一种基于局部边际最大化的动作识别方法与流程
[0001]
本发明涉及计算机视觉的技术领域,更具体地,涉及一种基于局部边际最大化的动作识别方法。
背景技术:
[0002]
近年来,随着视频可获取数量的急剧增加,视频数据的处理和识别在视频检索和视频摘要等领域引起了极大的关注。其中,动作视频的识别在计算机视觉领域中占据重要的地位,如视频监控、基于内容的视频检索、虚拟现实以及人机交互等。
[0003]
动作视频识别可以看作是对视频序列进行分类,在现实应用中,设计一个对复杂动作行为进行识别的强有力方法仍然是一个极具挑战性的问题。多重线性代数是分析动作视频数据的一个非常有效的数学工具。由于动作行为随着时间的变化可以表示为一个视频帧序列,所以可用一个三阶张量来表征每个动作视频,利用三阶张量来表征每个动作视频的方法与传统基于向量表示的算法相比,以张量的形式来表征视频数据不仅可以最大程度地保存视频中所包含的原始数据信息,还可以保留帧与帧之间的相关性。
[0004]
但与此同时,由于原始视频数据集通常存在噪声,这些噪声将会对动作识别带来干扰,当前存在一些降噪的方法例如通过多线性投影方案,将原始高维张量投影到一个有利于识别的低维空间中,可以降低噪声干扰。如2019年10月15日,公布号为cn110334618a的中国专利中公开了一种基于稀疏张量的人体行为识别方法,结合张量表示和稀疏表示,满足张量局部fisher判别分析的目标,而且保证了所得投影矩阵的稀疏性,进一步提高了人体行为的识别率,但此专利中的技术方案聚焦于在低维空间中实现原始动作行为数据几何结构的保持,忽略了对原始动作行为数据中判别信息的保持及保护。
技术实现要素:
[0005]
为解决当前在面对视频动作数据的噪声干扰时,通过投影降维的方法忽略了对原始动作行为数据中判别信息的保持及保护的问题,本发明提出一种基于局部边际最大化的动作识别方法,提高动作行为识别的准确率。
[0006]
为了达到上述技术效果,本发明的技术方案如下:
[0007]
一种基于局部边际最大化的动作识别方法,至少包括:
[0008]
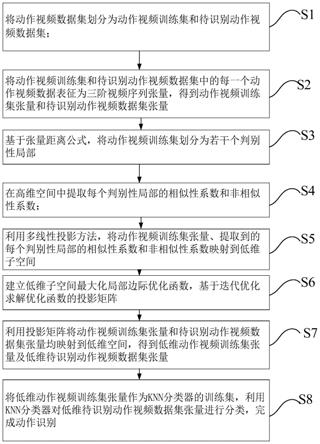
s1.将动作视频数据集划分为动作视频训练集和待识别动作视频数据集;
[0009]
s2.将动作视频训练集和待识别动作视频数据集中的每一个动作视频数据表征为三阶视频序列张量,得到动作视频训练集张量和待识别动作视频数据集张量;
[0010]
s3.基于张量距离公式,将动作视频训练集划分为若干个判别性局部;
[0011]
s4.在高维空间中提取每个判别性局部的相似性系数和非相似性系数;
[0012]
s5.利用多线性投影方法,将动作视频训练集张量、提取到的每个判别性局部的相似性系数和非相似性系数映射到低维空间;
[0013]
s6.建立低维空间最大化局部边际优化函数,基于迭代优化求解优化函数的投影
矩阵;
[0014]
s7.利用投影矩阵将动作视频训练集张量和待识别动作视频数据集张量均映射到低维空间,得到低维动作视频训练集张量及低维待识别动作视频数据集张量;
[0015]
s8.将低维动作视频训练集张量作为knn分类器的训练集,利用knn分类器对低维待识别动作视频数据集张量进行分类,完成动作识别。
[0016]
优选地,动作视频训练集中的每一个动作视频数据表征为三阶视频序列张量时,得到的动作视频训练集张量满足:
[0017][0018]
其中,表示动作视频训练集张量;i表示动作视频训练集中的动作视频编号;n表示动作视频训练集中动作视频的数量;i1表示动作视频训练集中动作视频每一帧的长度;i2表示动作视频训练集中动作视频每一帧的宽度;i3表示动作视频训练集中动作视频总的帧数;
[0019]
待识别动作视频数据集中的每一个动作视频数据表征为三阶视频序列张量时,得到的待识别动作视频数据集张量满足:
[0020][0021]
其中,表示待识别动作视频数据集张量;h表示待识别动作视频数据集中的动作视频编号;m表示待识别动作视频数据集中动作视频的数量。
[0022]
