一种用工数据匹配系统、方法及其存储介质与流程
1.本发明属于大数据领域,尤其涉及一种用工数据匹配系统、方法与存储介质。
背景技术:
2.随着经济发展,一大批待岗人员需要工作岗位,由于自由寻找工作的局限性,有很多人无法找到与自身能力相契合的工作,现代技术中的大数据可以通过数据匹配机制帮助到这些待岗人员。
3.大数据的发展,任务匹配机制也得到了发展,大数据需要在一定时间范围内进行捕捉、管理和处理大量数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产,传统的任务匹配方法耗时长,占用资源多,随着任务量增大会出现匹配信息错漏的情况,很难满足现有需求。
技术实现要素:
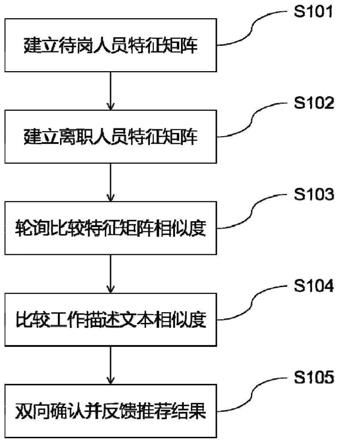
4.为了解决上述技术问题,本发明提出一种用工数据匹配方法,方法步骤如下;
5.步骤s101:建立待岗人员特征矩阵,对当前待岗的工作人员建立人员特征矩阵,进行系统初始化;
6.步骤s102:建立离职人员特征矩阵,对当前离职的工作人员建立人员特征矩阵,进行系统初始化;
7.步骤s103:轮询比较特征相似度,通过算法比较上述俩个特征矩阵之间的相似度,对待就业人员工作矩阵进行循环比较,选择相似度最高的人员作为拟匹配的推荐人员;
8.步骤s104:比较工作描述文本信息相似度,比较拟匹配的推荐人员和离职人员的工作描述文本信息,计算出相似度,根据相似度将待岗人员加入推荐信息列表;
9.步骤s105:双向确认并反馈推荐结果,推荐结果发送至企业与个人进行双向确认,反馈确认结果。
10.另外,本发明还包括一种用工数据匹配系统,系统包括待岗人员特征矩阵建模单元、离岗人员特征矩阵建模单元、特征矩阵比较单元、文本相似度比较单元、确认反馈单元和系统数据库。
11.其中,所述待岗人员特征矩阵建模单元建立待岗人员特征矩阵,对当前待岗的工作人员建立人员特征矩阵,进行系统初始化。
12.所述离岗人员特征矩阵建模单元建立离职人员特征矩阵,对当前离职的工作人员建立人员特征矩阵,进行系统初始化。
13.所述特征矩阵比较单元计算上述俩个矩阵的相似度,通过对待就业人员工作矩阵进行循环比较,选择相似度最高的人员作为拟匹配的推荐人员。
14.所述文本相似度比较单元计算工作描述文本信息相似度,比较拟匹配的推荐人员和离职人员的工作描述文本信息,计算出相似度,根据相似度将待岗人员加入推荐信息列表。
15.所述确认反馈单元双向确认并反馈推荐结果,推荐结果发送至企业与个人进行双向确认,反馈确认结果。
16.所述数据库接收存储上述出现的数据结果以及人员信息等。
17.另外,本发明还提出了一种计算机可读存储介质,所述计算机可读存储介质上存储计算机程序,所述计算机程序被处理器执行时实现如前所述用工数据匹配方法的步骤。
18.综上所述,本发明提供了一种用工数据匹配方法、系统与存储介质,通过特征矩阵建模,对离职人员与待就业人员进行基于特征的数字建模,解决了系统中新增待就业人员数据挖掘冷启动问题,通过特征矩阵相似度计算算法,基于离职人员的特征矩阵,寻找与离职人员相似的待就业人员,提高了数据挖掘的效率,提高了岗位匹配的准确性,通过基于稀疏向量的文本比较方法,进一步提高了数据匹配效率。
附图说明
19.图1为用工数据匹配方法步骤流程图;
20.图2为用工数据匹配方法系统框图。
具体实施方式
21.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
22.本发明的目的在于提供了一种用工数据匹配方法、系统与存储介质,通过特征矩阵建模,对离职人员与待就业人员进行基于特征的数字建模,解决了系统中新增待就业人员数据挖掘冷启动问题,通过特征矩阵相似度计算算法,基于离职人员的特征矩阵,寻找与离职人员相似的待就业人员,提高了数据挖掘的效率,提高了岗位匹配的准确性,通过基于稀疏向量的文本比较方法,进一步提高了数据匹配效率。
23.如图1所示本发明的用工数据匹配方法步骤如下:
24.步骤s101:建立待岗人员特征矩阵,对当前待岗的工作人员建立人员特征矩阵,进行系统初始化;
25.步骤s102:建立离职人员特征矩阵,对当前离职的工作人员建立人员特征矩阵,进行系统初始化;
26.步骤s103:轮询比较特征相似度,通过算法比较上述俩个特征矩阵之间的相似度,对待就业人员工作矩阵进行循环比较,选择相似度最高的人员作为拟匹配的推荐人员;
27.步骤s104:比较工作描述文本信息相似度,比较拟匹配的推荐人员和离职人员的工作描述文本信息,计算出相似度,根据相似度将待岗人员加入推荐信息列表;
28.步骤s105:双向确认并反馈推荐结果,推荐结果发送至企业与个人进行双向确认,反馈确认结果。
29.其中,步骤s101和步骤s102中,待岗人员特征和离职人员特征相同,待岗人员特征矩阵表示为g
ny
(a,b,c,d,e,f),离职人员特征矩阵表示为d
ny
(a,b,c,d,e,f),其中n表示人员编号;y表示人员工作描述文本信息;其中a表示年龄信息,年龄信息分为8个类别,分别用
0到7表示,0表示年龄为0岁到17岁,1表示年龄为18岁到23岁,2表示年龄为24岁到34岁,3表示年龄为35岁到40岁,4表示年龄为41岁到50岁,5表示年龄为51岁到55岁,6表示年龄为56岁到60岁,6表示年龄大于60岁。其中b表示性别信息,b分为两个类别,1表示男性,0表示女性。c表示工种大类信息,c分为8个类别,分别用0到7表示。d表示工种中类信息,d分为66个中类工种,分别用0到65表示。f为工种小类信息,f分为413个工种小类信息,分别用0到412表示。f为岗位级别信息,f分为4类,分别用0到3表示初、中、高、专家。
30.进一步地,所述步骤s103中,特征矩阵相似度计算方法如下:
31.由于现有比较计算工作量大,时间长,本发明采用轮询计算,即在计算特征矩阵相似度之前增加一个分布式计算的前置步骤,进行并发计算,并发计算时s个智能处理机同时处理,快速找到相似度最大的匹配值。
32.初始化s个智能处理机,每个智能处理机分配存储空间、cpu等计算资源,可独立执行计算任务。每个处理机设置监听任务,用于统计处理机的历史计算工作量dat与平均计算时间cot。
33.初始化文本值列表text
ny
,将待岗人员特征矩阵d
ny
(a,b,c,d,e,f)中参数依次去除保存到对应文本值列表汇总,计算文本值列表text
ny
的哈希值,获得哈希值列表hash
ny
。将哈希值列表hash
ny
中每个值转换为对应的十进制数字,并保存在十进制哈希列表ten
ny
.按照十进制哈希列表ten
ny
的十进制从大到小值排序,得到排序后十进制哈希列表ass
ny
。本步骤中转换成十进制的目的在于便于存储于数据库后期便于识别。
34.通过公式计算s个智能处理机的计算处理能力,其中datv表示第v个智能处理机历史计算次数,cotv表示第v个智能处理机平均计算时间。
35.选择当前hv最大值,并且空闲的智能处理机作为领取计算任务的处理机c。将当前被比较的离岗人员特征矩阵g
ny
(a,b,c,d,e,f)中参数转化为文本保存到文本lt中,将lt转化为哈希值,保存到哈希文本ht中,将ht转化为十进制数字并保存到tt中。
36.在十进制哈希列表ass
ny
中寻找与当前被比较的离岗人员的十进制哈希值tt最接近的人员,其特征矩阵作为智能处理机c的计算对象,每次选取计算任务,优先选取十进制哈希列表ass
ny
中,距离当前被比较的离职人员所处位置最近的其他待就业人员。
37.具体地,在找到离当前被比较的离职人员所处位置最近的其他待就业人员后,进行二者特征矩阵相似度计算,计算公式如下:
[0038][0039]
其中,p为特征矩阵中参数总数,p=6;其中x表示相似度系数,d(n)表示离岗人员特征矩阵g
ny
(a,b,c,d,e,f)中第n个参数值;g(n)表示待岗人员特征矩阵d
ny
(a,b,c,d,e,f)中第n个参数值。
[0040]
其中,所述相似度系数计算方法如下:
[0041]
[0042]
