加速单元、相关装置和方法与流程
1.本公开涉及芯片领域,更具体而言,涉及一种加速单元、相关装置和方法。
背景技术:
2.大数据为机器学习、模型分析提供了巨大机遇,但是出于隐私考虑,数据往往不能共享,形成数据孤岛。例如,平台需要收集用户终端上用户的行为偏好数据,以此进行大数据分析,进行资源更合理的投放,但用户又不希望暴露自己的隐私。基于同态加密的隐私计算应运而生。它意在打破数据孤岛,在不泄露数据隐私的前提下利用数据进行计算建模。同态加密是指这样一种加密函数,对明文进行环上的加法和乘法运算再加密,与加密后对密文进行相应的运算,结果是等价的。由于这个良好的性质,可以委托第三方对数据进行处理而不泄露信息。具有同态性质的加密函数是指两个明文a、b满足dec(en(a)
⊙
en(b))=a
⊕
b的加密函数,其中en是加密运算,dec是解密运算,
⊙
、
⊕
分别对应明文和密文域上的运算。当
⊕
代表加法时,称该加密为加同态加密:当
⊕
代表乘法时,称该加密为乘同态加密。
3.目前,同态加密在硬件上可以通过中央处理单元(cpu)、图形处理单元(gpu)、现场可编程门阵列(fpga)等实现。无论是cpu、gpu,还是fpga,其硬件都是针对同态加密的局部算法设计,有损于全局性能,且硬件针对同态加密的专用算法设计,通用性差。一旦同态加密的算法改变,原来规划的cpu、gpu或fpga等硬件方式可能不再适用,需要迁移到另一种硬件方式。
技术实现要素:
4.有鉴于此,本公开旨在提供一种通用的、全局性能好的、扩展性强的同态加密的硬件实现方式。
5.根据本公开的一方面,提供了一种加速单元,包括:
6.一个或多个数论变换单元,用于执行同态加密过程中的数论变换;
7.一个或多个算术逻辑单元,用于执行同态加密过程中的算术运算;
8.调度器,用于将待执行同态加密指令中的运算分配给所述一个或多个数论变换单元和所述一个或多个算术逻辑单元中的至少一个。
9.可选地,该加速单元还包括:
10.指令缓冲器,用于接收控制信号,所述控制信号包括所述待执行同态加密指令;
11.取指令单元,用于从所述指令缓冲器取出所述待执行同态加密指令;
12.指令译码单元,用于对所述取指令单元取回的所述待执行同态加密指令进行译码,并将译码后的所述待执行同态加密指令发送给所述调度器。
13.可选地,所述控制信号还包括访问存储器地址;所述加速单元还包括:存储器接口,与存储器进行数据传输;直接存储器访问单元,用于接收所述指令缓冲器发来的访问存储器地址,指示所述存储器接口按照所述访问存储器地址取所述待执行同态加密指令需要的数据。
14.可选地,所述调度器将所述待执行同态加密指令分成以下运算中的至少一个:模乘运算、模加运算、数论变换、逆数论变换、模交换、密钥交换、重新伸缩。
15.可选地,对于所述模乘运算或模加运算,所述调度器分配给所述一个或多个算术逻辑单元中的至少一个。
16.可选地,对于所述数论变换,所述调度器分配给所述一个或多个数论变换单元中的至少一个。
17.可选地,对于所述逆数论变换,所述调度器将所述逆数论变换分解成数论变换与模乘运算的组合,将分解成的数论变换分配给所述一个或多个数论变换单元中的至少一个,分解成的模乘运算分配给所述一个或多个算术逻辑单元中的至少一个。
18.可选地,对于所述模交换,所述调度器将所述模交换分解成模加和模乘的组合,分配给所述一个或多个算术逻辑单元中的至少一个。
19.可选地,对于所述密钥交换,所述调度器将所述密钥交换分解成数论变换、逆数论变换、模乘、模交换,并按照分解结果分配给所述一个或多个数论变换单元或所述一个或多个算术逻辑单元中的至少一个。
20.可选地,对于所述重新伸缩,所述调度器将所述重新伸缩分解成数论变换、逆数论变换、模交换,并按照分解结果分配给所述一个或多个数论变换单元或所述一个或多个算术逻辑单元中的至少一个。
21.可选地,所述一个或多个数论变换单元中的至少一个包括:
22.第一多项式系数存储子单元;
23.第二多项式系数存储子单元;
24.旋转因子存储子单元,用于存储所述数论变换中的旋转因子;
25.蝴蝶处理子单元,用于执行第一蝴蝶处理和第二蝴蝶处理,其中,所述第一蝴蝶处理包括:从所述第一多项式系数存储子单元读取第一多项式系数对,从所述旋转因子存储子单元中获取该第一多项式系数对所对应的旋转因子,基于该第一多项式系数对和所述旋转因子得到第二多项式系数对,写入所述第二多项式系数存储子单元;所述第二蝴蝶处理包括:从所述第二多项式系数存储子单元读取第三多项式系数对,从所述旋转因子存储子单元中获取该第三多项式系数对所对应的旋转因子,基于该第三多项式系数对和所述旋转因子得到第四多项式系数对,写入所述第一多项式系数存储子单元。
26.可选地,所述一个或多个数论变换单元中的至少一个还包括:控制单元,用于控制所述第一多项式系数存储子单元、所述第二多项式系数存储子单元、所述旋转因子存储子单元和所述蝴蝶处理子单元的运行。
27.可选地,所述第一多项式系数存储子单元和所述第二多项式系数存储子单元各包括多个存储体,每个存储体具有相应索引,所述第一多项式系数对与所述第三多项式系数对来自相同索引的存储体,所述第二多项式系数对与所述第四多项式系数对来自相同索引的存储体。
28.可选地,所述第一多项式系数存储子单元或所述第二多项式系数存储子单元中的存储体有m个,所述蝴蝶处理子单元有m/2个,且对于单个蝴蝶处理子单元,所述第一多项式系数对来自的一对存储体的索引与所述第三多项式系数对来自的一对存储体的索引相同,且该对存储体中的两个存储体的索引相差m/2;所述第二多项式系数对来自的一对存储体
的索引与所述第四多项式系数对来自的一对存储体的索引相同,且该对存储体中的两个存储体的索引相邻。
29.可选地,在经过log2m次的第一蝴蝶处理或第二蝴蝶处理后,所述控制单元将所述第一多项式系数存储子单元或所述第二多项式系数存储子单元转置,再由所述蝴蝶处理子单元进行log2m的第一蝴蝶处理或第二蝴蝶处理,其中,所述转置包括:将转置前所述第一多项式系数存储子单元或所述第二多项式系数存储子单元的各存储体中排队在同一序号的多项式系数取出,按照存储体索引顺序放置在转置后的一个存储体中。
30.可选地,所述蝴蝶处理子单元包括第一多路选通器、第二多路选通器、第三多路选通器、第四多路选通器、第一加法器、第二加法器、第一减法器、第二减法器、第一乘法器。
31.可选地,所述第一多项式系数对或第三多项式系数对中的第一系数输入到所述第一多路选通器的第一输入端,并与所述第一多项式系数对或第三多项式系数对中的第二系数经第一加法器相加后输入到所述第一多路选通器的第二输入端,由所述第一多路选通器的第一选通信号选通所述第一输入端和第二输入端中的一路到输出端;所述第二系数输入到所述第三多路选通器的第二输入端,并与第一系数经第一减法器相减后输入到所述第三多路选通器的第一输入端,由所述第三多路选通器的第三选通信号选通所述第一输入端和第二输入端中的一路到输出端,经第一乘法器与相应旋转因子相乘,得到积信号。
32.可选地,所述第一多路选通器的输出端输出的信号输入到所述第二多路选通器的第一输入端,并与所述积信号经第二加法器相加后输入到所述第二多路选通器的第二输入端,由所述第二多路选通器的第二选通信号选通所述第一输入端和第二输入端中的一路到输出端,作为第二多项式系数对或第四多项式系数对中的一个系数;所述积信号输入到所述第四多路选通器的第二输入端,并与所述第一多路选通器输出的信号经第二减法器相减后输入到所述第四多路选通器的第一输入端,由所述第四多路选通器的第四选通信号选通所述第一输入端和第二输入端中的一路到输出端,作为第二多项式系数对或第四多项式系数对中的另一个系数。
