一种结合注意力机制的PR-LSTM算法的空中交通延误预测方法
本发明属于智能交通技术领域,具体涉及一种结合注意力机制的pr-lstm算法的空中交通延误预测方法。
背景技术:
近年来,随着经济的发展以及技术水平的进一步提高,人们的出行方式发生了重大的改变,飞机出行逐渐成为普通群众出行的选择。仅2018年,全行业运输民航交通公司完成运输飞行小时1153.52万小时,比上年增长8.9%;完成旅客运输量61173.77万人次,同比增长10.9%。
日益增涨的出行需求给航空公司带来了巨大的压力。在现有的机场资源情况下,为满足乘客的需求,航空公司只能通过不断增加航班数量来满足乘客的需求。航班数量的增加给机场的航空排班带来了巨大的挑战。与此同时,由于航班与航班之间的间隔更短,给机场工作人员带来了更大的工作压力。当发生飞机延误时,其连锁反应不但会导致之后的航班均出现延误现场,而且会影响其他机场航班的正常运行,这给民航公司和乘客都带来了巨大的不便。因此,建立一套针对空中交通的延误预测系统迫在眉睫,同时,这也是进一步完善空中交通体系的重要一环。
目前,有许多学者研究空中交通的延误预测,目前的延误预测可分为机理模型和数据模型两大类。机理模型通过统计学、动力学方程对机场的延误预进行建模,其方法包括马尔可夫模型,贝叶斯网络以及卡尔曼滤波等,这些模型虽然有较强的可解释性,但是由于机场延误的高度复杂性以及非线性性,这些模型并不能准确刻画机场延误的传播过程。此外,这些模型只能够刻画单个机场的延误过程,却不能够对整个网络进行整体的延误预测,由各机场行程的图网络中,节点与节点之间的联系未被考虑。
随着大数据的进一步发展,通过数据驱动建模的方式在各个领域得到了广泛的应用。在智能交通系统(its)中,大数据更是得到了广泛的应用,如申请号为cn201910614671.x的中国专利提出了一种的中国发明专利申请提出一种机器学习的智能交通状态预测方法,该预测方法将时间和空间同时应用在模型中,并增加了一系列的辅助特征,如气象属性,道路属性以提高道路系统预测的准确度。
申请号为cn201810091588.4的中国专利提出了一种基于数据驱动的高架桥交通拥堵预测方法,通过获取路段的车流速度、密度等交通数据,利用交通流量、速度、密度三个指标数据构造被控路段的宏观交通流图,标定拥堵速度阈值,根据不同的拥堵工况进行分类,并建立利用分类器进行拥堵预测的模型。
在空中交通领域,申请号为cn202010819415.7的中国专利提出了一种航班延误预测方法、装置、服务器及存储介质,通过接收航班延误请求获取与航班延误预测相关的至少一个因素中每个因素的航班数据并进行预处理,对之后的航班同样提取相同的数据并判断与延误航班数据的相关性大小来判定航班是否延误。
然而,发明人发现,属于驱动的交通流预测方法更多停留在地面交通,空中交通流由于其更复杂的网络结构和动态性,难以整体把握。目前虽有研究单个航班延误预测的方法,但是考虑整个机场网络的数据驱动航班延误预测方法的研究仍然有待完善。
技术实现要素:
由于目标空中交通延误预测存在诸多不足之处,本发明提出了一种结合注意力机制的pr-lstm(pagerank-lstm)算法的空中交通延误预测方法,同时可面向乘客和机场工作人员,提供航班延误信息。
为实现上述目的,本发明所采用的实现方案如下:
一种结合注意力机制的pr-lstm算法的空中交通延误预测方法,该方法包括以下步骤:
步骤1:对后台机场数据库中的数据进行清洗后,调取设定时段内所有机场与机场之间的航班延误时间,并计算平均值作为有向图的权重。
步骤2:基于有向图构造机场网络的机场延误信息图矩阵g=(v,e,w);有向图中的v代表机场节点集合v={v1,v2,...vn},其中,n代表机场节点的数量;有向图中的e代表机场节点和机场节点之间的边集合e;有向图中的w为节点对的权重值;每个时刻都生成一个有向图,有向图的数量为时间节点数t,权重值的定义为:
