人工智能分布式训练平台的搭建方法及平台与流程
本发明涉及人工智能、云平台技术领域,特别是人工智能分布式训练平台的搭建方法及平台。
背景技术:
当前ai人工智能越来越普及,基于人工智能的算法训练也越来越受到关注。所谓人工只能训练,是数据科学家通过将数据集输入到一个算法代码中,经过算法的训练,生成一个模型。这个模型可以用来作为人工智能识别的支撑。比如拿一张照片,输入到算法中,算法结合模型,能够分辨出这张图片是猫还是狗。
人工智能的训练过程是极其耗费计算资源的,而且显卡又非常昂贵。集合有多显卡的设备价格更不是一般小企业所能承受的。
技术实现要素:
本发明的目的在于提出人工智能分布式训练平台的搭建方法及平台,通过此方法,可以集合公司装有显卡的计算机设备,搭建一套训练平台,将所有的显卡作为一个集群服务。
为解决上述的技术问题,本发明采用以下技术方案:
一种人工智能分布式训练平台的搭建方法,包括如下步骤:
1)总控管理模块其实现方式包括如下步骤:
步骤1.1:安装docker;
步骤1.2:下载并安装kubeadm;
步骤1.2.1:添加镜像源;步骤1.2.2安装kubeadm、kubelet、kubectl;
步骤1.3:初始化kubemetes环境;
步骤1.4:安装gpu设备管控插件;
2)计算机设备模块其实现方式包括如下步骤:
步骤2.1:搭建基础环境:同上述步骤1中的1.1、1.2,安装docker和kubeadm;
步骤2.2:在总控管理模块上,获取加入总控的指令:
步骤2.3:将计算机设备作为资源加入总控管理模块中;
3)镜像构建模块其实现方式包括如下步骤:
步骤3.1:编写dockerfile文件;
步骤3.2:构建镜像;
步骤3.3:编写yaml文件,作为部署文件;
步骤3.4:开始训练。
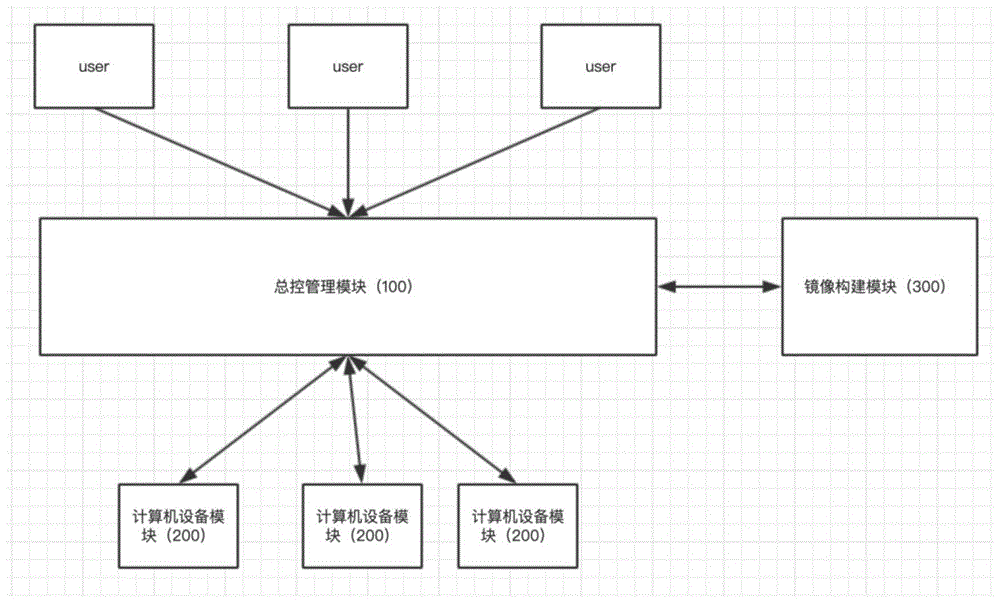
本发明还公开一种人工智能分布式训练平台,包括总控管理模块、计算机设备模块和镜像构建模块。
进一步,总控管理模块管理各个计算机的gpu资源,开发人员在此模块创建训练任务,创建的训练任务分发到各台独立的计算机设备上。
进一步,计算机设备模块是部署在各个计算机设备上,管控计算机的gpu资源,并上报给总控管理模块。
进一步,镜像构建模块为镜像构建模块,将开发人员提交的算法代码,集合运行环境,构建成一个docker镜像,总控管理模块获取构建出来的镜像,将镜像部署到计算机设备模块上进行训练。
与现有技术相比,本发明至少具有以下有益效果之一:
1.充分利用公司的pc作为计算资源,降低企业成本,提高训练速度。
2.屏蔽开发人员对gpu资源的感知。
3.做到gpu资源的隔离,每个开发人员只能看到自己使用的gpu资源,不会出现资源抢占冲突。
附图说明
图1为本发明模块系统图。
图中,100-总控管理模块;200-计算机设备模块;300-镜像构建模块。
具体实施方式
如图1示,为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
实施例
一种人工智能分布式训练平台的搭建方法,包括如下步骤:
1)总控管理模块(100)其实现方式包括如下步骤:
步骤1.1:安装docker;
步骤1.2:下载并安装kubeadm;
步骤1.2.1:添加镜像源;步骤1.2.2安装kubeadm、kubelet、kubectl;
步骤1.3:初始化kubernetes环境;
步骤1.4:安装gpu设备管控插件;
2)计算机设备模块(200)其实现方式包括如下步骤:
步骤2.1:搭建基础环境:同上述步骤1中的1.1、1.2,安装docker和kubeadm;
步骤2.2:在总控管理模块(100)上,获取加入总控的指令:
步骤2.3:将计算机设备(200)作为资源加入总控管理模块(100)中;
3)镜像构建模块(300)其实现方式包括如下步骤:
步骤3.1:编写dockerfile文件;
步骤3.2:构建镜像;
步骤3.3:编写yaml文件,作为部署文件;
步骤3.4:开始训练。
更为具体的实施过程如下:
一种人工智能分布式训练平台的搭建方法,包括如下步骤:
1)总控管理模块100其实现方式包括如下步骤:
步骤1.1:安装docker,apt-getinstalldocker.io;
步骤1.2:下载并安装kubeadm;
