基于KV数据库的数据表关联方法及装置与流程
本发明涉及大数据技术领域,尤其涉及一种基于kv数据库的数据表关联方法及装置。
背景技术:
在数据仓库的应用中,数据表之间的关联为普遍性操作,在分布式计算环境中,现有技术中的数据表关联经常会出现如下问题:
1、事实表指标类数值数据分布不均出现长尾问题;
2、维度表太大,导致加载io和算力消耗大。
技术实现要素:
本发明的目的在于提供一种基于kv数据库的数据表关联方法及装置,能够有效解决数据表关联出现的长尾问题和算力消耗大的问题。
为了实现上述目的,本发明的第一方面提供一种基于kv数据库的数据表关联方法,包括:
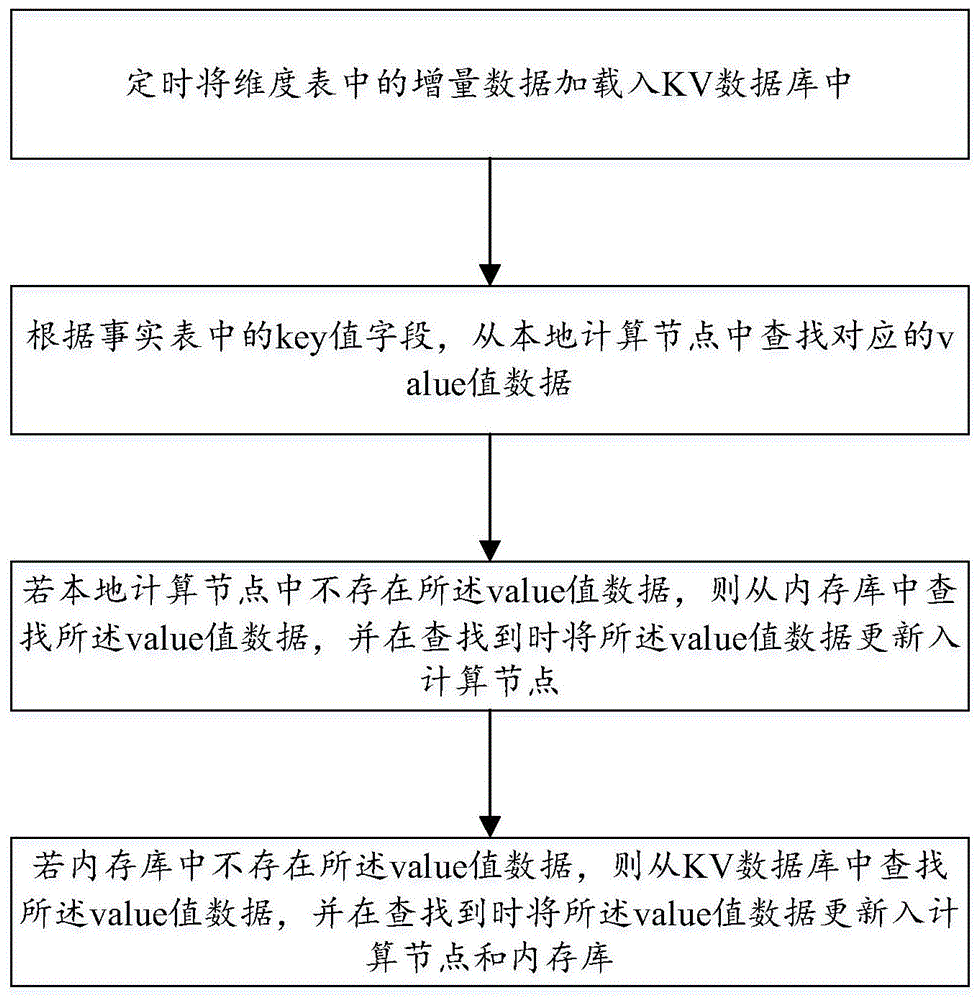
根据事实表中的key值字段,从本地计算节点中查找对应的value值数据;
若本地计算节点中不存在所述value值数据,则从内存库中查找所述value值数据,并在查找到时将所述value值数据更新入计算节点;
若内存库中不存在所述value值数据,则从kv数据库中查找所述value值数据,并在查找到时将所述value值数据更新入计算节点和内存库。
优选地,在步骤根据事实表中的key值字段,从本地计算节点中查找对应的value值数据之前还包括:
定时将维度表中的增量数据加载入kv数据库中。
较佳地,根据事实表中的key值字段,从本地计算节点中查找对应的value值数据的方法包括:
所述本地计算节点中包括事实表存储区和本地缓存区,根据数据表关联请求sql从事实表存储区读取事实表中的key值字段,再从本地缓存区中查找对应的value值数据。
示例性地,所述本地缓存区为cache。
优选地,将所述value值数据更新入计算节点的方法包括:
将所述value值数据更新入cache中。
与现有技术相比,本发明提供的用于数据库审计系统的sql新语句识别方法具有以下有益效果:
本发明提供的基于kv数据库的数据表关联方法中,数据表关联请求sql执行时,可以根据事实表中的key值字段,首先从本地计算节点中查找对应的value值数据,若本地计算节点中能查找到对应的value值数据则直接返回,若本地计算节点中查找不到对应的value值数据,则再从内存库中查找对应的value值数据,若内存库中能查找到对应的value值数据则直接返回,同时将value值数据更新入计算节点中,若内存库中查找不到则需从kv数据库中查找对应的value值数据,并在查找到时将value值数据更新入计算节点和内存库。
可见,本发明针对事实表和维度表的关联业务场景,能够减少数据分发过程(shuffle过程),使得事实表和维度表能够在map端关联计算,不会出现数据倾斜问题;另外,将增量维度数据定期加载到kv库中,在事实表关联时可按照实际发生的维度获取kv库中的维度数据,避免了每次将全量维度表加载计算导致性能消耗大的问题。
本发明的第二方面提供一种基于kv数据库的数据表关联装置,应用于上述技术方案所述的基于kv数据库的数据表关联方法中,所述装置包括:
关联查找单元,用于根据事实表中的key值字段,从本地计算节点中查找对应的value值数据;
第一处理单元,用于若本地计算节点中不存在所述value值数据,则从内存库中查找所述value值数据,并在查找到时将所述value值数据更新入计算节点;
第二处理单元,用于若内存库中不存在所述value值数据,则从kv数据库中查找所述value值数据,并在查找到时将所述value值数据更新入计算节点和内存库。
优选地,所述本地计算节点中包括事实表存储区和本地缓存区,关联查找单元根据数据表关联请求sql从事实表存储区读取事实表中的key值字段,再从本地缓存区中查找对应的value值数据。