优选地,步骤s3所述若干个判别性局部中第i个判别性局部的形成过程为:
[0023]
s31.根据张量距离公式求解张量距离,将求解的张量距离按从小到大排序,确定与动作视频训练集中每一个动作视频数据的动作视频训练集张量张量距离最近的k个动作视频训练张量,作为动作视频训练集张量的同类近邻点j=1,
…
,k,张量距离公式为:
[0024][0025]
其中,表示动作视频训练集张量与动作视频训练集张量之间的张量距离;i1、i2及i3分别表示动作视频训练集中动作视频的长度下标、宽度下标及总帧数下标;和分别表示动作视频训练集张量和动作视频训练集张量位于(i1,i2,i3)的元素大小;
[0026]
s32.动作视频训练集张量与构成第i个判别性局部表示为:
[0027][0028]
优选地,在高维空间中提取第i个判别性局部的相似性系数的过程为:
[0029]
将第i个判别性局部的相似性系数定义为:
[0030][0031]
其中,w
i,j
表示第i个判别性局部的相似性系数;
[0032]
利用第一选择向量s
i,j
提取第i个判别性局部的相似性系数,将第一选择向量s
i,j
提取的结果作为第i个判别性局部的相似性系数,第一选择向量s
i,j
的表达式为:
[0033][0034]
其中,i,j=1,
…
,n,表示时,在中的序号。
[0035]
优选地,在高维空间中提取第i个判别性局部的非相似性系数的过程为:
[0036]
利用第二选择向量l
i,j
提取第i个判别性局部的非相似性系数,将第二选择向量l
i,j
提取的结果作为第i个判别性局部的非相似性系数,第二选择向量l
i,j
的表达式为:
[0037][0038]
其中,i,j=1,
…
,n。
[0039]
优选地,步骤s5所述将动作视频训练集张量映射到低维空间的过程为:
[0040]
定义一组投影矩阵为基于投影矩阵,将动作视频训练集张量映射到低维空间,映射公式满足:
[0041][0042]
其中,表示在低维空间的低维表示;
×
m
表示m的模式积,i
m
是高维空间中动作视频训练集张量第m维的维度;j
m
是低维空间中动作视频训练集张量第m维的维度。不同的投影矩阵会将原始视频序列张量映射到不同的低维空间,使用多线性投影方案,可以将原始视频序列张量投影到一个可区分度更高的低维空间,对于提取到的每个判别性局部的相似性系数和非相似性系数,以相同的多线性投影方法,映射到低维空间。
[0043]
优选地,步骤s6所述建立的低维空间最大化局部边际优化函数包括第一优化函数及第二优化函数,所述第一优化函数为:
[0044][0045]
所述第二优化函数为:
[0046]
[0047]
其中,局部边际为判别性局部内外距离最近的两点之间的距离。最大化低维空间中的局部边际有利于局部内的数据点的识别,使得原始数据的判别信息得到很好的保持,为了在低维空间中最大化局部边际,每个局部内的近邻点向中心点靠近,而局部外的强干扰点应该远离局部。
[0048]
优选地,步骤s6所述基于迭代优化求解优化函数的投影矩阵的过程为:
[0049]
s61.限制投影矩阵使其满足:
[0050][0051]
s62.将投影矩阵u1,u2,u3初始化为单位矩阵;
[0052]
s63.在每一次优化迭代中,仅优化投影矩阵u1,u2,u3中的一个投影矩阵,固定剩余的两个投影矩阵;
[0053]
s64.判断优化迭代是否达到最大值,若是,迭代结束;否则,返回步骤s63。
[0054]
优选地,设步骤s63所述优化投影矩阵u1,u2,u3中的一个投影矩阵为u1,固定投影矩阵u2,u3,则第一优化函数为:
[0055][0056]
其中,其中,为张量ψ
i
的1模式展开,
[0057][0058]
第二优化函数为:
[0059][0060]
其中,
[0061]
优选地,在优化投影矩阵u1时,低维空间最大化局部边际优化函数转化为:
[0062]
第一优化函数转化为:
[0063][0064]
第二优化函数转化为:
[0065][0066]
即:
[0067][0068]
