一种应用于视频版权保护的视频待检索定位方法与流程
[0001]
本发明涉及视频版权保护领域,具体地涉及一种应用于视频版权保护的视频待检索定位方法。
背景技术:
[0002]
随着多媒体和互联网技术的快速发展,海量的视频数据已经广泛应用于社会的各个领域中,视频版权保护的问题日益严峻。通常利用视频待检索技术实现查找比对侵权视频和原始视频,其主要分为两个步骤:如何表达视频的特征信息以及高效的待检索方法。比如,国家专利公开文献cn111639228a,公开了“视频待检索方法、系统、设备及存储介质”,该发明包括接收视频待检索请求,视频待检索请求包括待检索信息;将待检索信息与视频索引信息进行匹配,得到视频待检索结果,视频索引信息是根据预设知识图谱对视频进行语义理解得到的,该视频索引信息用于表示视频与待检索信息之间的关系;输出视频待检索结果。该发明基于文本的视频待检索方法主要利用文本标注堆视频中的内容进行描述,但随着数据量级的快速增长,人工标注文本消耗成本高,已经不足以支撑现实中庞大的数据量,大数据下计算复杂度高。另外,现有的利用视频内容进行侵权检索方法在进行视频整体比对时难以从视频内容进行侵权定位,也无法获取侵权视频对于一些片段甚至一个画面的侵权。
[0003]
因此,亟需一种应用于视频版权保护的视频待检索定位方法能够利用高维视频特征以及更高效的待检索方法满足大规模数据下视频的比对识别以及侵权结果的快速查找排序。
技术实现要素:
[0004]
本发明提供一种应用于视频版权保护的视频待检索定位方法,从而解决现有技术的上述问题。
[0005]
第一方面,本发明提供了一种应用于视频版权保护的视频待检索定位方法,包括以下步骤:
[0006]
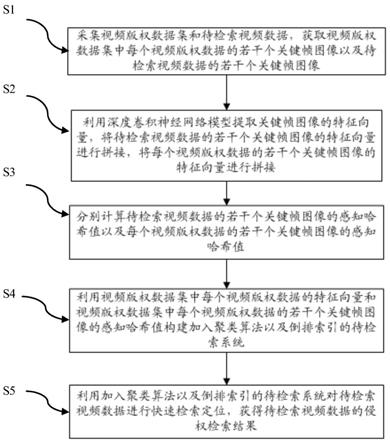
s1)采集视频版权数据集和待检索视频数据,获取视频版权数据集中每个视频版权数据的若干个关键帧图像以及待检索视频数据的若干个关键帧图像;
[0007]
s2)建立深度卷积神经网络模型,利用深度卷积神经网络模型提取关键帧图像的特征向量,将待检索视频数据的若干个关键帧图像的特征向量进行拼接,将每个视频版权数据的若干个关键帧图像的特征向量进行拼接,分别获得待检索视频数据的n
×
m维的特征向量以及视频版权数据集中每个视频版权数据的n
×
m维的特征向量;
[0008]
s3)分别计算待检索视频数据的若干个关键帧图像的感知哈希值以及每个视频版权数据的若干个关键帧图像的感知哈希值;
[0009]
s4)利用视频版权数据集中每个视频版权数据的n
×
m维的特征向量和视频版权数据集中每个视频版权数据的若干个关键帧图像的感知哈希值构建加入聚类算法以及倒排
索引的待检索系统;
[0010]
s5)利用加入聚类算法以及倒排索引的待检索系统对待检索视频数据进行快速检索定位,获得待检索视频数据的侵权检索结果。
[0011]
进一步的,在步骤s1)中,采集视频版权数据集和待检索视频数据,获取视频版权数据集中每个视频版权数据的若干个关键帧图像以及待检索视频数据的若干个关键帧图像,包括利用视频镜头分割方法分别对待检索视频数据以及视频版权数据集中每个视频版权数据进行视频镜头分割、并获取每个视频镜头中的代表帧,将代表帧作为关键帧,获得待检索视频数据的若干个关键帧图像以及视频版权数据集中每个视频版权数据的若干个关键帧图像;视频分割方法包括基于时域的视频对象分割方法、基于运动的视频对象分割方法或交互式视频对象分割方法。
[0012]
进一步的,在步骤s1)中,采集视频版权数据集和待检索视频数据,获取视频版权数据集中每个视频版权数据的若干个关键帧图像以及待检索视频数据的若干个关键帧图像,包括根据视频帧率对待检索视频数据以及视频版权数据集中每个视频版权数据分别进行图像采样,获得待检索视频数据的若干个采样帧以及视频版权数据集中每个视频版权数据的若干个采样帧,将采样帧作为关键帧,获得待检索视频数据的若干个关键帧图像以及视频版权数据集中每个视频版权数据的若干个关键帧图像。
