一种指数分布型产品可靠性评估方法与流程
本发明涉及一种指数分布型产品可靠性评估方法,属于产品可靠性、可靠性工程领域。
背景技术:
随着科技的进步和新型材料的发展,越来越多的产品呈现可靠性高,寿命长的特点。在自然贮存中,往往难以获得这类产品足够多的终态型寿命数据来支持有效的可靠性评估;因此,需要进行加速贮存试验来获得足够的数据,以外推方式评估自然贮存下的可靠性。加速寿命试验(alt)是在合理的工程及统计假设的基础上,提高试验应力水平,以快速获得产品寿命数据的试验方法。因其能够快速、有效地提供产品寿命数据,使得其在高可靠长寿命产品中的应用得到了高度重视,目前已被广泛应用于电子产品、航天航空及机械产品等领域。
然而,产品在不同的自然贮存环境下,所受应力不尽相同,单一地利用加速贮存数据评估常应力可靠性会存在误差,即加速贮存试验不能完全模拟自然贮存的环境。目前有许多研究着眼于融合自然贮存数据和加速贮存数据来提高加速试验估计的精度,但多是应用贝叶斯法进行信息的融合统计推断,建立未知参数的估计模型,运用最大期望法(em算法)或马尔科夫蒙特卡罗法(mcmc算法)进行未知参数的估计。但该类方法对未知参数的先验分布的选取过于主观,需进一步探讨。
在运用加速贮存试验对自然贮存产品进行评估时,加速模型是信息转换枢纽,其因控变量之间的响应形式和系数估计也因而成为重点研究目标之一。在因控变量的响应形式上,对于电子产品的可靠性评估,双应力加速模型往往更符合实际工程需求。指数分布是电子产品常见分布类型之一,考虑到自然贮存数据和加速贮存数据各自具有重要的信息量和统计片面性缺陷,以及基于贝叶斯统计模型的方法先验分布确定的困难性和后验分布求解的复杂性,本发明针对指数分布型产品提供一种基于相对熵信息融合的双应力恒加试验可靠性评估方法。
技术实现要素:
本发明以加速模型的参数优化为目的,基于相对熵和最小二乘统计法相结合的思想,针对指数型产品自然贮存现场数据和加速贮存样本数据,有效地融合两源数据信息,建立综合可靠性评估模型,为仅采用加速试验样本数据进行建模,反推自然贮存下产品的寿命特征存在的不足及利用信息不全等问题,提供一种基于相对熵信息融合的双应力恒加试验产品可靠性评价方法。
为了实现上述发明目的,本发明提供一种指数分布型产品可靠性评估方法,具体包括如下步骤:
步骤1、对指数分布型产品进行恒定应力定数截尾试验,并根据试验结果进行参数估计,获得指数分布型产品在恒定应力定数截尾试验下的寿命分布密度函数;其中,所述寿命分布密度函数为:
其中,
式中,
步骤2、基于步骤1建立的寿命分布密度函数构建基于相对熵的加速模型参数估计目标函数;其中,参数估计目标函数为:
其中,θij满足
步骤3、基于步骤2建立的所述参数估计目标函数对指数分布型产品的加速模型进行修正;其中,当待估参数a、b、c、d使得所述参数估计目标函数f(a,b,c,d)与g(a,b,c,d)之和达到最小值时,即为所述待估参数的修正值。
优选地,在步骤3中,首先将所述参数估计目标函数f(a,b,c,d)和g(a,b,c,d)标准化为:
其中,fmin为目标函数fs(a,b,c,d)的最小值;gmin为目标函数gs(a,b,c,d)的最小值;
随后,构建综合目标函数h(a,b,c,d)=fs(a,b,c,d)+gs(a,b,c,d),并将所述综合目标函数转化为如下方程组,通过求解如下方程组获得所述综合目标函数的最小值;
其中,
将上述方程组的解
与现有技术相比,本发明的有益效果:
本发明基于模型级融合思路,结合kl散度与最小二乘法,综合运用了自然贮存数据和加速贮存数据的信息,针对双应力恒加试验寿命分布为指数分布型产品,提供了一种信息融合综合评估方法。发明优点:
1)解决了仅利用自然贮存数据进行的统计推断受数据量过小影响,造成产品可靠性评价不准确的问题。
2)有机地将加速贮存数据与自然贮存数据信息融合,对加速模型系数进行了修正,使模型评估结果更准确。
3)本发明的方法具有可信度,在随机1000次模拟试验中,达到真实值的成功率达到95.10%。
多次模拟试验结果表明,在自然数据较少的情况下,该方法的评估结果不会出现较大偏差,具有稳健性。
附图说明:
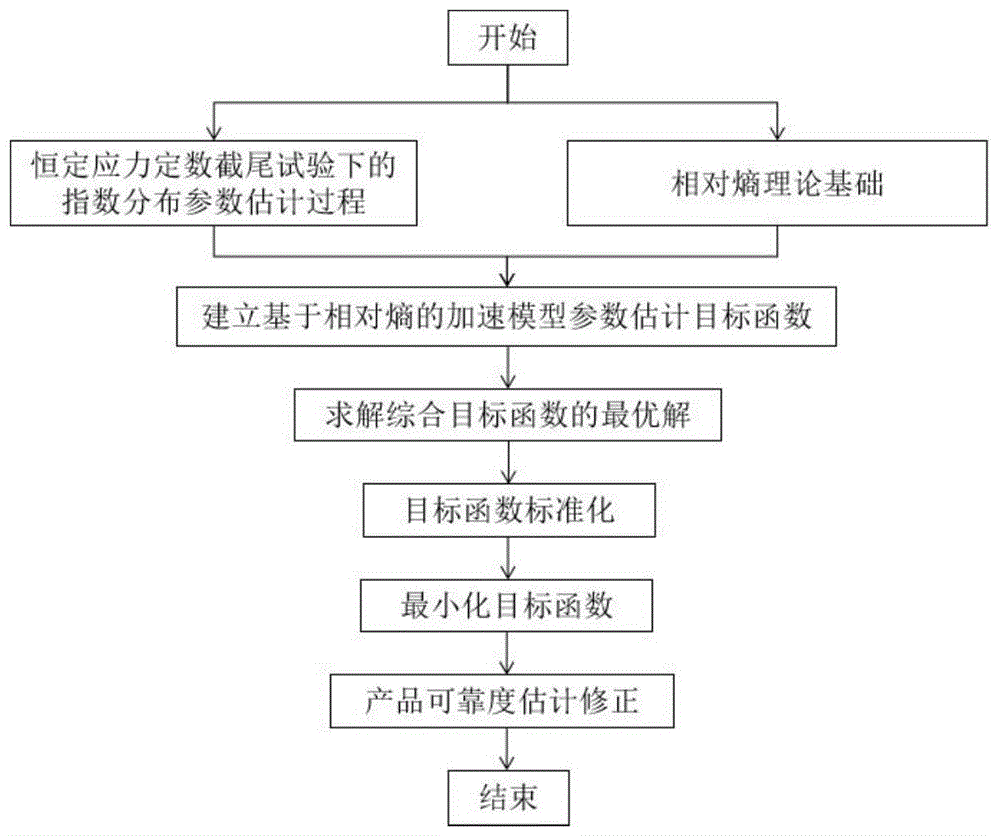
图1为本发明的产品可靠性评价方法流程;
图2为不同估计方法下的产品可靠性;
图3为1000次模拟中平均寿命估计散点图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合附图,对本发明实施例中的技术方案进行清楚、完整的描述。显然,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。
因此,以下对本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的部分实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征和技术方案可以相互组合。
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。
在本发明的描述中,需要说明的是,术语“上”、“下”等指示的方位或位置关系为基于附图所示的方位或位置关系,或者是该发明产品使用时惯常摆放的方位或位置关系,或者是本领域技术人员惯常理解的方位或位置关系,这类术语仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”等仅用于区分描述,而不能理解为指示或暗示相对重要性。
相对熵又称kullback-leibler散度(kl散度),用以表示随机变量x的拟合分布q(x)对随机变量x的真实分布p(x)进行匹配时的信息损失量,从定义易知,kl散度值越小,表明模型与实际数据间匹配程度越好,kl散度的定义分别有离散和连续2种表达方式
其中,在离散的情形下p(x),q(x)是随机变量x的两个概率分布函数,在连续的情况下,p(x),q(x)分别是分布p和q的概率密度函数,n表示离散情况下随机变量x的取值个数,ω表示连续情况下一维随机变量x的取值范围,由于本文数据为寿命数据,范围应为(0,+∞)。
kl散度具有一些特殊的性质,从定义式中可以看出dkl(p||q)≠dkl(q||p),因此kl散度不能表示距离,但为方便陈述,本发明中将称为“距离”。此外,由jensen不等式可知,kl散度大于等于零,当且仅当分布p和q相同时,kl散度为零。
由于加速贮存试验条件有限,无法完全模拟出自然贮存的全部情形,因此通过加速贮存数据评估自然贮存情形的可靠度,会出现信息损失,而kl散度可以用来描述这样的信息损失,因此,本发明提出应用kl散度对寿命分布为指数分布的加速寿命试验评估结果进行修正。
