基于条件生成模型的高效近似查询处理算法
本发明属于信息检索技术领域,具体涉及一种近似查询处理算法。
背景技术:
随着信息技术的快速发展,数据量呈爆炸性的速度持续增长,使得传统的数据库系统软件难以在交互式响应时间内回答用户的聚集查询。而在具体的决策分析任务中,用户通常只需要从数据中获取大致的趋势,不要求精确的结果。而且,在实际情况中,数据分布并不均匀,存在严重的偏斜问题。因此,如何在海量的偏斜数据中以更快的响应速度获取精度较高的查询结果具有重要的意义。
近似查询处理(approximatequeryprocessing,aqp)算法(chaudhuris,dingb,kandulas.approximatequeryprocessing:nosilverbullet[c]//proceedingsofthe2017acminternationalconferenceonmanagementofdata,chicago,may14-19,2017.newyork:acm,2017:511-519.)以牺牲一定的精度为代价来换取更快的查询响应速度,保证了用户的交互性需求,成为了近年来数据库查询领域的一大研究热点。目前,近似查询处理方法大致可分为三类。第一类是基于抽样的近似查询处理(sampling-basedapproximatequeryprocessing,saqp)(liky,ligl.approximatequeryprocessing:whatisnewandwheretogo?[j].datascienceandengineering,2018,3(4):379-397.),它以抽样的方法创建一个随机的数据样本,并将该样本作为原始数据的摘要,估计查询结果。saqp方法原理简单,适用于大多数通用查询,但该方法生成的样本往往不能代表总体数据集,尤其在面临高度偏斜的数据时,基于随机抽样的saqp算法不能为稀有数据生成足够的样本,影响估计结果的准确性(olkenf,rotemd.randomsamplingfromdatabases:asurvey[j].statisticsandcomputing,1995,5(1):25-42.)。基于分层抽样的saqp算法可以克服数据偏斜问题,但分层抽样依赖于对数据分布的先验知识,只适用于特定数据的查询,不具有一般性(panahbehaghb.stratifiedandrankedcompositesampling[j].communicationsinstatistics-simulationandcomputation,2020,49(2):504-515.)。另一类是聚集预计算(aggregateprecomputation,aggpre)(escobarp,candelag,trujilloj,etal.addingvaluetolinkedopendatausingamultidimensionalmodelapproachbasedontherdfdatacubevocabulary-sciencedirect[j].computerstandards&interfaces,1994,5(1):25-42.),该方法预先计算一些聚集查询的结果,之后使用该结果快速地回答用户查询。但aggpre方法的查询效率取决于预聚集值的计算,有限数量的预聚集值很难提供足够准确的查询结果,而预先计算较多的聚集值却将花费大量的存储空间。