33.可选地,所述算术逻辑单元包括模加器、模乘器、第五多路选通器、第六多路选通器、第七多路选通器,其中,第一输入信号输入到第五多路选通器和第六多路选通器的第一输入端,所述模加器的输出输入到第六多路选通器的第二输入端,所述模乘器的输出输入到第五多路选通器的第二输入端,由第五多路选通器的第五选通信号选通所述第五多路选通器的第一输入端和第二输入端中的一路到输出端,由第六多路选通器的第六选通信号选通所述第六多路选通器的第一输入端和第二输入端中的一路到输出端,所述第五多路选通器的输出端连接所述模加器的第一输入端,所述模加器的第二输入端输入第二输入信号,所述第六多路选通器的输出端连接所述模乘器的第一输入端,所述模乘器的第二输入端输入第三输入信号,所述模加器的输出端连接到第七多路选通器的第一输入端,所述模乘器的输出端连接到第七多路选通器的第二输入端,由第七多路选通器的第七选通信号选通所述第七多路选通器的第一输入端和第二输入端中的一路到输出端。
34.可选地,通过将所述第五选通信号置位成选通第一输入端,将所述第七选通信号置位成选通第一输入端,所述算术逻辑单元用于模加运算。
35.可选地,通过将所述第六选通信号置位成选通第一输入端,将所述第七选通信号置位成选通第二输入端,所述算术逻辑单元用于模乘运算。
36.可选地,通过将所述第五选通信号置位成选通第二输入端,将所述第六选通信号置位成选通第一输入端,将所述第七选通信号置位成选通第一输入端,所述算术逻辑单元用于先模乘后模加运算。
37.可选地,通过将所述第五选通信号置位成选通第一输入端,将所述第六选通信号置位成选通第二输入端,将所述第七选通信号置位成选通第二输入端,所述算术逻辑单元用于先模加后模乘运算。
38.根据本公开的一方面,提供了一种计算装置,包括:
39.存储器,用于存储待执行同态加密指令;
40.如上所述的加速单元;
41.处理单元,用于加载所述待执行同态加密指令,将所述待执行同态加密指令分配到所述加速单元执行。
42.根据本公开的一方面,提供了一种片上系统,包括如上所述的加速单元。
43.根据本公开的一方面,提供了一种数据中心,包括如上所述的计算装置。
44.根据本公开的一方面,提供了一种同态加密方法,包括:
45.接收待执行同态加密指令;
46.将所述待执行同态加密指令分解成运算;
47.将所述运算所包含的数论变换分配到一个或多个数论变换单元中的至少一个执行,将所述运算所包含的算术运算分配到一个或多个算术逻辑单元中的至少一个执行。
48.本公开实施例通过对同态加密各类算法的分析和分解,确定同态加密分解成的各类运算(包括模加、模乘、数论变换/逆数论变换、密钥交换、模交换、重新伸缩等)最后都能分解成数论变换和算术逻辑(模加、模乘及其组合),因此,引入数论变换单元执行数论变换,引入算术逻辑单元执行算术逻辑,通过调度器的调度,若干数论变换单元和若干算术逻辑单元可以独立执行不同的任务,也可以组成流水线顺序执行同一任务的不同阶段,因此该架构可以高效地兼容不同种类的算法。相比于现有技术中针对局部算法设计硬件,它提高了全局性能。相比于现有技术中针对专用算法设计硬件,它可扩展性和通用性强。一旦同态加密的算法改变,由于新的算法仍然可以通过数论变换和算术逻辑的各种组合实现,其仍可以不改变硬件结构。因此,本公开实施例提出了一种通用的、全局性能好的、扩展性强的同态加密的硬件实现方式。
附图说明
49.通过参考以下附图对本公开实施例的描述,本公开的上述以及其它目的、特征和优点将更为清楚,在附图中:
50.图1是本公开一个实施例所应用的数据中心的结构图;
51.图2是本公开一个实施例的数据中心中一个服务器的内部结构图;
52.图3是根据本公开一个实施例的服务器内部的处理单元和加速单元的内部结构图;
53.图4是图3中数论变换单元的一种内部结构图;
54.图5是图4中蝴蝶处理子单元的一种内部结构图;
55.图6是图3中算术逻辑单元的一种内部结构图;
56.图7是图6的各控制端子a、b、c为不同输入的组合的情况下算术逻辑单元行使的功能的表格;
57.图8是根据本公开一个实施例的蝴蝶处理子单元如何在第一多项式系数存储子单元和第二多项式系数存储子单元之间取放数据的示意图;
58.图9是根据本公开的一个实施例的同态加密方法的流程图。
具体实施方式
59.以下基于实施例对本公开进行描述,但是本公开并不仅仅限于这些实施例。在下文对本公开的细节描述中,详尽描述了一些特定的细节部分。对本领域技术人员来说没有这些细节部分的描述也可以完全理解本公开。为了避免混淆本公开的实质,公知的方法、过程、流程没有详细叙述。另外附图不一定是按比例绘制的。
60.在本文中使用以下术语。
61.隐私计算:大数据为机器学习、模型分析提供了巨大机遇,但是出于隐私考虑,数据往往不能共享,形成数据孤岛。例如,平台需要收集用户终端上用户的行为偏好数据,以此进行大数据分析,进行资源更合理的投放,但用户又不希望暴露自己的隐私。隐私计算应运而生。隐私计算是指在不泄露数据隐私的前提下利用数据进行计算建模。
62.同态加密:是指这样一种加密函数,对明文进行环上的加法和乘法运算再加密,与加密后对密文进行相应的运算,结果是等价的。由于这个良好的性质,可以委托第三方对数据进行处理而不泄露信息。具有同态性质的加密函数是指两个明文a、b满足dec(en(a)
⊙
en(b))=a
⊕
b的加密函数,其中en是加密运算,dec是解密运算,
⊙
、分别对应明文和密文域上的运算。当
⊕
代表加法时,称该加密为加同态加密:当代表乘法时,称该加密为乘同态加密。
63.加速单元:针对传统处理单元在一些专门用途的领域(例如,处理图像、处理深度学习网络的各种运算,等等)效率不高的情况,为了提高在这些专门用途领域中的数据处理速度而设计的处理单元。加速单元也称为人工智能(ai)处理单元,包括中央处理器(cpu)、图形处理器(gpu)、通用图形处理器(gpgpu)、现场可编程门阵列(fpga)、专用集成电路(asic)、以及专用智能加速硬件(例如,神经网络处理器npu、硬件加速器等)。在本公开实施例中采用的加速单元是针对同态加密领域设计的,提高了同态加密的通用性和全局性。
64.处理单元:在数据中心的服务器中进行传统处理(非用于图像处理和各种深度学习网络中的全连接运算等复杂运算的处理)的单元。另外,处理单元还承担着对加速单元和自身的调度职能,向加速单元和自身分配需要承担的任务。处理单元可以采用处理单元(cpu)、专用集成电路(asic)、现场可编程门阵列(fpga)等多种形式。
65.数论变换(number theoretic transform):一种计算卷积的快速演算法。算法本身类似于快速傅里叶变换,但是不同于快速傅里叶变换中旋转因子是复数,数论转换中的旋转因子是模p的整数。换句话说,快速傅里叶变换是定义在复平面上的变换,而数论转换时定义在多项式环上的变换。它广泛地应用于同态加密中。在同态加密中,明文或密文都以多项式系数的方式体现。一个多项式的各系数首尾相接,形成多项式环。在加密时,首先将明文处理成多项式系数,加密的过程是对各系数进行运算处理,变成其它数值,解密的过程是将其变回原来的数值。对密文的各种处理也是通过对密文多项式系数进行各种变换实现
