三特征向量接入随机失活层,得到第四特征向量;将所述第四特征向量接入全连接神经网络层,全连接神经网络层通过连接卷积神经网络及递归神经网络模型的输出结果,通过构造交叉熵构造损失函数及反向传播算法算法计算,实现了卷积神经网络和递归神经网络两部分内容的自主找权功能,自动对网站的body及head两部分内容信息赋予不同的权重,从而更好地表示文本的语义信息及语义信息的重要性程度,实现了高精度识别互联网网站的所属业态。最后输出维数为n的目标特征向量,即概率预测向量。
全连接神经网络容易使得模型产生过拟合现象,过拟合容易导致模型训练集上准确率较高,但在生产环境表现为过低的准确率。过拟合产生的原因主要有模型过于复杂、模型特征过多等原因。本实施例中,为了防止过拟合现象的发生,采用了随机失活技术,随机丢去一定概率的模型特征项,以此来降低由模型复杂度或特征变量过多导致的过拟合现象的发生的概率。
本实施例中,将某一互联网私募业态网站所述包含body特征信息、head特征信息的向量并联接入随机失活层,若某一互联网私募业态网站并联后的向量表示为[k1,k2,……,kp,h1,h2,……,hm],向量长度为(p+m),假设随机丢弃的概率设为0.5,则随机构造一个长度为(p+m)的0-1向量,向量中1出现的概率为0.5,0出现的概率为0.5,将0-1向量与[k1,k2,……,kp,h1,h2,……,hm]向量的乘积项目为随机失活层的输出层,该输出向量0出现的概率为0.5,非0向出现的概率也为0.5,达到了特征按照一定概率丢失防止过拟合的目的。根据随机失活层数据结果将其接入全连接神经网络层,令随机失活层的输出向量为[0,k2,……,kp,h1,0,……,hm],设全连接神经网络的权重为w,w为一个shape=(p+m,z)的矩阵,其中z表示隐藏层的个数,利用[0,k2,……,kp,h1,0,……,hm]与w相乘的机制,再通过反向传播技术计算得到最优w,使得损失函数最小,这里的w计算最优解实现了由全连接神经网络自动赋予head及body网站首页快照源码信息不同权重的功能,使得无需人为事先设定head及body两者之间的权重,却解决了业务上head及body关于私募属性信息重要程度不同的问题。
本实施例中,将某一互联网私募业态网站全连接神经网络输出的目标特征向量中的每个实数映射为0到1之间的实数,并且输出向量中所有实数之和为1,这些实数表示相应种类的概率大小,得到的输出为概率预测向量。
步骤s50,查找所述概率预测向量中的最大值,并以所述最大值对应的业态作为所述互联网网站的所属业态。
本实施例中,再经过全连接层对第四特征向量进行线性降维,最终得到维数为n的目标特征向量。其中,维数为n代表对应n个预测结果,即互联网网站所属的n个业态。得到的概率预测向量中的每个概率值表示该互联网网站属于某种业态的概率大小,因此,查找概率预测向量中的最大值,以该最大值对应的业态作为互联网网站的所属业态。因此,某一网站输出结果中私募业态概率值最大,则将该互联网网站标记为私募大类。在互联网网站私募业态分类中,将10864条互联网私募网站样本数据标记为正样本,记作1;将9347条非互联网私募网站(包含了新闻、留学移民、教育、科技公司、软件开发、服装、化妆品、珠宝、影视、论坛、黄赌毒、交易所、股票、银行、期货、黄金、外汇、保险、公募基金等非私募属性业态)标记为负样本,记作0。正负样本合并后输入所述模型,结果如下:样本为0,实际模型预测结果为0的共计9268条;样本为0,实际模型预测结果为1的共计79条;样本为1,实际模型预测结果为0的共计344条;样本为1,实际模型预测结果为1的共计10520条。因此,计算识别互联网网站私募业态的准确率为:(9268+10520)/20211=97.91%;计算的召回率为:10520/(10520+344)=96.83%。
相较之传统的卷积神经网络识别互联网私募业态(在同样的测试条件下,样本为0,实际模型预测结果为0的共计8758条;样本为0,实际模型预测结果为1的共计589条;样本为1,实际模型预测结果为0的共计825条;样本为1,实际模型预测结果为1的共计10039条。因此,计算识别互联网网站私募业态的准确率为:(8758+10039)/20211=93.00%;计算的召回率为:10039/(10039+825)=92.41%),准确率提高了4.91%,召回率提高了4.42%。
本实施例中,获取互联网网站业态的文本数据集,从所述文本数据集中提取文本特征词;基于所述文本特征词对文本特征词进行词向量化;将所述词向量序列分别输入递归神经网络及卷积神经网络模型,分别得到所述递归神经网络及卷积神经网络模型输出的目标特征向量,并将向量进行并联拼接;将已拼接的所述目标特征向量输入全连接神经网络,最后输出概率预测向量;查找所述概率预测向量中的最大值,并以所述最大值对应的业态作为所述互联网网站的所属业态。通过本发明,实现了高精度识别互联网网站的所属业态。通过本发明,预处理阶段和建模阶段将网站快照文本的head部分提取及body部分分别处理。其中,head部分提取了title、keywords、descriptions三部分信息拼接,在保持语义顺序及上下文关系的前提下充分利用了递归神经网络提取具有记忆优势的上下文特征的优势,重点提取文本当中的中心语义,生成文本在特定场景下的特征向量;其中,body部分提取了采用tf-idf提取技术,在自动去噪的前提下充分利用了卷积神经网络提取局部特征的优势,重点提取文本当中的关键词汇,生成文本在特定场景下的特征向量。最后将递归神经网络及卷积神经网络的特征向量进行拼接通过全连接神经网络自动对网站两部分内容赋予不同的权重,从而更好地表示文本的语义信息及语义信息的重要性程度,实现了高精度识别互联网网站的所属业态。