其中aj,i,t表示在t时间步长中,从机场vj到机场vi的平均时间;
对于阶时间步长,机场延误信息图矩阵
步骤3:将机场延误信息图矩阵作为输入值输入到pagerank算法模块中,得到延误时间权重矩阵pr(v)=[pr1(v),pr2(v),...,prt(v)]n×t,其中t时刻的延误时间权重向量为
步骤4:对机场数据库的数据进行清洗后调取用于训练的h*个历史步长的机场延误时间矩阵
步骤5:将步骤4得到的机场延误时间矩阵和步骤3得到的延误时间权重矩阵中对应的h*个列向量所组成的矩阵进行哈达玛积,得到的结果
步骤6:基于序列到序列的lstm模块的编码器接收步骤5的输出结果作为训练数据,对编码器进行训练后,得到全部的隐含层参数h所组成的向量h和最后一次的记忆状态c,并将这些数据传入到解码器中;
步骤7:解码器接收编码的输出数据,并接收待预测步数上一步的输出结果,将输出结果用解码器进行训练后,输出并保存隐含层参数ht+a和最后一次的记忆状态c;
步骤8:将步骤6得到的隐含层参数h所组成的向量h和步骤7得到的当前的预测值对应的隐含层参数ht+a输入到注意力机制模块中,得到加权后的隐含层参数ht+a并输出;
步骤9:提取专家系统内的专家知识并进行独热编码后输出;
步骤10:提取气象数据库服务器的天气数据并进行独热编码后输出;
步骤11:将步骤9和步骤10输出的数据进行数据降维并作为辅助特征数据输出;
步骤12:将步骤8得到的加权后的隐含层参数h’t+a和步骤11得到的降维后的辅助特征数据作为输入值输入到全连接网络中,得到所要预测的步数的延误时间矩阵;
步骤13:重复步骤7到步骤12的过程,预测之后全部p个步长的延误时间,并将其组成n×p的延误时间矩阵;
步骤14:将步骤13得到的延误时间矩阵输出至审核端进行审核,审核通过后将数据输出至展示发布模块进行展示。
进一步的,所述设定时段为1年或多年。
进一步的,所述pagerank算法模块的流程为:
1.1)在pagerank算法模块中输入机场的机场延误信息图矩阵g;
1.2)确定机场数量n和阻尼系数d;
1.3)给定pagerank算法的结果初始值向量
其中:m代表与第i个机场节点组成节点对的节点总数,参数sout(vj)t计算公式为:
其中vout(vj)表示从机场vj出发到达的所有机场vi所构成的集合:
1.4)根据
1.5)将所有n个经过1.4)迭代后输出的
进一步的,所述基于序列到序列的lstm模块包含编码器和解码器,其内部工作流程为:
在编码器中流程如下:
2.1)给定h*个历史步长的机场延误时间矩阵
2.2)取延误时间矩阵的第一列作为延误时间列向量x,并将其在矩阵中移除,将x输入编码器并训练编码器的lstm模型;
2.3)迭代2.2),不断输出隐含层参数向量h和记忆状态c至下一轮训练的lstm模型中并保存直到向量为空,将最后一层隐含层参数h和记忆状态c输出至解码器;
在解码器中流程如下:
3.1)输入待预测步数前一步输出的机场延误时间向量x,所述机场延误时间向量x来自于前一步预测最终得到的延误时间向量;
3.2)输入编码器传输的最后一层隐含层参数h和记忆状态c至解码器的lstm模型;
3.3)训练解码器的lstm模型并输出保存当前预测的向量的隐含层参数ht+a和记忆状态ct+a;
3.4)判断是否达到预测步长,若达到则停止,若没有达到则接收下一个机场延误时间向量xnext重复3.1)~3.3),直到达到预测步长后循环结束;且每次循环均输出生成的隐含层参数ht+a至注意力机制模块,并将隐含层ht+a和记忆状态ct+a作为输入值输入下一轮训练的lstm模型中。
进一步的,所述注意力机制模块的算法流程为:
4.1)接收编码器中保存的隐含层参数向量h;
4.2)输入当前的隐含参数ht+a;
4.3)取隐含层参数向量h的第一个隐含层参数h并在向量h中移除,计算ht+a和h的内积并保存;
4.4)不断迭代执行4.3),直到h向量为空;
4.5)对所得的所有内积进行softmax运算并得到权重;
4.6)根据4.5)计算得到的权重对未被移除的原向量h加权求和,得到所求向量对应的隐含层ht+a并输出。
进一步的,所述展示发布模块的工作流程为:
首先接收预测的延误时间矩阵,并将其展示至机场端,待机场工作人员审核数据确认后并将其发布至用户端。
进一步的,所述气象数据包含不同的天气类型。
进一步的,所述的专家知识包含机场与航班的特征信息。
本发明所提供的一种结合注意力机制的pr-lstm算法的空中交通延误预测系统,同时考虑了空中交通的时间相关性和空间相关性,采用pagerank算法计算空间相关性系数的大小,采用序列到序列的lstm模型实现了机场延误的多步预测,采用注意力机制确保了在多步预测中模型的预测精度。与现有的技术比,本发明具有如下优势:
1.以有向图的方式整体考虑机场的航班延误,考虑到了机场自身的航班延误对其他机场的影响,采用有向图的方式进行研究使得机场与机场之间的相互影响能够被考虑在内,网络的时间因素和空间因素在本模型中被充分考虑。该模型与仅从单个机场考虑的模型相比更具有说服力也更具有推广价值。
2.采用深度学习的方式充分挖掘历史的航班延误数据,学习历史时间序列中蕴含着的规律。使得航班延误数据这类高度非线性高复杂度的信息能够被充分学习以及利用。
3.采用序列到序列的深度学习模型实现了机场航班延误的多步预测,结合注意力机制保障了在多步预测过程中,过去的重要信息不会被丢失,模型的预测效果更加准确。
4.该交通延误系统通过借助专家系统充分考虑机场自身的特征信息,并借助后台的天气数据充分考虑外部因素信息,采用独热编码并降维的方式将这些数据信息以低维度的向量形式加入机场延误预测模型之中,使得预测模型拥有更高的预测精度。
附图说明
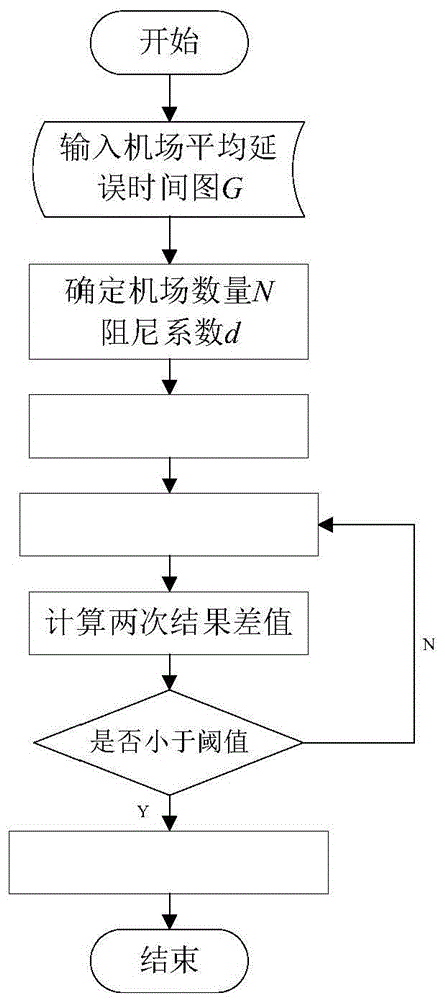
图1为空中交通延误预测系统的pagerank算法模块的工作流程图。
图2为不同输入长度验证集绝对误差变化曲线
图3为空中交通延误预测方法的基于序列到序列的lstm模块工作流程图。
图4为空中交通延误预测系统的注意力机制模块的整体工作流程图。
图5为注意力机制权重热力图
图6为不同模型在不同预测时间下的绝对误差图
图7为空中交通延误预测系统的整体工作流程图。
具体实施方式
下面结合附图和具体实施方式对本发明做具体阐述和说明:
本发明给出了一种结合注意力机制的pr-lstm算法的空中交通延误预测方法,下面结合具体实施例对本发明进一步描述,但本发明的保护范围不仅限于此。
在本发明的一个较佳实施例中,提供了一种结合注意力机制的pr-lstm算法的空中交通延误预测方法,该方法中包含四个模块,分别为pagerank算法模块,基于序列到序列的lstm模块,注意力机制模块和延误预测结果展示发布模块。各个模块耦合在整个空中交通延误预测系统之中,在系统延误预测时发挥作用。
该方法具体包括以下步骤:
步骤1:对后台机场数据库中的数据进行清洗后,调取设定时段内所有机场与机场之间的航班延误时间,并计算平均值作为有向图的权重。具体的设定时段可根据需要调整,可采用1年或多年的数据。
步骤2:基于有向图构造机场网络的机场延误信息图矩阵g=(v,e,w);有向图中的v代表机场节点集合v={v1,v2,...vn},其中,n代表机场节点的数量,vi表示第i个机场节点;有向图中的e代表机场节点和机场节点之间的边集合e={(vi,vj)|e1,e2,...,em},其中,m代表节点对的数量,em表示第m条边,两个机场节点之间存在边代表两者之间具有航班;有向图中的w为节点对的权重值;每个时刻都生成一个有向图,有向图的数量为时间节点数t,权重值的定义为:
其中aj,i,t表示在t时间步长中,从机场vj到机场vi的平均时间;at代表了所有节点对(vi,vj)的权重值,每一对节点对都由两个不同机场节点组成,因此at的维度为n×n。
对于阶时间步长,机场延误信息图矩阵
步骤3:将机场延误信息图矩阵作为输入值输入到pagerank算法模块中,得到延误时间权重矩阵pr(v)=[pr1(v),pr2(v),...,prt(v)],其中t时刻的延误时间权重向量为
在本实施例中,pagerank算法模块的流程为:
1.1)在pagerank算法模块中输入机场的机场延误信息图矩阵g;
1.2)确定机场数量n和阻尼系数d;
1.3)给定pagerank算法的结果初始值向量
其中:m代表与第i个机场节点组成节点对的节点总数,参数sout(vj)t计算公式为:
其中vout(vj)表示从机场vj出发到达的所有机场vi所构成的集合:
1.4)根据
1.5)将所有n个经过1.4)迭代后输出的
步骤4:对机场数据库的数据进行清洗后调取用于训练的h*个历史步长的机场延误时间矩阵
步骤5:将步骤4得到的机场延误时间矩阵和步骤3得到的延误时间权重矩阵中对应步骤4的h*个列向量所组成的矩阵进行哈达玛积,得到的结果
步骤6:基于序列到序列的lstm模块的编码器接收步骤5的输出结果作为训练数据,对编码器进行训练后,得到全部的隐含层参数h所组成的向量h和最后一次的记忆状态c,并将这些数据传入到解码器中。需注意的是,本发明中非粗体的h和粗体的h所代表的含义不同,非粗体的h表示隐含层参数h,而表示粗体的h表示由参数h组成的向量。
步骤7:解码器接收编码的输出数据,并接收待预测步数上一步的输出结果(此处的上一步具体指代为:若是预测t+1步,则接收当前时刻的延误时间向量,若预测t+p步,则接收t+p-1步的延误时间向量)将输出结果用解码器进行训练后,输出并保存隐含层参数ht+a和最后一次的记忆状态c。
在本实施例中,上述步骤6和步骤7的基于序列到序列的lstm模块中包含了编码器和解码器,两者均基于lstm模型构建,其中编码器和解码器内部工作流程具体介绍如下:
在编码器中流程如下:
2.1)给定h*个历史步长的机场延误时间矩阵
2.2)取延误时间矩阵的第一个延误时间列向量x,并将其在矩阵中移除,将x输入编码器并训练编码器的lstm模型;
2.3)迭代2.2),不断输出隐含层参数向量h和记忆状态c至下一轮训练的lstm模型中并保存直到矩阵为空,将最后一层隐含层参数h和记忆状态c输出至解码器;
在解码器中流程如下:
3.1)输入待预测步数前一步输出的机场延误时间向量x,所述机场延误时间向量x来自于前一步预测最终得到的延误时间向量(其模块是耦合的,只是在解释中进行了分解);
3.2)输入编码器传输的最后一层隐含层参数h和记忆状态c至解码器的lstm模型;
3.3)训练解码器的lstm模型并输出保存当前预测的向量的隐含层参数ht+a和记忆状态ct+a;
3.4)判断是否达到预测步长,若达到则停止,若没有达到则接收下一个机场延误时间向量xnext重复3.1)~3.3),直到达到预测步长后循环结束;且每次循环均输出生成的隐含层参数ht+a至注意力机制模块,并将隐含层ht+a和记忆状态ct+a作为输入值输入下一轮训练的lstm模型中。
步骤8:将步骤6得到的隐含层参数h所组成的向量h和步骤7得到的当前的预测值对应的隐含层参数ht+a输入到注意力机制模块中,得到加权后的隐含层参数h’t+a并输出。
在本实施例中,注意力机制模块的算法流程具体为:
4.1)接收编码器中保存的隐含层参数向量h;
4.2)输入当前的隐含参数ht+a;
