基于安全洗牌和差分隐私的联邦学习模型安全防护方法及系统与流程
1.本发明属于人工智能领域,具体涉及一种基于安全洗牌和差分隐私的联邦学习模型安全防护方法及系统。
背景技术:
2.联邦学习是一种正在被广泛研究和使用的人工智能技术,目标是在保障大数据交换时的信息安全、保护终端数据和个人数据隐私、保证合法合规的前提下,在多参与方或多计算结点之间开展高效率的机器学习。因此,联邦学习能够解决数据不出本地的机器学习任务,从而保护协同参与者的训练样本数据隐私,解决了数据孤岛问题。然而,目前联邦学习虽然解决了各个参与方的训练样本等数据隐私问题,但现有的相关差分隐私保护技术的使用都关注模型训练过程中样本隐私和参数隐私,未能够解决联邦学习模型发布本地使用的模型安全隐私。众所周知,邦学习模型是多方协同合作的结果,原始的联邦学习模型是模型拥有者的数据资产,保证联邦学习模型发布使用的隐私性仍是亟待解决的问题。因此,如何安全发布原始的联邦学习模型,以及保证用户对模型的可用性是一个重要的技术难点。
技术实现要素:
3.发明目的:针对现有技术的不足,本发明一种基于安全洗牌和差分隐私的联邦学习模型安全防护方法及系统,能保护联邦学习模型拥有者的隐私、保证用户获得的联邦模型的可用性。
4.技术方案:本发明所述的一种基于安全洗牌和差分隐私的联邦学习模型安全防护方法,包括以下步骤:
5.(1)基于差分隐私高斯机制对联邦学习的模型参数进行加噪声,生成带噪声的模型参数;
6.(2)利用用户授权密钥和安全洗牌算法对差分隐私加噪后的模型参数进行加密,并将加密的联邦学习模型参数发送给用户;
7.(3)利用用户授权密钥和安全洗牌算法解密模型参数密文,得到带噪声的联邦学习模型;
8.(4)将用户的数据作为带噪声的联邦学习模型的输入,得到期望的输出结果。
9.进一步地,所述步骤(1)实现过程如下:
10.联邦学习模型π的参数构成一个m
×
n的矩阵a
π
,利用差分隐私中的高斯机制对矩阵a
π
中的每个元素进行噪声处理,得到带噪声的联邦学习模型π
′
的参数矩阵a
′
π
:
11.a
′
π
(i,j)=a
π
(i,j)+α
ꢀꢀꢀꢀꢀꢀ
(1)
12.其中,高斯机制提供松弛(ε,δ)-差分隐私,噪声比例σ≥cδs/ε,常数差分隐私,噪声比例σ≥cδs/ε,常数ε∈(0,1);敏感度高斯噪声分布α~n(0,σ2)满
足(ε,δ)-差分隐私,α为矩阵中每一个数据所增加的噪声数值,敏感度代表了查询函数s针对相邻数据集的输出的最大不同。
13.进一步地,所述步骤(2)包括以下步骤:
14.(21)读入m
×
n的带噪声的联邦学习模型参数矩阵a
π
;
15.(22)初始化逻辑映射控制参数s,d,f,g,其中,s为混沌控制参数,d和f为逻辑映射控制参数,分别对xn、yn进行映射,g为耦合项;并初始迭代映射iter=200,给定密钥key={x,y},其中x和y是混沌映射的两个初始值;
16.(23)以密钥key为初始值,通过迭代映射m
×
n+iter对混沌序列值,舍弃iter对值,得到m
×
n对的混沌序列值,并将其分别存储于大小为m
×
n的一维数组p和q中:
[0017][0018]
(24)对p和q中的元素运行下面的安全洗牌算法1运算得到两个整数值的一维矩阵p
′
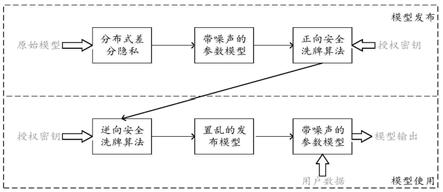
和q
′
;
[0019]
(25)通过p
′
和q
′
进行排序生成两个长度为m
×
n的一维伪随机序列矩阵p”和q”,其元素取值为[0,m
×
n-1]内不等的整数;
[0020]
(26)对于一维随机序列p”和q”中的各元素p”(k)和q”(k)进行下列变换,并将其映射为大小为m
×
n的二维置乱矩阵x、y;
[0021][0022]
其中,x(i,j)、y(i,j)分别为二维置乱矩阵x、y的元素;
[0023]
(27)利用置乱矩阵x先对矩阵a
π
进行置乱,得到临时模型参数置乱中间结果;再用y对临时模型参数置乱中间结果进行位置置乱,得到最终的带噪声的联邦学习模型参数置乱密文。