参照图2,图2为本发明的基于神经网络识别互联网网站所属业态的一实施例的功能模块示意图。一实施例中,所述基于神经网络识别互联网网站所属业态包括:
预处理模块10,用于获取互联网网站的文本数据集,从所述文本数据集中提取文本特征词;
向量化模块20,用于基于所述文本特征词对所述文本特征词进行词向量化以获取词向量序列;
第一输入模块30,用于将所述词向量序列分别输入递归神经网络及卷积神经网络模型,分别得到所述递归神经网络及卷积神经网络模型输出的目标特征向量,并将所述目标特征向量进行并联拼接;
第二输入模块40,将已拼接的所述目标特征向量输入全连接神经网络,最后输出概率预测向量;
查找模块50,用于查找所述概率预测向量中的最大值,并以所述最大值对应的业态作为所述互联网网站的所属业态。
进一步地,一实施例中,所述预处理模块10用于:
获取互联网网站的html源码;
对所述互联网网站的html源码进行解析,得到互联网网站的首页源码数据作为互联网网站的文本数据集;
对所述文本数据集进行预处理,所述预处理一:剔除所述文本数据集中的无用字符、停用词,通过中文分词及tf-idf技术提取第一文本特征词;
对所述文本数据集进行预处理,所述预处理二:剔除网站的源码head部分所述文本数据集中的无用字符、停用词,通过中文分词技术提取head部分的title、keywords、descriptions三部分信息进行拼接,作为第二文本特征词。
进一步地,一实施例中,所述向量化模块20用于:
对所述第一文本特征词进行文本的向量化,得到第一词向量序列;
对所述第二文本特征词进行文本的向量化,得到第二词向量序列。
进一步地,一实施例中,所述第一输入模块30用于:
将所述第一词向量序列输入所述卷积神经网络模型,以供所述卷积神经网络模型对所述第一词向量序列进行运算,得到所述卷积神经网络模型输出的第一特征向量;
将所述第二词向量序列输入所述递归神经网络模型,以供所述递归神经网络模型对所述第二词向量序列进行运算,得到所述递归神经网络模型输出的第二特征向量;
将所述第一特征向量与所述第二特征向量进行拼接,得到第三特征向量。
进一步地,一实施例中,所述第二输入模块40用于:
将所述第三特征向量接入随机失活层,得到第四特征向量。
将所述第四特征向量接入全连接神经网络层,全连接神经网络层通过连接卷积神经网络及递归神经网络模型的输出结果,通过构造交叉熵构造损失函数及反向传播算法算法计算,实现了卷积神经网络和递归神经网络两部分内容的自主找权功能,自动对网站的body及head两部分内容赋予不同的权重,从而更好地表示文本的语义信息及语义信息的重要性程度,实现了高精度识别互联网网站的所属业态。最后输出维数为n的目标特征向量,即概率预测向量。
本发明基于神经网络识别互联网网站所属业态的具体实施例与上述识别互联网网站所属业态的方法的各个实施例基本相同,在此不做赘述。
本发明可以通过硬件、软件或者软、硬件结合来实现。本发明可以在至少一个计算机系统中以集中方式实现,或者由分布在几个互连的计算机系统中的不同部分以分散方式实现。任何可以实现本发明方法的计算机系统或其它设备都是可适用的。常用软硬件的结合可以是安装有计算机程序的通用计算机系统,通过安装和执行程序控制计算机系统,使其按本发明方法运行。
本发明还可以通过计算机程序进行实施,所述计算机程序包含能够实现本发明方法的全部特征,当其安装到计算机系统中时,可以实现本发明的方法。本文件中的计算机程序所指的是:可以采用任何程序语言、代码或符号编写的一组指令的任何表达式,该指令组使系统具有信息处理能力,以直接实现特定功能,或在进行下述一个或两个步骤之后实现特定功能:a)转换成其它语言、编码或符号;b)以不同的格式再现。
因此,本发明还可以涉及一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现所述的基于神经网络识别互联网网站所属业态的方法。
本发明中,获取互联网网站业态的文本数据集,从所述文本数据集中提取文本特征词;基于所述文本特征对文本特征进行词向量化;将所述词向量序列分别输入递归神经网络及卷积神经网络模型,分别得到所述递归神经网络及卷积神经网络模型输出的目标特征向量,并将向量进行并联拼接;将已拼接的所述目标特征向量输入全连接神经网络,最后输出的概率预测向量;查找所述概率预测向量中的最大值,并以所述最大值对应的业态作为所述互联网网站的所属业态。通过本发明,实现了高精度识别互联网网站的所属业态。通过本发明,预处理阶段和建模阶段将网站快照文本的head部分提取及body部分分别处理。其中,head部分提取了title、keywords、descriptions三部分信息拼接,在保持语义顺序及上下文关系的前提下充分利用了递归神经网络提取具有记忆优势的上下文特征的优势,重点提取文本当中的中心语义,生成文本在特定场景下的特征向量;其中,body部分提取了采用tf-idf提取技术,在自动去噪的前提下充分利用了卷积神经网络提取局部特征的优势,重点提取文本当中的关键词汇,生成文本在特定场景下的特征向量。最后将递归神经网络及卷积神经网络的特征向量进行并联拼接通过全连接神经网络自动对网站两部分内容赋予不同的权重,从而更好地表示文本的语义信息及语义信息的重要性程度,实现了高精度识别互联网网站的所属业态。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者系统中还存在另外的相同要素。
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!