[0013]
进一步的,在获取视频版权数据集中每个视频版权数据的若干个关键帧图像以及待检索视频数据的若干个关键帧图像之前,还包括将每个视频版权数据的若干个关键帧图像以及待检索视频数据的若干个关键帧图像中为无效帧的关键帧图像进行删除,无效帧的关键帧图像为纯白图像或纯黑图像。
[0014]
进一步的,步骤s2)中,建立深度卷积神经网络模型,利用深度卷积神经网络模型提取关键帧图像的特征向量,将待检索视频数据的若干个关键帧图像的特征向量进行拼接,将每个视频版权数据的若干个关键帧图像的特征向量进行拼接,分别获得待检索视频数据的n
×
m维的特征向量以及视频版权数据集中每个视频版权数据的n
×
m维的特征向量,包括以下步骤:
[0015]
s21)将待检索视频数据的若干个关键帧图像以及每个视频版权数据的若干个关键帧图像分别缩放到第一预设尺寸大小;
[0016]
s22)建立深度卷积神经网络模型,将缩放后的每个关键帧图像分别输入所述深度卷积神经网络模型,将深度卷积神经网络模型的最后一个卷积层的特征图作为输出;
[0017]
s23)采用r-mac方法对每个特征图提取若干不同尺度的区域,获得若干个区域r-mac特征,对所述若干个区域r-mac特征进行求和池化、并进行拼接,获得与每个关键帧图像对应的特征向量;
[0018]
s24)分别获得待检索视频数据的若干个关键帧图像的特征向量以及所述视频版权数据集中每个视频版权数据的若干个关键帧图像的特征向量。
[0019]
深度卷积神经网络模型在预训练时可以对反转、镜像、旋转等侵权对抗手段通过数据增强的方式在模型中进行微调。
[0020]
进一步的,步骤s3)中,分别计算待检索视频数据的若干个关键帧图像的感知哈希值以及每个视频版权数据的若干个关键帧图像的感知哈希值,包括以下步骤:
[0021]
s31)将待检索视频数据的若干个关键帧图像以及每个版权视频数据的若干个关
键帧图像分别缩放到第二预设尺寸大小;
[0022]
s32)将缩放到第二预设尺寸大小的每个关键帧图像分别转化为灰度图像;
[0023]
s33)计算转化为灰度图像后每个关键帧图像的离散余弦变换,获得离散余弦变换系数矩阵;
[0024]
s34)提取离散余弦变换系数矩阵的左上角预设大小的低频矩阵,计算低频矩阵的元素平均值,将低频矩阵中大于等于元素平均值的元素置1,将低频矩阵中小于元素平均值的元素置0,获得元素置1或置0的低频矩阵;
[0025]
s35)将元素置1或置0的低频矩阵压平为一维向量,获得待检索视频数据的若干个关键帧图像的感知哈希值以及每个视频版权数据的若干个关键帧图像的感知哈希值。
[0026]
进一步的,步骤s4)中,利用视频版权数据集中每个视频版权数据的n
×
m维的特征向量和视频版权数据集中每个视频版权数据的若干个关键帧图像的感知哈希值构建加入聚类算法以及倒排索引的待检索系统,n为若干个关键帧图像的总数,m为每个关键帧图像的特征向量的维度,包括以下步骤:
[0027]
s41)初始化待检索索引文件数据结构,所述待检索索引文件数据结构包括倒排列表、码表、倒排向量id表和/或倒排向量编码表;
[0028]
s42)获取训练数据,利用训练数据训练聚类算法;训练数据包括若干个数据点,若干个数据点分别为视频版权数据集中每个视频版权数据的n个m维的特征向量;建立倒排向量id表,倒排向量id表用于存储若干个数据点以及若干个数据点的id;
[0029]
s43)根据训练数据的数据量确定聚类的中心数以及每个聚类中心内的元素数量范围;
[0030]