的。无论是明文系数或密文系数的变换,一种重要的变换就是数论变换。
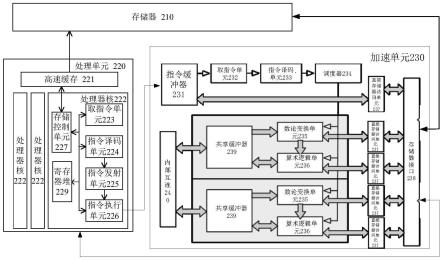
66.逆数论变换:上述数论变换的相反过程。逆数论变换可以看作是数论变换和模乘运算的组合。
67.加密过程中的算术运算:一般指模运算,主要是模加和模乘运算,以及模加和模乘的各种组合。模是“mod”的音译,模运算多应用于程序编写中。mod的含义为求余。模运算在数论和程序设计中都有着广泛的应用,从奇偶数的判别到素数的判别,从模幂运算到最大公约数的求法,从孙子问题到凯撒密码问题,无不充斥着模运算的身影。模加运算是这样一种运算:(a+b)%p,其结果是a+b算术和除以p的余数,作为变换后的多项式系数,也就是说,(a+b)=kp+r,其中,k、p、r为正整数。模乘运算是这样一种运算:(a*b)%p,其结果是a*b算术乘法除以p的余数,作为变换后的多项式系数,也就是说,(a*b)=kp+r,其中,k、p、r为正整数。
68.模交换(modulus switch):在同态加密的技术中,密文以多项式系数的形式存在,这些系数是模另一个数的剩余类,模交换的目的是将这些系数所对应的模数换成另一个模数。例如,原本这些系数是模5的剩余类,模交换后变成模3的剩余类。因此,经过模交换中,多项式系数会变化。模交换可以分解成上述模加和模乘的基本运算的组合。
69.密钥交换(key switch):在同态加密的技术中,密文的多项式系数是用特定密钥对明文加密而得到的。密钥交换可以对密文进行处理,将其密钥换成另一个密钥,这个处理过程需要一个额外的换成的密钥,称之为密钥交换密钥(key-switch key)。经过密钥交换,密文多项式系数变换成了另外的密文多项式系数。密钥交换可以分解成数论变换、逆数论变换、模乘、模交换运算的组合。
70.重新伸缩(rescale):给定一个模m的数a(0《=a《m)和一个伸缩因子r,重新伸缩意味着将a除以r,伸缩后的数a’=a/r的范围变成了0《=a《m/r。通过重新伸缩,上述密文多项式系数都变成的原来的1/r。可以将重新伸缩分解成数论变换、逆数论变换、模交换的组合。
71.调度:一方面将指令中的运算按照指令中的运算顺序排序,另一方面根据待调度单元(本公开实施例中是各数论变换单元和各算术逻辑单元)的负荷,将这些运算分配到合适的单元执行,这整个的过程叫做调度。
72.蝴蝶处理:数论变换可以看成对多项式环的多项式系数按照同一规则进行反复处理的过程,例如将多项式环某两个固定位置的多项式系数取出,用旋转因子处理,得到一对新的多项式系数放回多项式环的另两个固定位置,如将多项式环的第1个多项式系数和第5个多项式系数取出,用旋转因子处理后,放回多项式环的第1和多项式系数位置和第2个多项式系数位置。当所有多项式系数都取出并用旋转因子处理,再放入多项式环的其它多项式系数位置后,再重复上述过程,即将新多项式环的第1个多项式系数和第5个多项式系数取出,用旋转因子处理后,放回多项式环的第1和多项式系数位置和第2个多项式系数位置。为了反复执行这一操作,创建了蝴蝶处理。即,设置两个多项式环的存储子单元,当从第一个存储子单元的预定位置取出多项式系数后,用旋转因子处理,放入第二个存储子单元的另外的预定位置。反过来,再从该第二个存储子单元的预定位置取出多项式系数后,用旋转因子处理,放入第一个存储子单元的另外的预定位置。这样,简化了数论变换中的用旋转因子反复处理的过程,将该反复的过程看成是同一过程针对不同存储子单元的倒换操作。每一次取多项式系数、处理、并将结果写入不同多项式系数位置的操作,叫做蝴蝶处理。
73.存储体:存储模块,每个存储模块上按顺序容纳一个存储队列,例如,本公开实施例的多项式系数形成的队列。如图8所示的例子中,第一多项式系数存储子单元2351或第二多项式系数存储子单元2352各包括若干存储体23511,每个存储体存放8个多项式系数的队列。当密文表示为64个多项式系数的多项式时,64个多项式系数就可以分布在8个存储体中,每个存储体中存放8个多项式系数。
74.转置:阵列的行变成阵列的列,阵列的列变成阵列的行。当明文或密文表示成多项式的多项式系数后,各多项式系数如上所述存储在多个存储体中,每个存储体存储一部分多项式系数。在该上下文中,转置是指,让每个存储体的相同位置(相同索引)的多项式系数成为一个新的列(存储体),使得新的每列(每个存储体)各含有原来的每个存储体的各一个多项式系数,即各存储体中存放的多项式系数阵列的行和列互换。
75.多路选通器:连接多个输入端,响应于选通信号,将多个输入端的一路连接到输出端输出的器件。
76.片上系统(soc:system-on-a-chip)指的是在单个芯片上集成一个完整的系统,对所有或部分必要的电子电路进行分组的技术。所谓完整的系统一般包括中央处理器(cpu)或加速单元、存储器、以及外围电路等。soc是与其它技术并行发展的,如绝缘硅(soi),它可以提供增强的时钟频率,从而降低微芯片的功耗。
77.数据中心
78.数据中心是全球协作的特定设备网络,用来在互联网网络基础设施上传递、加速、展示、计算、存储数据信息。在今后的发展中,数据中心也将会成为企业竞争的资产。随着数据中心应用的广泛化,人工智能等越来越多地应用到数据中心。而深度学习作为人工智能的重要技术,已经大量应用到数据中心大数据分析运算中。
79.在传统的大型数据中心,网络结构通常如图1所示,即互连网络模型(hierarchical inter-networking model)。这个模型包含了以下部分:
80.服务器140:各服务器140是数据中心的处理和存储实体,数据中心中大量数据的处理和存储都是由这些服务器140完成的。
81.接入交换机130:接入交换机130是用来让服务器140接入到数据中心中的交换机。一台接入交换机130接入多台服务器140。接入交换机130通常位于机架顶部,所以它们也被称为机顶(top of rack)交换机,它们物理连接服务器。
82.汇聚交换机120:每台汇聚交换机120连接多台接入交换机130,同时提供其他的服务,例如防火墙,入侵检测,网络分析等。
83.核心交换机110:核心交换机110为进出数据中心的包提供高速的转发,为汇聚交换机120提供连接性。整个数据中心的网络分为l3层路由网络和l2层路由网络,核心交换机110为通常为整个数据中心的网络提供一个弹性的l3层路由网络。
84.通常情况下,汇聚交换机120是l2和l3层路由网络的分界点,汇聚交换机120以下的是l2网络,以上是l3网络。每组汇聚交换机管理一个传送点(pod,point of delivery),每个pod内都是独立的vlan网络。服务器在pod内迁移不必修改ip地址和默认网关,因为一个pod对应一个l2广播域。
85.汇聚交换机120和接入交换机130之间通常使用生成树协议(stp,spanning tree protocol)。stp使得对于一个vlan网络只有一个汇聚层交换机120可用,其他的汇聚交换机
120在出现故障时才被使用。也就是说,在汇聚交换机120的层面,做不到水平扩展,因为就算加入多个汇聚交换机120,仍然只有一个在工作。
