一种基于分布式多任务的社会负面舆情实时分析方法与流程
本发明属于人工智能技术领域,特别涉及一种基于分布式多任务的社会负面舆情实时分析方法及方法。
背景技术:
互联网的日益发达,社会信息发展的非常迅速,很多网络舆情负面消息也日益彰显。互联网时代每天会有大量的负面舆情通过网络而自由传播,这些内容包括图文、视频、音频等,内容情感方面有正面、有负面甚至有涉恐、涉暴、涉黄、涉毒等不良信息。对于舆情监测如何快速抓取、分析、危害社会治安或者可能造成不良影响的舆论,成为稳定社会舆情的难题。
技术实现要素:
(1)要解决的技术问题
本发明的实施例提供一种基于分布式多任务的社会负面舆情实时分析方法,通过设置若干个预警警亭、物联网模块以及云端服务器,解决了如何快速发现有利和不利的文章和舆论,以便迅速应对不利于社会发展的突发事件的问题。
(2)技术方案
本发明的实施例提出了一种基于分布式多任务的社会负面舆情实时分析方法,包括如下步骤,
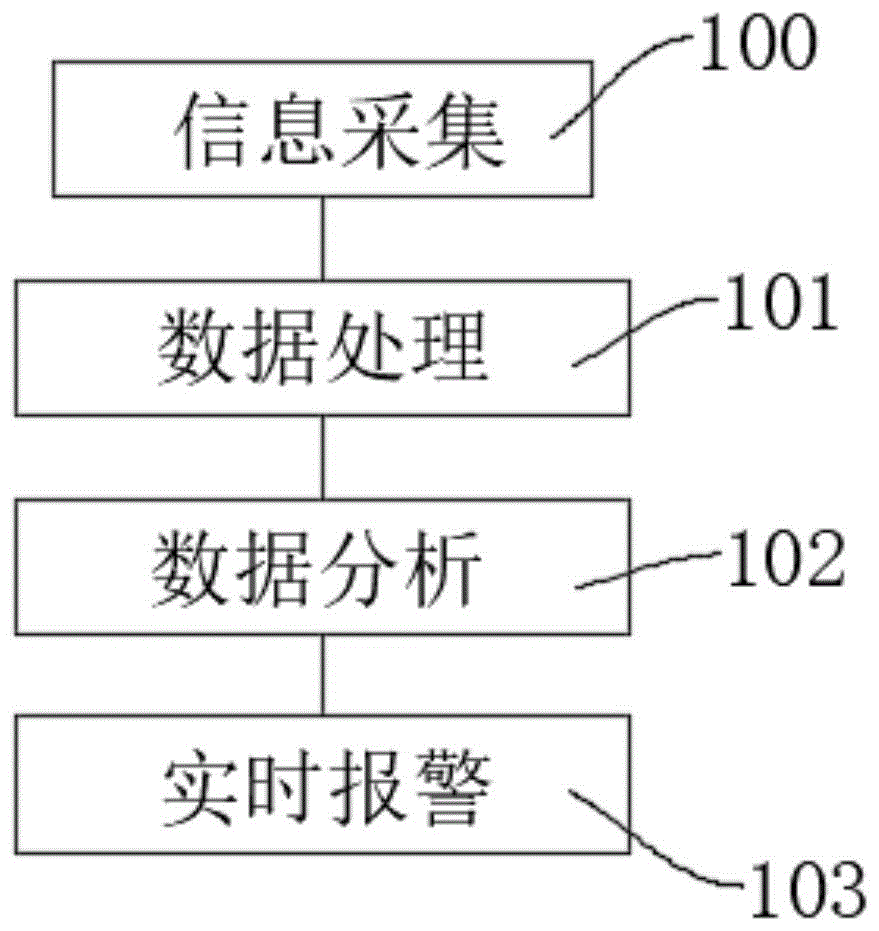
s1:信息采集,实时采集互联网上的原始数据,并进行存储;
s2:数据处理,对存储后的原始数据进行处理,获得修整数据;
s3:实时数据分析;对修整数据进行统计以及nlp情感分析算法实时分析,及时获得负面舆情;
s4:实时报警;
其中,所述信息采集和所述数据处理均采用分布式多任务进行。
进一步地,s1中所述信息采集具体步骤如下:
i:通过各大网站以及app进行信息数据采集;其中,在采集过程中采用多分布多线程和多任务执行,从多个队列中并行读取数据,读写同时进行;
ii:存放到hadoop分布式存储集群中。
进一步地,s2中所述数据处理具体步骤如下:
①:简单清洗;对原始数据中存在的乱码、多余空格、多余空行等进行祛噪点;
②:条件筛选:根据数据渠道以及数据类型对数据进行筛选;
③:复杂清洗:祛除数据中广告性质的文字。
进一步地,s3中所述实时数据分析的具体步骤如下:
ss1:对舆情信息数据进行统计;
ss2:nlp情感分析算法对舆情信息数据进行处理分析;
ss3:汇总每日、周、月、区域等相关舆情信息传播情况,包括整体趋势、媒体监测情况、周热点、舆论重点等方面;
ss4:分析总结监测结果,形成报告提供给用户使用。
进一步地,所述nlp情感分析算法包括:
输入门:rt=σ(dtwdr+yt-1wyr+cr);
遗忘门:st=σ(dtwds+yt-1wys+cs);
输出门:ut=σ(dtwdu+yt-1wyu+cu);
候选记忆细胞:
记忆细胞:
隐藏状态:yt=ut⊙tanh(et);
其中,wdr、wds、wdu、
(3)有益效果
综上所述,本发明通过采用分布式系统多任务方式,进行海量的网络舆情信息采集;其次数据进行分析处理,并结合nlp情感分析技术等,实时监控热点及舆情,重点舆情信息分析报告,监测负面信息发展趋势及舆论走向,分析传播路径和核心传播用户,通过数据分析汇总产生舆情报告;最终实时发现社会负面舆情信息,进而实时报警反馈,得到快速响应和及时处理,尽早控制负面舆情消息蔓延。把握舆情态势,快速了解网络上的各种声音,对负面舆情实时告警,为社会或企业解决舆情监测的问题,助力快速顺利地处置突发负面舆情信息。
附图说明
图1是本发明整体框架示意图;
图2是本发明中数据采集模块示意图;
图3是本发明中数据处理模块示意图;
图4是本发明中数据分析模块示意图;
图5是本发明中负面舆情类型示意图。
图中:100-信息采集;101-数据处理;102-实时数据分析;103-实时报警。
具体实施方式
