一种基于UFIM-Matrix算法改进的不确定频繁项集营销数据挖掘算法
本发明属于数据挖掘领域,涉及一种基于ufim-matrix算法改进的不确定频繁项集挖掘算法。
背景技术:
随着时代的发展,数据挖掘受到了各行各业的重视,已变成众多学者研究的热点。数据挖掘指在许多领域信息中,找出隐蔽、新奇、有效、容易分析的高级数据处理操作。随着信息技术的发展,在金融、物流以及天体研究等众多领域,时刻都会产生和记录海量的数据。如何从这些数据中获取有价值的潜在信息,如何智能地将海量的数据转换成有用的知识,并用知识对未来进行指引,这些需求引发了对新的技术和自动工具的研究,数据挖掘始然出现。
不确定数据的出现,使数据挖掘领域变得更加棘手,不确定数据是指每一条事务中项目的存在不再是百分百确定的,而是依据某种相似性度量或是概率形式存在。不确定数据主要是由于数据本身的特点或者数据在产生、收集、存储和传输过程中存在大量随机性导致的,比如说通过对购物篮分析从而预测商品需求量时,购物篮中的商品用户并不是肯定要购买的。目前,不确定数据广泛应用于传感器网络、rfid应用、web应用、商业决策等诸多领域。
商品营销在生活中非常的常见,一个大型的超市,每天都有海量的购物数据产生,那么如何从这些海量的营销数据中挖掘出对商场有用的信息呢?在营销数据挖掘方面虽然有很多的技术,如:u-apriori算法、uf-growth算法、cuf-growth算法等等,但是它们无论是在数据的准确度,挖掘的时间还是算法运行占用的内存,都存在一定的弊端,无法适应越来越多的营销数据。
尤其是营销数据的不确定性给频繁模式挖掘带来了极大挑战,一方面是相对于营销数据规模呈指数增长,另一方面是新出现的概率维度,这导致传统的针对确定性营销数据的频繁模式挖掘算法的准确性和时效性大大降低,不能满足具体的应用需求。因此,迫切需要提出新的理论模型和算法解决不确定营销数据的频繁模式挖掘问题。
技术实现要素:
本发明旨在解决以上现有技术的问题。提出了一种基于ufim-matrix算法改进的不确定频繁项集营销数据挖掘算法。本发明的技术方案如下:
一种基于ufim-matrix算法改进的不确定频繁项集营销数据挖掘算法,其包括以下步骤:
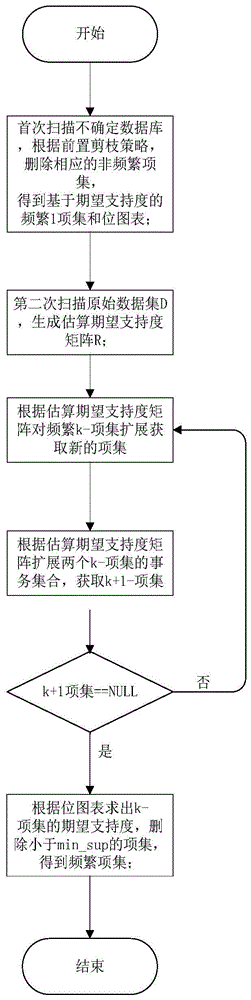
步骤一:首先扫描营销不确定数据库,根据前置剪枝策略对非频繁项集进行删减,得到基于期望支持度的频繁1-项集l1;
步骤二:对原始营销数据集d(即不确定数据库)进行扫描,生成最大概率矩阵r;
步骤三:将l1自乘并利用最大概率矩阵r生成2-项集;
步骤四:依次取出步骤三的各个2-项集,采用子集检测的方法扩展为3-项集,依次类推扩展出k-项集,并利用位图表求出相关项集的期望支持度,将期望支持度小于min_sup的项集删除,得到基于期望支持度的营销数据频繁项集。
进一步的,所述步骤一具体为:首次扫描不确定营销数据库,利用前置剪枝策略(1)(2)对非频繁项集进行删减,得到基于期望支持度的频繁1-项集l1:
策略1如果cnt(x)<minsup,则x是非频繁的;
sup表示支持度,cnt(x)表示包含项集x的事物数。
策略2定义u=esup(x),
u表示x的期望支持度、esup(x)表示x的期望支持度、σ分别表示支持度偏离度。
(1)σ≥2e-1并且2-σu<minprob(5)
(2)0<σ<2e-1并且
prob表示概率支持度
进一步的,所述步骤二具体为:根据公式(7)第二次对原始营销数据集d进行扫描,生成最大概率矩阵r;
定义3设不确定数据集d中有n个事务和m个基于期望支持度的频繁1-项集,经过f:d→r转换为最大概率矩阵r;
其中,r=f(d)=(rju)n*m(j=1,2,...,n;u=1,2,...,m)
rju表示矩阵中j列m行数据、f(d)分别表示映射函数,n*m表示n行m列矩阵;pcap*表示最大概率,t表示事务数据。