第三类是采用机器学习中的方法来实现近似查询处理,诸如变分自编码器(variationalauto-encoder,vae)、生成对抗网络(generativeadversarialnetwork,gan)等深度生成模型。此类算法可以学习到原始数据的分布特征,从而达到生成高质量样本的效果,提高查询准确率(hilprechtb,schmidta,kulessam,etal.deepdb:learnfromdata,notfromqueries![j].proceedingsofthevldbendowment,2020,13(7):992-1005.)。其中,vae是一种常见的生成模型(yanlc,yoshuab,geoffreyh.deeplearning[j].nature,2015,521(7553):436-444.),通过学习原始数据的低维潜在特征,对各种复杂的数据分布进行建模并生成样本。vae的训练过程简单高效,具有可解释的潜层空间,但其误差衡量不够精确,难以使潜层空间中生成的数据符合期望分布,影响查询准确率。gan是另一种有效的生成模型(creswella,whitet,dumoulinv,etal.generativeadversarialnetworks:anoverview[j].ieeesignalprocessingmagazine,2018,35(1):53-65.),通过使内部的生成网络与鉴别网络相互对抗,从而降低模型误差,生成符合原始数据分布的样本。但是,gan在训练过程中很难保证内部网络均衡,容易出现模型坍塌。
技术实现要素:
针对现有技术中存在的上述问题,本发明首先设计了一种新型的生成模型,该模型将条件变分自编码器的编码网络融入到条件生成对抗网络中,可以高效的近似原始数据的分布,克服数据偏斜;同时,使用wasserstein距离作为误差衡量,防止模型坍塌。其次,本发明基于该模型实现近似查询处理算法,可根据用户需求生成任意大小的样本,而无需访问底层数据,避免磁盘交互。之后,本发明将该算法与聚集预计算相融合构成交互式分析查询的通用框架,并通过设计的表决算法最小化查询误差,从而更好的处理交互式查询。
本发明解决其技术问题采用的技术方案是:基于条件生成模型的高效近似查询处理算法,包括:
采用聚集预计算获得用户查询的预聚集值;
对用户查询进行处理,获得估计用户查询与预聚集范围之间差异的新查询newq及选择的预聚集值
构建基于wasserstein的条件变分生成对抗网络模型,利用训练完成的模型为新查询newq生成数据样本;
对生成的数据样本进行过滤,将过滤后的数据样本与选择的预聚集值相结合,计算得到最终的查询估计值。
作为本发明的一种优选方式,所述的模型由编码网络、生成网络以及鉴别网络组成。
进一步优选地,所述模型的训练过程包括数据预处理阶段,对原始数据进行聚类预处理,获得聚类后的真实数据x以及各类的条件特征y。
进一步优选地,所述模型的训练过程还包括迭代训练阶段,将所述数据预处理阶段获得的真实数据x与对应的条件特征y相融合作为模型的输入,使用编码网络得到潜层空间中数据分布的均值μ与方差δ2;并以μ和δ2作为参数,通过random()随机函数产生潜层空间中的噪音数据z={z1,...,zn};生成网络从潜层空间中随机地抽取一组噪音数据,并通过深层网络模型生成满足条件特征y的虚假样本x_fake;使用鉴别网络对x_fake进行判断,得到x_fake是否为真的概率值。
进一步优选地,所述迭代训练阶段还包括采用kl散度损失函数来计算编码网络的误差损失,计算公式为:
其中,kl_loss表示编码网络构造的潜层空间中,数据的实际分布q(z|x)与期望分布p(z|x)之间的差异;μ和σ2分别表示编码网络生成的均值与方差;k表示模型在预处理阶段聚类所划分的类别的个数;j=1,2,……,k,表示第j个类别。
进一步优选地,所述迭代训练阶段还包括采用交叉熵损失函数来计算生成网络的误差损失:
其中,re_loss表示生成网络生成的虚假数据x_fake与真实数据x之间的差异。
进一步优选地,所述迭代训练阶段还包括采用wasserstein距离作为损失函数计算生成网络、鉴别网络的误差损失:
g_loss=-e(d(x_fake));