其中,θ=(f
non-local
)-1
f
local
,投影矩阵u1由θ的j
n
个最小特征值对应的特征向量组成。
[0069]
与现有技术相比,本发明技术方案的有益效果是:
[0070]
本发明提出一种基于局部边际最大化的动作识别方法,利用张量对动作视频训练集和待识别动作视频数据集中的每一个动作视频数据进行表征,从而实现充分考虑视频数据空间信息的目的;在低维空间中保持从原始动作视频数据集中所提取的相似性和非相似性系数,使得低维判别性局部的局部边际得以最大化,从而能够更好地保护每个局部所携带的判别信息,然后通过最大化局部边际,提高判别性局部内动作数据点的识别准确率。
附图说明
[0071]
图1表示本发明实施例中提出的基于局部边际最大化的动作识别方法的流程图。
具体实施方式
[0072]
附图仅用于示例性说明,不能理解为对本专利的限制;
[0073]
为了更好地说明本实施例,附图某些部位会有省略、放大或缩小,并不代表实际尺寸;
[0074]
对于本领域技术人员来说,附图中某些公知内容说明可能省略是可以理解的。
[0075]
下面结合附图和实施例对本发明的技术方案做进一步的说明。
[0076]
实施例1
[0077]
如图1所示的基于局部边际最大化的动作识别方法的流程图,参见图1,所述方法包括以下步骤:
[0078]
s1.将动作视频数据集划分为动作视频训练集和待识别动作视频数据集;
[0079]
s2.将动作视频训练集和待识别动作视频数据集中的每一个动作视频数据表征为三阶视频序列张量,得到动作视频训练集张量和待识别动作视频数据集张量;
[0080]
s3.基于张量距离公式,将动作视频训练集划分为若干个判别性局部;
[0081]
s4.在高维空间中提取每个判别性局部的相似性系数和非相似性系数;
[0082]
s5.利用多线性投影方法,将动作视频训练集张量、提取到的每个判别性局部的相似性系数和非相似性系数映射到低维空间;
[0083]
s6.建立低维空间最大化局部边际优化函数,基于迭代优化求解优化函数的投影矩阵;
[0084]
s7.利用投影矩阵将动作视频训练集张量和待识别动作视频数据集张量均映射到低维空间,得到低维动作视频训练集张量及低维待识别动作视频数据集张量;
[0085]
s8.将低维动作视频训练集张量作为knn分类器的训练集,利用knn分类器对低维待识别动作视频数据集张量进行分类,完成动作识别。其中,knn分类器(基于k-nearest neighbor algorithmk最邻近方法)是一种统计分类器,对数据的特征变量的筛选尤其有效。
[0086]
在本实施例中,动作视频训练集中的每一个动作视频数据表征为三阶视频序列张量时,得到的动作视频训练集张量满足:
[0087][0088]
其中,表示动作视频训练集张量;i表示动作视频训练集中的动作视频编号;n表示动作视频训练集中动作视频的数量;i1表示动作视频训练集中动作视频每一帧的长度;i2表示动作视频训练集中动作视频每一帧的宽度;i3表示动作视频训练集中动作视频总的帧数;
[0089]
待识别动作视频数据集中的每一个动作视频数据表征为三阶视频序列张量时,得到的待识别动作视频数据集张量满足:
[0090][0091]
其中,表示待识别动作视频数据集张量;h表示待识别动作视频数据集中的动作视频编号;m表示待识别动作视频数据集中动作视频的数量;h1表示待识别动作视频数据集中动作视频的宽度;h2表示待识别动作视频数据集中动作视频的高度;h3表示待识别动作视频数据集中动作视频的长度。
[0092]
在本实施例中,步骤s3所述若干个判别性局部中第i个判别性局部的形成过程为:
[0093]
s31.根据张量距离公式求解张量距离,将求解的张量距离按从小到大排序,确定与动作视频训练集中每一个动作视频数据的动作视频训练集张量张量距离最近的k个动作视频训练张量,作为动作视频训练集张量的同类近邻点j=1,
…
,k,张量距离公式为:
[0094][0095]