[0024]
进一步地,所述步骤(3)实现过程如下:
[0025]
(31)给定与加密过程相同的密钥key={x,y},由密钥x,y生成置乱矩阵x、y;
[0026]
(32)利用置乱矩阵y先对带噪声的联邦学习模型参数置乱密文进行置乱,得到临时模型参数置乱中间结果,再用x对临时模型参数置乱中间结果进行位置置乱,得到带噪声的参数模型。
[0027]
基于相同的发明构思,本发明还提出一种基于安全洗牌和差分隐私的联邦学习模型安全防护系统,包括参数处理模块、加密模块和解密模块;所述参数处理模块基于差分隐私高斯机制对联邦学习的模型参数进行加噪声,生成带噪声的模型参数;所述加密模块利用用户授权密钥和安全洗牌算法对差分隐私加噪后的模型参数进行加密,并将加密的联邦学习模型参数发送给用户;所述解密模块利用用户授权密钥和安全洗牌算法解密模型参数密文,得到带噪声的联邦学习模型。
[0028]
进一步地,所述参数处理模块工作过程如下:
[0029]
联邦学习模型π的参数构成一个m
×
n的矩阵a
π
,利用差分隐私中的高斯机制对矩阵a
π
中的每个元素进行噪声处理,得到带噪声的联邦学习模型π
′
的参数矩阵a
′
π
:
[0030]a′
π
(i,j)=a
π
(i,j)+α
ꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0031]
其中,高斯机制提供松弛(ε,δ)-差分隐私,噪声比例σ≥cδs/ε,常数差分隐私,噪声比例σ≥cδs/ε,常数ε∈(0,1);敏感度高斯噪声分布α~n(0,σ2)满足(ε,δ)-差分隐私,α为矩阵中每一个数据所增加的噪声数值,敏感度代表了查询函数s针对相邻数据集的输出的最大不同。
[0032]
进一步地,所述加密模块工作过程如下:
[0033]
(s1)读入m
×
n的带噪声的联邦学习模型参数矩阵a
π
;
[0034]
(s2)初始化逻辑映射控制参数s,d,f,g,其中,s为混沌控制参数,d和f为逻辑映射控制参数,分别对xn、yn进行映射,g为耦合项;并初始迭代映射iter=200,给定密钥key={x,y},其中x和y是混沌映射的两个初始值;
[0035]
(s3)以密钥key为初始值,通过迭代映射m
×
n+iter对混沌序列值,舍弃iter对值,得到m
×
n对的混沌序列值,并将其分别存储于大小为m
×
n的一维数组p和q中:
[0036][0037]
(s4)对p和q中的元素运行下面的安全洗牌算法1运算得到两个整数值的一维矩阵p
′
和q
′
;
[0038]
(s5)通过p
′
和q
′
进行排序生成两个长度为m
×
n的一维伪随机序列矩阵p”和q”,其元素取值为[0,m
×
n-1]内不等的整数;
[0039]
(s6)对于一维随机序列p”和q”中的各元素p”(k)和q”(k)进行下列变换,并将其映射为大小为m
×
n的二维置乱矩阵x、y;
[0040][0041]
其中,x(i,j)、y(i,j)分别为二维置乱矩阵x、y的元素;
[0042]
(s7)利用置乱矩阵x先对矩阵a
π
进行置乱,得到临时模型参数置乱中间结果;再用y对临时模型参数置乱中间结果进行位置置乱,得到最终的带噪声的联邦学习模型参数置乱密文。
[0043]
进一步地,所述解密模块工作过程如下:
[0044]
(h1)给定与加密过程相同的密钥key={x,y},由密钥x,y生成置乱矩阵x、y;
[0045]
(h2)利用置乱矩阵y先对带噪声的联邦学习模型参数置乱密文进行置乱,得到临时模型参数置乱中间结果,再用x对临时模型参数置乱中间结果进行位置置乱,得到带噪声的参数模型。
[0046]
有益效果:与现有技术相比,本发明的有益效果:本发明使模型拥有者利用差分隐私保护了真实联邦学习模型的隐私性,且在加噪方面对训练完成的模型参数上添加噪声,避免对神经网络训练模型产生干扰,保证了带噪声的联邦学习模型的可用性;安全洗牌和授权密钥的结合保证只有授权用户才能得到带噪声的联邦学习模型;从而达到了联邦学习
模型发布本地使用的安全发布。
附图说明