d_loss=e(d(x_fake))-e(d(x));
其中,g、d分别表示生成网络和鉴别网络。
进一步优选地,在所述迭代训练阶段,使用rmspropoptimizer作为模型优化器,优化各网络的参数。
进一步优选地,采用所述预处理阶段获得的原始数据的各个类别作为预聚集值计算的范围。
进一步优选地,数据样本的过滤采用表决算法;所述的表决算法包括样本过滤器和数据过滤器;所述样本过滤器用于对模型生成的单一样本进行分类预测;所述数据过滤器用于对样本内部数据进行快速预测。
本发明的算法构建了一种高效的深度生成模型,该模型融合cvae、cgan等经典的模型算法,并引入wasserstein距离作为误差衡量,消除模型坍塌;其次,将该模型应用于近似查询,并与聚集预计算相结合,提出cvwgaqp++算法框架;同时,设计了高效的表决算法,降低近似查询误差。本发明提出的算法相较于对比算法在性能上有显著的提高。
附图说明
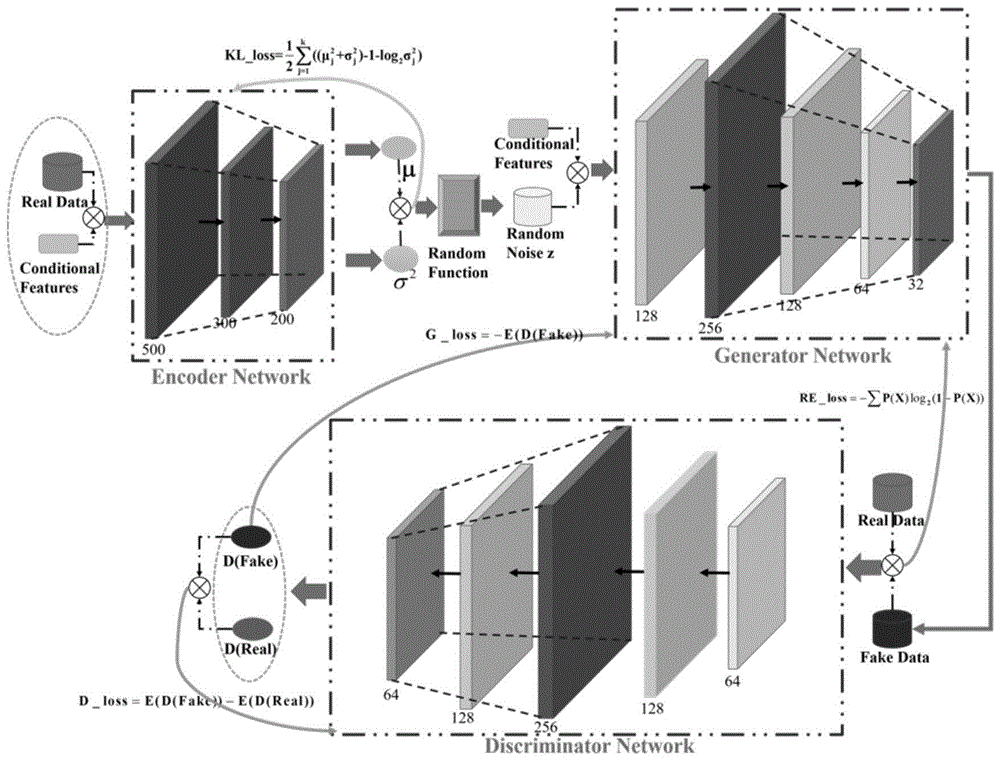
图1为本发明实施例中提供的基于wasserstein的条件变分生成对抗网络模型的结构图;
图2为本发明实施例中模型的训练流程图;
图3为本发明实施例中提供的基于条件生成模型的高效近似查询处理算法的流程图;
图4为样本过滤器的算法流程图;
图5为数据过滤器的算法流程图;
图6为本发明的cvwgaqp++算法与对比算法在偏斜数据中查询结果对比图;
图7为本发明的cvwgaqp++算法与对比算法在不同原始数据规模下查询质量对比图;
图8为本发明的cvwgaqp++算法与对比算法在不同生成数据规模下查询响应时间对比图。
具体实施方式
本发明提供的基于条件生成模型的高效近似查询处理算法,具体实现过程和步骤详细阐述如下:
一、基于wasserstein的条件变分生成对抗网络模型的构建
本发明提供的基于wasserstein的条件变分生成对抗网络模型(conditionalvariationalwassersteingenerativeadversarialnetwork,cvwgan)以cgan的网络结构为基础,融入cvae中的编码网络,保证总体模型的稳定。模型的具体结构如图1所示。
该模型由编码网络(encoder,e)、生成网络(generator,g)以及鉴别网络(discriminator,d)组成。其中,编码网络将真实数据的未知分布映射为潜层空间(latentspace,ls)中的常见分布,共有三层,以真实数据x以及对应的条件特征y作为输入,映射得到各类数据在ls中分布的均值与方差等参数。之后,模型根据该参数构建ls,并从中随机抽取大小为n*1的噪音数据z={z1,...,zn},且与y融合,共同作为生成网络的输入。生成网络共有五层,根据输入的随机噪音,生成符合真实数据分布的虚假数据x_fake。鉴别网络对x_fake进行判别,输出得到x_fake是否为真的概率d(x_fake)。该网络共有5层,使用wasserstein距离衡量网络的误差,且在训练过程中,执行回归任务,拟合wasserstein距离,从而避免梯度消失,防止模型坍塌。模型的具体信息如表1所示。
表1模型信息表
二、模型重要参数设置
1、batch_size
batch_size为模型每次训练的样本个数,它的大小与模型的收敛速度以及训练效率密切相关。经实验测试可知,当batch_size为640时,收敛步数最少,收敛速度最快。因此,本发明将模型的batch_size参数设置为640。
2、损失函数
本发明模型的误差分为四部分:kl散度误差kl_loss、重构误差re_loss、生成误差g_loss以及鉴别误差d_loss。本发明针对上述误差,设计出高效的损失函数,并通过最小化该函数来优化整体模型。