下面结合附图和实施例对本发明的实施方式作进一步详细描述。以下实施例的详细描述和附图用于示例性地说明本发明的原理,但不能用来限制本发明的范围,即本发明不限于所描述的实施例,在不脱离本发明的精神的前提下覆盖了零件、部件和连接方式的任何修改、替换和改进。
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。下面将参照附图并结合实施例来详细说明本申请。
实施例1:
如图1-5所示的一种基于分布式多任务的社会负面舆情实时分析方法,包括如下步骤,
s1:信息采集100,实时采集互联网上的原始数据,并进行存储;
s2:数据处理101,对存储后的原始数据进行处理,获得修整数据;
s3:实时数据分析102;对修整数据进行统计以及nlp情感分析算法实时分析,及时获得负面舆情;
s4:实时报警103;
其中,所述信息采集100和所述数据处理101均采用分布式多任务进行;本发明通过采用分布式系统多任务方式,进行海量的网络舆情信息采集;其次数据进行分析处理,并结合nlp情感分析技术等,实时监控热点及舆情,重点舆情信息分析报告,监测负面信息发展趋势及舆论走向,分析传播路径和核心传播用户,通过数据分析汇总产生舆情报告;最终实时发现社会负面舆情信息,进而实时报警反馈,得到快速响应和及时处理,尽早控制负面舆情消息蔓延。把握舆情态势,快速了解网络上的各种声音,对负面舆情实时告警,为社会或企业解决舆情监测的问题,助力快速顺利地处置突发负面舆情信息。
值得注意的是,所述分布式多任务的具体过程是:底层采用hadoop构建出一个由几十台服务器组成的大集群,并实现其分布式存储与分布式计算,hadoop采用的是移动计算的方式,通过将计算脚本复制到集群中的每一台机器上,让其读取本地数据来提高计算的效率。实现对海量数据的存储与计算,通过将多台服务器共同组成一个大的集群的方式,将多台服务器的硬盘空间组成一个共同的文件系统,这个文件系统分布在多台服务器上,并且可以任意一台服务器都可以访问这个文件系统,同时对海量数据计算时,也可以充分利用多台服务器的硬件设备,起到一个并行计算的作用,加快对海量数据的处理速度。
进一步地,s1中所述信息采集100的具体步骤如下:
i:通过各大网站以及app端进行信息数据采集;其中,在采集过程中采用多分布多线程和多任务执行,从多个队列中并行读取数据,读写同时进行;其中,app端包括客户端、微信、头条、抖音等;
ii:存放到hadoop分布式存储集群中。
进一步地,s2中所述数据处理101的具体步骤如下:
①:简单清洗;对原始数据中存在的乱码、多余空格、多余空行等进行祛噪点;
②:条件筛选:根据数据渠道以及数据类型对数据进行筛选;
③:复杂清洗:祛除数据中广告性质的文字。
进一步地,s3中所述实时数据分析的具体步骤如下:
ss1:对舆情信息数据进行统计;
在本实施例中,采用flink、spark等技术对舆情信息数据进行统计;
ss2:nlp情感分析算法对舆情信息数据进行处理分析;
ss3:汇总每日、周、月、区域等相关舆情信息传播情况,包括整体趋势、媒体监测情况、周热点、舆论重点等方面;
ss4:分析总结监测结果,形成报告提供给用户使用。
进一步地,所述nlp情感分析算法包括:
输入门:rt=σ(dtwdr+yt-1wyr+cr);
遗忘门:st=σ(dtwds+yt-1wys+cs);
输出门:ut=σ(dtwdu+yt-1wyu+cu);
候选记忆细胞:
记忆细胞:
隐藏状态:yt=ut⊙tanh(et);
其中,wdr、wds、wdu、