s44)随机初始化所有聚类中心,对所有聚类中心及码表进行更新,包括以下步骤:
[0031]
s441)初始化所有聚类中心;
[0032]
s442)计算任意一个聚类中心c
q
到其他聚类中心的最短距离d(c
q
,c
w
),d(c
q
,c
w
)表示聚类中心c
q
与距离所述聚类中心c
q
最近的聚类中心c
w
的距离;
[0033]
s443)获取聚类中心c
q
所在簇中的数据点x到所述聚类中心c
q
的距离d(c
q
,x),判断2d(c
q
,x)≤d(c
q
,c
w
)是否成立,若否,则所述数据点x的归类位置不变;若否,则进入步骤s3034);
[0034]
s444)计算数据点x到其他聚类中心的距离,将数据点x归类到与其他聚类中心的距离最近的聚类中心的所在簇中;
[0035]
s445)重复步骤s442)至步骤s444),依次获得聚类中心c
q
所在簇中的每个数据点的归类位置;
[0036]
s446)重复步骤s442)至步骤s445),依次获得每个聚类中心所在簇中的每个数据点的归类位置;
[0037]
s447)更新所有聚类中心,判断所有聚类中心是否发生变动,若是,则返回步骤s442);若否,则结束聚类更新,获得更新完成后的所有聚类中心以及每个聚类中心所在簇中的所有数据点,每一个数据点对应有一个id,将更新完成后的所有聚类中心加入码表,将每个聚类中心所在簇中的所有数据点以及数据点的id存储进对应的倒排列表中,每个聚类中心对应有一个倒排列表,倒排列表中储存着倒排id和倒排编码表,所述倒排id用于存储数据点的id,所述倒排编码表用于存储聚类中心所在簇中的所有数据点。
[0038]
进一步的,在步骤s5)中,利用加入聚类算法以及倒排索引的待检索系统对待检索视频数据进行快速检索定位,获得待检索视频数据的侵权检索结果,包括以下步骤:
[0039]
s51)获取构造的待检索索引文件,计算待检索视频数据的每一个m维的特征向量与更新完成后的所有聚类中心之间的向量距离,获取距离所述待检索视频数据的第j个m维的特征向量最近的k个聚类中心点,j=1、2、
…
、n;
[0040]
s52)获取k个聚类中心点的倒排列表,通过openmp并列遍历k个聚类中心点的倒排编码表,计算待检索视频数据的第j个m维的特征向量与每个聚类中心点的倒排编码表中特征向量之间的距离;获得距离所述待检索视频数据的第j个m维的特征向量最近的若干个特征向量,若干个特征向量分别对应于不同视频版权数据的一个关键帧图像;
[0041]
s53)分别计算若干个特征向量与待检索视频数据的第j个m维的特征向量之间的欧式距离;
[0042]
s54)获取若干个特征向量对应的不同视频版权数据的关键帧图像的感知哈希值,分别计算待检索视频数据的第j个m维的特征向量对应的感知哈希值与若干个特征向量对应的不同视频版权数据的关键帧图像的感知哈希值之间的汉明距离;
[0043]
s55)建立评分函数f
i
=w1d
1i
+w2d
2i
,i=1、2、...、m,m为若干个特征向量的总数;w1为特征向量距离权重,w2为感知哈希值距离权重,d
1i
为所述若干个特征向量中的第i个特征向量与所述待检索视频数据的第j个m维的特征向量之间的欧式距离,d
2i
为所述待检索视频数据的第j个m维的特征向量对应的感知哈希值与第i个特征向量对应的不同视频版权数据的关键帧图像的感知哈希值之间的汉明距离;f
i
为与第i个特征向量相对应的视频版权数据的关键帧图像的评分值;
[0044]
s56)分别计算与所述若干个特征向量对应的不同视频版权数据的关键帧图像的评分值、并对评分值进行排序,设定评分阈值,筛选出前z个评分值大于所述评分阈值的特征向量对应的不同视频版权数据的关键帧图像;
[0045]
