一种针对T型拓扑结构的DDR4地址控制线映射和Ball排列方法与流程
本发明涉及片上系统(soc)封装排布和地址映射领域,具体涉及针对t型拓扑结构的ddr4地址控制线映射和ball排列方法。
背景技术:
随着系统主频提升,高清摄像头的应用,以及越来越多的算法应用,比如人脸识别,手机,智能摄像头系统的数据速率变得越来越高。系统中所使用的ddr存储器速率也随之提升,并且存储器的数目也增多。随之而来的就是速率提升带来的信号完整性问题,多颗存储器的拓扑结构也使得信号极具恶化,业内常用的两种地址/控制拓扑结构各有优缺点:
t型拓扑结构,常用于两片存储器的方案,不适用于多片。fly-by结构,多用于多片的方案,片数越多,信号恶化越明显,需要对分支和主线的阻抗做特殊设计以满足阻抗匹配,同时分支的长度对速率影响明显。本文中所探讨的t型拓扑结构的方案,多用于同时驱动两片存储器的场景,相比较于fly-by结构,t型结构的布局布线面积更小。它的缺点在于,在高速的应用场景下,t型结构的分叉点到两个存储器的延时差同时影响到眼图的质量和建立保持时间的裕度。为了保证设计满足要求信号质量和时序裕度,就需要控制分支等延时,同时控制组内多跟信号线的延时差,对pcb设计要求严格会导致布线面积加大。同时容易被忽视的是,由于pcb外层和内层的单位长度的走线延时不同,就会导致看起来等长的走线,实际上延时并不一致,信号质量控制的要求交付到客户有不可控因素。
技术实现要素:
本发明提供一种针对t型拓扑结构的ddr4地址控制线映射和ball排列方法,满足信号质量和时序裕度要求。
本发明所要解决的技术问题是通过如下技术方案实现的:
本发明提供一种针对t型拓扑结构的ddr4地址控制线映射和ball排列方法,其特征在于:根据过孔位置的排布,过孔相邻的地址/控制线映射时分配在一个组内;即在ddr控制器的配置时,共用一个延时配置。
优选的,点对点的信号,对应同一颗存储器分配在一个组内。
优选的,ddr控制器的管脚排列,同一组内的管脚排布位置相邻,以保证延时相近。
优选的,同一个组内的地址/控制信号,在相同的内层走线。
本发明的有益效果在于:综合眼图质量最优,在实现时序裕度最大化的同时又能降低pcb绕等长的难度,减小pcb走线面积。在不需要专门pcb等长处理的同时,满足地址/控制线时序裕度的最大化,简化pcb设计,缩小布线面积的同时保证硬件设计的一致性。
附图说明
图1是本发明的针对t型拓扑结构的ddr4地址控制线映射和ball排列方法应用案例;
图2是本发明的针对t型拓扑结构的ddr4地址控制线映射和ball排列方法针对的t型拓扑结构。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
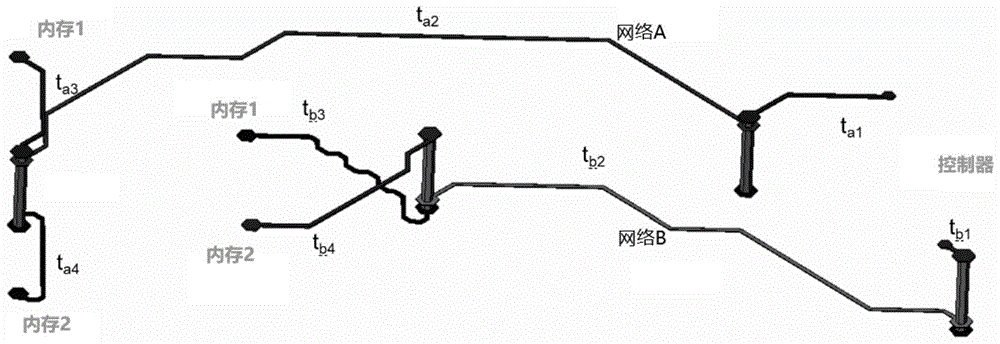
图1是本实施例的针对t型拓扑结构的ddr4地址控制线映射和ball排列方法应用案例。a,b是同一组内两个地址/控制信号,每一段的延时如下图,为了讨论方便,假设t型后的分支相等,即ta3=ta4,tb3=tb4。在任意一个存储器的接收端,地址控制线的延时满足公式1。根据前面的讨论,同一组内的信号,网络a,网络b的延时将影响采样窗口的大小。为了最大的时序裕度,|ta-tb|应小于控制器的延时调整步进,或者更小。为了满足这个要求,需要在pcb走线上控制|ta-tb|。由于jedec协议中对存储器地址的位置固定,ta3,tb3是明确的,ta2,ta3,tb2,tb3则和ddr控制器相对应的ball的位置相关,假设网络a,网络b在ddr控制器侧的位置相对较远,则需要在pcb走线上做延时不偿,来满足延时偏差。如此就会增加pcb的走线难度和走线面积。
本发明所提供的方案就是从ballmap排列和地址/控制信号映射方案,在不需要额外的pcb走线补偿的同时,满足最佳的时序裕度。
公式1:
ta=ta1+ta2+ta3
tb=tb1+tb2+tb3
ddr4存储器的地址ball位置,除了个别的地址信号比如ras,cas,bg1由于存储器的page,bank的数量不一样,绝大多数的地址位置是固定的。当使用t型机构,两颗存储器背靠背的方案,信号扇出的方式也相对固定。
地址映射和管脚分布以及pcb走线的原则如下:
根据过孔位置的排布,过孔相邻的地址/控制线映射时分配在一个组内。即在ddr控制器的配置时,共用一个延时配置。
ddr控制器的管脚排列,同一组内的管脚排布位置相邻,以保证延时相近,不需要额外的走线等长满足延时调整