86.本公开实施例可以被应用于隐私保护多方计算、隐私保护机器学习、端上预测等场景。当应用于隐私保护多方计算时,进行计算的是图1中的一台服务器140。多方计算需要用多方的数据,其中需要用到的是一些方的明文数据,和另一些方的密文数据。这些明文数据或密文数据可能分别来自于图1中的另一些服务器140。进行计算的服务器140通过上述接入交换机130、汇聚交换机120、核心交换机110等连接到明文数据或密文数据所在的服务器140,从数据所在的服务器140获取明文数据或密文数据,利用本公开实施例的下述硬件结构进行同态加密运算。
87.服务器
88.服务器140是数据中心真实的处理设备。图2示出了一个服务器140内部的结构框图。服务器140包括有总线连接的存储器210、处理单元集群270和加速单元集群280。处理单元集群270包括多个处理单元220。加速单元集群280包括多个加速单元230。加速单元230即为了提高在专门用途领域中的数据处理速度而设计的处理单元。加速单元即人工智能(ai)处理单元,包括中央处理器(cpu)、图形处理器(gpu)、通用图形处理器(gpgpu)、现场可编程门阵列(fpga)、专用集成电路(asic)、以及专用智能加速硬件(例如,神经网络处理器npu、硬件加速器等)。
89.传统的处理单元220的架构设计,使得在架构中控制单元、存储器占用了很大一部分空间,而计算单元占用的空间反而不足,因此其在逻辑控制方面十分有效,而在大规模并行计算方面则效率不够。因此,开发出了各种专门的加速单元230,用来针对不同功能和不同领域的计算进行更有效的提高运算速度的处理。在本公开实施例中,加速单元230是为了进行同态加密运算设计的硬件加速器。这种运算中的数据和中间结果在整个计算过程中紧密联系,会被经常用到,用现有的处理单元构架,由于处理单元的核内的内存容量很小,因此要大量频繁访问核外存储器,造成处理的低效。采用这种专用的加速单元,由于其具有大量内部缓冲器等结构,避免频繁访问核外部的存储器,大大提高处理效率,提高计算性能。另外,本公开实施例的加速单元230设计时考虑到对于各种同态加密运算的通用性和总体性,这将在下文详细描述。
90.加速单元230要接受处理单元220的调度。存储器210中存储有同态加密指令。当需要时这些指令被图2中的一个处理单元220部署到一个加速单元230。即,处理单元220可以通过指令的形式向加速单元230发送同态加密指令中的参数在存储器210中的地址。加速单元230在进行同态加密计算时,就会根据这些参数在存储器210中的地址,直接在存储器210中寻址这些参数,将其暂存在其内部缓冲器中,进行同态加密运算。
91.处理单元和加速单元的内部结构
92.下面结合图3的处理单元220与加速单元230的内部结构图,具体说明处理单元220是如何调度加速单元230和自身进行工作的。
93.如图3所示,处理单元220内包含多个处理器核222和被多个处理器核222共享的高速缓存221。每个处理器核222包括取指令单元203、指令译码单元224、指令发射单元225、指令执行单元226。
94.取指令单元223用于将要执行的指令从存储器210中搬运到指令寄存器(可以是图
3示出的寄存器堆229中的一个用于存放指令的寄存器)中,并接收下一个取指地址或根据取指算法计算获得下一个取指地址,取指算法例如包括:根据指令长度递增地址或递减地址。
95.取出指令后,处理单元220进入指令译码阶段,指令译码单元224按照预定的指令格式,对取回的指令进行解码,以获得取回的指令所需的操作数获取信息,从而为指令执行单元225的操作做准备。操作数获取信息例如指向立即数、寄存器或其他能够提供源操作数的软件/硬件。
96.指令发射单元225位于指令译码单元224与指令执行单元226之间,用于指令的调度和控制,以将各个指令高效地分配至不同的指令执行单元226,使得多个指令的并行操作成为可能。
97.指令发射单元225将指令发射到指令执行单元226后,指令执行单元226开始执行指令。但如果该指令执行单元226判断该指令应该是加速单元执行的,则将其转发到相应的加速单元执行。例如,如果该指令是待执行同态加密指令,则指令执行单元226不再执行该指令,而是将该指令通过总线发送到加速单元230,由加速单元230执行。
98.现有技术中对同态加密运算进行加速的加速单元230可以采用中央处理单元(cpu)、图形处理单元(gpu)、现场可编程门阵列(fpga)三种方式。采用cpu的方案实现了同态加密中较为完备的算子,包括密钥生成、加解密、密钥交换、模交换等。有些场景也利用了cpu提供的多线程功能。采用gpu的方案充分利用了gpu进行处理的并行性,对同态加密中易于并行的算子(数论变换等)进行gpu加速。实验表明,其可以比cpu处理时加速几倍到几十倍。采用fpga的方案将同态加密的算法实现在fpga,充分利用硬件的流水线和高吞吐的特性。它们的缺点是,无论是cpu、gpu,还是fpga,它们都是针对局部算法设计,有损于全局性能。硬件针对专有算法实现,通用性差。
99.本公开实施例采用图3中加速单元230的结构,其克服了上述现有技术硬件实现中的缺点,通用性强,全局性能好,扩展性强。
100.如图3所示,加速单元230包括指令缓冲器231、取指令单元232、指令译码单元233、调度器234、数论变换单元235、算术逻辑单元236、直接存储器访问单元237、存储器接口238、共享缓冲器239、内部互连240等。数论变换单元235可以有一个或多个,算术逻辑单元236也可以由一个或多个。
101.指令执行单元226向加速单元230发送的不只是待执行同态加密指令,还有待执行同态加密指令所需要的数据存储在存储器210的访问存储器地址。指令执行单元226可以将待执行同态加密指令以及该访问存储器地址合成到控制信号中,发送到加速单元230。
102.该控制信号首先进入加速单元230的指令缓冲器231。指令缓冲器231一方面将待执行同态加密指令缓存,另一方面将访问存储器地址发送到直接存储器访问单元237。直接存储器访问单元237接收所述访问存储器地址,指示与存储器210进行数据传输的存储器接口238按照所述访问存储器地址,从存储器210取出所述待执行同态加密指令需要的数据。这样,当数论变换单元235和算术逻辑单元236真正执行指令时,就可以从直接存储器访问单元237直接获得所述数据。
103.取指令单元232从所述指令缓冲器231取出所述待执行同态加密指令,发送给指令译码单元233。指令译码单元233对所述取指令单元232取回的所述待执行同态加密指令进
行译码,并将译码后的所述待执行同态加密指令发送给调度器234。注意,在处理单元220中的指令译码单元224已经对待执行同态加密指令进行过译码,在这里重新译码的原因在于,加速单元230能够理解的指令集与处理单元220能够理解的指令集不一定相同,因此需要重新进行译码,将其译成能够被加速单元230的指令集理解的指令。