s57)根据筛选出的前z个评分值大于所述评分阈值的特征向量对应的不同视频版权数据的关键帧图像对所述待检索视频数据的第j个m维的特征向量对应的关键帧图像进行侵权定位统计;
[0046]
s58)重复步骤s51)至步骤s57),依次获得所述待检索视频数据的n个m维的特征向量对应的关键帧图像的侵权定位统计结果,所述待检索视频数据的每一帧关键帧图像分别对应于不同视频版权数据的不同帧关键帧图像;
[0047]
s59)根据侵权定位统计结果对待检索视频数据进行标记,获得待检索视频数据的侵权检索结果,待检索视频数据的侵权检索结果包括疑似全局相似、疑似部分相似或疑似画面相似;疑似全局相似、疑似部分相似或疑似画面相似分别对应于不同视频版权数据。
[0048]
进一步的,在步骤s5)中,还包括当待检索视频数据的侵权检索结果为疑似全局相似或疑似部分相似时对待检索视频数据进行侵权片段定位;进行侵权片段定位包括以下步骤:
[0049]
s61)当待检索视频数据的若干个关键帧图像为关键帧时,获取与待检索视频数据的侵权检索结果相对应的视频版权数据y1,获取待检索视频数据的若干个关键帧图像在视频版权数据y1中对应的关键帧图像的时间,根据关键帧图像的时间设置时间范围,根据时间范围获取待检索视频数据在所述视频版权数据y1中的侵权片段;
[0050]
s62)当待检索视频数据的若干个关键帧图像为采样帧时,获取与待检索视频数据的侵权检索结果相对应的视频版权数据y2,获取待检索视频数据的若干个关键帧图像在视频版权数据y2中对应的关键帧图像的时间,采用滑动窗口的方式进行双向扫描所述视频版权数据y2中对应的关键帧图像获取待检索视频数据在视频版权数据y2中的侵权片段。
[0051]
本发明的有益效果是:本发明首先通过深度卷积神经网络与r-mac方法结合提取视频的关键帧图像的高维特征向量,同时计算视频的关键帧图像的感知哈希值,两层尺度对视频进行识别比对,尤其是加强了对侵权视频可能出现的对抗攻击手段的识别,大大加强了模型的鲁棒性;本发明不仅能对待检索视频数据进行侵权检索,而且还能准确地定位到侵权视频片段或画面,定位准确率高。另外,本发明充分利用计算资源进行高效的聚类算法和倒排表计算,在单机效果小可实现千万视频数据秒级查询,提高了在海量数据下的检索效率;同时针对视频版权保护的特点,通过多种特征指标融合增加对侵权对抗方法的识别,最大程度保证了检索的准确率和召回率。另外,本发明通过提取视频的代表帧或采样帧的方法能够在一定程度下节约大量的储存和计算资源。
附图说明
[0052]
为了更清楚地说明本发明实施例的技术方案,下面将对实施例所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0053]
图1为本实施例一提供的应用于视频版权保护的视频待检索定位方法流程示意图。
具体实施方式
[0054]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不用于限定本发明。需要说明的是,本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用来区别类似的对象,而不必用于描述特定的顺序或先后次序,应该理解这样使用的术语在适当情况下可以互换,这仅仅是描述本发明的实施例中对相同属性的对象在描述时所采用的区分方式。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,以便一系列单元的过程、方法、系统、产品或设备不必限于那些单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其他单元。
[0055]
实施例一,s1)采集视频版权数据集和待检索视频数据,获取视频版权数据集中每个视频版权数据的若干个关键帧图像以及待检索视频数据的若干个关键帧图像。