4.3)取隐含层参数向量h的第一个隐含层参数h并在向量h中移除,计算ht+a和隐含层参数h的内积并保存;
4.4)不断迭代执行4.3),直到h向量为空;
4.5)对所得的所有内积进行softmax运算并得到权重;
4.6)根据4.5)计算得到的权重对未被移除的原向量h加权求平均,得到所求向量对应的隐含层h’t+a并输出。
步骤9:提取专家系统内的机场特征的专家知识并进行独热编码后输出。本实施例中的机场特征的专家知识可以同时包含机场与航班的特征信息。
步骤10:提取气象数据库服务器的天气数据并进行独热编码后输出。由于天气类型会直接影响航班的延误情况,因此本实施例中的气象数据可包含不同的天气类型。
步骤11:将步骤9和步骤10输出的数据进行数据降维并作为辅助特征数据输出;
步骤12:将步骤8得到的加权后的隐含层参数h’t+a和步骤11得到的降维后的辅助特征数据作为输入值输入到全连接网络中,得到所要预测的步数的延误时间矩阵。
步骤13:重复步骤7到步骤12的过程,预测之后全部p个步长的延误时间矩阵,并将其组成n×p的延误时间矩阵。此处的p的具体步数可以根据实际调整,最少为1步,p为大于等于1的自然数。如果p为1,本步骤中实际无需重复步骤7到步骤12的过程了,如果p大于1,那么本步骤中还需要重复步骤7到步骤12的过程共p-1次,得到p个步长的延误时间矩阵。
步骤14:将步骤13得到的延误时间矩阵输出至审核端进行审核,审核通过后将数据输出至展示发布模块进行展示。
在本实施例中,展示发布模块的工作流程为:
首先接收预测的延误时间矩阵,并将其展示至机场端,待机场工作人员审核数据确认后并将其发布至用户端。同时,延误时间矩阵亦可展示至其他的平台,对此不做限定。
下面将上述方法应用于具体的数据集中,各步骤的实现方式参见上述步骤1~步骤14,不再完全重复赘述,下面主要展示其具体实现细节和效果。
实施例:
本实施例的数据为飞常准公司统计的2016年1月1日至2016年12月31日的起始机场为国内的航班运行信息。该数据集包含的字段为:航班号、航班日期、航班计划出发/到达时间、航班实际出发/到达时间、飞机类型、飞机注册号、计划出发/到达机场、实际出发/到达机场、航空公司和航班状态等信息。
1):定义延误率。本例中延误率的定义为2016年新版征求意见对航班的延误进行定义,其定义公式为航班实际出发时间与计划出发时间的差值,即:dep_delay=max(r_dep_time-p_dep_time-15,0)。定义平均延误率:平均延误率的定义为采样时间内所有的延误的均值,其公式如下:
2):对机场后台航班的数据进行数据清洗,清洗规则如下:1.删除后台数据中取消的航班的数据,2.删除后台数据中丢失计划出发时间或者实际出发时间的航班数据。3.由于航班的延误时间不能过长,删除延误时间超过6个小时以上的航班数据。
3):设置本例中的采样间隔为1小时,计算各个机场的延误时间矩阵和平均延误时间矩阵并将数据集加载,建立机场延误信息图矩阵并提取历史延误的时间矩阵。本例共获得171个机场的3135672条数据,按照采样时间为1小时进行计算后获得相应的机场延误信息图矩阵和历史延误的时间矩阵。进行数据清洗后,所剩的数据共包含112个机场和4532条有向边,选择的时间步长为t=8784。即得到的图矩阵的形式为
4):通过pagerank算法对整个机场延误信息图矩阵进行重要性计算。pagerank算法的流程图如图1所示,其流程为:1.在模块中输入机场的平均延误时间图g,2.确定机场数量n和阻尼系数d,3.给定pagerank算法的结果初始值向量
5):图2为不同输入长度验证集绝对误差变化曲线,由图观察可知,在输入步长达到7步之后,误差的下降速度十分缓慢,基本保持平稳,因此设置输入时间步长为h=7,延误时间矩阵的形式为x7=[x(t-6),x(t-5),...,x(t)]。