其中x表示相似度系数;m表示待岗人员特征矩阵与离职人员特征矩阵中a、b、c、d、e和f完全相同的个数;p为特征矩阵中参数总数,p=6。
[0043]
进一步地,步骤s104中,工作描述文本信息相似度计算方法如下:
[0044]
其中,使用jieba分词工具,对文本y1和y2分词,得到两个分词文本f1和f2;
[0045]
使用defaultdict方法,计算两个分词文本f1和f2的词频信息,得到词频文本c1和c2;
[0046]
选取词频数量前10组成词频精选文本j1和j2;
[0047]
通过doc2bow工具将词频精选文本j1和j2转化为稀疏向量s1和s2;
[0048]
对稀疏向量s1和s2加工处理,得到新词库n1和n2;
[0049]
通过tf-idf模型处理新词库n1和n2,得到tf-idf数值;
[0050]
通过token2id得到tf-idf数值对应的特征数值t1和t2;
[0051]
通过similarities的sparsematrixsimilarity方法,计算特征数值t1和t2的稀疏矩阵相似度,稀疏矩阵相似度即为工作描述文本信息相似度。
[0052]
需要说明的是,稀疏矩阵相似度大于40%的待岗人员加入推荐信息列表,如果稀疏矩阵相似度小于40%则重复比较下一个待岗人员工作矩阵。
[0053]
进一步地,步骤s105中,双向确认并反馈推荐结果,推荐结果发送至企业与个人进行双向确认,反馈确认结果。
[0054]
为了实现上述用工数据匹配方法,本发明还包括一种用工数据匹配系统。
[0055]
如图2所示的用工数据匹配系统框图,系统包括待岗人员特征矩阵建模单元、离岗人员特征矩阵建模单元、特征矩阵比较单元、文本相似度比较单元、确认反馈单元和系统数据库。
[0056]
其中,所述待岗人员特征矩阵建模单元建立待岗人员特征矩阵,对当前待岗的工作人员建立人员特征矩阵,进行系统初始化。
[0057]
所述离岗人员特征矩阵建模单元建立离职人员特征矩阵,对当前离职的工作人员建立人员特征矩阵,进行系统初始化。
[0058]
所述特征矩阵比较单元计算上述俩个矩阵的相似度,通过对待就业人员工作矩阵进行循环比较,选择相似度最高的人员作为拟匹配的推荐人员。
[0059]
所述文本相似度比较单元计算工作描述文本信息相似度,比较拟匹配的推荐人员和离职人员的工作描述文本信息,计算出相似度,根据相似度将待岗人员加入推荐信息列表。
[0060]
所述确认反馈单元双向确认并反馈推荐结果,推荐结果发送至企业与个人进行双向确认,反馈确认结果。
[0061]
所述数据库接收存储上述出现的数据结果以及人员信息等。
[0062]
此外,本发明还提出了一种计算机可读存储介质,所述计算机可读存储介质上存储计算机程序,所述计算机程序被处理器执行时实现如前所述用工数据匹配方法的步骤。
[0063]
运用本实施例中提出的一种用工数据匹配方法、系统与存储介质,寻找与离职人员相似的待就业人员,提高了数据挖掘的效率,提高了岗位匹配的准确性,通过基于稀疏向量的文本比较方法,进一步提高了数据匹配效率。
[0064]
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排
他性的包含,从而使得包括一系列要素的过程、方法、物品或者装置不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者装置所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括该要素的过程、方法、物品或者装置中还存在另外的相同要素。
[0065]
上面结合附图对本发明的实施例进行了描述,但是本发明并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本发明的启示下,在不脱离本发明宗旨和权利要求所保护的范围情况下,还可做出很多形式,均属于本发明的保护之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1