[0056]
在步骤s1)中,采集视频版权数据集和待检索视频数据,获取视频版权数据集中每个视频版权数据的若干个关键帧图像以及待检索视频数据的若干个关键帧图像,包括利用视频镜头分割方法分别对待检索视频数据以及视频版权数据集中每个视频版权数据进行视频镜头分割、并获取每个视频镜头中的代表帧,将代表帧作为关键帧,获得待检索视频数据的若干个关键帧图像以及视频版权数据集中每个视频版权数据的若干个关键帧图像;视频分割方法包括基于时域的视频对象分割方法、基于运动的视频对象分割方法或交互式视频对象分割方法。
[0057]
在步骤s1)中,采集视频版权数据集和待检索视频数据,获取视频版权数据集中每个视频版权数据的若干个关键帧图像以及待检索视频数据的若干个关键帧图像,包括根据视频帧率对待检索视频数据以及视频版权数据集中每个视频版权数据分别进行图像采样,获得待检索视频数据的若干个采样帧以及视频版权数据集中每个视频版权数据的若干个采样帧,将采样帧作为关键帧,获得待检索视频数据的若干个关键帧图像以及视频版权数据集中每个视频版权数据的若干个关键帧图像。
[0058]
在获取视频版权数据集中每个视频版权数据的若干个关键帧图像以及待检索视频数据的若干个关键帧图像之前,还包括将每个视频版权数据的若干个关键帧图像以及待检索视频数据的若干个关键帧图像中为无效帧的关键帧图像进行删除,无效帧的关键帧图像为纯白图像或纯黑图像。
[0059]
在进行待检索时,可以利用视频镜头分割方法对视频版权数据集中每个视频版权数据分别进行视频镜头分割,获得每个视频版权数据的若干个关键帧图像。也可以根据视频帧率对视频版权数据集中每个视频版权数据分别进行关键帧图像采样(比如视频帧率为25fps的视频每隔50帧采样一次),本实施例通过视频镜头分割的代表帧进行检索,同时也能够利用采样帧进行最后的视频侵权片段的准确时间点定位。
[0060]
s2)建立深度卷积神经网络模型,利用深度卷积神经网络模型提取关键帧图像的特征向量,将待检索视频数据的若干个关键帧图像的特征向量进行拼接,将每个视频版权数据的若干个关键帧图像的特征向量进行拼接,分别获得待检索视频数据的n
×
m维的特征向量以及视频版权数据集中每个视频版权数据的n
×
m维的特征向量,包括以下步骤:
[0061]
s21)将待检索视频数据的若干个关键帧图像以及每个视频版权数据的若干个关键帧图像分别缩放到第一预设尺寸大小;
[0062]
s22)建立深度卷积神经网络模型,将缩放后的每个关键帧图像分别输入所述深度卷积神经网络模型,将深度卷积神经网络模型的最后一个卷积层的特征图作为输出;
[0063]
s23)采用r-mac方法对每个特征图提取若干不同尺度的区域,获得若干个区域r-mac特征,对所述若干个区域r-mac特征进行求和池化、并进行拼接,获得与每个关键帧图像对应的特征向量;
[0064]
s24)分别获得待检索视频数据的若干个关键帧图像的特征向量以及所述视频版权数据集中每个视频版权数据的若干个关键帧图像的特征向量。
[0065]
深度卷积神经网络模型在预训练时可以对反转、镜像、旋转等侵权对抗手段通过数据增强的方式在模型中进行微调。步骤s2)中将深度卷积神经网络模型最后一个卷积层计算得到的特征图通过r-mac方法进行区域特征提取,使用r-mac方法对图像中央指定的局部区域生成一系列的区域向量,之后进行求和池化进行向量聚合,输出为512维特征向量,将所有向量结果保存在数据库中待检索过程使用。深度卷积神经网络模型使用imagenet预训练模型参数,可选择在特定数据上进行微调,满足不同数量级数据的需要。深度卷积神经网络模型为选取在imagenet上预训练的vgg16或alexnet卷积神经网络。