6):预测系统将5)得到的机场延误时间矩阵和4)得到的延误时间的延误时间权重矩阵中对应的7个列向量所组成的矩阵进行哈达玛积,得到
7):基于序列到序列的lstm模块的编码器接收5)的输出结果,进行训练后,得到全部的隐含层参数h组成的向量h和最后一次的记忆状态c,并将这些数据传入到解码器中。
8):解码器接收编码的输出数据,并接收预测步数上一步的输出结果,(若是预测t+1步,则接收当前时刻的延误时间向量,若预测t+p步,则接收t+p-1步的延误时间向量)将这些结果用解码器进行训练后,输出并保存隐含层参数h和最后一次的记忆状态c。序列到序列的lstm模块流程图如图3所示。在本例中,设置的预测步长p=6。基于序列到序列的lstm模块的工作流程具体如下:编码器:1.给定历史7个步长的机场延误时间矩阵
9):将7)得到的编码器隐含层参数向量h和8)得到的解码器中当前的预测延误时间向量对应的隐含层参数h输入到注意力机制模块中,得到加权后的隐含层参数h’并输出。注意力机制模块的工作流程图如图4所示,在本例中,其工作流程为:1.接收编码器中保存的h参数向量,2.输入当前的隐含参数ht+a,3.取隐含层参数向量的第一个h并在向量h中移除,4.计算ht+a和h的内积并保存,直到h向量为空,5.对所得结果进行softmax运算并得到权重,6.根据5计算得到的权重对向量h加权求平均得到所求向量对应的隐含层h’t+a并输出,图5为注意力机制模块中,经过softmax运算得到的权重值大小的热力图。
10):延误预测系统提取气象数据库服务器的气象数据,在本例中,气象数据中的天气类型被分为雨、雪、雾、其他恶劣天气、预警和其他。每种天气类型中包含不同的天气状态,如雨包含了阵雨、大雨、暴雨、冻雨、雷雨;雪包含了阵雪、雨夹雪、中雪、大雪和暴雪;雾包含了大雾、冻雾、雾霾;其他恶劣天气包含了低能见度、对流天气、低云、浮尘、扬沙、沙尘暴、冰;预警包含了红色预警、橙色预警、蓝色预警;其他包含了通行能力下降、跑道关闭、空域繁忙。这些变量用独热编码进行处理后进行输出。
11):延误预测系统提取专家系统的数据库信息,专家系统的信息包含机场与航班的特征,在本例中,所提取的信息为航班计划起飞降落时间,所在的月份、所属的星期、航空公司、起飞降落机场规模、机型、驻地优势和航班持续时间、航班所在的航季。将这些数据中的连续部分进行归一化,离散部分进行独热编码后进行输出。
12):将10)和11)得到的数据进行数据降维并作为输出,本例中采用的降维方法为线性回归方法,确保数据在维度降低的同时不丢失信息。
13):重复7)到12)的过程,预测之后p个步长的延误时间矩阵,并将其组成n×p的时间序矩阵。图6为本例中预测得到的飞机延误的绝对值误差与其他方法的对比效果图,从图中可知,相比于其他模型,本发明提出的模型效果最佳。
14):预测系统将13)得到的延误时间矩阵输出至机场工作人员处进行审核,审核通过后将数据输出至展示发布模块进行展示。发布模块的工作流程为1.接收预测的延误时间矩阵,并将其展示至机场端。2.机场工作人员审核数据,确认后并将其发布至用户端。用户可以根据预测延误时间调整出行,机场根据预测延误时间调整航班规划。
图6为空中交通延误预测系统的整体工作流程图。利用好上述训练好的模型,对未来6个小时的航班进行预测,得到未来6小时整体机场网络的延误数据,为机场管理人员和用户带来方便。
以上所述的实施例只是本发明的部分较佳的方案,然其并非用以限制本发明。因此有关技术领域的普通技术人员,在不脱离本发明的精神和范围的情况下,还可以做出各种变化和变型。凡采取等同替换或等效变换的方式所获得的技术方案,均落在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!