104.如上所述,同态加密的各类运算包括模加、模乘、数论变换/逆数论变换、密钥交换、模交换、重新伸缩等。关于模加、模乘、数论变换/逆数论变换、密钥交换、模交换、重新伸缩的概念在上文的术语解释中已经描述。对于模加和模乘运算,其是一种算术逻辑运算,可以由一个或多个算术逻辑单元236中的至少一个执行。对于数论变换,其可以由一个或多个数论变换单元235中的至少一个执行。对于逆数论变换,其可以看成数论变换与模乘运算的组合,其中的数论变换由一个或多个数论变换单元235中的至少一个执行,模乘运算由一个或多个算术逻辑单元236中的至少一个执行。对于模交换,其可以看成模加和模乘的组合,由一个或多个算术逻辑单元236中的至少一个执行。对于密钥交换,其可以看成数论变换、逆数论变换、模乘、模交换的组合,逆数论变换和模交换可以再分解,最终由一个或多个数论变换单元235和一个或多个算术逻辑单元236中的至少一个执行。对于重新伸缩,其可以看成数论变换、逆数论变换、模交换,逆数论变换和模交换可以再分解,最终由一个或多个数论变换单元235和一个或多个算术逻辑单元236中的至少一个执行。从上可知,待执行同态加密指令包含的所有运算最终都可以分解成由一个或多个数论变换单元235和一个或多个算术逻辑单元236中的至少一个执行的运算。调度器234就是将待执行同态加密指令中的各运算分配给一个或多个数论变换单元235和一个或多个算术逻辑单元236中的至少一个执行的单元。其具体做法是将所述待执行同态加密指令分成模乘运算、模加运算、数论变换、逆数论变换、模交换、密钥交换、重新伸缩运算中的至少一个的组合,再将模乘运算、模加运算、数论变换、逆数论变换、模交换、密钥交换、重新伸缩运算按照上述规则分解交由一个或多个数论变换单元235和一个或多个算术逻辑单元236中的至少一个执行。调度器234内部存储着上述分解的规则。
105.无论何种同态加密算法,最后都能分解成数论变换和算术逻辑(模加、模乘及其组合)的不同组合。本公开实施例引入数论变换单元235执行数论变换,引入算术逻辑单元236执行算术逻辑,并通过调度器234的调度,若干数论变换单元235和若干算术逻辑单元236可以独立执行不同的任务,也可以组成流水线顺序执行同一任务的不同阶段。因此,本公开实施例可以高效地兼容不同种类的算法,提高了全局性、可扩展性和通用性。
106.除了上述存储待执行同态加密指令的指令缓冲器231之外,数论变换单元235和算术逻辑单元236内部还可以包含有本地缓冲器,用于存储数论变换单元235进行数论变换时需要的数据和产生的中间数据、算术逻辑单元236进行模加和模乘运算时需要的数据和产生的中间数据。当进行数论变换、模加和模乘时需要的数据和产生的中间数据在本地缓冲器存储不下时,其可以存储在数论变换单元235和算术逻辑单元236共享的共享缓冲器239中。共享缓冲器239通过内部互连240彼此通信,实现数据共享。由于本公开实施例的加速单元230内部具有大量本地缓冲器、共享缓冲器239等,避免频繁访问核外部的存储器210,大大提高同态加密的处理效率,提高计算性能。
107.数论变换单元的内部结构
108.数论变换可以看成对多项式环的多项式系数按照同一规则进行反复处理的过程,
例如将多项式环某两个固定位置的多项式系数取出,用旋转因子处理,得到一对新的多项式系数放回多项式环的另两个固定位置,如将多项式环的第1个多项式系数和第5个多项式系数取出,用旋转因子处理后,放回多项式环的第1和多项式系数位置和第2个多项式系数位置。当所有多项式系数都按上述方式处理好后,产生新多项式环。再重复上述过程,即将新多项式环的第1个多项式系数和第5个多项式系数取出,用旋转因子处理后,放回多项式环的第1个多项式系数位置和第2个多项式系数位置。为了反复执行这一操作,创建了蝴蝶处理。如图4所示,在数论变换单元2354中设置第一多项式系数存储子单元2351和第二多项式系数存储子单元2352。第一多项式系数存储子单元2351存储着最初的多项式环中的各多项式系数。从其预定位置取出多项式系数后,用旋转因子处理,放入第二多项式系数存储子单元2352的另外的预定位置。这样,得到新的各多项式系数。反过来,再从该第二多项式系数存储子单元2352的预定位置取出多项式系数后,用旋转因子处理,放入第一多项式系数存储子单元2351的另外的预定位置。这样,反复倒换处理,直到满足预定要求,此时第一多项式系数存储子单元2351或第二多项式系数存储子单元2352存储的新的各多项式系数就是数论变换的结果。每一次取多项式系数、处理、并将结果写入不同多项式系数位置的操作,叫做一次蝴蝶处理,它由蝴蝶处理子单元2354。数论变换单元235还包括旋转因子存储子单元2353,用于存储上述蝴蝶处理中用到的旋转因子,其事先设置并存储在旋转因子存储子单元2353中。数论变换单元235还可以包括控制单元2355,用于控制所述第一多项式系数存储子单元2351、所述第二多项式系数存储子单元2352、所述旋转因子存储子单元2353和所述蝴蝶处理子单元2354的运行。
109.上述蝴蝶处理可以分为第一蝴蝶处理和第二蝴蝶处理。
110.第一蝴蝶处理包括:从所述第一多项式系数存储子单元2351读取第一多项式系数对,从所述旋转因子存储子单元2353中获取该第一多项式系数对所对应的旋转因子,基于该第一多项式系数对和所述旋转因子得到第二多项式系数对,写入所述第二多项式系数存储子单元2352。上面例子中,将第一多项式系数存储子单元2351中的第1个多项式系数和第5个多项式系数取出,作为第一多项式系数对,用旋转因子处理后,成为第二多项式系数对,放回第二多项式系数存储子单元2352的第1个多项式系数位置和第2个多项式系数位置,就属于第一蝴蝶处理。
111.第二蝴蝶处理包括:从所述第二多项式系数存储子单元2352读取第三多项式系数对,从所述旋转因子存储子单元2353中获取该第三多项式系数对所对应的旋转因子,基于该第三多项式系数对和所述旋转因子得到第四多项式系数对,写入所述第一多项式系数存储子单元2351。上面例子中,将第二多项式系数存储子单元2352中的第1个多项式系数和第5个多项式系数取出,作为第三多项式系数对,用旋转因子处理后,成为第四多项式系数对,放回第一多项式系数存储子单元2351的第1个多项式系数位置和第2个多项式系数位置,就属于第二蝴蝶处理。
112.第一多项式系数存储子单元2351和第二多项式系数存储子单元2352各包括多个存储体23511,每个存储体23511按顺序容纳一个存储队列。如图8所示的例子中,第一多项式系数存储子单元2351或第二多项式系数存储子单元2352各包括8个存储体23511,索引分别为b1-8。每个存储体存放8个多项式系数的队列。即,当密文表示为64个多项式系数的多项式时,64个多项式系数就可以分布在8个存储体中,每个存储体中存放8个多项式系数。多
项式系数c0-7放置在存储体b1中;多项式系数c8-15放置在存储体b2中;多项式系数c16-23放置在存储体b3中
……
多项式系数c56-63放置在存储体b8中。一般来说,多项式环中的多项式系数的个数和存储体的个数可以设置成2的正整数次幂。假设第一多项式系数存储子单元2351或所述第二多项式系数存储子单元2352中的存储体各有m个,如上例中的8个,其等于2的3次幂。这样做有利于多次蝴蝶处理后,多项式系数在各存储体中排布的顺序能够回到最初,从而结束蝴蝶处理。在取第一多项式系数对与第三多项式系数对时,尽量让系数对中的两个系数取自的存储体隔开较远且能保持相等隔开距离,例如将m个存储体分成前m/2个存储体和后m/2个存储体,从前m/2个存储体的第一个存储体和后m/2个存储体的第一个存储体中取多项式系数形成一个第一多项式系数对,再从前m/2个存储体的第二个存储体和后m/2个存储体的第二个存储体中取多项式系数形成一个第一多项式系数对,以此类推
……