其中,表示动作视频训练集张量与动作视频训练集张量之间的张量距离;i1、i2及i3分别表示动作视频训练集中动作视频的长度下标、宽度下标及总帧数下标;和分别表示动作视频训练集张量和动作视频训练集张量位于(i1,i2,i3)的元素大小;
[0096]
s32.动作视频训练集张量与构成第i个判别性局部表示为:
[0097][0098]
在本实施例中,在高维空间中提取第i个判别性局部的相似性系数的过程为:
[0099]
将第i个判别性局部的相似性系数定义为:
[0100][0101]
其中,w
i,j
表示第i个判别性局部的相似性系数;
[0102]
利用第一选择向量s
i,j
提取第i个判别性局部的相似性系数,将第一选择向量s
i,j
提取的结果作为第i个判别性局部的相似性系数,第一选择向量s
i,j
的表达式为:
[0103][0104]
其中,i,j=1,
…
,n,表示时,在中的序号。
[0105]
在本实施例中,在高维空间中提取第i个判别性局部的非相似性系数的过程为:
[0106]
利用第二选择向量l
i,j
提取第i个判别性局部的非相似性系数,将第二选择向量l
i,j
提取的结果作为第i个判别性局部的非相似性系数,第二选择向量l
i,j
的表达式为:
[0107][0108]
其中,i,j=1,
…
,n。
[0109]
在本实施例中,步骤s5所述将动作视频训练集张量映射到低维空间的过程为:
[0110]
定义一组投影矩阵为基于投影矩阵,将动作视频训练集张量映射到低维空间,映射公式满足:
[0111][0112]
其中,表示在低维空间的低维表示;
×
m
表示m的模式积,i
m
是高维空间中动作视频训练集张量第m维的维度;j
m
是低维空间中动作视频训练集张量第m维的维度。不同的投影矩阵会将原始视频序列张量映射到不同的低维空间,使用多线性投影方案,可以将原始视频序列张量投影到一个可区分度更高的低维空间,对于提取到的每个判别性局部的相似性系数和非相似性系数,以相同的多线性投影方法,映射到低维空间。
[0113]
在本实施例中,步骤s6所述建立的低维空间最大化局部边际优化函数包括第一优化函数及第二优化函数,所述第一优化函数为:
[0114][0115]
所述第二优化函数为:
[0116][0117]
其中,局部边际为判别性局部内外距离最近的两点之间的距离。最大化低维空间中的局部边际有利于局部内的数据点的识别,使得原始数据的判别信息得到很好的保持,为了在低维空间中最大化局部边际,每个局部内的近邻点向中心点靠近,而局部外的强干扰点应该远离局部。
[0118]
在本实施例中,步骤s6所述基于迭代优化求解优化函数的投影矩阵的过程为:
[0119]
s61.限制投影矩阵使其满足:
[0120][0121]
s62.将投影矩阵u1,u2,u3初始化为单位矩阵;
[0122]
s63.在每一次优化迭代中,仅优化投影矩阵u1,u2,u3中的一个投影矩阵,固定剩余的两个投影矩阵。
[0123]
s64.判断优化迭代是否达到最大值,若是,迭代结束;否则,返回步骤s63。
[0124]
在本实施例中,步骤s6所述的优化函数包括第一优化函数及第二优化函数,设步骤s63所述优化投影矩阵u1,u2,u3中的一个投影矩阵为u1,固定投影矩阵u2,u3,则第一优化函数为:
[0125][0126]
其中,其中,为张量ψ
i
的1模式展开,
[0127][0128]
第二优化函数为:
[0129][0130]
其中,
[0131]
在优化投影矩阵u1时,低维空间最大化局部边际优化函数转化为:
[0132]
第一优化函数转化为:
[0133][0134]
第二优化函数转化为:
[0135][0136]
即:
[0137][0138]
其中,θ=(f
non-local
)-1
f
local
,投影矩阵u1由θ的j
n
个最小特征值对应的特征向量组成。
[0139]
附图中描述位置关系的用于仅用于示例性说明,不能理解为对本专利的限制;显然,本发明的上述实施例仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1