示例性地,所述本地缓存区为cache。
优选地,将所述value值数据更新入计算节点的方法包括:
将所述value值数据更新入cache中。
与现有技术相比,本发明提供的基于kv数据库的数据表关联装置的有益效果与上述技术方案提供的基于kv数据库的数据表关联方法的有益效果相同,在此不做赘述。
本发明的第三方面提供一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序,计算机程序被处理器运行时执行上述基于kv数据库的数据表关联方法的步骤。
与现有技术相比,本发明提供的计算机可读存储介质的有益效果与上述技术方案提供的基于kv数据库的数据表关联方法的有益效果相同,在此不做赘述。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本发明的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1为本发明实施例中基于kv数据库的数据表关联方法的一种流程示意图;
图2为本发明实施例中查找value值数据的交互逻辑示例图;
图3为本发明实施例中基于kv数据库的数据表关联方法的另一种流程示意图。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其它实施例,均属于本发明保护的范围。
实施例一
请参阅图1-图3,本实施例提供一种基于kv数据库的数据表关联方法,包括:
根据事实表中的key值字段,从本地计算节点中查找对应的value值数据;若本地计算节点中不存在value值数据,则从内存库中查找value值数据,并在查找到时将value值数据更新入计算节点;若内存库中不存在value值数据,则从kv数据库中查找value值数据,并在查找到时将value值数据更新入计算节点和内存库。
本实施例提供的基于kv数据库的数据表关联方法中,数据表关联请求sql执行时,可以根据事实表中的key值字段,首先从本地计算节点中查找对应的value值数据,若本地计算节点中能查找到对应的value值数据则直接返回,若本地计算节点中查找不到对应的value值数据,则再从内存库中查找对应的value值数据,若内存库中能查找到对应的value值数据则直接返回,同时将value值数据更新入计算节点中,若内存库中查找不到则需从kv数据库中查找对应的value值数据,并在查找到时将value值数据更新入计算节点和内存库。
可见,本实施例针对事实表和维度表的关联业务场景,能够减少数据分发过程(shuffle过程),使得事实表和维度表能够在map端关联计算,不会出现数据倾斜问题;另外,将增量维度数据定期加载到kv库中,在事实表关联时可按照实际发生的维度获取kv库中的维度数据,避免了每次将全量维度表加载计算导致性能消耗大的问题。
上述实施例中,在步骤根据事实表中的key值字段,从本地计算节点中查找对应的value值数据之前还包括:
定时将维度表中的增量数据加载入kv数据库中。
上述实施例中,根据事实表中的key值字段,从本地计算节点中查找对应的value值数据的方法包括:
所述本地计算节点中包括事实表存储区和本地缓存区,根据数据表关联请求sql从事实表存储区读取事实表中的key值字段,再从本地缓存区中查找对应的value值数据。示例性地,上述本地缓存区为cache。
上述实施例中,将value值数据更新入计算节点的方法包括:
将value值数据更新入cache中。