[0066]
s3)分别计算待检索视频数据的若干个关键帧图像的感知哈希值以及每个视频版权数据的若干个关键帧图像的感知哈希值,包括以下步骤:
[0067]
s31)将待检索视频数据的若干个关键帧图像以及每个版权视频数据的若干个关键帧图像分别缩放到第二预设尺寸大小;
[0068]
s32)将缩放到第二预设尺寸大小的每个关键帧图像分别转化为灰度图像;
[0069]
s33)计算转化为灰度图像后每个关键帧图像的离散余弦变换,获得离散余弦变换系数矩阵;
[0070]
s34)提取离散余弦变换系数矩阵的左上角预设大小的低频矩阵,计算低频矩阵的元素平均值,将低频矩阵中大于等于元素平均值的元素置1,将低频矩阵中小于元素平均值的元素置0,获得元素置1或置0的低频矩阵;
[0071]
s35)将元素置1或置0的低频矩阵压平为一维向量,获得待检索视频数据的若干个关键帧图像的感知哈希值以及每个视频版权数据的若干个关键帧图像的感知哈希值。
[0072]
为了加强模型对于侵权图像的对抗攻击能力,在深度学习特征的基础上,选用感知哈希作为后验衡量指标,首先将关键帧图像缩放到32x32的尺寸,减少图像冗余信息同时加快离散余弦变换的计算,将关键帧图像转化为64度灰度图像,进一步简化计算量,计算图像的离散余弦变换,本实施例中得到32x32的离散余弦变换系数矩阵,保留离散余弦变换系数矩阵的左上角8x8的低频矩阵,计算元素平均值,将8x8的低频矩阵中大于等于元素平均值的元素设为1,小于元素平均值的元素设为0,压平为64位的一维向量。
[0073]
s4)利用视频版权数据集中每个视频版权数据的n
×
m维的特征向量和视频版权数据集中每个视频版权数据的若干个关键帧图像的感知哈希值构建加入聚类算法以及倒排索引的待检索系统,n为若干个关键帧图像的总数,m为每个关键帧图像的特征向量的维度,包括以下步骤:
[0074]
s41)初始化待检索索引文件数据结构,所述待检索索引文件数据结构包括倒排列表、码表、倒排向量id表和/或倒排向量编码表;
[0075]
s42)获取训练数据,利用训练数据训练聚类算法;训练数据包括若干个数据点,若干个数据点分别为视频版权数据集中每个视频版权数据的n个m维的特征向量;建立倒排向量id表,倒排向量id表用于存储若干个数据点以及若干个数据点的id;
[0076]
s43)根据训练数据的数据量确定聚类的中心数以及每个聚类中心内的元素数量范围;
[0077]
s44)随机初始化所有聚类中心,对所有聚类中心及码表进行更新,包括以下步骤:
[0078]
s441)初始化所有聚类中心;
[0079]
s442)计算任意一个聚类中心c
q
到其他聚类中心的最短距离d(c
q
,c
w
),d(c
q
,c
w
)表示聚类中心c
q
与距离所述聚类中心c
q
最近的聚类中心c
w
的距离;
[0080]
s443)获取聚类中心c
q
所在簇中的数据点x到所述聚类中心c
q
的距离d(c
q
,x),判断2d(c
q
,x)≤d(c
q
,c
w
)是否成立,若否,则所述数据点x的归类位置不变;若否,则进入步骤s3034);
[0081]
s444)计算数据点x到其他聚类中心的距离,将数据点x归类到与其他聚类中心的距离最近的聚类中心的所在簇中;
[0082]
s445)重复步骤s442)至步骤s444),依次获得聚类中心c
q
所在簇中的每个数据点的归类位置;
[0083]
s446)重复步骤s442)至步骤s445),依次获得每个聚类中心所在簇中的每个数据点的归类位置;
[0084]
s447)更新所有聚类中心,判断所有聚类中心是否发生变动,若是,则返回步骤