这样,取出的多项式系数对中的两个多项式系数取自的存储体索引总保持相差m/2。而所述第一多项式系数对来自的一对存储体的索引可以与所述第三多项式系数对来自的一对存储体的索引相同。例如,在取第一多项式系数对时,从第一和第五个存储体中取多项式系数;在取相应的第三多项式系数对时,也从第一和第五个存储体中取多项式系数。另外,所述第二多项式系数对来自的一对存储体的索引与所述第四多项式系数对来自的一对存储体的索引相同,且该对存储体中的两个存储体的索引相邻。例如,形成第二多项式系数对后,将其放入第一个和第二个存储体;形成相应的第四多项式系数对后,也将其放入第一个和第二个存储体。第一蝴蝶处理后进行第二蝴蝶处理,再进行第一蝴蝶处理
……
以此类推,直到蝴蝶处理取的多项式系数排布在的存储体又恢复到其最初所在的存储体。
113.以图8为例,第一多项式系数存储子单元2351中8个存储体的最初排序是b1-8。即,m=8。有4个蝴蝶处理子单元2354。第一蝴蝶处理子单元2354将第一多项式系数存储子单元2351中的存储体b1中的多项式系数和存储体b5中的多项式系数取出,作为第一多项式系数对,用旋转因子处理后,得到第二多项式系数对,放回第二多项式系数存储子单元2352的存储体b1和b2中。这时,第二多项式系数存储子单元2352的存储体b1和b2中放置的多项式系数来源于第一多项式系数存储子单元2351中的存储体b1和b5。同理,第二蝴蝶处理子单元2354将第一多项式系数存储子单元2351中的存储体b2中的多项式系数和存储体b6中的多项式系数取出,作为第一多项式系数对,用旋转因子处理后,得到第二多项式系数对,放回第二多项式系数存储子单元2352的存储体b3和b4。这时,第二多项式系数存储子单元2352的存储体b3和b4中放置的多项式系数来源于第一多项式系数存储子单元2351中的存储体b2和b6。以此类推,经过第一蝴蝶处理后,第二多项式系数存储子单元2352的存储体b5和b6中放置的多项式系数来源于第一多项式系数存储子单元2351中的存储体b3和b7,第二多项式系数存储子单元2352的存储体b7和b8中放置的多项式系数来源于第一多项式系数存储子单元2351中的存储体b4和b8。因此,经过第一蝴蝶处理后,第二多项式系数存储子单元2352的存储体b1-b8存储的内容实质上分别相当于原第一多项式系数存储子单元2351的存储体b1、b5、b2、b6、b3、b7、b4、b8。
114.在第二蝴蝶处理中,第一蝴蝶处理子单元2354将第二多项式系数存储子单元2352中的第一和第五个存储体存储的多项式系数取出,实际上是将原存储体b1和b3中的多项式系数取出,作为第三多项式系数对,用旋转因子处理后,得到第四多项式系数对,放回第一多项式系数存储子单元2351的第一和第二个存储体中。这时,第一多项式系数存储子单元
2351的存储体b1和b2中放置的多项式系数实质上是原存储体b1和b3的内容。同理,经第二至四蝴蝶处理子单元2354处理后,第一多项式系数存储子单元2351的存储体b3和b4中放置的多项式系数实质上是原存储体b5和b7的内容;第一多项式系数存储子单元2351的存储体b5和b6中放置的多项式系数实质上是原存储体b2和b4的内容;第一多项式系数存储子单元2351的存储体b7和b8中放置的多项式系数实质上是原存储体b6和b8的内容。经过第二蝴蝶处理后,第一多项式系数存储子单元2351的存储体b1-b8存储的内容实质上分别相当于原存储体b1、b3、b5、b7、b2、b4、b6、b8。
115.然后,再经过一轮第一蝴蝶处理,第二多项式系数存储子单元2352的存储体b1-b8存储的内容实质上分别相当于原第一多项式系数存储子单元2351的存储体b1、b2、b3、b4、b5、b6、b7、b8,即与原存储体的顺序一致。此时,按照一般的蝴蝶处理原则,经过上述log2m次的蝴蝶处理,就可以停止处理,这些存储体中存储的多项式系数就成为数论变换的处理结果。
116.可以看出,上述过程中,对于单个蝴蝶处理子单元2354(第一、第二、第三或第四蝴蝶处理子单元2354),其在第一蝴蝶处理中从第一多项式系数存储子单元2351中取第一多项式系数对的存储体索引(如上述第一蝴蝶处理子单元的b1和b5、第二蝴蝶处理子单元的b2和b6、第三蝴蝶处理子单元的b3和b7、第四蝴蝶处理子单元的b4和b8)与在第二蝴蝶处理中从第二多项式系数存储子单元2352中取第三多项式系数对的存储体索引保持一致。这种一致读写的方式可以缓解布局布线的压力。另外,它们取自的存储体索引相差m/2(如1和5之间、2和6之间、3和7之间、4和8之间相差4)。单个蝴蝶处理子单元2354在第一蝴蝶处理中将生成的第二多项式系数对放入的第二多项式系数存储子单元2352中的存储体索引(如上述第一蝴蝶处理子单元的b1和b2、第二蝴蝶处理子单元的b3和b4、第三蝴蝶处理子单元的b5和b6、第四蝴蝶处理子单元的b7和b8)与在第二蝴蝶处理中将生成的第四多项式系数对放入的第一多项式系数存储子单元2351中的存储体索引保持一致,以缓解布局布线的压力。另外,它们放入的存储体索引相邻。只有这样,才能在若干次蝴蝶处理之后,各存储体存储的多项式系数源自的存储体的顺序回复到初始状态,如上例中的b1、b2、b3、b4、b5、b6、b7、b8,而且是经过log2m次蝴蝶处理后,回复到初始状态,从而达到一般意义上的数论变换终止条件。
117.上面提到的仅仅是一般意义上的数论变换终止条件,本公开实施例在达到一般意义上的数论变换终止条件后,控制单元2355将所述第一多项式系数存储子单元2351或所述第二多项式系数存储子单元2352转置,再由所述蝴蝶处理子单元2354进行log2m次的第一蝴蝶处理或第二蝴蝶处理,即在转置的基础上再次达到上述数论变换终止条件。
118.所述转置包括:将转置前所述第一多项式系数存储子单元2351或所述第二多项式系数存储子单元2352的各存储体中排队在同一序号的多项式系数取出,按照存储体索引顺序放置在转置后的一个存储体23511中。即,将各多项式系数在第一多项式系数存储子单元2351或所述第二多项式系数存储子单元2352中排成的阵列的行和列颠倒。原来排成的列(存储体23511)作为新阵列的行(每个存储体23511中相同序号的多项式系数),原来排成的行(每个存储体23511中相同序号的多项式系数)作为新阵列的列(存储体23511)。如图8所示,将原第一多项式系数存储子单元2351中存储体b1-8中排队在第一位的多项式系数c0、c8、c16、c24、c32、c40、c48、c56按照索引由小到大的顺序放置在转置后的存储体b1中;将原
第一多项式系数存储子单元2351中存储体b1-8中排队在第二位的多项式系数c1、c9、c17、c25、c33、c41、c49、c57按照索引由小到大的顺序放置在转置后的存储体b2中;将原第一多项式系数存储子单元2351中存储体b1-8中排队在第三位的多项式系数c2、c10、c18、c26、c34、c42、c50、c58按照索引由小到大的顺序放置在转置后的存储体b3中
……
将原第一多项式系数存储子单元2351中存储体b1-8中排队在最后一位的多项式系数c7、c15、c23、c31、c39、c47、c55、c63按照索引由小到大的顺序放置在转置后的存储体b8中。
119.进行完转置后,再由所述蝴蝶处理子单元2354进行log2m次的第一蝴蝶处理或第二蝴蝶处理。由于该过程与转置前的处理过程完全相同,为节约篇幅,故不赘述。