首先,对试验样品进行恒定应力定数截尾试验下的指数分布参数估计。设恒加实验的各应力组合及自然贮存条件为(ii,tj),i=0,1,…,k,j=0,1,…,l,且i≠j时,i·j≠0。其中,i表示电压,单位为v;t表示温度,单位为k;i表示电压应力等级,j表示温度应力等级。(i0,t0)表示自然贮存条件,且i0<i1<…ik,t0<t1<…tl。指数寿命分布类产品的加速试验基于以下两个假设进行。
假设1:在自然贮存和加速贮存条件下,产品的寿命均服从失效率为λij的指数分布,i=0,1,…,k,j=0,1,…,l,且i≠j时,i·j≠0。
假设2:产品在双应力组合(ii,tj)下试验,且该应力组合下的产品平均寿命θij满足加速模型:
其中
在以上假设条件下进行定数截尾试验,在应力组合(ii,tj)条件下,即在所有应力水平及自然贮存条件下,从产品中分别随机抽取nij个试验样本量进行定数截尾试验,在各组的nij个样本中观测到截尾试验的截尾数为rij,即有rij个失效时停止试验,记录其失效时间依次为tij(1)≤tij(2)≤…≤tij(k),k=0,1,…,rij,其中tij(k)表示第k个截尾样本的截尾时间。
由假设1,各组样本的平均寿命θij=1/λij,即其寿命分布的密度函数为
其中,i=0,1,…,k,j=0,1,…,l,且i≠j时,i·j≠0。
因此,各组样本的似然函数为
其中,
因此,在各应力组合的加速试验和自然贮存中,寿命分布的密度函数为:
随后,基于相对熵理论,构建基于相对熵的加速模型参数估计目标函数。具体地,由假设2知,双应力组合(ii,tj)和该应力组合下特征寿命ξij之间的加速模型为:
式中的
其中,i=0,1,…,k,j=0,1,…,l,且i≠j时,i·j≠0。因此,在确定参数a、b、c、d后,通过公式(8)可得指数分布情形下,由加速贮存数据评估得到的自然贮存下的平均寿命θ00为:
其中,
根据最小二乘法的思想,由加速模型得到的各应力组合下的寿命特征估计值与极大似然法得到的估计值之间的距离为:
其中,
而根据前述的kl散度的定义知,由式(2)、式(6)、式(10)三式可得加速贮存试验结果评估所得自然贮存下寿命分布与自然贮存下的寿命分布的“距离”如式(12)所示:
根据上述公式可知,式(11)表示由加速模型得到的各应力组合下的寿命特征估计值与极大似然法得到的估计值之间的距离。而式(12)中通过kl散度来表述,加速模型外推获得的自然贮存下寿命分布和利用自然贮存数据进行极大似然估计得到的自然贮存下寿命分布之间的“距离”。即式(11)和式(12)分别代表加速模型结果与加速试验数据和自然贮存数据之间的“差异”,因此结合式(11)与式(12)可以达到综合利用两源数据的目的。
因此参数估计的问题,转化为确定参数值a、b、c、d同时使得式(11)和式(12)达到最小。简化式(12),令
取:
其中,
对于上述目标函数而言,由于二者量纲可能不一致,因此在求解的过程中需要对f(a,b,c,d)和g(a,b,c,d)进行标准化。首先分别求取f(a,b,c,d)和g(a,b,c,d)的最小值,由kl散度性质可得,当θ’00=θ00时,f(a,b,c,d)取最小值,记最小值为:
fmin=1+lnθ’00.(14)
同时,此时的解记为(afm,bfm,cfm,dfm)。
又由于g(a,b,c,d)也是a、b、c、d的连续函数,对g(a,b,c,d)分别求a、b、c、d的偏导
其中,
a(a,b,c,d)′=b.(15)
其中:
因此,当a-1存在时,式(15)的解为
(a,b,c,d)′=a-1b.