s442);若否,则结束聚类更新,获得更新完成后的所有聚类中心以及每个聚类中心所在簇中的所有数据点,每一个数据点对应有一个id,将更新完成后的所有聚类中心加入码表,将每个聚类中心所在簇中的所有数据点以及数据点的id存储进对应的倒排列表中,每个聚类中心对应有一个倒排列表,倒排列表中储存着倒排id和倒排编码表,所述倒排id用于存储数据点的id,所述倒排编码表用于存储聚类中心所在簇中的所有数据点。
[0085]
本发明通过运用三角不等式减少了不必要的距离计算,加速了聚类算法。训练聚类算法时固定每个聚类中心的元素数量范围可避免出现元素过少导致聚类中心无代表性,同时防止过多数据元素训练模型,徒增训练时间。
[0086]
s5)利用加入聚类算法以及倒排索引的待检索系统对待检索视频数据进行快速检索定位,获得待检索视频数据的侵权检索结果;包括以下步骤:
[0087]
s51)获取构造的待检索索引文件,计算待检索视频数据的每一个m维的特征向量与更新完成后的所有聚类中心之间的向量距离,获取距离所述待检索视频数据的第j个m维的特征向量最近的k个聚类中心点,j=1、2、
…
、n;
[0088]
s52)获取k个聚类中心点的倒排列表,通过openmp并列遍历k个聚类中心点的倒排编码表,计算待检索视频数据的第j个m维的特征向量与每个聚类中心点的倒排编码表中特征向量之间的距离;获得距离所述待检索视频数据的第j个m维的特征向量最近的若干个特征向量,若干个特征向量分别对应于不同视频版权数据的一个关键帧图像;
[0089]
s53)分别计算若干个特征向量与待检索视频数据的第j个m维的特征向量之间的欧式距离;
[0090]
s54)获取若干个特征向量对应的不同视频版权数据的关键帧图像的感知哈希值,分别计算待检索视频数据的第j个m维的特征向量对应的感知哈希值与若干个特征向量对应的不同视频版权数据的关键帧图像的感知哈希值之间的汉明距离;
[0091]
s55)建立评分函数f
i
=w1d
1i
+w2d
2i
,i=1、2、...、m,m为若干个特征向量的总数;w1为特征向量距离权重,w2为感知哈希值距离权重,d
1i
为所述若干个特征向量中的第i个特征向量与所述待检索视频数据的第j个m维的特征向量之间的欧式距离,d
2i
为所述待检索视频数据的第j个m维的特征向量对应的感知哈希值与第i个特征向量对应的不同视频版权数据的关键帧图像的感知哈希值之间的汉明距离;f
i
为与第i个特征向量相对应的视频版权数据的关键帧图像的评分值;
[0092]
s56)分别计算与若干个特征向量对应的不同视频版权数据的关键帧图像的评分值、并对评分值进行排序,设定评分阈值,筛选出前z个评分值大于所述评分阈值的特征向量对应的不同视频版权数据的关键帧图像;
[0093]
s57)根据筛选出的前z个评分值大于所述评分阈值的特征向量对应的不同视频版权数据的关键帧图像对待检索视频数据的第j个m维的特征向量对应的关键帧图像进行侵权定位统计;
[0094]
s58)重复步骤s51)至步骤s57),依次获得所述待检索视频数据的n个m维的特征向量对应的关键帧图像的侵权定位统计结果,所述待检索视频数据的每一帧关键帧图像分别对应于不同视频版权数据的不同帧关键帧图像;
[0095]
s59)根据侵权定位统计结果对待检索视频数据进行标记,获得所述待检索视频数据的侵权检索结果,待检索视频数据的侵权检索结果包括疑似全局相似、疑似部分相似或
疑似画面相似;疑似全局相似、疑似部分相似或疑似画面相似分别对应于不同视频版权数据。
[0096]
在步骤s5)中,还包括当待检索视频数据的侵权检索结果为疑似全局相似或疑似部分相似时对待检索视频数据进行侵权片段定位;进行侵权片段定位包括以下步骤:
[0097]