(1)kl_loss表示编码网络构造的潜层空间中,数据的实际分布q(z|x)与期望分布p(z|x)之间的差异,使用kl散度来进行衡量,具体如公式1所示。
本发明模型的潜层空间中数据的期望分布为高斯分布,因此,将编码网络生成的均值μ与方差σ2代入公式1,推导可得kl_loss的具体表达式如公式2所示。
其中,k表示模型在预处理阶段聚类所划分的类别的个数;j=1,2,……,k,表示第j个类别。每一个类别都有一个属于自己分布,因此也有属于自己的μ、δ2。
(2)re_loss表示g网络生成的虚假数据x_fake与真实数据x之间的差异,使用交叉熵损失函数计算,如公式3所示。
(3)本发明的模型将g、d网络结合,使用wasserstein距离作为两者的损失函数。wasserstein距离(又称earth-mover(em)距离)是一种衡量数据分布之间相似程度的有效方法,具体定义如公式4所示。
其中,π(pr,pg)表示两个数据分布pr与pg组成的联合分布的集合,即π(pr,pg)中的每一个元素的边缘分布都是pr与pg。因此,对于每一个可能的联合分布γ,可以从中采样获得(x,y)~γ,其中x~pr,y~pg,之后,以||x-y||的期望值来近似表示数据分布pr与pg之间的差异。为便于求解,可设连续函数f(x)满足k-lipschitz,即|f(x)-f(y)|≤k|x-y|,将其代入公式4并近似可得公式5。
本发明以d网络作为f(x)函数,且对g、d网络的损失函数均不取对数,同时,将d网络的截断参数clip设置为[-0.1,0.1],代入公式5并推导可得g、d网络的损失函数分别如公式6以及公式7所示。
g_loss=-e(d(x_fake))(6)
d_loss=e(d(x_fake))-e(d(x))(7)
(4)优化器
本发明通过实验对比发现:相较于momentum和adam等基于动量的优化算法,rmspropoptimizer能够更好地保证鉴别网络在训练过程中误差梯度的稳定,且能够修改传统的梯度积累为指数加权的移动平均,从而能自适应地调节学习率的变化。因此,本发明使用rmspropoptimizer作为模型优化器,更好地优化各网络模型参数。本发明综合考虑模型的收敛情况以及训练过程中误差大小等因素,将模型的学习率设置为0.001。
三、模型的训练
本发明模型的训练过程分为两个阶段:数据预处理与迭代训练。具体流程如图2所示。
本发明在数据预处理阶段对原始数据按照取值范围进行聚类,可降低类内数据的偏斜程度,提升模型的学习效率。由于本模型处理的原始数据具有规模庞大、分布偏斜等特点,因此,本发明使用mini_batch_kmeans算法,对原始数据进行聚类预处理,获得聚类后的真实数据x以及各类的条件特征y等参数信息。
之后,在迭代训练阶段,本发明将真实数据与对应的条件特征信息相融合作为模型的输入,使用编码网络得到潜层空间中数据分布的均值μ与方差δ2;并以μ和δ2作为参数,通过random()随机函数产生潜层空间中的噪音数据z={z1,...,zn}。生成网络从潜层空间中随机地抽取一组噪音数据,并通过深层网络模型生成满足条件特征y的虚假样本x_fake。之后,模型使用鉴别网络对x_fake进行判断,得到x_fake是否为真的概率值,并根据公式2、3、6、7分别计算编码网络、生成网络以及鉴别网络的误差损失。如果各网络的误差均低于收敛阈值ε,则训练完成,否则继续迭代训练,并使用rmspropoptimizer优化器根据学习率ρ调整整个模型的参数。
四、基于条件生成模型的近似查询处理算法(cvwgaqp++算法)
本发明利用cvwgan模型所生成的符合原始数据分布的样本摘要,实现近似查询处理;并与聚集预计算相结合,构成高效的近似查询处理算法,提高查询准确率,满足用户交互性。同时,采用表决算法,对模型生成的样本进行过滤,可提高样本质量,降低近似查询误差。算法流程如图3所示,具体为:
1、采用聚集预计算,计算用户查询的预聚集值,利用模型训练过程中数据预处理阶段对原始数据划分得到的各个类别作为预聚集值计算的范围;
2、使用deal()函数对用户查询进行处理,匹配预先计算的聚集值的范围,获得估计用户查询与聚集预计算范围之间差异的新查询newq,以及选择的预聚集值truevalue;
3、利用本发明构建的cvwgan模型为新查询newq生成数据样本;
4、通过表决算法对生成的数据样本以及样本内部数据进行过滤。
本发明设计的表决算法包含两种过滤器,分别为样本过滤器(samplefilter,sf)与数据过滤器(datafilter,df)。每种过滤器均采用集成学习的思想,选用多种分类算法,更好、更全面的对模型生成的数据进行过滤。
本发明综合考虑近似查询算法的准确性与实用性,令每种过滤器均包含三种分类算法,从而更加高效的对生成的样本以及样本内部数据进行过滤。其中,样本过滤器选用支持向量机、人工神经网络以及决策树等精度较高的分类算法,对模型生成的单一样本进行分类预测;数据过滤器选用朴素贝叶斯、决策树以及逻辑回归等算法,实现对样本内部数据的快速预测。样本过滤器、数据过滤器的具体算法流程分别如图4和图5所示。
5、将过滤后的样本与选择的预聚集值相结合,计算得到最终的查询估计值。
五、算法评价
为了评价本发明算法的性能,本发明提供以下实验数据予以验证。
1、实验环境设置
实验硬件环境为nvidiateslak80gpu;8gb内存;500gb硬盘;操作系统为windows10。本发明采用pycharm2020.2编程环境与python编程语言开发了模拟测试程序,使用tensorflow学习框架构建本发明的生成模型。
2、实验数据集
本发明选用两个数据集进行实验,分别为真实数据集tlctrip与合成数据集。
tlctrip数据集:tlctrip是纽约市出租车和豪华轿车委员会(nyctaxiandlimousinecommission)的真实数据集。本发明使用2010年至2020年黄车数据表中的”trip_distance”属性数据,截取其中的部分元组4000万个。
合成数据集:本发明使用tpc-h基准生成合成数据集。本发明固定生成数据的规模,将偏斜因子从0变化到2,每次增加0.5,获得5个含有100万行元组,偏斜程度不同的数据集。
3、实验工作负载与评估指标
本发明对实验数据集执行求平均的聚集查询,对每个查询重复执行1000次并对结果求平均。为评估本发明算法的效率,实验使用平均相对误差以及平均查询响应时间作为评估指标,具体如公式8和公式9所示。
其中,avg_re表示平均相对误差;n表示所执行查询的次数;esti表示第i次查询的估计聚集值;truei表示第i次查询的真实聚集值;avg_time表示平均响应时间;timei表示第i次查询的响应时间。
4、对比算法
为了更好的体现本发明提出的cvwgaqp++算法的准确性与高效性,实验选择以下的对比算法。
(1)基于随机抽样的saqp++
基于随机抽样的saqp++算法将基于随机抽样的saqp与aggpre相结合,具有比saqp以及aggpre更高的性能。因此,本发明选用saqp++算法作为实验的对比算法,并参照文献(zhangd,leim,zhux.saqp++:bridgingthegapbetweensampling-basedapproximatequeryprocessingandaggregateprecomputation[c]//2018ieeethirdinternationalconferenceondatascienceincyberspace(dsc),guangzhou,june18-21,2018,piscataway:ieee,2018:258-265.)中的算法思想,在本实验平台进行实现