记解为(agm,bgm,cgm,dgm)′,此时取得g(a,b,c,d)的最小值记为gmin。
选取极值法无量纲方法,得到二者的标准化为
由于fs(a,b,c,d)和gs(a,b,c,d)具有相同的量纲,且取值范围均为[0,1),因此,考虑最小化目标函数:
h(a,b,c,d)=fs(a,b,c,d)+gs(a,b,c,d).(17)
由于fs(a,b,c,d)和gs(a,b,c,d)二者皆为关于a、b、c、d的值域为[0,1)的连续函数,且分别与f(a,b,c,d)和g(a,b,c,d)的增减性相同,则h(a,b,c,d)为关于a、b、c、d的连续函数,且存在驻点,其最小值点在其驻点处取得。对h(a,b,c,d)求a、b、c、d偏导:
令各偏导式为零,由式(14),可转化为
以消元法解上述方程组,可得h(a,b,c,d)的驻点,考虑其实际意义,易知,h(a,b,c,d)的最小值点应在(agm,bgm,cgm,dgm)′附近取得,因此若出现多个驻点,则在(agm,bgm,cgm,dgm)′相近处取得,记为
由前述公式(10)可得,修正之后自然贮存下的产品寿命分布密度函数为:
其中,
为了验证上述本发明提出的一种恒定应力情形下加速寿命试验产品可靠性评价方法的有效性,本发明如下进行仿真对比分析进行验证。
首先,基于最小二乘法估计产品可靠度。假定对某寿命指数型产品进行恒加双应力加速试验,应力分别为:电压(i/v)与温度(t/k),其不同应力组合下参与试验的样本数n与失效寿命数据(t/h)如表1所示(试验截尾数为9)。
表1不同应力组合下的产品失效寿命数据
表2不同应力组合下产品平均寿命估计
由上述寿命数据对各应力下产品的平均寿命进行极大似然估计:
结果如表2所示,其中平均寿命单位为h。以平均寿命参数为因变量,各应力组合为自变量,通过最小二乘法,得到加速方程中各系数a、b、c、d的估计分别为10.92,-7.08,920.51,1817.08,则加速方程为:
则假设自然贮存条件为i0=6.3v,t0=313.0k,其平均寿命估计值为:
因此,产品可靠度函数为
rlse(t)=e-t/99721.33.
其中,rlse(t)表示通过最小二乘法得到的产品可靠度函数。
采用极大似然估计方法估计产品可靠度如下:
由于缺少真实自然贮存环境下产品寿命数据,因此采用蒙特卡洛模拟的方法,通过软件随机生成1000个θ00的值。以此1000个θ00进行模拟,得到自然贮存下产品寿命“真实值”。每次模拟的流程如下:
首先,生成特征寿命为θ00的40个指数型寿命数据,并进行失效数为5的定数截尾模拟;
随后,以上述数据对产品的平均寿命进行极大似然估计:
模拟获得的寿命数据依次为:
3658.26,5834.52,10412.04,13722.24,14302.51
因此,平均寿命θ’00=109703.48,此时可靠度函数为:
r’mle(t)=e-t/109703.48.
其中,r’mle(t)表示通过极大似然估计法得到的产品可靠度函数。
本发明提出的基于相对熵信息融合的产品可靠度估计算例如下:
同样地,采用上述随机生成1000个θ00的值,生成特征寿命为θ00的40个指数型寿命数据,并进行失效数为5的定数截尾模拟;随后,以上述数据,对产品的平均寿命进行极大似然估计;再通过解方程组(18)可得,最小化目标函数h(a,b,c,d)对应的参数a、b、c、d的值;由上一步所得参数值,可计算信息融合模型估计的平均寿命为:
利用r软件中bfgs方法(拟牛顿法),得到h(a,b,c,d)最小值为3.01×10-4,此时a、b、c、d分别取值为10.72,-7.02,996.00,1793.94。因此,平均寿命估计值为:
此时,可靠度计算为:
rkl(t)=e-t/101813.70.
分析mle、lse、信息融合模型三种方法计算得到的可靠度函数变化趋势,图2显示了不同估计方法下的产品可靠性,信息融合模型对应的可靠度函数值介于另外两种方法对应的可靠度函数值之间,这也充分体现了信息融合模型方法对自然贮存数据和加速贮存数据的融合特征。
上述模拟过程重复1000次,得到的平均寿命估计值如图3所示。在1000次模拟中,代表mle方法所得估计值的点呈现较为分散的特征,表明一次mle估计结果可能存在较大偏差度。而代表信息融合模型所得估计值的点较为集中,表明该模型估计的稳健性。且在1000次模拟试验中,信息融合模型相较于mle方法得出的估计值,有951次更接近“真实值”。
根据上述计算结果可知,本发明的方法具有可信度,在随机1000次模拟试验中,达到真实值的成功率达到95.10%。多次模拟试验结果表明,在自然数据较少的情况下,该方法的评估结果不会出现较大偏差,具有稳健性。
以上实施例仅用以说明本发明而并非限制本发明所描述的技术方案,尽管本说明书参照上述的各个实施例对本发明已进行了详细的说明,但本发明不局限于上述具体实施方式,因此任何对本发明进行修改或等同替换;而一切不脱离发明的精神和范围的技术方案及其改进,其均涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!