同一个组内的地址/控制信号,在相同的内层走线,就可以避免由于过孔长度不一致引入的同一组内的信号延时差。
cs,odt,cke点对点的信号,对应同一颗存储器分组一组
在控制器地址重映射,管脚排列和pcb布线的时候按照以上三个原则,就可以在不需要专门pcb等长处理的同时,满足地址/控制线时序裕度的最大化,简化pcb设计,缩小布线面积的同时保证硬件设计的一致性。
jesd79-4a协议中对于ddr存储器地址信号的时序要求,在地址信号的接收端,也就是存储器的输入端,需要满足一定的建立保持时间。实际的应用中,地址信号和时钟信号有延时调整机制,可以至少在一个ui(单位时间间隔)以内调整时钟和地址/控制信号的延时,即调整信号采样点。所以信号完整性仿真,就不再关心具体的建立保持时间,而是关注信号的有效采样窗口,即信号眼宽。考虑信号眼宽,除了存储器本身的采样窗口,还需要ddr控制器时钟抖动,电源引入的信号抖动,以及同一组地址/控制线的延时差。
需要特别说明的是,所谓同一组地址/控制信号,在ddr控制器的配置中,共用一个延时配置,这就代表,同一个组内的信号线,需要控制组内信号封装和pcb的延时差,小于延时调整的步进,以保证时钟和地址/控制信号的延时调整,可以在最小的信号眼宽内,保证有效的建立保持时间。为了满足时序要求,将同一组内的信号ca1,ca2增加额外的延时t=n*单位步进。在调整的过程中,ca1和ca2由于封装,pcb的延时差δt固定存在,就会增加额外的采样窗口需求。所以对于地址/控制信号线来说,除了关心眼宽,还需要关心同一个延时配置的组内多个信号线的延时差。
图2是本实施例的针对t型拓扑结构的ddr4地址控制线映射和ball排列方法针对的t型拓扑结构。ddr的地址/控制线走线表层扇出后,通过内层到t型结构的分支点,再由分支点,分别经过顶层和底层到两个存储器,两个存储器的位置相对。为了分析分支的影响,将t型拓扑结构在仿真软件中建模,从控制器到分支点的长度固定为l1=15mm,分支点到第一颗存储器的走线长度为l2,分支点到第二颗存储器的走线长度为l3。下面的仿真案例调整l2,l3的长度看眼图的变化。
固定l1=15mm,l2=5mm,l3=3mm,4mm,5mm,6mm,7mm,8mm,9mm。根据仿真结果可以看到,当分支的长度相等时存储器1和存储器2的眼图一样。当分支的长度不相等时,分支短的存储器接收眼图恶化,并且随着分支长度的差异变大,眼图进一步恶化。固定l1=15mm,l2=l3=5mm和l2=l3=12mm的眼图,可以看到信号的眼图随着分支的绝对长度变长而恶化。实际应用中由于串扰的存在,随着走线长度边长,串扰信号耦合加大,长分支的眼图恶化会更明显。
为了分析过孔的延时影响,建模如下:6层叠层结构,网络a,从顶层扇出经过过孔到第四层,再从过孔到顶层。网络b从顶层扇出经过过孔到第三层,再从过孔到顶层层网络。a,b只有过孔的差异,每一段的长度相等,第三层和第四层走线参考层完整,走线长度和延时相等。换句话说,这两个网络的延时差异,只顶层到第三层,和顶层到第4层的过孔延时差异。
延时的结果如下:根据叠层,顶层到第三层,和顶层到第4层的过孔长度差异带来的延时差为28.3ps。相对于走线的延时差,地址/控制线的调整步进,这个延时差已经不能忽略。这就带来一个问题,当走线叠层厚度,即过孔长度不固定,并且实际走线中,外层微带线和内层带状线单位长度的时延不一致。就会导致时延的控制很难通过pcb走线的等长来控制。甚至看上去长度相等的走线,延时并不相等。如果不通过仿真,就无法获知并控制组内的延时。即便是相同的走线,也会因为pcb的厚度不一样,导致不同层过孔引入的延时不一样,带来硬件的不一致以及客户设计方案不可控。
综合以上的仿真,结论如下:对于t型的两个存储器的布局
分支长度相等时,信号质量最佳。
分支长度不相等时,分支短的信号眼图恶化更明显。
同样分支长度相等的情况下,分支越短越好,分支的长度会影响眼宽。
如果分支长度过长,或者分支的走线长度差异大,会影响眼图的宽度,从而影响地址/控制线的速率。
过孔会引入额外的延时,案例相同的走线,由于走线所在的层不同,同一组信号内的信号延时差异。
以上的仿真是基于单根信号线的评估,在实际的系统里,由于线间串扰的影响,眼图闭合将会更加明显。
本发明中关于管脚排列的建议,就是根据dram固定的地址信号分布,调整控制器的地址/控制线映射方案,用最简单的pcb走线,控制同组地址/控制线的组间延时差。
- 还没有人留言评论。精彩留言会获得点赞!