[0047]
图1为本发明的流程图;
[0048]
图2为联邦学习模型正向洗牌流程图;
[0049]
图3为联邦学习模型逆向洗牌流程图。
具体实施方式
[0050]
下面结合附图对本发明作进一步详细说明。
[0051]
本发明提供一种基于安全洗牌和差分隐私的联邦学习模型发布本地使用安全防护方法,保护了模型拥有者的模型资产,保证了用户所获得联邦学习模型的可用性。如图1所示,具体包括以下步骤:
[0052]
步骤1:联邦模型拥有者利用差分隐私对联邦学习的模型参数进行加噪声,生成带噪声的模型参数。各参数说明如表1所示:
[0053]
表1参数说明
[0054]
[0055][0056]
假设联邦学习模型π的参数构成了一个m
×
n的矩阵a
π
,利用差分隐私中的高斯机制对矩阵a
π
中的每个元素进行噪声处理,得到带噪声的联邦学习模型π
′
的参数矩阵a
π
,其数学公式如下:
[0057]a′
π
(i,j)=a
π
(i,j)+α
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0058]
高斯机制能够提供松弛(ε,δ)-差分隐私,为了确保增加的高斯噪声分布α~n(0,σ2)满足(ε,δ)-差分隐私,α为矩阵中每一个数据所增加的噪声数值,设置噪声比例σ≥cδs/∈,其中常数∈∈(0,1),敏感度∈∈(0,1),敏感度敏感度代表了查询函数s针对相邻数据集的输出的最大不同。
[0059]
步骤2:利用用户授权密钥和安全洗牌算法加密模型参数,并将加密的联邦学习模型参数发送给用户,如图2所示。
[0060]
1)读入m
×
n的带噪声的联邦学习模型参数矩阵a
π
。
[0061]
2)初始化逻辑映射控制参数s=4,d=0.9,f=0.9,g=0.1,并初始迭代映射iter=200,给定密钥key={x,y},其中x和y是混沌映射的两个初始值。
[0062]
3)以密钥key为初始值,通过迭代映射m
×
n+iter对混沌序列值,舍弃iter对值,得到m
×
n对的混沌序列值,并将其分别存储于大小为m
×
n的一维数组p和q中,如下式:
[0063][0064]
4)对p和q中的元素运行下面的安全洗牌算法运算得到两个整数值的一维矩阵p
′
和q
′
,如表2所示:
[0065]
表2安全洗牌算法
[0066][0067]
5)通过p
′
和q
′
进行排序生成两个长度为m
×
n的一维伪随机序列矩阵p”和q”,其元素取值为[0,m
×
n-1]内不等的整数。
[0068]
6)对于一维随机序列p”和q”中的各元素p”(k)和q”(k)进行下列变换,并将其映射为大小为m
×
n的二维置乱矩阵x、y:
[0069][0070]
其中,x(i,j)、y(i,j)分别为二维置乱矩阵x、y的元素。
[0071]
7)利用置乱矩阵x先对矩阵a
π
进行置乱,得到临时模型参数置乱中间结果,再用y对临时模型参数置乱中间结果进行位置置乱,得到最终的带噪声的联邦学习模型参数置乱密文。
[0072]
步骤3:用户在本地使用联邦学习模型时,利用用户授权密钥和安全洗牌算法解密模型参数密文,得到带噪声的联邦学习模型,如图3所示,用户将数据作为带噪声的联邦学习模型的输入,得到期望的输出结果。
[0073]
用户收到带噪声的联邦学习模型参数置乱密文和密钥key={x,y}后,需要执行联邦学习模型拥有者的逆运算操作带噪声的参数模型π;使用该模型对自己的数据进行处理。具体过程如下:
[0074]
1)给定与联邦学习模型拥有者加密过程相同的密钥key={x,y}与其加密过程相同,由密钥x,y生成置乱矩阵x、y;
[0075]
2)利用置乱矩阵y先对带噪声的联邦学习模型参数置乱密文进行置乱,得到临时
模型参数置乱中间结果,在用x对临时模型参数置乱中间结果进行位置置乱,得到可以使用的带噪声的参数模型。
[0076]