请参阅图3,具体实施时,据数据表关联请求sql执行数据表关联操作,基于输入的key值字段,从本地计算节点中查找对应的value值数据,若查找到了则返回value值数据,若没查找到了,继续从内存库中查找对应的value值数据,若查找到了,将内存库中对应的value值数据更新入本地计算节点中,同时返回对应的value值数据,若仍未查找到,则请求kv数据库继续查找对应的value值数据,并将查找到的结果更新入内存库和计算节点,同时返回对应的value值数据。
可见,上述实施例针对事实表和维度表关联业务场景,使用kv库、缓存计算能力和分布式udf计算能力,将sql关联计算转换为函数计算,解决了如下问题:
1、将commonjoin转换为函数计算,减少数据shuffle过程,事实表和维度表关联在map端计算,不会出现数据倾斜问题;
2、将增量维度数据定时加载如kv数据库,事实表关联按照实际发生维度获取kv数据库的维度数据,避免了每次将全量维度表加载计算导致性能消耗大的问题。进而减少平台的资源消耗,提升计算效率。
综上,上述实施例具有如下有益效果:
1、将上述逻辑使用sql封装,降低使用门槛,提升开发效率;
2、对于大型事实表的数据倾斜问题,以往的sql优化需要针对key分布做优化,优化操作复杂,使用此方案,不需要关心key值的数据分布,直接按照设定节点的数据大小分配计算资源,使得数据计算资源能够分配均匀,更高效的利用好大数据的计算资源;
3、对于大型维度表,仅需要加载使用到的维度数据,减少获取维度数据的计算开销,提升计算性能;
4、以往每个sql执行过程中使用的维度热点数据互不共享,每次使用需要各自加载和销毁,考虑到实际业务中,不同业务计算场景中的维度热点数据往往都比较相似,通过引入内存库,可以缓存当前热点维度数据,每个sql之间能共享热点数据,提升大数据sql的处理性能。
实施例二
本实施例提供一种基于kv数据库的数据表关联装置,包括:
关联查找单元,用于根据事实表中的key值字段,从本地计算节点中查找对应的value值数据;
第一处理单元,用于若本地计算节点中不存在所述value值数据,则从内存库中查找所述value值数据,并在查找到时将所述value值数据更新入计算节点;
第二处理单元,用于若内存库中不存在所述value值数据,则从kv数据库中查找所述value值数据,并在查找到时将所述value值数据更新入计算节点和内存库。
优选地,所述本地计算节点中包括事实表存储区和本地缓存区,关联查找单元根据数据表关联请求sql从事实表存储区读取事实表中的key值字段,再从本地缓存区中查找对应的value值数据。
示例性地,所述本地缓存区为cache。
优选地,将所述value值数据更新入计算节点的方法包括:
将所述value值数据更新入cache中。
与现有技术相比,本发明实施例提供的基于kv数据库的数据表关联装置的有益效果与上述实施例一提供的基于kv数据库的数据表关联方法的有益效果相同,在此不做赘述。
实施例三
本实施例提供一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序,计算机程序被处理器运行时执行上述基于kv数据库的数据表关联方法的步骤。
与现有技术相比,本实施例提供的计算机可读存储介质的有益效果与上述技术方案提供的基于kv数据库的数据表关联方法的有益效果相同,在此不做赘述。
本领域普通技术人员可以理解,实现上述发明方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,上述程序可以存储于计算机可读取存储介质中,该程序在执行时,包括上述实施例方法的各步骤,而的存储介质可以是:rom/ram、磁碟、光盘、存储卡等。
以上,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!