120.本公开实施例中转置的作用如下:如果未经转置,蝴蝶处理子单元2354永远针对两个不同存储体23511中的多项式系数235111进行蝴蝶处理。但是,在实践中,有时也需要对同一存储体23511中的不同多项式系数235111进行蝴蝶处理。因此,引入了转置。在转置前,蝴蝶处理针对的两个多项式系数来自于不同的存储体23511。在转置后,蝴蝶处理针对的两个多项式系数来自于原来的同一存储体23511的低位和高位。例如,存储体23511中有8个多项式系数235111排队,前四个多项式系数235111为低位,后四个多项式系数为高位。这样,多项式系数可以在同一存储体的高位和低位之间来回读写,丰富了蝴蝶处理的适用范围。
121.蝴蝶处理子单元的内部结构
122.如图5所示,根据本公开的一个实施例的蝴蝶处理子单元2354包括第一多路选通器23541、第二多路选通器23542、第三多路选通器23543、第四多路选通器23544、第一加法器23545、第二加法器23546、第一减法器23547、第二减法器23548、第一乘法器23549。图3中的每个多路选通器有第一输入端(0输入端)、第二输入端(1输入端)、控制端和输出端。控制端连接控制信号sel或sel的非。当sel置1时,第二输入端(1输入端)导通,其信号直接进入输出端。当sel置0时,第一输入端(0输入端)导通,其信号直接进入输出端。通过控制端连接的信号置0还是1,决定第一输入端和第二输入端中哪一路被输出。
123.如图5所示,所述第一多项式系数对或第三多项式系数对中的第一系数301输入到所述第一多路选通器23541的第一输入端(0输入端),并与所述第一多项式系数对或第三多项式系数对中的第二系数302经第一加法器23545相加后输入到所述第一多路选通器23541的第二输入端(1输入端),由所述第一多路选通器23541的第一选通信号(sel的非)选通所述第一输入端和第二输入端中的一路到输出端。所述第二系数302输入到第三多路选通器23543的第二输入端(1输入端),并与第一系数301经第一减法器23547相减后输入到所述第三多路选通器23543的第一输入端(0输入端),由第三多路选通器23543的第三选通信号(sel的11非)选通所述第一输入端和第二输入端中的一路到输出端,经第一乘法器23549与相应旋转因子相乘,得到积信号。
124.第一多路选通器23541的输出端输出的信号输入到所述第二多路选通器23546的第一输入端(0输入端),并与所述积信号经第二加法器23546相加后输入到所述第二多路选通器23542的第二输入端(1输入端),由所述第二多路选通器23542的第二选通信号(sel)选通所述第一输入端和第二输入端中的一路到输出端,作为第二多项式系数对或第四多项式系数对中的一个系数303。所述积信号输入到所述第四多路选通器23544的第二输入端(1输入端),并与所述第一多路选通器输出的信号经第二减法器23548相减后输入到所述第四多
路选通器23544的第一输入端(0输入端),由所述第四多路选通器23544的第四选通信号(sel)选通所述第一输入端和第二输入端中的一路到输出端,作为第二多项式系数对或第四多项式系数对中的另一个系数304。
125.在上述结构中,如果sel=1,sel的非等于0,第一多路选通器23541和第三多路选通器23543的第一输入端(0输入端)导通,第一多路选通器23541输出的信号为第一系数301,第三多路选通器23543输出的信号为(第二系数302-第一系数301),经第一乘法器23549后,得到积信号=(第二系数302-第一系数301)
×
旋转因子。由于sel=1,第二多路选通器23542和第四多路选通器23544的第二输入端(1输入端)导通,第二多路选通器23542输出的信号为第一系数301+积信号=第一系数301+(第二系数302-第一系数301)
×
旋转因子=第一系数301
×
(1-旋转因子)+第二系数302
×
旋转因子,第四多路选通器23544输出的信号为积信号=(第二系数302-第一系数301)
×
旋转因子。该输出303和304的上述公式恰好与数论变换的要求一致,即当sel=1时,可以利用上述结构进行数论变换。
126.在上述结构中,如果sel=0,sel的非等于1,第一多路选通器23541和第三多路选通器23543的第二输入端(1输入端)导通,第一多路选通器23541输出的信号为(第一系数301+第二系数302),第三多路选通器23543输出的信号为第二系数302,经第一乘法器23549后,得到积信号=第二系数302
×
旋转因子。由于sel的非为0,第二多路选通器23542和第四多路选通器23544的第一输入端(0输入端)导通,第二多路选通器23542输出的信号为(第一系数301+第二系数302),第四多路选通器23544输出的信号为积信号-(第一系数301+第二系数302)=第二系数302
×
(旋转因子-1)-第一系数301。该输出303和304的上述公式恰好与逆数论变换的要求一致,即当sel=0时,可以利用上述结构进行逆数论变换。
127.通过上述实施例,利用简单的结构,实现了数论变换和逆数论变换,提高了数论变换和逆数论变换的实现效率。
128.上述蝴蝶处理子单元2354的结构只是例示,还可以有其它结构能够实现如上所述的数论变换和逆数论变换。
129.算术逻辑单元的内部结构
130.如图6所示,根据本公开一个矢量的算术逻辑单元236包括模加器2363、模乘器2364、第五多路选通器2361、第六多路选通器2362、第七多路选通器2365。以上每个多路选通器具有第一输入端(0输入端)、第二输入端(1输入端)、控制端和输出端。控制端连接控制信号a、b或c。当控制信号a、b或c置1时,相应第二输入端(1输入端)导通,其信号直接进入输出端。当控制信号a、b或c置0时,第一输入端(0输入端)导通,其信号直接进入输出端。通过控制端连接的信号置0还是1,决定第一输入端和第二输入端中哪一路被输出。
131.如图6所示,第一输入信号305输入到第五多路选通器2361和第六多路选通器2362的第一输入端(0输入端)。模加器263的输出输入到第六多路选通器2362的第二输入端(1输入端)。模乘器2364的输出输入到第五多路选通器2361的第二输入端(1输入端)。由第五多路选通器2361的第五选通信号a选通所述第五多路选通器2361的第一输入端(0输入端)和第二输入端(1输入端)中的一路到输出端,由第六多路选通器2362的第六选通信号b选通所述第六多路选通器2362的第一输入端(0输入端)和第二输入端(1输入端)中的一路到输出端。第五多路选通器2361的输出端连接所述模加器2363的第一输入端,所述模加器2363的第二输入端输入第二输入信号306。模加器2363将第一输入端的输入信号和第二输入端的
输入信号进行模加,得到的结果从其输出端输出。所述第六多路选通器2362的输出端连接所述模乘器2364的第一输入端,所述2364模乘器的第二输入端输入第三输入信号307。模加器2363的输出端连接到第七多路选通器2365的第一输入端(0输入端),模乘器2364的输出端连接到第七多路选通器2365的第二输入端(1输入端),由第七多路选通器2365的第七选通信号c选通所述第七多路选通器2365的第一输入端(0输入端)和第二输入端(1输入端)中的一路到输出端308。