值得注意的是,nlp情感分析算法是基于lstm提出的,它将当前时间的正向隐藏状态记为
本发明的工作原理:采集来源自各网站、客户端、微信、头条、抖音等渠道的数据,并存储在hadoop分布式存储集群中,但是由于不同渠道的数据构成各不相同,并且一个渠道的数据包括了图片、视频、文字等多种数据类型,例如头条渠道数据包括微头条、短视频、文章等,所以我们需要根据数据渠道、数据类型对数据进行条件筛选归类,以分布式多任务方式同时处理不同类型数据。以达到nlp情感分析对文本内容质量要求,所以在单个任务中,先对采集到的原始数据存在着乱码、多余空格、多余空行等,需要经过初步的简单清洗,替换掉这些内容,接着进行复杂的清洗,例如:微信文本数据根据特定规则可以去除“扫描二维码,关注****的公众号”等广告性质的文字,使后续的nlp情感分析更加准确。
实施例2:
为了更好的讲述本发明:以微博渠道为例。
大数据分布式系统实时监控指定作者在微博平台发文情况。当该作者发布了新的文章“\n#大头娃娃涉事店铺被罚款4000元#”,系统会及时将该条文本及其作者、点赞数、评论数等信息采集到hadoop分布式存储集群中,在这过程中系统进行了简单的清洗,将文章开头的“\n”脏数据去除。采用分布式多任务并行读取的方式从集群中实时读取到数据,通过数据标签"data_channel":"wb"(即数据渠道来自于微博)判定认定为微博文本类数据,以微博文本特定的清洗方式将“#大头娃娃涉事店铺被罚款4000元#”中“#”去除而不影响文本质量。接下来,判断该文本“大头娃娃涉事店铺被罚款4000元”的情感正负面:
(1)将文本内容进行分词处理并根据停用词典,删除停用词“被”,得到“大头”,“娃娃”,“涉事”,“店铺”,“罚款”,“4000”,“元”上述七个词;
(2)利用word2vec算法,将上述七个词转换成128维度词向量形式,例如:“罚款”:[-0.18098572,-0.99400914,-0.01475801,-0.49014655,-0.481841,……,1.1071281,-0.13225996]。其中,word2vec算法属于nlp情感分析算法,具体为将每个词表示一个指定长度的向量,并使得这些向量能够较好地表达不同词之间的相似和类比关系;
(3)将七个词向量导入训练好的正负面情感分类nlp情感模型进行计算,得到正/负面:0.05,0.95,即“大头娃娃涉事店铺被罚款4000元”这段内容正面的可能性为5%,负面的可能性为95%,所以判定这篇文章为负面。
本发明的描述中,需要理解的是,术语“中心”、“横向”、“上”、“下”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”等指示的方位或位置关系-基于附图所示的方位或位置关系,仅是-了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解-对本发明的限制。此外,术语“第一”、“第二”仅用于描述目的,而不能理解-指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。在本发明的描述中,除非另有说明,“若干个”的含义是两个或两个以上。另外,术语“包括”及其任何变形,意图在于覆盖不排他的包含。
本发明按照实施例进行了说明,在不脱离本原理的前提下,本装置还可以作出若干变形和改进。应当指出,凡采用等同替换或等效变换等方式所获得的技术方案,均落在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!