基于相同的发明构思,本发明还提出一种基于安全洗牌和差分隐私的联邦学习模型安全防护系统,包括参数处理模块、加密模块和解密模块;所述参数处理模块基于差分隐私高斯机制对联邦学习的模型参数进行加噪声,生成带噪声的模型参数;所述加密模块利用用户授权密钥和安全洗牌算法对差分隐私加噪后的模型参数进行加密,并将加密的联邦学习模型参数发送给用户;所述解密模块利用用户授权密钥和安全洗牌算法解密模型参数密文,得到带噪声的联邦学习模型。
[0077]
其中,参数处理模块工作过程如下:
[0078]
联邦学习模型π的参数构成一个m
×
n的矩阵a
π
,利用差分隐私中的高斯机制对矩阵a
π
中的每个元素进行噪声处理,得到带噪声的联邦学习模型π
′
的参数矩阵a
′
π
:
[0079]a′
π
(i,j)=a
π
(i,j)+α
ꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0080]
其中,高斯机制提供松弛(ε,δ)-差分隐私,噪声比例σ≥cδs/ε,常数差分隐私,噪声比例σ≥cδs/ε,常数ε∈(0,1);敏感度高斯噪声分布α~n(0,σ2)满足(ε,δ)-差分隐私,α为矩阵中每一个数据所增加的噪声数值,敏感度代表了查询函数s针对相邻数据集的输出的最大不同。
[0081]
加密模块工作过程如下:
[0082]
(s1)读入m
×
n的带噪声的联邦学习模型参数矩阵a
π
;
[0083]
(s2)初始化逻辑映射控制参数s,d,f,g,其中,s为混沌控制参数,d和f为逻辑映射控制参数,分别对xn、yn进行映射,g为耦合项;并初始迭代映射iter=200,给定密钥key={x,y},其中x和y是混沌映射的两个初始值;
[0084]
(s3)以密钥key为初始值,通过迭代映射m
×
n+iter对混沌序列值,舍弃iter对值,得到m
×
n对的混沌序列值,并将其分别存储于大小为m
×
n的一维数组p和q中:
[0085][0086]
(s4)对p和q中的元素运行下面的安全洗牌算法1运算得到两个整数值的一维矩阵p
′
和q
′
;
[0087]
(s5)通过p
′
和q
′
进行排序生成两个长度为m
×
n的一维伪随机序列矩阵p”和q”,其元素取值为[0,m
×
n-1]内不等的整数;
[0088]
(s6)对于一维随机序列p”和q”中的各元素p”(k)和q”(k)进行下列变换,并将其映射为大小为m
×
n的二维置乱矩阵x、y;
[0089][0090]
其中,x(i,j)、y(i,j)分别为二维置乱矩阵x、y的元素;
[0091]
(s7)利用置乱矩阵x先对矩阵a
π
进行置乱,得到临时模型参数置乱中间结果;再用
y对临时模型参数置乱中间结果进行位置置乱,得到最终的带噪声的联邦学习模型参数置乱密文。
[0092]
解密模块工作过程如下:
[0093]
(h1)给定与加密过程相同的密钥key={x,y},由密钥x,y生成置乱矩阵x、y;
[0094]
(h2)利用置乱矩阵y先对带噪声的联邦学习模型参数置乱密文进行置乱,得到临时模型参数置乱中间结果,再用x对临时模型参数置乱中间结果进行位置置乱,得到带噪声的参数模型。
[0095]
本领域内的技术人员应明白,本技术的实施例可提供为方法、系统、或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0096]
本技术是参照根据本技术实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0097]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0098]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0099]
最后应当说明的是:以上实施例仅用以说明本发明的技术方案而非对其限制,尽管参照上述实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等同替换,其均应涵盖在本发明的权利要求保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1