进一步的,所述步骤三具体为:根据公式(8)将l1自乘并利用最大概率矩阵r生成2-项集;
定义4二项集{ix,iy}的定义为:
式中:“λ”表示求最小值运算。
进一步的,所述步骤四具体为:依次取出各个2-项集,并采用子集检测的方法,扩展为3-项集,依次类推扩展出k-项集,根据位图表利用期望支持度的求值公式求出每个项集的期望支持度,将期望支持度小于min_sup的项集删除,得到基于期望支持度的频繁项集。
本发明的优点及有益效果如下:
1)本发明通过引入前置剪枝策略,与常规的索引剪枝策略相比,该策略只涉及到一些常数的四则运算,是一种十分高效的剪枝手段,提前删除不频繁的项,避免前期数据量过大而导致过多的空间消耗,节省算法运行的空间。由于该策略需要用到期望偏离度,而前期的剪枝策略都没有出现计算期望偏离度的方法,所以本发明用到的这个策略与常规方法相比具有一定的高效性。
2)本发明在计算k-项集支持度时,引入位图表和项集期望的求值公式,通过计算出相应的项集支持度,得到频繁项集,与常规的先计算估算期望支持度,然后进行第三次扫描营销数据库,进而得到频繁项集相比,该方法最大的优势
在于只需要对数据库进行两次扫描,节省了算法的时间。
附图说明
图1是本发明提供优选实施例基于ufim-matrix算法改进的不确定频繁项集营销数据挖掘算法流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、详细地描述。所描述的实施例仅仅是本发明的一部分实施例。
本发明解决上述技术问题的技术方案是:
在本实施例中,一种基于ufim-matrix算法改进的不确定频繁项集挖掘算法是按如下步骤进行的。
步骤一:扫描营销数据库获取频繁1-项集;
首次扫描不确定营销数据库,利用前置剪枝策略(9)(10)对非频繁项集进行删减,得到基于期望支持度的频繁1-项集l1;
策略1如果cnt(x)<minsup,则x是非频繁的;
sup表示支持度,cnt(x)表示包含项集x的事物数。
策略2定义u=esup(x),
u表示x的期望支持度、esup(x)表示x的期望支持度、σ分别表示支持度偏离度。
(1)σ≥2e-1并且2-σu<minprob(9)
(2)0<σ<2e-1并且
prob表示概率支持度
步骤二:第二次扫描原始数据集d,生成最大概率矩阵r;
对不确定营销数据库进行第二次扫描,根据公式(11)生成最大概率矩阵r;
定义5设不确定数据集d中有n个事务和m个基于期望支持度的频繁1-项集,经过f:d→r转换为最大概率矩阵r;
其中,r=f(d)=(rju)n*m(j=1,2,...,n;u=1,2,...,m)
rju表示矩阵中j列m行数据、f(d)分别表示映射函数,n*m表示n行m列矩阵;pcap*表示最大概率,t表示事务数据。
步骤三:将l1自乘并利用最大概率矩阵r生成2-项集;
根据公式(12)将l1自乘并利用最大概率矩阵r生成2-项集;
定义6二项集{ix,iy}的定义为:
式中:“λ”表示求最小值运算。
步骤四:依次取出各个2-项集,并采用子集检测的方法,扩展为3-项集,依次类推扩展出k-项集,根据位图表利用期望支持度的求值公式求出每个项集的期望支持度,将期望支持度小于min_sup的项集删除,得到基于期望支持度的频繁项集。
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、商品或者设备中还存在另外的相同要素。
以上这些实施例应理解为仅用于说明本发明而不用于限制本发明的保护范围。在阅读了本发明的记载的内容之后,技术人员可以对本发明作各种改动或修改,这些等效变化和修饰同样落入本发明权利要求所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!