步骤1.2.1:添加镜像源,curl-shttps://packages.cloud.google.com/apt/doc/apt-key.gpg|apt-keyadd-
cat<<eof>/etc/apt/sources.1ist.d/kubernetes.list
debhttp://mirrors.ustc.edu.cn/kubernetes/aptkubemetes-xenialmain
eof;
步骤1.2.2安装kubeadm、kubelet、kubectl,apt-getinstallkubeadm=1.14.3-00kubelet=1.14.3-00kubectl=1.14.3-00--allow-unauthenticated;
步骤1.3:初始化kubernetes环境,kubeadminit--pod-network-cidr=10.244.0.0/16--image-repositoryregistry.cn-hangzhou.aliyuncs.com/google_containers;
步骤1.4:安装gpu设备管控插件,
kubectlcreate-fhttps://raw.githubusercontent.com/nvidia/k8s-device-plugin/1.0.0-beta4/nvidia-device-plugin.yml:
2)计算机设备模块200其实现方式包括如下步骤:
步骤2.1:搭建基础环境:同上述步骤1中的1.1、1.2,安装docker和kubeadm;
步骤2.2:在总控管理模块100上,获取加入总控的指令,
root@ubuntu:~#kubeadmtokencreate--print-join-command
kubeadmjoin192.168.5.31:6443-tokennvvob8.ikonwk1jh99nmx4b
--discovery-token
rt-hash
sha256:7be69827ca9c687bc8438015663ad822302dc01d137beac8950a1612c9b25
cc3
root@ubuntu:~#;
步骤2.3:将计算机设备200作为资源加入总控管理模块100中,
kubeadmjoin192.168.3.14:6443--tokenlwo4ez.dcah2dv49swggwrx\
--discovery-token-ca-cert-hash;
3)镜像构建模块300其实现方式包括如下步骤:
步骤3.1:编写dockerfile文件,如下为示例文件:
frommxnet/python:gpu
workdir/app
copy./app
runexportpythonunbuffere=θ
cmd【“python”,“test.py”】;
步骤3.2:构建镜像($name、$version为可变参数,根据实际情况填写),
dockerbuild-t$name:$version.
将构建一个以$name为名称,$version为版本号的镜像文件;
步骤3.3:编写yaml文件,作为部署文件,示例如下,设定要使用的gpu个数
步骤3.4:开始训练,执行如下命令
kubectlcreate-f${filename}。
如图1所示,本发明还公开一种人工智能分布式训练平台,包括总控管理模块100、计算机设备模块200和镜像构建模块300;总控管理模块100为总控模块,管理各个计算机的gpu资源,开发人员在此模块创建训练任务,创建的训练任务分发到各台独立的计算机设备上;计算机设备模块200是部署在各个计算机设备上,管控计算机的gpu资源,并上报给总控管理模块100;镜像构建模块300为镜像构建模块,将开发人员提交的算法代码,集合运行环境,构建成一个docker镜像,总控管理模块100获取构建出来的镜像,将镜像部署到计算机设备模块200上进行训练,充分利用公司的pc作为计算资源,降低企业成本,提高训练速度。
以上所述,仅为本申请的具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本申请的保护范围之内,凡是落入本发明权利要求界定范围内的技术方案,均落在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!