s61)当待检索视频数据的若干个关键帧图像为关键帧时,获取与待检索视频数据的侵权检索结果相对应的视频版权数据y1,获取待检索视频数据的若干个关键帧图像在视频版权数据y1中对应的关键帧图像的时间,根据关键帧图像的时间设置时间范围,根据时间范围获取待检索视频数据在所述视频版权数据y1中的侵权片段;
[0098]
s62)当待检索视频数据的若干个关键帧图像为采样帧时,获取与待检索视频数据的侵权检索结果相对应的视频版权数据y2,获取待检索视频数据的若干个关键帧图像在视频版权数据y2中对应的关键帧图像的时间,采用滑动窗口的方式进行双向扫描视频版权数据y2中对应的关键帧图像获取待检索视频数据在视频版权数据y2中的侵权片段。
[0099]
采样帧的作用和关键帧的作用相互独立,本实施例可以用关键帧检索关键帧,也可以用关键帧检索采样帧,或者采样帧检索采样帧,因为采样帧密度更大,检索准确率也会相对提高。另外,在需要进行侵权片段定位时,关键帧给的范围就是记录的连续相似匹配到的关键帧片段所对应的时间,此时如果需要更精细的时间就可以采用采样帧,通过一个滑动窗口来进行双向扫描,获取在预设的时间窗口大小范围内满足顺序匹配约束条件的最大权重的匹配对。
[0100]
本发明实施例中,待检索视频数据的nxm维的特征向量进行检索时,每个特征向量在筛选后得到一个相似向量列表,但是对于待检索视频数据的每一个m维的特征向量得到结果视频并不一定是对应的,比如,待检索视频数据有三帧关键帧图像,分别为关键帧f1、关键帧f2和关键帧f3,对三帧关键帧图像分别检索并筛选打分后得到的结果为:关键帧f1分别对应于视频版权数据集中视频1的第1帧关键帧图像、视频版权数据集中视频2的第1帧关键帧图像、视频版权数据集中视频3的第1帧关键帧图像以及视频版权数据集中视频3的第4帧关键帧图像;关键帧f2对应于视频版权数据集中视频1的第二帧关键帧图像、视频版权数据集中视频3的第二帧关键帧图像;关键帧f3对应于视频版权数据集中视频2的第3帧关键帧图像、视频版权数据集中视频3的第三帧关键帧图像,如表1所示。
[0101]
表1待检索视频数据的三帧关键帧图像与结果视频关键帧图像匹配表
[0102] 关键帧f1关键帧f2关键帧f3视频1第1帧第2帧空视频2第1帧空第3帧视频3第1帧、第4帧第2帧第3帧
[0103]
表1
[0104]
检索并筛选打分后得到的结果有出现一对多的情况(比如关键帧f1对应于视频版权数据集中视频3的第1帧关键帧图像以及视频版权数据集中视频3的第4帧关键帧图像),此时需要将两个结果同时保留。根据侵权定位统计结果对待检索视频数据进行标记,如果得到的侵权定位统计结果是在一个视频中能够统计到与待检索视频数据大部分帧相似,会将该视频标记为疑似全局相似;如果得到的侵权定位统计结果是一个视频中小段连续帧相似,则会将该视频标记为疑似部分相似,如果得到的侵权定位统计结果是一个视频中非常
零散的帧(存在些许几帧连续或者大量帧都是离散分开的),则会将该视频被标记为疑似画面相似。
[0105]
通过采用本发明公开的上述技术方案,得到了如下有益的效果:
[0106]
本发明首先通过深度卷积神经网络与r-mac方法结合提取视频的关键帧图像的高维特征向量,同时计算视频的关键帧图像的感知哈希值,两层尺度对视频进行识别比对,尤其是加强了对侵权视频可能出现的对抗攻击手段的识别,大大加强了模型的鲁棒性;另外,本发明充分利用计算资源进行高效的聚类算法和倒排表计算,在单机效果小可实现千万视频数据秒级查询,大大提高了在海量数据下的检索效率;同时针对视频版权保护的特点,通过多种特征指标融合增加对侵权对抗方法的识别,最大程度保证了检索的准确率和召回率。另外,本发明通过提取视频的代表帧或采样帧的方法能够在一定程度下节约大量的储存和计算资源。
[0107]
以上仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1