(2)基于vae近似查询处理算法以及基于cwgan的近似查询处理算法
vae以及cwgan是基于模型的近似查询处理方向中比较经典的生成模型算法,且两者的模型结构与本发明算法相似,因此,本发明选用vae以及cwgan模型所实现的近似查询处理算法作为对比算法,并在本实验平台进行实现。文献(zhangm,wangh.approximatequeryprocessingforgroup-byqueriesbasedonconditionalgenerativemodels[j].arxivpreprintarxiv,2021,2101.02914.)采用cwgan模型实现近似查询处理,回答group-by查询,因此,本发明的cwgan对比算法以该文献为基础,并进行一定修改以适应本文求平均的聚集查询。本发明的vae对比算法参照文献(thirumuruganathans,hasans,koudasn,etal.approximatequeryprocessingfordataexplorationusingdeepgenerativemodels[c]//2020ieee36thinternationalconferenceondataengineering(icde),dallas,april20-24,2020.piscataway:ieee,2020:1309-1320.)中提出的基于多vae模型的近似查询算法进行实现。
5、结果分析
(1)克服数据偏斜的效果分析
为测试本发明的cvwgaqp++算法在偏斜数据中的查询效果,本发明在偏斜因子不同的合成数据集中进行实验,并选用上述对比算法进行对比,实验结果如图6所示。
从图6中可以看出,当偏斜因子为0,数据均匀分布时,本发明的算法与各对比算法都有着较高的准确率,avg_re相差不大;当偏斜因子为1.0时,saqp++算法的avg_re已经超过0.15,而本发明的算法的avg_re却只增加不到0.04,且低于vae与cwgan。而且偏斜因子从0增加到2的过程中,本发明算法的avg_re前后变化平稳,因此,本发明提出的算法能够有效地克服数据偏斜对近似查询的影响。
(2)查询结果质量分析
本发明在不同规模的真实数据集下,保持生成样本的规模及查询范围的大小不变,将本发明的算法与本实验中的其他对比算法进行对比测试,实验结果如图7所示。从图中可以发现,相较于其他对比算法,本发明的cvwgaqp++算法具有更高的准确性,而且随着原始数据规模的增加,cvwgaqp++算法的平均相对误差增长较小,能够更加准确地回答用户查询。
(3)查询响应时间分析
本发明在真实数据集下,通过变化各算法生成数据的规模,测试cvwgaqp++算法与其他对比算法对用户查询的平均响应时间,实验结果如图8所示。从图中可以看出,在预先加载好生成模型的情况下,随着生成的数据规模的增加,cvwgaqp++等生成模型算法的平均响应时间远小于saqp++算法,原因在于cvwgaqp++算法在回答用户查询时,只需利用预先加载的生成模型,根据查询需要生成数据样本,而无需访问底层数据,从而能够避免磁盘交互,减少查询时间。cvwgaqp++为保证查询精度引入了表决算法,因此,其查询响应时间高于cwgan与vae等算法,但从总体来看,相互之间差距并不大。因此,本文提出的cvwgaqp++算法可以很好地满足用户查询的交互性。
本发明提供了基于条件生成模型的近似查询处理算法。首先,本发明构建了一种高效的深度生成模型,该模型融合cvae、cgan等经典的模型算法,并引入wasserstein距离作为误差衡量,消除模型坍塌;其次,将该模型应用于近似查询,并与聚集预计算相结合,提出cvwgaqp++算法框架;同时,设计了高效的表决算法,降低近似查询误差。实验结果表明,本发明提出的算法相较于对比算法在性能上有显著的提高。
- 还没有人留言评论。精彩留言会获得点赞!