132.通过上述电路结构,将上述第五、第六、第七多路选通器2361、2362、2365的第五、第六、第七选通信号a、b、c进行不同的置位,图6的算术逻辑单元236就能实现模加、模乘及其不同组合的运算。
133.如图6所示,当将所述第五选通信号a置位成0,即选通其第一输入端(0输入端),将所述第七选通信号c置位成0,即选通其第一输入端(0输入端)时,第七多路选通器2365的输出308等于其第一输入端(0输入端)的输入,该输入是模加器2363模加的结果。模加器2363的两个输入分别是第五多路选通器2361的输出和第二输入306。第五多路选通器2361的输出就等于第五多路选通器2361的第一输入端的第一输入305,因为其第五选通信号a置位成0。这样,模加器2363的输出等于第一输入305+第二输入306,从而算术逻辑单元236的输出也等于第一输入305+第二输入306。这样,通过将所述第五选通信号a置位成0,将所述第七选通信号c置位成0,算术逻辑单元236完成模加的功能,如图7所示。
134.如图6所示,当将所述第六选通信号b置位成选通第一输入端(0输入端),将所述第七选通信号c置位成选通第二输入端(1输入端)时,第七多路选通器2365的输出308等于其第二输入端(1输入端)的输入。该输入是模乘器2364模乘的结果。模加器2364的两个输入分别是第六多路选通器2362的输出和第三输入307。第六多路选通器2362的输出就等于第六多路选通器2362的第一输入端(0输入端)的第一输入305,因为其第六选通信号b置位成0。这样,模乘器2364的输出等于第一输入305
×
第三输入307,从而算术逻辑单元236的输出也等于第一输入305
×
第三输入307。这样,通过将所述第六选通信号b置位成0,将所述第七选通信号c置位成1,算术逻辑单元236完成模乘的功能,如图7所示。
135.如图6所示,当将所述第五选通信号a置位成选通第二输入端(1输入端),第六选通信号b置位成选通第一输入端(0输入端),第七选通信号c置位成选通第一输入端(0输入端)时,第七多路选通器2365的输出308等于其第一输入端(0输入端)的输入。该输入是模加器2363模加的结果。模加器2363的两个输入分别是第五多路选通器2361的输出和第二输入306。因此,算术逻辑单元236的输出308=第五多路选通器2361的输出+第二输入306。由于将所述第五选通信号a置位成选通第二输入端(1输入端),第五多路选通器2361的输出等于其第二输入端(1输入端)的输入,该输入是模乘器2364的输出。模乘器2364的输出等于第六多路选通器2362的输出
×
第三输入307。由于将所述第六选通信号b置位成选通第一输入端(0输入端),第六多路选通器2362的输出等于其第一输入端(0输入端)的输入,即第一输入305,因此,第五多路选通器2361的输出等于第一输入305
×
第三输入307。这样,输出308=第一输入305
×
第三输入307+第二输入306。算术逻辑单元236完成先模乘后模加的功能,如图7所示。
136.如图6所示,当将所述第五选通信号a置位成选通第一输入端(0输入端),第六选通信号b置位成选通第二输入端(1输入端),第七选通信号c置位成选通第二输入端(1输入端)
时,第七多路选通器2365的输出308等于其第二输入端(1输入端)的输入。该输入是模乘器2364模乘的结果。模乘器2364的两个输入分别是第六多路选通器2362的输出和第三输入307。因此,算术逻辑单元236的输出308=第六多路选通器2362的输出
×
第三输入307。由于将所述第六选通信号b置位成选通第二输入端(1输入端),第六多路选通器2362的输出等于其第二输入端(1输入端)的输入,该输入是模加器2363的输出。模加器2363的输出等于第五多路选通器2361的输出+第二输入306。由于将所述第五选通信号a置位成选通第一输入端(0输入端),第五多路选通器2361的输出等于其第一输入端(0输入端)的输入,即第一输入305,因此,第六多路选通器2362的输出等于第一输入305+第二输入306。这样,输出308=(第一输入305+第二输入306)
×
第三输入307。算术逻辑单元236完成先模加后模乘的功能,如图7所示。
137.如图6所示,当将所述第五选通信号a置位成选通第二输入端(1输入端),第六选通信号b置位成选通第二输入端(1输入端),第七选通信号c置位成选通第一输入端(0输入端)时,电路无法完成任何运算,即无效,如图7所示。同理,当将所述第五选通信号a置位成选通第二输入端(1输入端),第六选通信号b置位成选通第二输入端(1输入端),第七选通信号c置位成选通第二输入端(1输入端)时,电路也无法完成任何运算,即无效,如图7所示。
138.通过上述简单的电路、以及选通信号a、b、c的不同置位组合,使算术逻辑单元236能够实现模加和模乘运算的不同组合,达到同一电路完成多种算术逻辑运算的作用,提高了电路的功效。
139.根据本公开实施例的深度神经网络运行方法流程
140.如图9所示,根据本公开的一个实施例,提供了一种同态加密方法,包括:
141.步骤410、接收待执行同态加密指令;
142.步骤420、将所述待执行同态加密指令分解成运算;
143.步骤430、将所述运算所包含的数论变换分配到一个或多个数论变换单元中的至少一个执行,将所述运算所包含的算术运算分配到一个或多个算术逻辑单元中的至少一个执行。
144.由于上述过程的实现细节已在前述装置实施例的描述中详细介绍,故不赘述。
145.本公开实施例的商业价值
146.经试验验证,本公开实施例提出了一个通用的、模块化的、可扩展的同态加密加速器架构,使得同态加密算法的部署成本以及之后改换算法引起的重新部署的成本大大降低,可以降低到原来的50%-80%,具有很好的市场前景。
147.应该理解,本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同或相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于方法实施例而言,由于其基本相似于装置和系统实施例中描述的方法,所以描述的比较简单,相关之处参见其他实施例的部分说明即可。
148.应该理解,上述对本说明书特定实施例进行了描述。其它实施例在权利要求书的范围内。在一些情况下,在权利要求书中记载的动作或步骤可以按照不同于实施例中的顺序来执行并且仍然可以实现期望的结果。另外,在附图中描绘的过程不一定要求示出的特定顺序或者连续顺序才能实现期望的结果。在某些实施方式中,多任务处理和并行处理也是可以的或者可能是有利的。
149.应该理解,本文用单数形式描述或者在附图中仅显示一个的元件并不代表将该元件的数量限于一个。此外,本文中被描述或示出为分开的模块或元件可被组合为单个模块或元件,且本文中被描述或示出为单个的模块或元件可被拆分为多个模块或元件。
150.还应理解,本文采用的术语和表述方式只是用于描述,本说明书的一个或多个实施例并不应局限于这些术语和表述。使用这些术语和表述并不意味着排除任何示意和描述(或其中部分)的等效特征,应认识到可能存在的各种修改也应包含在权利要求范围内。其他修改、变化和替换也可能存在。相应的,权利要求应视为覆盖所有这些等效物。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1